Книга: Руководство по DevOps
Назад: Глава 9. Создание основы конвейера внедрения
Дальше: Глава 11. Запустить и практиковать непрерывную интеграцию
Глава 10. Быстрое и надежное автоматизированное тестирование
На этом этапе разработчики и тестировщики используют в повседневной работе среды, приближенные к производственным. Мы успешно выполняем интеграционную сборку и запускаем код в такой среде после добавления каждой новой функции, при том что все изменения фиксируются в системе контроля версий. Однако мы, скорее всего, получим нежелательные результаты, если будем искать и исправлять ошибки на отдельном этапе тестирования, выполняемом отдельным подразделением уже после полного окончания разработки. И если тестирование выполняется только несколько раз в году, то разработчики узнают о допущенных промахах лишь через несколько месяцев после того, как внесли изменение, приведшее к ошибке. За это время связь между причиной и следствием будет, скорее всего, потеряна, а решение проблемы требует героических усилий и буквально археологических раскопок. Что самое плохое, значительно уменьшится наша способность учиться на ошибках и применять полученный опыт в будущей работе.
Автоматизированное тестирование решает еще одну серьезную и тревожащую проблему. Гэри Грувер отмечает: «Если нет автоматизированного тестирования, то чем больше кода мы пишем, тем больше времени и средств требуется для проверки, и в большинстве случаев это абсолютно немасштабируемая бизнес-модель для любой технологической организации».
Сейчас компания Google, несомненно, является примером внутренней производственной культуры, должным образом ценящей автоматизированное тестирование. Но такой подход соблюдался не всегда. В 2005 г., когда Майк Блэнд пришел на работу в компанию, развертывание обновлений сайта зачастую сопровождалось серьезными проблемами, особенно для команды Google Web Server (GWS).
Как объясняет Блэнд, «команда GWS попала в описанную выше ситуацию в середине 2000-х гг. Ей было чрезвычайно трудно внести изменения в веб-сервер — приложение на C++, обрабатывавшее все запросы к главной странице Google и многим другим веб-страницам сайта. При всей важности и известности работа в составе команды GWS была отнюдь не гламурным занятием — зачастую она напоминала поиски на свалке кода, реализующего различные функции, написанные командами, которые работали независимо друг от друга. Они сталкивались с такими проблемами, как слишком длительные сборка и тестирование кода, запуск в производство непротестированного кода, проходящая лишь изредка запись изменений кода, причем эти изменения вступали в противоречие с вносимыми другими командами».
Последствия всего этого были серьезными: результаты поиска могли содержать ошибки, или сам поиск был неприемлемо медленным, что влияло на тысячи поисковых запросов на сайте . Потенциальный результат — потеря не только дохода, но и доверия клиентов.
Блэнд описывает, как сумел повлиять на разработчиков, развертывавших изменения: «Страх стал убийцей мышления. Страх перед изменениями останавливал новых членов команды, они не понимали, как работает система. Но страх останавливал также и опытных сотрудников, так как они очень хорошо понимали последствия». Блэнд был частью группы, решавшей эту проблему.
Руководитель команды GWS Бхарат Медиратта считал, что автоматизированное тестирование поможет решить проблему. Как описывает Блэнд, «они утвердили жесткую позицию: изменения не будут приняты в GWS, если они не прошли автоматизированное тестирование. Они настроили непрерывную сборку и буквально с религиозным упорством соблюдали это правило. Они организовали отслеживание уровня тестового покрытия и обеспечивали постоянный его рост с течением времени. Они дописали политику и руководства по тестированию и настаивали, чтобы все участники, связанные с этими процессами как внутри команды, так и вне ее, строго соблюдали установленные правила».
