Глава 22. Защита информации как часть повседневной работы всех сотрудников компании
Одним из главных возражений против принятия принципов и практик DevOps стало то, что службы безопасности, как правило, не позволяют их использовать. И тем не менее подход DevOps является одним из лучших, если нужно встроить защиту информации в повседневную работу всех участников потока создания ценности.
Когда за информационную безопасность отвечает отдельное подразделение, возникает много проблем. Джеймс Уикетт, один из создателей средства защиты GauntIt и организатор конференции DevOpsDays в Остине и конференции Lonestar Application Security, отмечает:
«Одной из причин появления DevOps называют необходимость повысить производительность разработчиков, потому что с ростом числа разработчиков инженеры эксплуатации перестают справляться с развертываниями. Это ограничение еще сильнее бросается в глаза в информационной безопасности: отношение инженеров разработки, эксплуатации и информационной безопасности в типичной организации — обычно 100:10:1. Когда работников информационной безопасности так мало, без автоматизации и интегрирования защиты информации в повседневную деятельность отделов разработки и эксплуатации их времени будет хватать только на проверку, соответствует ли продукт нормативам и требованиям, что прямо противоположно принципам защиты данных. И, кроме того, из-за этого все нас ненавидят».
Джеймс Уикетт и Джош Кормен, бывший технический директор компании Sonatype и известный исследователь информационной безопасности, писали о встраивании целей защиты информации в DevOps, о наборе методик и принципов под названием прочный DevOps (Rugged DevOps). Похожие идеи, где защита информации встроена во все стадии цикла создания ПО, были разработаны Тапабратой Палом, директором и инженером по разработке платформ банка Capital One, и командой Capital One. Они назвали придуманные ими процессы DevOpsSec. Один из источников идей DevOps — книга Visible Ops Security, ее авторы — Джин Ким, Пол Лав и Джордж Спаффорд.
В этой книге мы изучали, как полностью встроить цели контроля качества и эксплуатации на протяжении всего потока создания ценности. В этой главе мы пишем, как похожим способом можно встроить цели информационной безопасности в повседневную работу, увеличив продуктивность разработчиков и инженеров эксплуатации, безопасность и надежность систем и сервисов.
Приглашайте инженеров службы безопасности на презентации промежуточных этапов создания продуктов
Одна из наших целей — сделать так, чтобы инженеры службы безопасности начинали работать с командами разработчиков как можно раньше, а не присоединялись в самом конце проекта. Один из возможных способов добиться этого — приглашать службу безопасности на презентации продукта в конце каждого цикла разработки, чтобы ей было проще разобраться в целях разработчиков в контексте целей организации, пронаблюдать за развитием компонентов продукта, высказать пожелания и дать обратную связь на ранних стадиях проекта, когда еще достаточно времени и свободы, чтобы вносить правки.
Джастин Арбакл, бывший ведущий архитектор GE Capital, отмечает: «Когда дело дошло до информационной безопасности и соответствия нормам и стандартам, мы обнаружили, что проблемы в конце проекта обходились гораздо дороже, чем вначале, и проблемы безопасности были худшими. “Проверка соответствия требованиям на промежуточных этапах” стала одним из важных ритуалов равномерного распределения сложности по всем стадиям создания продукта».
Далее он продолжает: «Вовлекая службу безопасности в создание любого нового элемента функциональности, мы сильно сократили число чек-листов и начали больше полагаться на знания и опыт инженеров информационной безопасности на всех стадиях разработки продукта».
Это упростило выполнение бизнес-целей организации. Снехал Антани, бывший директор по информационным технологиям подразделения Enterprise Architecture компании GE Capital Americas, говорил, что у них тремя ключевыми показателями были «скорость разработки (то есть скорость вывода на рынок новых продуктов и элементов функциональности), неудачи в работе с клиентами (то есть сбои и ошибки) и время на выполнение запроса о соответствии нормам (то есть время от запроса аудиторов до предоставления всей количественной и качественной информации для удовлетворения запроса)».
Когда отдел безопасности вовлечен в процесс создания продукта, даже если его просто держат в курсе того, что происходит, сотрудники имеют представление о контексте работы и поэтому могут принимать взвешенные решения. Кроме того, инженеры безопасности могут помочь командам разработчиков понять, что нужно, чтобы продукт соответствовал нормам безопасности и законодательным требованиям.
Вовлекайте инженеров безопасности в поиск дефектов и приглашайте их на совещания по разбору ошибок и сбоев
Если есть возможность, стоит отслеживать все проблемы с защитой данных в той же системе учета, которая используется в разработке и эксплуатации. Такой подход очень отличается от традиционного подхода службы безопасности, где все уязвимые места хранятся в инструменте GRC (governance, risk, compliance — управление, риск, соответствие требованиям), а доступ к нему есть только у отдела безопасности. Вместо этого будем помещать все задачи по защите данных в системы, используемые разработкой и эксплуатацией.
