Книга: Руководство по DevOps
Назад: Глава 17. Встройте основанную на гипотезах разработку и A/B-тестирование в свою повседневную работу
Дальше: Часть V. Третий путь: методики непрерывного обучения и экспериментирования
Глава 18. Создайте процессы проверки и координации для улучшения качества текущей работы
В предыдущих главах мы создали систему телеметрии, необходимую для обнаружения и решения проблем в эксплуатации и на всех стадиях процесса непрерывного развертывания, а также быстрые циклы обратной связи от клиентов для получения нового опыта — опыта, пробуждающего вовлеченность в процесс и ответственность за удовлетворенность клиентов и работу всех компонентов сервиса. Все это помогает добиваться успеха.
Цель этой главы — помочь разработчикам и отделу эксплуатации сократить риск производственных изменений до того, как они сделаны. Обычно, анализируя изменения перед новым развертыванием, мы полагаемся на отзывы, проверки и согласование прямо перед самым развертыванием. Часто согласование дается чужими командами, слишком далекими от нашей работы. Принять обоснованное решение о рискованности правок затруднительно, а время на получение всех разрешений удлиняет сроки внесения изменений.
Процесс проверки работы коллегами (peer review) сервиса GitHub — яркий пример того, как критическое рассмотрение может улучшить качество, сделать развертывание более безопасным и стать частью повседневной работы. Специалисты сервиса GitHub стали первопроходцами практики pull request (запроса на внесение изменений), одной из самых популярных форм проверки кода коллегами как в разработке, так и в эксплуатации.
Скотт Чейкон, директор по информационным технологиям и один из основателей компании GitHub, писал на своем сайте, что запросы на внесение изменений — механизм, позволяющий инженерам сообщать об изменениях, отправляемых в репозиторий GitHub. Когда запрос отправлен, заинтересованные лица могут оставить отзыв о предлагаемых правках, обсудить потенциальные модификации и даже, если потребуется, предложить расширение кода на основе предлагаемых изменений. Программисты, отправляющие запрос, часто запрашивают «+1», «+2» и так далее в зависимости от того, сколько отзывов нужно.
На GitHub запросы на внесение изменений — также механизм для развертывания кода в производственную среду через набор практик, называемых пользователями «потоком GitHub». Так программисты запрашивают рецензии, собирают обратную связь, на ее основе вносят изменения в код и сообщают о развертывании кода в производственной среде (то есть в ветку master).

Рис. 40. Комментарии и предложения к запросу внесение изменений, GitHub (источник: Скотт Чикон, “GitHub Flow”, сайт , 31 августа 2011 г., )
Поток GitHub состоит из пяти этапов.
1. Чтобы начать работать над чем-то новым, инженер создает соответствующую именованную ветку от «master» (например, «new-oauth2-scopes»).
2. Инженер работает только с этой веткой, регулярно отправляя свой код на сервер.
3. Когда ему нужна обратная связь или помощь или когда он считает, что ветка готова к слиянию с master, он отправляет запрос на внесение изменений.
4. Когда инженер получает рецензии и необходимые согласования новой функциональности, он может добавить свои изменения в ветку «master».
5. Когда правки внесены и отправлены в главную ветку, инженер развертывает их в производственную среду.
Эти практики, встраивающие рецензирование и координацию в процесс ежедневной работы, позволили компании GitHub быстро и надежно поставлять на рынок продукты высокого качества и высокой надежности. Например, в 2012 г. сотрудники провели 12 062 развертывания — потрясающее количество. В частности, 23 августа на общекорпоративной конференции придумали и обсудили много новых замечательных идей, и это был самый загруженный день этого года: сотрудники и пользователи провели 563 сборки и 175 успешных развертываний. Все благодаря механизму запросов на внесение изменений.
В этой главе мы будем постепенно разбирать практики, используемые в GitHub, чтобы избежать зависимости от периодических проверок и согласований и перейти к комплексному и непрерывному рецензированию кода в процессе ежедневной работы. Наша цель — сделать так, чтобы разработка, IT-эксплуатация и служба информационной безопасности перешли к модели постоянного сотрудничества, чтобы вносимые в наши системы изменения работали надежно, безопасно и так, как было запланировано.