Результаты поразили воображение. Как отмечает Блэнд, «GWS быстро стала одной из самых продуктивных команд в компании, выполняя интеграционную сборку большого числа изменений, поступающих от разных команд каждую неделю, поддерживая при этом график быстрых релизов. Новые члены команды теперь почти сразу же начинали плодотворно работать, внося вклад в сложную систему благодаря хорошему покрытию кода тестами и его качеству. В итоге радикальная политика позволила главной странице сайта быстро расширить возможности, преуспев в стремительно меняющемся мире конкурирующих технологий».
Но GWS все же была относительно небольшой командой в крупной и растущей компании. Команда хотела распространить применяемые методы на всю организацию. Поэтому на свет появилась Testing Grouplet, неофициальная группа инженеров, желавших распространить автоматизированное тестирование во всей организации. В течение следующих пяти лет они помогли растиражировать культуру автоматического тестирования на все подразделения компании Google.
Теперь, когда любой разработчик компании выполняет запись изменений кода, сразу запускается набор из сотен тысяч автотестов. Если код проходит проверку, то он автоматически включается в основную ветку и оказывается готовым к развертыванию в производственной среде. Многие продукты Google собираются ежечасно или ежедневно, другие используют философию доставки Push on Green.
Ставки при таком подходе выше, чем когда бы то ни было: одна-единственная ошибка развертывания кода может одномоментно нарушить работу всего комплекса программ Google (например, из-за глобальных изменений в инфраструктуре или если дефект внесен в одну из основных библиотек, от которой зависит каждая программа).
Эран Мессери, инженер группы Google Developer Infrastructure, отмечает: «Время от времени случаются большие неудачи. Вы получаете кучу мгновенных сообщений, а инженеры стучатся в вашу дверь. Когда конвейер развертывания сломан, мы должны исправить это сразу, потому что разработчики не могут больше записывать изменения кода. Поэтому мы хотим сделать откат очень легким».
Эта система работает в компании Google благодаря профессионализму инженеров и культуре высокого доверия, предполагающей, что каждый хочет сделать свою работу хорошо и что мы можем быстро обнаруживать проблемы и исправлять их. Мессери объясняет: «В Google нет жестких правил, например “если вы вызовете остановку у более чем десяти проектов, то обязаны устранить проблему в течение десяти минут”. Вместо этого существует взаимное уважение между командами, подразумевается, что каждый делает все от него зависящее для поддержания конвейера развертывания. Все мы знаем, что однажды я могу нечаянно повредить ваш проект, а на следующий день вы можете сломать мой».
Результаты, полученные Майком Блэндом и командой Testing Grouplet, сделали компанию Google одной из самых продуктивных технологических организаций в мире. К 2013 г. автоматизированное тестирование и непрерывная интеграция позволили более чем 4000 независимых команд в компании работать вместе и оставаться продуктивными, одновременно выполняя разработку, непрерывную интеграцию, тестирование и развертывание своего кода в производственной среде. Весь код хранится в одном репозитории, он состоит из миллиардов файлов, и они постоянно используются для сборки и интеграции, причем ежемесячно код обновляется наполовину. Некоторые другие статистические данных об их производительности выглядят весьма внушительно:
• 40 000 записей изменений кода в день;
• 50 000 сборок в день (в выходные дни их число может превысить 90 000);
• 120 000 наборов автоматизированных тестов;
• 75 миллионов тестов выполняется ежедневно;
• свыше 100 инженеров, занимающихся разработкой тестов, непрерывной интеграцией и созданием инструментов для увеличения производительности труда разработчиков (что составляет 0,5 % от общего числа разработчиков).
В оставшейся части этой главы мы рассмотрим методы непрерывной интеграции, дающие возможность повторить эти результаты.
Непрерывные сборка, тестирование и интеграция кода и среды
Наша цель — обеспечить качество нашего продукта уже на самых ранних этапах, а для этого разработчики должны организовать автоматизированное тестирование как часть их повседневной работы. Это создает быструю обратную связь, что помогает разработчикам рано обнаруживать проблемы и быстро их исправлять, пока еще это не требует серьезных затрат (например, времени и ресурсов).