В презентации 2012 г. на конференции DevOpsDays в Остине Ник Галбрет, на протяжении многих лет возглавлявший отдел информационной безопасности в Etsy, так описывает свой подход к проблемам защиты: «Все задачи по защите данных мы создавали в JIRA. Ею все инженеры пользуются каждый день, и их приоритет был либо “P1”, либо “P2” — то есть они должны были быть исправлены сразу же или к концу недели, даже если проблема была во внутреннем приложении организации».
Кроме того, он утверждает: «Каждый раз, когда у нас была проблема с безопасностью, мы проводили совещание по разбору ошибок, потому что после них инженеры лучше понимали, как предотвратить такие ошибки в будущем, и потому что это отличный способ распространять знания о безопасности и защите данных между командами».
Встройте профилактические средства контроля безопасности в общие репозитории и сервисы
В мы создали хранилище кода, доступное всей организации. В нем все могут легко найти накопленные знания организации: не только о коде, но и о наборах инструментов, о конвейере развертывания, стандартах и т. д. Благодаря этому все сотрудники могут извлечь пользу из опыта своих коллег.
Теперь добавим в репозиторий все механизмы и инструменты, которые помогут сделать приложения и среды более безопасными. Мы добавим одобренные службой безопасности библиотеки, выполняющие вполне конкретные цели по защите данных: это библиотеки и сервисы аутентификации и шифрования данных. Поскольку все в потоке создания ценности DevOps используют системы контроля версий для всего, что пишут или поддерживают, добавление компонентов и утилит безопасности позволит влиять на повседневную деятельность разработки и эксплуатации, потому что теперь все, что мы создаем, становится доступно для поиска и повторного использования. Система контроля версий также служит многонаправленным средством коммуникации, благодаря чему все находятся в курсе сделанных изменений.
Если сервисы в нашей организации централизованные и общедоступные, мы можем создавать и управлять общедоступными платформами и в сфере безопасности, например централизовать аутентификацию, авторизацию, логирование и другие нужные разработке и эксплуатации сервисы защиты и аудита. Когда инженеры используют одну из заранее созданных библиотек или сервисов, им не нужно планировать специальную проверку безопасности для этого модуля. Укрепление защиты конфигураций, настройки безопасности баз данных, длина ключей — везде будет достаточно просто воспользоваться уже созданными ориентирами.
Чтобы еще больше увеличить шансы, что библиотеки будут использоваться правильно, можно провести специальный тренинг для команд разработки и эксплуатации, а также отрецензировать их работу и проверить, что требования безопасности выполнены, особенно если команды пользуются этими инструментами впервые.
Наша итоговая цель — предоставить библиотеки и сервисы защиты информации, нужные в любом современном приложении или среде: это аутентификация, авторизация, управление паролями, шифрование данных и так далее. Кроме того, мы можем создать эффективные настройки конфигурации безопасности для компонентов, используемых командами разработки и эксплуатации в своих стеках приложения, например логирование, аутентификация и шифрование. Сюда можно включить вот что:
• библиотеки и рекомендуемые конфигурации (например, 2FA (двухфакторная аутентификация), хэширование паролей bcrypt, логирование);
• управление секретной информацией (например, настройки соединения, ключи шифрования) с помощью таких инструментов, как Vault, sneaker, Keywhiz, credstash, Trousseau, Red October и так далее;
• пакеты и сборки операционных систем (например, NTP для синхронизирования времени, безопасные версии OpenSSL с правильными конфигурациями, OSSEC или Tripwire для слежения за целостностью файлов, конфигурации syslog для логирования важных параметров безопасности в стек ELK).
Помещая все эти инструменты в единый репозиторий, мы упрощаем инженерам работу: они могут использовать в приложениях и средах гарантированно верные стандарты логирования и шифрования, без лишних усилий с нашей стороны.
Кроме того, можно скооперироваться с командами эксплуатации и создать базовый справочник и образы нашей операционной системы, баз данных и другой инфраструктуры (например, NGINX, Apache, Tomcat), чтобы проконтролировать, что они находятся в безопасном, безрисковом, известном состоянии. Единый репозиторий становится тем местом, где можно не только взять последние версии кода, но и где мы сотрудничаем с другими инженерами, наблюдаем за важными с точки зрения безопасности модулями и в случае непредвиденных происшествий получаем соответствующие оповещения.
Встройте меры безопасности в конвейер развертывания
В прошлые эпохи при работе над безопасностью приложения анализ его защиты обычно начинался после завершения разработки. Зачастую результат такого анализа — сотни страниц текста в формате PDF с перечислением уязвимых мест. Их мы отправляли командам разработки и эксплуатации. Эти проблемы обычно оставлялись без внимания, так как дедлайны подходили уже совсем близко или уязвимые места обнаруживались слишком поздно, чтобы их можно было легко исправить.
На этом шаге мы автоматизируем столько тестов защиты данных, сколько сможем, чтобы они проводились вместе со всеми другими тестами в конвейере развертывания. В идеале любое подтверждение кода и в разработке, и в эксплуатации должно приводить к запуску тестирования, даже на самых ранних стадиях проекта.