Опасность процесса согласования изменений
Провал компании Knight Capital — одна из самых показательных ошибок внедрения ПО в недалеком прошлом. Пятнадцатиминутная ошибка развертывания — причем инженеры не могли отключить рабочие сервисы — привела к потере 440 миллионов долларов. Финансовые убытки поставили под удар функционирование организации, в результате чего владельцы были вынуждены быстро продать компанию, чтобы она могла продолжать деятельность без риска для финансовой системы.
Джон Оллспоу замечает, что, когда происходят такие резонансные провалы, как ошибка развертывания Knight Capital, обычно есть две противоречащие фактам интерпретации, почему же эти сбои вообще могли случиться.
Первая интерпретация гласит, что авария произошла из-за сбоя в системе контроля изменений. Звучит правдоподобно, поскольку мы можем представить ситуацию, когда лучшие методики контроля могли бы отследить такой риск раньше и не допустили бы отправки изменений в производственную среду. А если бы они и не смогли предотвратить развертывание плохого кода, то мы быстрее обнаружили бы ошибку и сразу же предприняли шаги по восстановлению системы.
Вторая интерпретация заключается в том, что провал случился по вине сбоя тестирования. Это тоже кажется правдоподобным. Чем лучше методы тестирования, тем больше шансы отследить неполадки в самом начале и отменить рискованное развертывание. Или как минимум мы могли бы быстрее заметить ошибку и вернуть систему в рабочее состояние.
Удивительно, но факт: в компаниях с низким уровнем доверия и культурой, основанной на контроле и управлении, частый результат жесткого контроля над изменениями и тестированием — высокая вероятность того, что такие проблемы повторятся снова, с еще более печальным исходом.
Джин Ким (соавтор этой книги) называет осознание того, что контроль над изменениями и тестирование могут иметь совершенно противоположный результат, «одним из важнейших моментов моей профессиональной карьеры. Это озарение было результатом одного разговора в 2013 г. с Джоном Оллспоу и Джезом Хамблом о провале Knight Capital. Я начал сомневаться в некоторых своих основополагающих убеждениях, сформированных за последние десять лет, особенно если учесть мое аудиторское образование».
Ким продолжает: «Как бы печально это ни было, этот момент был для меня ключевым. Они не только убедили меня в том, что они правы, но мы также протестировали эти предположения в обзоре 2014 State of DevOps Reports, что привело ко многим потрясающим открытиям. Построение культуры с высоким уровнем доверия — наверное, самый большой вызов для менеджмента в этом десятилетии».
Потенциальные опасности чрезмерного контроля над изменениями
Традиционный контроль над изменениями может привести к непредусмотренным результатам, например к долгим срокам разработки продукта, сокращению силы и скорости обратной связи с этапа развертывания кода. Чтобы понять, как это происходит, рассмотрим часто применяемые средства управления во время провала контроля над изменениями:
• добавление новых вопросов в форму запроса на внесение изменений;
• требование большего числа разрешений. Например, еще один уровень согласования в управленческой иерархии (допустим, вместо разрешения директора по эксплуатации теперь нужно разрешение от директора по информационным технологиям) или других заинтересованных лиц (например, системных администраторов, комиссий контроля по архитектуре и так далее);
• требование большего количества времени для разрешения на внесение изменений, чтобы правки оценивались и анализировались как должно.
Такие методы контроля часто добавляют помехи в процесс развертывания, увеличивая количество лишних шагов, нужных согласований и время развертывания. Все это, как мы знаем, сокращает вероятность благоприятного итога и для разработчиков, и для отдела эксплуатации. Излишний контроль также замедляет обратную связь о качестве нашей работы.
Один из важнейших постулатов системы производства Toyota — «самые близкие к проблеме исполнители обычно знают о ней больше всего». Это особенно заметно, если выполняемая работа или рабочая система становятся более сложной и динамичной, что характерно как раз для потоков создания ценности DevOps. В таких случаях потребность в разрешении руководителей, находящихся все дальше и дальше от текущей задачи, может уменьшить вероятность благоприятного исхода. Как уже не раз было доказано, чем больше расстояние между сотрудником, выполняющим работу (то есть тем, кто вносит какие-либо изменения), и человеком, принимающим решение о ее необходимости (то есть тем, кто выдает разрешение на внесение изменений), тем хуже результат.
В обзоре 2014 State of DevOps Reports компании Puppet Labs одним из ключевых открытий было то, что высокоэффективные организации больше полагались на рецензии коллег, а не на внешнее одобрение изменений. На рис. 41 показано: чем больше компании зависят от получения разрешений, тем хуже их результаты и в отношении стабильности (среднее время восстановления сервиса и доля неудачных изменений), и в отношении производительности (время на развертывание, частота развертываний).