На этом этапе мы создаем наборы автоматических тестов, обеспечивающие увеличение частоты интеграций и превращающие тестирование нашего кода и наших сред из периодических в непрерывные. Мы можем сделать это за счет создания конвейера развертывания, и он будет выполнять интеграцию нашего кода и сред и запускать серию тестов каждый раз, когда в систему контроля версий вносится новое изменение (рис. 13).

Рис. 13. Конвейер развертывания (источник: Humble and Farley, Continuous Delivery, 3)
Конвейер развертывания, впервые описанный Джезом Хамблом и Дэвидом Фарли в их книге Continuous Delivery: Reliable Software Releases Through Build, Test, and Deployment Automation, гарантирует, что весь код, записанный в систему контроля версий, автоматически собран и проверен в среде, близкой к производственной. Действуя таким образом, мы обнаруживаем любые ошибки сборки, тестирования или интеграции сразу же, как только они появились, что позволяет нам немедленно их исправить. При правильном выполнении процедур мы можем всегда быть уверенными, что код находится в состоянии готовности к развертыванию и релизу.
Для достижения этой цели необходимо создать автоматизированные процессы сборки и тестирования, выполняющиеся в выделенных средах. Это имеет жизненно важное значение по следующим причинам:
• процессы сборки и тестирования можно запустить в любое время и независимо от того, какой стиль работы предпочитают другие инженеры;
• раздельные процессы сборки и тестирования гарантируют, что мы понимаем все зависимости, необходимые для сборки, упаковки, запуска и тестирования нашего кода (то есть проблема «это работало на ноутбуке разработчика, но не работает в производственной среде» исключена);
• мы можем упаковать наши приложения, чтобы обеспечить повторяемость установки кода и конфигураций в разных средах (например, в Linux RPM, yum, npm, в Windows, OneGet, могут также использоваться альтернативные системы упаковки для интегрированных систем, такие как файлы EAR и WAR для Java, gems для Ruby и так далее);
• вместо того чтобы упаковывать наш код, мы можем помещать наши приложения в развертываемые контейнеры (например, Docker, Rkt, LXD, AMIs);
• среды могут быть сделаны более близкими к производственным, причем стабильным и повторяемым способом (например, из среды удаляются компиляторы, выключаются флаги отладки и тому подобное).
Конвейер развертывания после любого изменения проверяет, что код успешно интегрируется в среду, близкую к производственной. Он становится платформой. Через нее тестировщики запрашивают сборки и сертифицируют их во время приемочных испытаний и тестирования удобства использования, и он будет автоматически выполнять проверки производительности и безопасности.
Кроме того, он будет использоваться для самообслуживающихся сборок сред приемо-сдаточного тестирования, интеграционного тестирования и тестирования безопасности. На следующих шагах, по мере того как мы станем развивать конвейер развертывания, он также будет использоваться для управления всеми видами деятельности, необходимыми, чтобы провести сделанные изменения от системы контроля версий до развертывания.
Для обеспечения функциональности конвейера развертывания были разработаны различные продукты, в том числе с открытым исходным кодом (например, Jenkins, ThoughtWorks Go, Concourse, Bamboo, Microsoft Team Foundation Server, TeamCity, Gitlab CI, а также решения на базе облачных служб, таких как Travis CI and Snap).
Мы начнем создавать конвейер развертывания с той стадии записи изменений кода, когда делается сборка и создается установочный пакет, запускаются автоматизированные модульные тесты и выполняются дополнительные проверки, такие как статический анализ кода, анализ на дублирование кода, проверка тестового покрытия и проверка стилей. В случае успеха запускается стадия приемки: автоматически развертываются пакеты, созданные на этапе записи изменений, и запускаются автоматизированные приемочные тесты.
После того как изменения будут включены в систему контроля версий, желательно, чтобы упаковка кода делалась только один раз, с тем чтобы для развертывания кода по всей протяженности конвейера развертывания использовались те же самые пакеты. При этом код будет развертываться для интеграционного тестирования в тестовых средах точно так же, как и в производственной среде. Это уменьшает возможные отклонения, что позволяет избежать трудно диагностируемых ошибок на выходе процесса (например, с использованием разных компиляторов, флагов компиляции, разных версий библиотек или конфигураций).