Наша цель — дать разработке и эксплуатации быструю обратную связь по их работе, чтобы они были в курсе, когда их код потенциально небезопасен. Благодаря этому они смогут быстро находить и исправлять проблемы с защитой данных в ходе ежедневной работы, накапливая полезный опыт и предотвращая будущие ошибки.
В идеале автоматизированные тесты должны запускаться в конвейере развертывания вместе с другими инструментами анализа кода.
Такие инструменты, как GauntIt, специально были созданы для работы в конвейере развертывания. Они проводят автоматические тесты безопасности для приложений, зависимостей приложений, для среды и так далее. Примечательно, что GauntIt даже помещает все свои тесты в тестовые скрипты на языке Gherkin, широко используемом разработчиками для модульного и функционального тестирования. Благодаря такому подходу тесты оказываются в уже знакомой им среде разработки. Кроме того, их можно легко запускать в конвейере развертывания при каждом подтверждении изменений кода, например при статическом анализе кода, проверке на наличие уязвимых зависимостей или при динамическом тестировании.
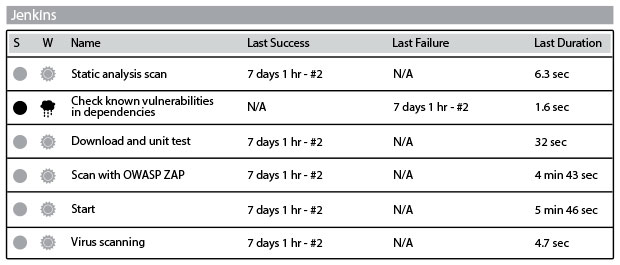
Рис. 43. Автоматизированное тестирование в системе Jenkins (источник: Джеймс Уикет и Гарет Рашгров, “Battle-tested code without the battle,” презентация на конференции Velocity 2014, выложенная на сайте , 24 июня 2014 г., )
Благодаря этим методикам у всех в потоке ценности будет мгновенная обратная связь о статусе безопасности всех сервисов и продуктов, что позволит разработчикам и инженерам эксплуатации быстро находить и устранять проблемы.
Обеспечьте безопасность приложений
В тестировании на стадии разработки часто обращают особое внимание на правильность работы приложения, концентрируясь на потоках «положительной логики». Такой тип тестирования часто называют счастливым путем (happy path), в нем проверяется обычное поведение пользователя (и иногда некоторые альтернативные пути), когда все происходит, как было запланировано, без исключений и ошибок.
С другой стороны, хорошие тестировщики, инженеры службы безопасности и специалисты по фрод-мошенничеству часто заостряют внимание на грустных путях (sad path), когда что-то идет не так, особенно если это касается ошибок, связанных с защитой данных (такие виды типичных для защиты данных событий часто в шутку называют плохими путями, или bad path).
Например, предположим, что на нашем сайте есть форма и в нее покупатель для оплаты заказа вносит данные своей платежной карты. Мы хотим найти все грустные и плохие пути, убедиться в том, что недействительные данные карты не принимаются, и предотвратить возможное использование уязвимых мест сайта, например внедрение SQL-кода, переполнение буфера и так далее.
Вместо того чтобы проводить проверку вручную, в идеале стоит сделать тесты безопасности частью автоматизированных тестовых модулей, чтобы они могли проводиться в конвейере развертывания непрерывно. Скорее всего, нам потребуются следующие виды функциональности.
• Статический анализ: это тестирование не в среде исполнения: идеальная среда — конвейер развертывания. Обычно инструмент статического анализа проверяет код программы на все возможные способы выполнения кода и ищет недочеты, лазейки и потенциально вредоносный код (иногда этот процесс называют «тестированием изнутри наружу»). Примеры инструментов статического анализа — Brakeman, Code Climate и поиск запрещенных функций (как, например, «exec()»).
• Динамический анализ: в противоположность статическому тестированию динамический анализ состоит из тестов, проводимых во время работы программы. Динамические тесты проверяют системную память, поведение функций, время ответа и общую работоспособность системы. Этот метод (иногда называемый «тестированием снаружи внутрь») имеет много общего с тем, как злоумышленники взаимодействуют с приложением. Примерами инструментов могут быть Arachni и OWASP ZAP (Zed Attack Proxy). Некоторые типы тестирования на проникновение (pentesting) можно проводить автоматически, их можно включить в динамический анализ с помощью таких инструментов, как Nmap и Metasploit. В идеале автоматизированное динамическое тестирование должно проводиться во время фазы автоматического функционального тестирования в конвейере развертывания или даже уже во время эксплуатации сервиса. Чтобы проконтролировать соблюдение требований безопасности, можно настроить инструменты вроде OWASP ZAP, так чтобы они атаковали наши сервисы через прокси-сервер, а затем изучать сетевой трафик в специальной тестовой программе.