Производительность в IT
Рецензии коллег vs Получение разрешений
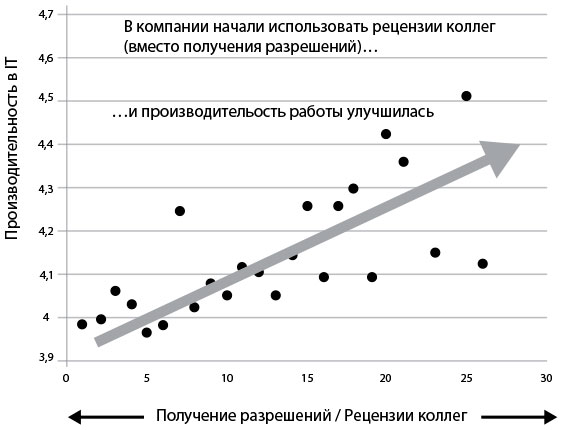
Рис. 41. Производительность организаций с рецензированием кода выше, чем у организаций, где требуется разрешение на внесение изменений (источник: отчет DevOps Survey of Practice, 2014 г., компания Puppet Labs)
Во многих организациях консультативные советы по изменениям играют важную роль в координации и управлении процессом внедрения, но их работа не должна сводиться к оценке каждой правки кода. Стандарт ITIL тоже не требует такого подхода.
Чтобы понять, почему так происходит, представьте, в каком затруднительном положении оказываются члены консультативных советов. Им нужно рецензировать сложные изменения, состоящие из тысяч строк кода, что написаны сотнями программистов.
Одна крайность в том, что, просто читая пространное описание правок или проверяя все пункты чек-листа, мы не сможем предсказать, будут ли изменения успешными. Другая — в том, что тщательный осмотр под микроскопом тысяч строк кода вряд ли раскроет что-то новое. Одна из причин этого — сама природа изменений в сложных системах. Даже инженеры, каждый день работающие с базой исходного кода, часто бывают удивлены побочными эффектами того, что казалось обычной правкой с низким уровнем риска.
Все эти причины свидетельствуют, что нужно создать эффективные практики контроля, более близкие к рецензированию кода коллегами и сокращающие зависимость от внешних органов, одобряющих или запрещающих внесение изменений. Кроме того, нам нужно эффективно координировать и планировать изменения. Этой темой мы и займемся в двух следующих параграфах.
Обеспечьте условия для координации и планирования изменений
Всякий раз, когда над взаимозависимыми системами работают несколько групп, необходимо как-то согласовывать вносимые изменения, чтобы они не влияли друг на друга (например, группируя их по какому-либо принципу или выстраивая в очередь). В общем случае чем более независимы компоненты архитектуры, тем меньше нам нужно общаться и координироваться с другими командами. Когда архитектура — действительно сервис-ориентированная, группы разработчиков могут вносить изменения с большей долей автономии. Локальные правки вряд ли станут причиной глобальных сбоев.
Однако даже в слабо связанной архитектуре, когда много команд проводят сотни независимых развертываний в день, есть риск того, что изменения будут мешать друг другу (например, при одновременном A/B-тестировании). Для уменьшения этих рисков можно использовать чаты, чтобы оповещать о планируемых правках и проактивно обнаруживать возможные накладки.
Для более сложных систем и систем с сильно связанной архитектурой возникает необходимость планирования изменений: представители команд собираются вместе, но не для того, чтобы одобрить правки или выдать на них разрешение, а чтобы составить расписание и порядок внесения изменений для снижения числа возможных неприятностей.
Однако в некоторых областях, таких как изменения в глобальной инфраструктуре (например, исправления в коммутаторе ядра сети), риск всегда будет выше. Для них нужны будут специальные профилактические меры: избыточность, перехват управления при отказе, комплексные испытания и (в идеале) симуляция.
Введите практику рецензирования изменений
Вместо того чтобы требовать разрешения на развертывание у внешнего арбитра, можно побуждать инженеров рецензировать работу своих коллег. В разработке эта практика носит название анализ кода, но ее можно приспособить и для любых других изменений в приложениях или окружении, включая серверы, сеть и базы данных. Суть метода в том, чтобы кто-нибудь из инженеров, близких к конкретной задаче, тщательно рассмотрел и проанализировал предлагаемые правки. Такое рецензирование улучшает качество вносимых исправлений, а также стимулирует взаимное обучение и улучшение навыков.