Цель конвейера развертывания — предоставление каждому включенному в поток создания ценности, особенно разработчикам, как можно более быстрой обратной связи о том, что внесенные изменения нарушают готовность продукта к развертыванию. Это может быть изменение, внесенное в код, в любую из наших сред, в автоматизированные тесты или даже в инфраструктуру конвейера развертывания (например, настройки конфигурации Jenkins).
В результате инфраструктура нашего конвейера развертывания становится основой для процесса разработки как инфраструктура системы контроля версий. Конвейер развертывания также хранит историю каждой сборки, в том числе информацию, какие тесты были проведены с той или иной сборкой, какие сборки были развернуты и в какой среде, каковы результаты тестирования. Объединив это с информацией в истории контроля версий, мы можем быстро определить, что нарушило работу конвейера развертывания и, вероятно, как устранить ошибку.
Эта информация также помогает нам выполнить требования аудита и соответствия нормам и правилам, поскольку соответствующие подтверждения автоматически создаются в ходе повседневной работы.
Теперь, когда у нас есть работающая инфраструктура конвейера развертывания, мы должны создать методы непрерывной интеграции, обеспечивающие следующую функциональность:
• всеобъемлющий и надежный комплекс автоматизированных проверок, подтверждающий, что мы готовы к развертыванию;
• производственную культуру, «останавливающую всю производственную линию», когда тесты сообщают о сбое;
• разработчики трудятся над небольшими пакетами изменений основной ветви кода, а не над отдельной долгоживущей веткой для выделенного функционала.
В следующем разделе мы опишем, почему нам необходимо быстрое и надежное автоматизированное тестирование и как его создать.
Создайте комплекс быстрой и надежной автоматизированной тестовой проверки
На предыдущем шаге мы начали создавать инфраструктуру автоматизированного тестирования, проверяющую наличие зеленой сборки (такой, где все компоненты в системе контроля версий находятся в состоянии, обеспечивающем сборку и развертывание). Чтобы подчеркнуть, почему нам необходимо выполнять этот шаг — интеграции и тестирования — непрерывно, рассмотрим, что происходит, когда мы выполняем эту операцию лишь периодически, например в ходе ночных сборок.
Предположим, у нас есть команда из десяти разработчиков, и каждый ежедневно записывает изменения кода в системе контроля версий. Один вносит изменение, «ломающее» выполнение ночной сборки и работу по ее тестированию. В этом сценарии мы, придя утром на работу, обнаружим отсутствие «зеленой сборки», и потребуется несколько минут или, что более вероятно, несколько часов, пока команда выяснит, какие именно изменения вызвали проблему, кто их внес и как это исправить.
Рассмотрим наиболее плохой вариант, когда проблема не была вызвана изменением кода, а связана с изменением тестовой среды (например, какой-то параметр конфигурации был установлен неправильно). Команда разработчиков может считать, что они устранили проблему, поскольку все тесты успешно пройдены, но на следующий день обнаружится, что ночью вновь произошел сбой.
Можно еще сильнее усложнить ситуацию, предположив, что в течение дня записано десять изменений в коде. Каждое из них потенциально могло породить ошибки, нарушающие выполнение автоматизированных тестов, что еще увеличивает сложность успешной диагностики и устранения проблем.
Короче говоря, медленная и нечастая обратная связь убивает процесс разработки. Особенно в случае больших команд. Проблема еще осложняется, если десятки, сотни и даже тысячи разработчиков ежедневно записывают изменения кода в системе контроля версий. В результате сборки и автоматические тесты часто сбоят, и разработчики даже приостанавливают на время запись изменений в системе контроля версий («зачем беспокоиться, ведь все равно сборка кода и его проверка сломаны»). Вместо этого для интеграции кода они дожидаются приближения конца проекта, что приводит ко всем нежелательным результатам крупных пакетов работы, интеграции в стиле big bang («большой взрыв») и проблемам с внедрением в производство.