• Проверка зависимостей: еще один тип статического тестирования, проводимый во время сборки программы в конвейере развертывания, включает в себя проверку всех зависимостей продукта на наличие бинарных и исполняемых файлов, а также проверку того, что у всех этих зависимостей (а над ними у нас часто нет контроля) нет уязвимых мест или вредоносного кода. Примеры инструментов для таких тестов — Gemnasium и bundler audit для Ruby, Maven для Java, а также OWASP Dependency-Check.
• Целостность исходного кода и подпись программы: у всех разработчиков должен быть свой PGP-ключ, возможно, созданный и управляемый в такой системе, как keybase.io. Все подтверждения кода в системе контроля версий должны быть подписаны — это легко сделать с помощью таких инструментов свободного ПО, как gpg и git. Кроме того, все пакеты, созданные во время процесса непрерывной интеграции, должны быть подписаны, а их хэш должен быть записан в централизованный сервис логирования для облегчения аудита.
Кроме того, стоит определить шаблоны проектирования для написания такого кода, злоупотребить которым будет непросто. Это, например, введение ограничений для скорости сервисов и отключение кнопок отправления ранее использованных данных. Организация OWASP публикует много полезных руководств, в том числе серию чек-листов, рассматривающих следующие вопросы:
• как хранить пароли;
• как работать с забытыми паролями;
• как работать с входом в систему;
• как избежать уязвимых мест межсайтового скриптинга (XSS).
Практический пример
Статическое тестирование безопасности в компании Twitter (2009 г.)
Презентация 10 Deploys per Day: Dev and Ops Cooperation at Flickr, подготовленная Джоном Оллспоу и Полом Хэммондом в 2009 г., известна тем, какое масштабное влияние она оказала на сообщество DevOps. Ее эквивалент для сообщества информационной безопасности — по-видимому, презентация Джастина Коллинса, Алекса Смолина и Нила Мататала, представленная на конференции AppSecUSA в 2012 г. В ней рассказывалось о трансформации работы над защитой данных в компании Twitter.Из-за стремительного роста у этой организации появилось много проблем. На протяжении многих лет, когда у сайта не было достаточного количества ресурсов, чтобы соответствовать высокому спросу пользователей, на экран выводилась страница с сообщением об ошибке. На ней был нарисован кит, поднимаемый в небо восемью птичками. Масштаб роста числа пользователей поражал воображение: между январем и мартом 2009 г. число активных пользователей Twitter выросло с 2,5 миллиона до 10 миллионов человек.У компании в этот период также были и проблемы с безопасностью. В начале 2009 г. произошло два серьезных инцидента. В январе был взломан аккаунт . Затем, в апреле, с помощью словарного перебора были взломаны аккаунты администрации Twitter. Эти события привели к тому, что Федеральная комиссия по торговле США приняла решение о том, что организация вводила своих пользователей в заблуждение относительно безопасности их аккаунтов, и издала соответствующее распоряжение.Согласно этому распоряжению, компания должна была в течение 60 дней ввести несколько мер, а затем поддерживать их 20 лет. Среди этих мер были:
• назначение сотрудников, ответственных за план информационной безопасности компании;• определение относительно предсказуемых рисков, как внутренних, так и внешних, приводящих к несанкционированному проникновению, а также создание и воплощение плана по сокращению этих рисков;• защита личной информации, причем не только от внешних источников, но и от внутренних, с примерным планом возможных источников верификации и тестирования безопасности и правильности этих реализаций.
Группа инженеров, назначенная для решения этой проблемы, должна была сделать защиту данных частью повседневной работы разработки и эксплуатации и закрыть дыры в системе безопасности — причины взломов аккаунтов.В уже упоминавшейся презентации Коллинс, Смолин и Мататал определили несколько насущных проблем.
• Предотвратить повторение ошибок в сфере безопасности: они обнаружили, что на самом деле они снова и снова исправляли все те же дефекты и уязвимые места, что и раньше. Нужно было так изменить инструменты автоматизации и всю систему работы, чтобы эти проблемы перестали повторяться.• Встроить цели безопасности в уже существующие инструменты разработки: они определили, что основным источником уязвимости были проблемы с кодом. Использовать какой-нибудь инструмент, выдающий огромный PDF-отчет, затем отправляющийся разработчикам или инженерам эксплуатации, было нерационально. Вместо этого требовалось средство, сообщающее конкретному разработчику, создавшему конкретную уязвимость, точную информацию, необходимую для устранения проблемы.• Сохранить доверие разработчиков: им надо было заслужить и сохранить доверие разработчиков. Это означало, что требовалось узнавать о случаях, когда они посылали разработчикам неверную информацию, чтобы стало возможным разобраться в причинах ложного срабатывания и впоследствии не тратить зря время разработчиков.• Поддерживать быстрый поток в информационной безопасности с помощью автоматизации: даже когда сканирование кода на наличие уязвимых мест было автоматизировано, службе безопасности все равно приходилось делать много работы вручную и тратить время на ожидание. Нужно было ждать завершения сканирования, получить большую стопку отчетов, интерпретировать результаты и затем найти ответственного за исправление недочетов. А когда код менялся, нужно было проделывать все с самого начала. Автоматизируя работу вручную, сотрудники выполняли меньше примитивных задач, сводящихся к бездумному нажатию кнопок, и могли тратить время на более творческие задачи.• Отдать все, что связано с защитой данных на самостоятельное обслуживание, если это возможно: они верили, что большинство специалистов хотят работать как можно лучше, поэтому нужно дать им доступ ко всему контексту и всей нужной информации, чтобы они могли сами исправлять ошибки.• Принять целостный подход к защите данных: их целью был анализ со всех возможных точек зрения: исходный код, среда эксплуатации и даже то, что видели их клиенты.