Логичный момент, когда нужно проводить анализ, — перед отправкой кода в систему управления кодом, где изменения потенциально могут привести к глобальному сбою. Как минимум рецензирование должен проводить ваш непосредственный коллега, но для областей с более высоким уровнем риска, например для баз данных или критичных для бизнеса компонентов со слабым покрытием автоматизированными тестами, может потребоваться более глубокий анализ эксперта (например, инженера по информационной безопасности или инженера по базам данных) или же несколько разных рецензий от разных специалистов («+2» вместо «+1»).
Принцип небольших кусков кода применяется и в анализе кода. Чем больше размер разбираемого фрагмента кода, тем больше времени нужно, чтобы его понять, и тем больше ответственность на проверяющем сотруднике. Как отмечает Рэнди Шуп, «есть нелинейная зависимость между величиной вносимых изменений и потенциальным риском внедрения этих изменений: когда вы переходите от десяти строк кода к сотне, риск вырастает больше чем в десять раз, и так далее». Поэтому так важно, чтобы разработчики были заняты небольшими, постепенными приращениями кода, а не одной многолетней веткой компонента функциональности.
Кроме того, наша способность осмысленно критиковать правки кода уменьшается с ростом объема этих правок. Как написал в своем твиттере Гирей Озил, «попросите программиста проверить десять строчек кода, и он найдет десять проблем. Попросите его проверить сотню строчек, и он скажет, что все хорошо».
Принципы рецензирования кода включают в себя следующее:
• у каждого сотрудника должен быть кто-нибудь, кто проверяет его исправления (и в коде, и в окружении) перед отправкой в основной код проекта;
• все сотрудники должны следить за потоком правок своих коллег, чтобы можно было заметить и проанализировать потенциальные конфликты изменений;
• определите, какие изменения считаются очень рискованными: они могут потребовать анализа эксперта в этой области (например, исправления в базах данных, такие важные с точки зрения безопасности модули, как подтверждение прав доступа, и так далее);
• если кто-то собирается внести слишком объемные для понимания правки — другими словами, если даже после нескольких прочтений вы не можете понять, к каким последствиям они приведут, или вам нужно просить о разъяснениях, — их нужно разделить на более мелкие части, понятные с первого взгляда.
Чтобы убедиться в том, что мы не просто механически штампуем бессмысленные рецензии, можно проанализировать статистику по рецензиям, чтобы найти соотношение между принятыми и отвергнутыми правками. Возможно, полезно провести выборочное исследование конкретных рецензий.
Анализ кода может принимать несколько разных форм.
• Парное программирование. Программисты работают парами (см. раздел ).
• «Чересплечное» программирование. Один программист наблюдает за работой другого, когда тот проходит по написанному им коду.
• Передача по электронной почте. Система управления исходным кодом автоматически рассылает код на рецензию после того, как программист ставит пометку о внесении изменений
• Анализ кода с помощью инструментов. Авторы и рецензенты используют специально разработанные для обзора кода инструменты (например, Gerrit, запросы на внесение изменений GitHub и так далее) или средства, предоставляемые репозиториями исходного кода (например, GitHub, Mercurial, Subversion, а также такие платформы, как Gerrit, Atlassian Stash и Atlassian Crucible).
Тщательный анализ изменений эффективен для обнаружения пропущенных ошибок. Рецензирование кода поможет увеличить частоту внесения правок и развертываний. Оно также поддерживает модель разработки и внедрения на основе единой ветви кода (trunk-based development) и непрерывной поставки. Рассмотрим это подробнее на следующем примере из практики.
Практический пример
Рецензирование кода в компании Google (2010 г.)
Компания Google — прекрасный пример организации, использующей разработку на основе единой ветви кода и непрерывную масштабируемую поставку. Как отмечалось ранее, Эран Мессери рассказывал, что в 2013 г. организация процессов в Google позволяла более чем 13 000 разработчиков работать в своих ветвях над одним и тем же исходным кодом, совершая более 5500 коммитов в неделю. Число развертываний за неделю доходило до нескольких сотен. Согласно данным 2010 г., каждую минуту в основную ветку кода отправлялось более двадцати правок, из-за таких темпов каждый месяц обновлялось 50 % кода.Для такой организации от команд разработчиков требуются значительная дисциплина и обязательное рецензирование кода, покрывающее следующие области:
• легкая читаемость кода (нужны руководства по стилю оформления кода);• назначение ответственных за поддеревья кода для поддержания единообразия и контроля над отсутствием ошибок;• прозрачность кода и сотрудничество в работе над одним и тем же кодом между разными командами.