Для предотвращения такого сценария нам нужны быстрые автоматические тесты, запускающиеся в средах сборки и тестирования всякий раз, когда в системе управления версиями записывается новое изменение. В этом случае мы можем найти и устранить любые проблемы немедленно, как это показывает пример команды GWS. Действуя так, можно обеспечить выполнение работы небольшими партиями, а также то, что в любой момент код готов к развертыванию.
В целом автоматизированные тесты относятся к одной из следующих категорий (перечислим, начиная от самых быстрых и до самых медленных).
• Модульное тестирование (юнит-тесты). Как правило, эти тесты проверяют один метод, класс или функцию изолированно от других, показывая разработчикам, что их код работает так, как задумано. По многим причинам, в том числе из-за необходимости поддерживать наши тесты быстрыми и не зависящими от состояния системы в целом, в модульных тестах используются заглушки для баз данных и других внешних зависимостей (например, функции изменены, чтобы возвращать статические, предустановленные значения вместо реального обращения к базам данных).
• Приемочное тестирование. Как правило, это тестирование приложения в целом. Оно необходимо, чтобы убедиться, что более верхнеуровневая функциональность работает так, как задумано (например, бизнес-критерии приемки в соответствии с требованиями клиента, правильность API), и что отсутствуют ошибки регрессии (то есть не повреждены функции, ранее работавшие правильно). Хамбл и Фарли так определили разницу между модульным и приемочным тестированием: «Цель модульного тестирования — показать, что отдельная часть приложения делает то, что задумал программист… Цель приемочных тестов — доказать, что наше приложение делает то, что от него ожидает клиент, а не то, что оно должно делать, по мнению программиста». После того как сборка проходит наши модульные тесты, конвейер развертывания запускает приемочное тестирование. Любая сборка, прошедшая приемочное тестирование, обычно становится затем доступной для тестирования вручную (например, исследовательское тестирование, тестирование пользовательского интерфейса и так далее), а также для интеграционного тестирования.
• Интеграционное тестирование. Интеграционное тестирование дает нам возможность убедиться, что наши приложения правильно взаимодействуют с другими приложениями и сервисами в производственной среде, в отличие от тестирования с заглушками на интерфейсах. Как отметили Хамбл и Фарли, «значительная часть работы в среде тестирования системной интеграции включает развертывание новых версий каждого приложения, пока они не начнут правильно взаимодействовать. В этой ситуации “смоук-тест” (проверка общей работоспособности) обычно — полный набор приемочных испытаний. Им подвергается все приложение». Интеграционным тестам подвергаются сборки, прошедшие модульные и приемочные испытания. Поскольку интеграционное тестирование часто оказывается нестабильным, мы хотим свести к минимуму количество интеграционных тестов и найти как можно больше дефектов в ходе модульного и приемочного тестирования. Возможность использования виртуальных или имитированных версий удаленных сервисов при запуске приемочных испытаний становится важным для архитектуры требованием.
Если разработчики сталкиваются с давлением из-за приближающегося срока завершения проекта, они могут перестать создавать модульные тесты в ходе повседневной работы, независимо от того, как мы определили состояние «сделано». Для обнаружения этой проблемы мы можем выбрать в качестве показателя и сделать прозрачной глубину покрытия тестами (как функцию от числа классов, строк кода, перестановок и так далее), даже считая наш набор приемосдаточных тестов не пройденным, если покрытие падает ниже определенного уровня.