Первый большой прорыв произошел во время общеорганизационного недельного хакатона, когда они интегрировали статический анализ кода в процесс сборки. Команда использовала Brakeman, сканирующий приложения Ruby on Rails на наличие уязвимых мест. Целью было встроить сканирование в самые ранние стадии разработки, а не только проверять итоговый код, отправляемый в репозиторий.Результаты интеграции тестирования в процесс разработки были потрясающими. За год благодаря быстрой обратной связи о небезопасном коде и о способах его корректировки Brakeman сократил долю обнаруженных уязвимых мест на 60 %, как показано на рис. 44 (пики обычно соответствуют релизу новой версии Brakeman).
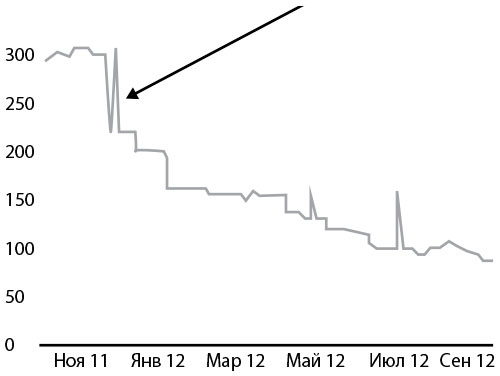
Рис. 44. Число уязвимых мест в системе безопасности, обнаруженное Brakeman
Этот пример из практики показывает, как важно встроить защиту данных в повседневную работу и в инструменты DevOps и как эффективно это может работать. Благодаря такому подходу можно сократить риски безопасности, уменьшить вероятность появления уязвимых мест в системе и научить разработчиков писать более надежный код.
Проконтролируйте безопасность системы поставок программного обеспечения
Джош Кормен отметил: как разработчики «мы больше не пишем программы для клиентов — вместо этого мы собираем их из программ с открытым исходным кодом, от которых стали очень зависимы». Другими словами, когда мы используем в продуктах какие-либо компоненты или библиотеки — как коммерческие, так и открытые, — то получаем не только их функциональность, но и их проблемы с безопасностью.
При выборе программного обеспечения мы определяем, когда наши проекты зависят от компонентов или библиотек, имеющих известные уязвимые места, и помогаем разработчикам делать этот выбор осознанно и тщательно, полагаясь на компоненты (например, на проекты с открытым исходным кодом), оперативно исправляющие бреши в защите данных. Мы также следим за разными версиями одной и той же библиотеки в сервисах, особенно за старыми, ведь в них есть уязвимые места.
Изучение нарушений конфиденциальности данных о владельцах карт наглядно показывает, насколько важна безопасность используемых компонентов. С 2008 г. ежегодный отчет Verizon PCI Data Breach Investigation Report (DBIR) считается самым авторитетным источником об утечках данных владельцев карт. В отчете 2014 г. они изучили более 85 000 утечек, чтобы лучше понять пути атак, как именно крадут данные владельцев карт и какие факторы способствуют нарушениям конфиденциальности.
Исследование DBIR показало, что в 2014 г. всего из-за десяти уязвимых мест (так называемые распространенные уязвимые места и риски — CVE (common vulnerabilities and exposures)) произошло примерно 97 % утечек информации. Возраст восьми из этих уязвимых мест был больше десяти лет.
В отчете Sonatype State of the Software Supply Chain Report 2015 г. проанализированы данные об уязвимых местах репозитория Nexus Central Repository. В 2015 г. в этом репозитории хранилось более 605 000 проектов с открытым кодом, он обслуживал более 17 миллиардов запросов на скачивание программ и зависимостей, в основном для платформы Java, от более чем 106 000 организаций.
В отчете упоминались следующие пугающие факты:
• типичная организация полагалась на 7601 программный продукт (то есть источник программного обеспечения или компонент) и использовала 18 614 разных версий (то есть частей программного обеспечения);
• из этих компонентов у 7,5 % содержались известные уязвимые места, примерно 66 % были известны более двух лет, и никаких мер по их устранению предпринято не было.
Последний факт подтверждается и в исследовании Дэна Джира и Джоша Кормэна: они показали, что из всех открытых проектов с известными уязвимыми местами, зарегистрированных в Национальной базе, проблемы с защитой были устранены только у 41 % и в среднем на выпуск патча требовалось 390 дней. Для уязвимых мест с наивысшей степенью опасности (уровень 10 по шкале CVSS) исправление заняло в среднем 224 дня.