На рис. 42 показано, как время на рецензирование кода зависит от размера внесенных изменений. На оси X отмечается размер правок, на оси Y — время, затраченное на проверку кода. В общем случае чем больше объем изменений, тем дольше проходит анализ. Точки в верхнем левом углу обозначают более сложные и потенциально рискованные изменения, требующие более глубокого обдумывания и обсуждения.
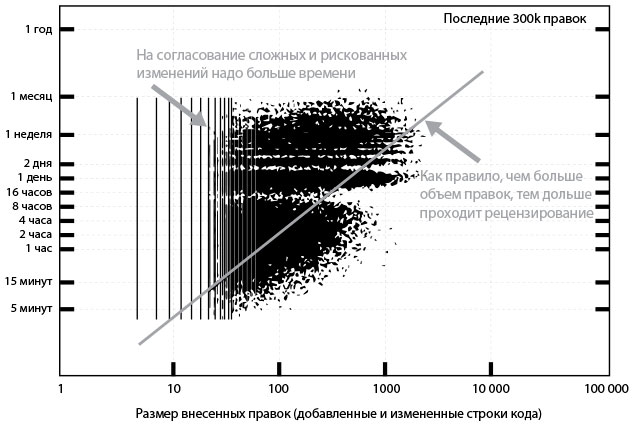
Рис. 42. Длительность рецензирования в зависимости от размера кода в компании Google (источник: Ашиш Кумар, “Development at the Speed and Scale of Google,” презентация на QCon, Сан-Франциско, CA, 2010. )
Чтобы решить техническую проблему компании Google, Рэнди Шуп, в то время занимавший должность технического директора организации, начал свой личный проект. Он отмечал: «Я работал над этим проектом неделями и наконец решился попросить специалиста в этой области проверить мой код. Это было примерно три тысячи строк. Через них рецензент продирался несколько дней. После чего он попросил: “Пожалуйста, больше так не делай”. Я был очень благодарен ему, что он нашел время помочь мне. Именно тогда я и понял, как встроить рецензирование кода в ежедневную работу».
Потенциальные опасности тестирования преимущественно вручную и заморозки изменений
Теперь, когда мы ввели рецензирование кода, уменьшающее риски, сокращающее время на введение изменений и способствующее непрерывной масштабируемой поставке, как мы выяснили на примере компании Google, перейдем к тому, как тестирование может обернуться против нас. Когда происходят ошибки тестирования, типичная реакция — провести еще больше тестов. Однако если мы просто проводим тесты в конце нашего проекта, то можем ухудшить результаты.
Это особенно верно, если мы проводим тестирование вручную, поскольку оно более медленно и трудоемко. «Дополнительное тестирование» обычно требует больше времени, чем предполагалось, что сокращает частоту развертываний и повышает объем единовременно вносимых правок кода. А мы уже знаем и из теории, и из практики, что большие объемы нового развертываемого кода снижают шансы на благоприятный исход и увеличивают значение MTTR и число сбоев — совсем не то, что нам нужно.
Вместо того чтобы тестировать объемные куски кода за счет замораживания всех других правок, мы хотим встроить тестирование в процесс повседневной работы как часть непрерывного потока на стадии внедрения, а также увеличить частоту развертываний. Благодаря этому система будет изначально качественной, что позволит тестировать, развертывать и выпускать код еще более мелкими порциями, чем раньше.
Введите практику парного программирования, чтобы улучшить качество изменений
Парное программирование — ситуация, когда два программиста вместе работают на одном рабочем месте. Этот метод был популяризован в ранних 2000-х гг. в таких направлениях, как экстремальное программирование (Extreme Programming) и гибкая методология разработки (Agile). Как и рецензирование кода, этот способ появился в разработке, но он также применим и к деятельности любого инженера в потоке создания ценности. Далее термины парная работа и парное программирование будут использоваться как синонимы, чтобы подчеркнуть, что этот метод подходит не только разработчикам.