Обеспечьте безопасность программной среды
На этом шаге мы должны сделать все возможное, чтобы наши среды были надежны и устойчивы, а связанные с ними риски — минимальны. Хотя мы уже могли создать понятные и хорошие конфигурации, нужно обязательно встроить средства мониторинга и контроля, чтобы все экземпляры в эксплуатации соответствовали этим конфигурациям.
Для этого мы создадим автоматизированные тесты, проверяющие, что у средств обеспечения устойчивости конфигураций, настроек безопасности баз данных, длин ключей и многого другого выставлены верные параметры. Кроме того, мы используем тесты для сканирования сред на известные уязвимые места.
Другое направление проверки безопасности — анализ того, как работают реальные среды (другими словами, «как есть», а не как «должно быть»). Примеры инструментов этого направления — Nmap, следящий за тем, что открыты только нужные порты, и Metasploit, проверяющий, что все типичные уязвимые места сред закрыты, например с помощью симуляции SQL-инъекций. Результаты применения этих инструментов должны храниться в общем репозитории и в процессе функционального тестирования сравниваться с предыдущими версиями. Это поможет быстро отследить любые нежелательные изменения.
Практический пример
Автоматизация проверок на соответствие требованиям с помощью Compliance Masonry, сделанное группой 18F для федерального правительства
В 2016 г. федеральные государственные учреждения США должны были потратить на информационные технологии 80 миллиардов долларов. Вне зависимости от учреждения, чтобы перевести систему в эксплуатацию, нужно было получить специальное разрешение на использование от соответствующего органа. Законы и требования в исполнительной власти состоят из десятков документов. В сумме они насчитывают более 4000 страниц, усеянных непонятными аббревиатурами вроде FISMA, FedRAMP и FITARA. Даже в системах с низким уровнем конфиденциальности, целостности и доступности должно быть проверено, задокументировано и проверено более сотни элементов. После завершения разработки обычно требуется от восьми до четырнадцати месяцев, чтобы получить разрешение.Чтобы решить эту проблему, команда 18F Управления служб общего назначения федерального правительства приняла многоэтапный план. Майк Бланд объясняет: «Группу 18F в Управлении служб общего назначения создали на волне ажиотажа от успеха восстановления сервиса ради полного изменения подхода правительства к разработке и покупке программного обеспечения».Одним из результатов работы группы стала платформа , собранная из общедоступных компонентов с открытым исходным кодом. В настоящее время сервис работает в облаке AWS GovCloud. Платформа не только сама справляется с такими задачами эксплуатации, как логирование, мониторинг, оповещения и управление жизненным циклом сервиса. Ими обычно занимаются команды эксплуатации. Она также сама следит за большей частью задач по соблюдению законодательных требований. Для приложений, запускаемых на этом сервисе, большинство компонентов, обязательных для правительственных систем, можно реализовать на инфраструктурном или платформенном уровне. После этого документировать и тестировать нужно только компоненты на уровне приложения, что значительно сокращает нагрузку по соблюдению требований и уменьшает сроки получения разрешений.Сервис AWS одобрен для использования всеми правительственными системами всех типов, в том числе требующими высокого уровня конфиденциальности, целостности и доступности. К тому времени, когда вы будете читать эту книгу, скорее всего, сервис будет одобрен для всех систем, требующих среднего уровня конфиденциальности, целостности и доступности.Кроме того, команда разрабатывает платформу для автоматического создания планов безопасности систем (system security plan, SSP), «полных описаний архитектуры системы, ее компонентов и общих средств обеспечения безопасности… обычно очень сложных и занимающих несколько сотен страниц». Они разработали прототип инструмента, названного Compliance Masonry, чтобы данные SSP можно было хранить в машиночитаемом формате YAML и автоматически преобразовывать в GitBooks- или PDF-документы.Группа 18F исповедует принципы открытой работы и выкладывает всю свою работу в свободный доступ. Вы можете найти Compliance Masonry и компоненты в репозиториях GitHub команды 18F, вы даже можете запустить свой инстанс . Работа по созданию документации для SSP ведется в тесном сотрудничестве с сообществом OpenControl.
Дополните информационную безопасность телеметрией
Маркус Сакс, один из исследователей утечек данных компании Verizon, отмечал: «На протяжении многих лет организации только месяцы спустя обнаруживали утечку данных о владельцах карт. Что еще хуже, утечка обнаруживалась не внутренними инструментами контроля, а чаще всего людьми, не работающими в компании. Обычно это был или бизнес-партнер, или клиент, заметивший мошеннические операции с картой. Одна из главных причин заключалась в том, что никто регулярно не просматривал логи».
Другими словами, внутренние средства контроля редко отслеживают нарушения безопасности вовремя или из-за слепых пятен в системе мониторинга, или потому, что никто в компании не изучает соответствующую телеметрию.