В одном из наиболее частых подходов один инженер ведущий — он пишет код. Другой — штурман, наблюдатель или наводчик — анализирует и оценивает работу непосредственно во время выполнения. В процессе наблюдения он может обдумать стратегическое направление, придумать новые идеи улучшений и предугадать возможные проблемы. Это позволяет ведущему сосредоточить все внимание на тактических задачах, штурман страхует его от ошибок и указывает дальнейшее направление движения. Если у членов пары разные специальности, то побочный эффект — ненамеренное обучение друг друга навыкам как через ситуативную тренировку, так и с помощью обмена методиками и неочевидными способами решения проблем.
Еще один подход к парному программированию воплощает принципы основанной на тестировании разработки (test-driven development, TDD): один инженер пишет автоматизированные тесты, а второй — собственно приложение. Джефф Этвуд, один из основателей сайта Stack Exchange, пишет: «Я все время думаю о том, что парное программирование — всего лишь рецензирование кода на стероидах… Преимущество парного программирования — в его захватывающей непосредственности: невозможно игнорировать рецензента, если он сидит рядом с тобой».
Джефф продолжает: «Большинство людей пассивно уклонятся от необходимости оценивать чужой код, если у них имеется такая возможность. В парном программировании это невозможно. Каждая половина пары должна понимать код, здесь и сейчас, прямо во время его написания. Работа в паре может идти через силу, но она также поднимает коммуникацию на высочайший уровень. Достичь его иначе просто невозможно».
В 2001 г. Лори Уильямс провела исследование, где показала, что «программисты в паре работают на 15 % медленнее, а объем кода без ошибок увеличивается с 70 до 85 %. Поскольку тестирование и отладка часто во много раз дороже, чем создание первоначального кода, эти результаты впечатляют. Пары обычно рассматривают больше альтернатив, чем программисты-одиночки, и в результате их решения проще и поддерживать их легче. Они также раньше замечают ошибки проектирования». Лори Уильямс также отмечает, что 96 % ее респондентов сообщили, что работа в паре понравилась им больше, чем работа в одиночку.
У парного программирования есть дополнительное преимущество: оно способствует распространению знаний в компании и увеличивает обмен информацией в команде. Когда более опытные инженеры наблюдают за тем, как их менее опытные коллеги пишут код, обучение проходит гораздо эффективнее.
Практический пример
Замена неэффективного рецензирования кода парным программированием в организации Pivotal Labs (2011 г.)
Элизабет Хендриксон, технический директор организации Pivotal Software, Inc. и автор книги Explore It!: Reduce Risk and Increase Confidence with Exploratory Testing, много раз говорила, что каждая команда должна нести ответственность за качество своего труда, вместо того чтобы возлагать ответственность на отделы. Она утверждает, что такой подход не только повышает качество результата, но также увеличивает количество изменений.В своей презентации на конференции DevOps Enterprise Summit в 2015 г. она рассказала, что в 2011 г. в Pivotal было два метода оценки кода: парное программирование (каждая строчка кода проверялась двумя людьми) и рецензирование кода с помощью программного обеспечения Gerrit (каждая фиксация кода должна была получить «+1» от двух человек, прежде чем отправиться в основной код проекта).Элизабет заметила, что с Gerrit есть одна проблема: иногда программисты ждали рецензии целую неделю. Что хуже, у опытных программистов «появлялось раздражение и опускались руки оттого, что они не могли внести в код простейшие изменения, потому что мы непреднамеренно создали невыносимые заторы в работе».Она пожаловалась: «Старшие инженеры единственные способны ставить “+1” правкам кода, но у них много других обязанностей, им часто все равно, над какими проблемами бьются младшие разработчики и какая у них производительность. Получилась ужасная ситуация: пока ты ждешь рецензии на изменения, другие разработчики отправляют код в систему. Целую неделю приходилось загружать внесенные другими изменения на свой ноутбук, еще раз прогонять все тесты, чтобы убедиться, что все удачно, и иногда отправлять код на рецензию заново!»Чтобы решить эту проблему и устранить все эти задержки, в компании решили полностью избавиться от рецензирования кода в Gerrit. Вместо него для внесения правок в систему нужно было использовать парное программирование. Благодаря этому программисты сократили время на оценку кода с недель до нескольких часов.Элизабет Хендриксон тем не менее отмечает, что рецензирование кода отлично работает во многих организациях. Однако оно требует наличия культуры: анализ кода должен цениться так же высоко, как и его создание. Когда такой культуры еще нет, парное программирование может служить важным промежуточным шагом.