В мы обсуждали создание такой культуры: все участники потока создания ценности участвуют в распространении телеметрии, чтобы коллеги могли видеть результаты работы сервисов в эксплуатации. Кроме того, мы изучили необходимость обнаружения слабых сигналов о неполадках, чтобы можно было обнаруживать и исправлять проблемы до того, как они приведут к катастрофическим последствиям.
Сейчас же мы рассмотрим введение мониторинга, логирования и оповещений для защиты данных, а также проконтролируем их централизацию, чтобы полученную информацию было легко получать и анализировать.
Мы добьемся этого, встраивая телеметрию защиты данных в инструменты разработчиков, тестировщиков и инженеров эксплуатации, чтобы все в потоке создания ценности могли видеть, как среды и приложения работают во враждебной среде, где злоумышленники все время пытаются воспользоваться уязвимыми местами систем, получить неавторизованный доступ, встроить лазейки, воспрепятствовать авторизованному доступу и так далее.
Распространяя сведения о том, как наши сервисы ведут себя при внешней атаке, мы напоминаем всем о необходимости иметь в виду риски безопасности и разрабатывать соответствующие контрмеры в ходе ежедневной работы.
Создайте телеметрию защиты данных в приложениях
Чтобы вовремя замечать подозрительное поведение пользователей, свидетельствующее о мошенничестве или неавторизованном доступе, мы должны создать в приложениях соответствующую телеметрию.
Примерами показателей могут быть:
• успешные и неуспешные входы в систему;
• смена паролей пользователей;
• изменение адреса электронной почты;
• изменения данных кредитной карты.
Например, ранним сигналом чьей-то попытки получить неавторизованный доступ с помощью перебора (брутфорса) может быть соотношение неудачных и удачных попыток входа в систему. И, конечно же, нужно создать соответствующие средства оповещения о важных событиях, чтобы проблемы можно было быстро обнаружить и исправить.
Создайте телеметрию защиты данных в своих средах
Помимо телеметрии приложений, нам также нужно получать достаточно информации из сред, чтобы можно было отслеживать ранние сигналы о неавторизованном доступе, особенно в компонентах, работающих в неподконтрольной нам инфраструктуре (например, хостинги, облачная инфраструктура).
Мы должны следить и при необходимости получать оповещения о следующих событиях:
• изменения в операционной системе (например, в эксплуатации, в инфраструктуре разработки);
• изменение групп безопасности;
• изменения конфигураций (например, OSSEC, Puppet, Chef, Tripwire);
• изменения облачной инфраструктуры (например, VPC, группы безопасности, пользовательские привилегии);
• попытки XXS (cross-site scripting attacks, межсайтовый скриптинг);
• попытки SQLi (SQL-инъекций);
• ошибки серверов (например, ошибки 4XX и 5XX).
Также нужно проконтролировать, что у нас правильно настроено логирование и вся телеметрия отправляется в нужное место. Когда мы фиксируем атаки, то, помимо логирования самого факта атаки, можно также сохранять информацию о ее источнике и автоматически блокировать доступ, чтобы верно выбирать контрмеры.
Практический пример
Оснащение сред инструментами слежения в компании Etsy (2010 г.)
В 2010 г. Ник Галбрет работал директором по разработке в компании Etsy, в его обязанности входили контроль над информационной безопасностью, предотвращение незаконных операций и обеспечение защиты личных данных. Галбрет определил мошенничество так: «Неверная работа системы, разрешающая недопустимый или непроверяемый ввод данных в систему, который приводит к финансовым потерям, краже или потере данных, сбоям в работе системы, вандализму или атакам на другую систему».Для обеспечения защиты данных Галбрет не стал создавать отдельную систему контроля фрод-мошенничеств или новый отдел информационной безопасности. Вместо этого он встроил эти задачи в весь поток ценности DevOps.Галбрет создал телеметрию защиты данных, отображающуюся вместе со всеми другими показателями разработки и эксплуатации. Ее любой инженер Etsy мог видеть каждый день.
• Некорректное завершение программы в эксплуатации (например, ошибки сегментации, ошибки дампов памяти и так далее): «Особенно интересно было, почему некоторые процессы, запускаемые с одного из IP-адресов, снова и снова приводили к падению всей нашей среды эксплуатации. Такими же интересными были и эти “ошибки 500: внутренняя ошибка сервера”. Это были сигналы о том, что кто-то использовал уязвимое место, чтобы получить неавторизованный доступ к нашим системам, и эту дыру надо срочно заделать».• Ошибки синтаксиса баз данных: «Мы всегда искали ошибки синтаксиса баз данных в нашем коде — это были или потенциальные лазейки для SQL-инъекций, или разворачивающиеся прямо на наших глазах атаки. По этой причине ошибки синтаксиса мы исправляли незамедлительно, потому что это один из основных путей взлома систем».• Признаки SQL-инъекций: «Это был на удивление простой тест: мы просто поставили оповещение о любом вводе команды UNION ALL в полях ввода пользовательской информации, потому что это практически всегда говорит о попытке взлома с помощью внедрения SQL-кода. Мы также добавили специальный тест, чтобы подобный тип неконтролируемого пользовательского ввода не принимался нашей системой».