Оценка эффективности pull request процессов
Поскольку рецензирование кода — важное средство контроля, мы должны уметь определять, эффективно оно или нет. Один метод заключается в том, чтобы рассмотреть сбои и оценить, можно ли что-то изменить в процессе рецензирования, чтобы этих сбоев можно было избежать.
Другой способ был предложен Райаном Томайко, директором по информационным технологиям и сооснователем GitHub, а также одним из авторов идеи запросов на внесение изменений. Когда его попросили описать разницу между хорошим запросом на внесение изменений и плохим, он сказал, что результаты не имеют к этому никакого отношения. У плохого запроса недостаточно контекста для читателя и нет описания, что эта правка должна делать, например, если сопроводительный текст выглядит как «Исправление проблемы #3616 и #3841».
Этот реальный внутренний запрос организации GitHub Райан Томайко раскритиковал: «Скорее всего, его написал один из новых сотрудников нашей компании. Во-первых, в нем не было указано ни одного инженера. Как минимум программист должен указать своего наставника или специалиста в той области, к которой относится правка, чтобы рецензию провел компетентный человек. Но вдобавок нет никакого пояснения, что это за изменение, почему оно важно или как размышлял его автор».
С другой стороны, на вопрос о хорошем запросе, отражающем эффективный процесс рецензирования, Томайко быстро перечислил важнейшие элементы: должно быть достаточно деталей о том, зачем нужно это изменение, как оно было проделано, а также его возможные риски и меры противодействия этим рискам».
Райан Томайко также обращает внимание на хороший анализ вносимого изменения в контексте запроса: часто в нем акцентируются дополнительные риски, идеи по более подходящим способам внедрения изменений и по смягчению возможных рисков и так далее. И если во время развертывания происходит что-то плохое или неожиданное, информация добавляется в запрос вместе со ссылкой на проблему. Обсуждение проходит без поиска виноватых; вместо него проходит открытый и непредвзятый разговор о том, как предотвратить такие проблемы в будущем.
В качестве примера Томайко приводит другой внутренний запрос GitHub касательно миграции баз данных. Он был длиной в несколько страниц, содержал обширный анализ возможных рисков и завершался следующей фразой автора запроса: «Я сейчас отправляю эту правку в исходный код. Сборки этой ветки сейчас падают, потому что на CI-серверах (серверах непрерывной интеграции) не хватает одного столбца» (ссылка на лог падения MySQL).
Автор правки потом извинился за сбой и рассказал, какие условия и ошибочные предположения привели к неполадке, а также предложил список мер для предотвращения этой проблемы в будущем. Все это сопровождалось страницами разбора и анализа. Читая этот запрос, Томайко улыбнулся: «Вот это отличный запрос!»
Как описано выше, мы можем оценить эффективность процессов рецензирования, проанализировав выборочные запросы как из всей совокупности запросов на внесение изменений, так и только из имевших отношение к сбоям.
Бесстрашно избавляйтесь от бюрократических процессов
Пока что мы обсуждали рецензирование кода и парное программирование, позволяющие увеличить качество результатов и избавиться от необходимости получать разрешения от внешних структур. Однако у многих компаний до сих пор есть процессы одобрения изменений. На них требуются месяцы. Эти процессы могут значительно увеличивать время создания продукта, что не только не дает быстро выполнять заказы клиентов, но также потенциально препятствует достижению целей организации. Если такое все же происходит, нужно изменить процессы внутри компании, чтобы цели достигались быстрее и безопаснее.
Как отмечает Адриан Коккрофт, «вывешивать на широкое обозрение стоит отличный показатель — сколько встреч и тикетов нужно, чтобы сделать один релиз. Цель — неуклонно сокращать усилия инженеров на создание продукта и поставку его заказчикам».
Точно так же Тапабрата Пал, сотрудник компании Capital One, описал одну программу под названием Got Goo?. Специальная команда устраняет всевозможные препятствия, включая инструменты, процессы и одобрение, мешающие завершению процесса. Джейсон Кокс, старший директор по проектированию систем компании Disney, в презентации на конференции DevOps Enterprise Summit 2015 г. описал программу Join the Rebellion. Ее цель — избавить от тяжелого труда и всевозможных препятствий.