На рис. 45 показан пример графика, доступного каждому разработчику компании. На нем отображается число потенциальных атак с помощью SQL-инъекций в среде эксплуатации. Как отмечает Галбрет, «ничто так не помогает разработчикам понять враждебность среды эксплуатации, как возможность видеть атаки на их код в реальном времени».
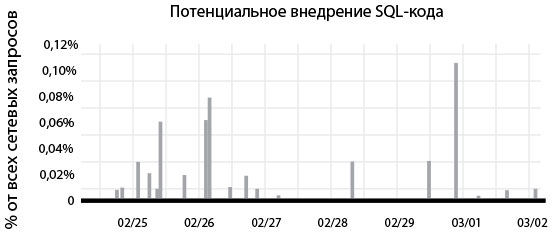
Рис. 45. Разработчики Etsy могли видеть попытки SQL-инъекций в систему мониторинга Graphite (источник: “DevOpsSec: Appling DevOps Priciples to Security, DevOpsDays Austin 2012”, , опубликовано Ником Галбретом, 12 апреля 2012 г., )
Он также добавляет: «Одним из результатов введения этого графика стало то, что разработчики осознали: атаки происходят все время! И это было потрясающе, потому что их образ мышления изменился, они стали думать о безопасности кода в процессе его написания».
Защитите конвейер развертывания
Инфраструктура, поддерживающая непрерывную интеграцию и непрерывное развертывание, также становится возможной целью атаки. Например, если злоумышленник взламывает серверы, на которых работает конвейер развертывания, где содержатся параметры доступа к системе контроля версий, то он может украсть наш исходный код. Что еще хуже, если у конвейера есть доступ с правом записи, взломщик может внести вредоносные изменения в репозиторий контроля версий и, следовательно, внести вредоносные правки в приложения и сервисы.
Как отметил Джонатан Клаудиус, бывший старший тестировщик безопасности в организации TrustWave SpiderLabs, «серверы непрерывной сборки приложений и тестирования работают потрясающе, я сам их использую. Но я начал задумываться о том, как использовать CI и CD для внедрения вредоносного кода. Что привело меня к вопросу: где хорошее место для того, чтобы спрятать вредоносный код? Ответ очевиден: в юнит-тестах. На них никто не смотрит, и они запускаются каждый раз, когда кто-то отправляет свой код в репозиторий».
Это наглядно демонстрирует, что для адекватной защиты целостности приложений и сред нужно также позаботиться о защите конвейера развертывания. Среди возможных рисков — разработчики могут написать код, разрешающий неавторизованный доступ (с этим можно справиться с помощью тестирования и рецензирования кода, а также с помощью тестов на проникновение), или неавторизованные пользователи могут получить доступ к нашему коду или среде (это исправляется проверкой конфигураций на соответствие известным правильным образцам и эффективным созданием патчей).
Кроме того, чтобы защитить конвейер непрерывной сборки, интеграции или развертывания, можно ввести такие стратегии:
• защита серверов непрерывной сборки и интеграции и создание механизмов для их автоматического восстановления, чтобы их нельзя было взломать; все точно так же, как и для инфраструктуры, поддерживающей ориентированные на клиентов сервисы;
• анализ и оценка всех изменений в системе контроля версий, или с помощью парного программирования во время подтверждения кода, или с помощью рецензирования кода между подтверждением кода и добавлением его в основную ветку. Так в серверы непрерывной интеграции не будет поступать неконтролируемый код (например, тесты могут содержать вредоносный код, делающий возможным неавторизованный доступ);
• оснащение репозиториев инструментами для обнаружения подозрительных API-вызовов в коде тестов (например, тесты, требующие доступа к файловой системе или сетевым соединениям), добавляемых в репозиторий, возможно, с карантином подозрительного кода и его немедленным анализом;
• предоставление для каждого процесса непрерывной интеграции своего изолированного контейнера или виртуальной машины;
• проверка того, что параметры доступа контроля версий, используемые системой непрерывной интеграции, разрешают только чтение.
Заключение
В этой главе мы описали пути интегрирования целей защиты данных во все этапы ежедневной работы сотрудников. Для этого нужно встроить компоненты информационной безопасности в уже созданные механизмы и проконтролировать, что все запрашиваемые среды достаточно укреплены, а связанные с ними риски — минимизированы. Эти цели можно выполнить с помощью встраивания тестирования защиты данных в конвейер развертывания и создания соответствующей телеметрии в тестовых и производственных средах. Благодаря этим мерам увеличиваются как продуктивность разработчиков и инженеров эксплуатации, так и общий уровень безопасности. На следующем шаге мы рассмотрим, какими способами можно защитить наш конвейер развертывания.
Назад: Введение
Дальше: Глава 23. Безопасность конвейера развертывания