В 2012 г. в компании Target комбинация процесса принятия новых технологий (TEAP) и ведущей комиссии контроля по архитектуре (LARB) привела к тому, что на одобрение использования новой технологии требовалось очень много времени. Чтобы предложить новую технологию, например иную базу данных или систему мониторинга, нужно было заполнить форму TEAP. Эти предложения затем оценивались, и стоящие заносились в список вопросов ежемесячных встреч LARB.
Хизер Микман и Росс Клэнтон, директор по разработке и директор по эксплуатации в Target, Inc. соответственно, помогали внедрять методы DevOps в своей компании. Микман нашла необходимую для одного проекта технологию (в данном случае Tomcat и Cassandra). Решение LARB гласило, что в данный момент команда эксплуатации не может ее поддерживать. Однако Микман была настолько убеждена в необходимости этих систем, что она предложила, чтобы за поддержку, интеграцию, доступность и безопасность этой технологии отвечала ее команда разработчиков, а не команда эксплуатации.
«Пока это предложение рассматривалось, я хотела понять, почему процесс TEAP-LARB занимает столько времени, и я использовала методику “пяти почему”… Она в конце концов привела меня к вопросу, зачем вообще нужен TEAP-LARB. Удивительно, но никто не мог на него ответить, кроме разве что расплывчатых соображений о том, что нам нужен какой-то контроль. Многие знали, что несколько лет назад произошла какая-то катастрофа и она ни за что не должна повториться снова. Но никто не мог точно вспомнить, что же это была за катастрофа».
Микман отмечает, что проходить через этот процесс ее группе было необязательно, если они соглашались быть ответственными за поддержание новой технологии. Она также добавляет: «Я дала всем знать, что все новые технологии, поддержанные моей командой, согласовывать с TEAP-LARB не нужно».
В результате систему управления базами данных Cassandra в Target успешно внедрили. Более того, процесс TEAP-LARB впоследствии был отменен. В благодарность за устранение барьеров для введения новых технологий команда Хизер Микман вручила ей награду за профессиональные достижения.
Заключение
В этой главе мы обсудили, как вводить в работу новые методики, повышающие качество вносимых изменений, сокращающие риск неудачных развертываний и уменьшающие зависимость от процессов согласования и одобрения изменений. Примеры из практики компаний GitHub и Target показывают: эти методики не только улучшают наши результаты, но также значительно сокращают время на создание продуктов и увеличивают производительность разработчиков. Для всего этого требуется культура высокого доверия.
Вот история об одном младшем инженере, рассказанная Джоном Оллспоу. Этот инженер спросил, можно ли отправить в развертывание небольшую правку в HTML-коде, и Оллспоу ответил: «Я не знаю». Затем он спросил: «Кто-нибудь просмотрел твой код? Ты знаешь, кого лучше всего спрашивать об изменениях такого типа? Сделал ли ты все возможное, чтобы досконально убедиться, что эти изменения будут вести себя в эксплуатации именно так, как и планировалось? Если да, то не спрашивай меня — просто внеси правки, и все».
Таким ответом Оллспоу напомнил инженеру, что за качество изменений отвечает только он сам: если она сделал все, что мог, чтобы убедиться в том, что все работает правильно, тогда ему не нужно было просить одобрения, он мог просто внести свои правки.
Создание условий, когда авторы идей сами отвечают за их качество, — важная часть производительной культуры высокого доверия. Ее мы и хотим построить. Кроме того, такие условия позволяют создать более безопасную систему, где все помогают друг другу достичь целей, преодолевая любые препятствия.
Заключение части IV
В части IV мы показали, что петли обратной связи позволяют нам достигать общих целей, замечать проблемы на стадии их возникновения и с помощью быстрого обнаружения и восстановления гарантировать, что элементы функциональности не только работают так, как планировалось, но и способствуют выполнению целей организации и взаимному обучению внутри компании. Мы также изучили то, как общие цели становятся мостами через пропасть между разработкой и отделом эксплуатации, что оздоровляет весь поток создания ценности.
Теперь мы готовы перейти к части V: третий путь, методики обучения. В ней мы рассмотрим, как раньше других, быстро и дешево создавать возможности для обучения, чтобы можно было развернуть на полную мощность культуру инноваций и экспериментирования, позволяющую всем осмысленно действовать, способствуя преуспеванию организации.
Назад: Глава 17. Встройте основанную на гипотезах разработку и A/B-тестирование в свою повседневную работу
Дальше: Часть V. Третий путь: методики непрерывного обучения и экспериментирования