Мартин Фаулер отмечает, что в целом «десять минут на сборку и тестирование — отличное время, в пределах разумного… Сначала мы выполняем компиляцию и запускаем более локальные модульные тесты с базой данных, полностью отключенной с помощью заглушек. Такие тесты могут выполняться очень быстро, завершаясь в течение десяти минут. Однако любые ошибки, связанные с более масштабным взаимодействием, особенно включающие работу с реальными базами данных, не будут найдены. На втором этапе сборка подвергается другому набору тестов приемочных испытаний, работающих с реальными базами данных и проверяющих более сложное, сквозное поведение. Выполнение этого набора тестов может занять несколько часов».
Обнаружение ошибок с помощью автоматизированного тестирования на самых ранних этапах
Конкретная цель разработки наших наборов автоматизированных тестов — найти ошибки на максимально раннем этапе тестирования. Вот почему мы запускаем быстро работающие автоматизированные тесты (например, модульные) раньше, чем медленнее работающие автоматизированные тесты (например, приемочные и интеграционные тесты), а они, в свою очередь, запускаются до любых видов тестирования вручную.
Другое следствие этого принципа — то, что любые ошибки должны быть найдены с помощью самых быстрых категорий тестирования. Если большинство ошибок обнаруживаются в ходе приемочного и интеграционного тестирования, то обратная связь к разработчикам приходит на порядок медленнее, чем при модульном тестировании — и интеграционное тестирование требует применения ограниченных и сложных тестовых сред. Они могут использоваться только одной командой в каждый момент, что еще сильнее затягивает получение обратной связи.
Кроме того, не только само воспроизведение ошибок, обнаруженных в ходе интеграционного тестирования, является трудоемким и отнимает много времени. Сложным является даже процесс проверки того, что они действительно исправлены (то есть разработчик создает исправление, но затем необходимо ждать четыре часа, чтобы узнать, успешно ли завершилось интеграционное тестирование).
Поэтому, обнаружив ошибку в ходе приемочного или интеграционного тестирования, мы должны создать модульный тест, чтобы он мог найти ошибку быстрее, раньше и дешевле. Мартин Фаулер описал понятие «пирамиды идеального тестирования». С ее помощью мы могли бы отлавливать большинство ошибок благодаря модульным тестам (рис. 14). На деле же зачастую верно обратное, и основной вклад в поиск ошибок вносят ручное и интеграционное тестирование.
Идеальное и неидеальное автоматизированное тестирование 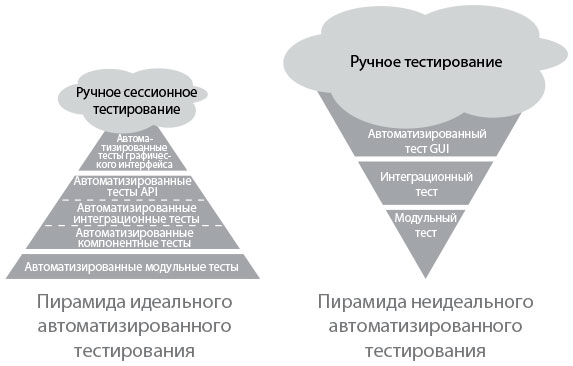
Рис. 14. Пирамиды идеального и неидеального автоматизированного тестирования (источник: Martin Fowler, TestPyramid)
Если мы обнаружим, что модульные или приемочные испытания слишком сложны и дорогостоящи, чтобы писать их и поддерживать, то, скорее всего, у нас слишком связанная архитектура, когда четких границ между модулями не существует (или, возможно, никогда не существовало). В этом случае нам необходимо создать менее связанную систему. Ее модули можно тестировать независимо, без среды интеграции. Тогда можно сделать так, чтобы приемочные испытания даже самых сложных приложений выполнялись в течение нескольких минут.
Обеспечьте быстрое выполнение тестов (если необходимо — параллельное)
Поскольку мы хотим, чтобы наши тесты выполнялись быстро, нам необходимо разработать их так, чтобы они могли работать параллельно и потенциально — на большом количестве разных серверов. Нам также может понадобиться выполнять тесты различных категорий параллельно. Например, когда сборка проходит приемочные тесты, мы можем запускать тесты производительности и одновременно — тесты безопасности, как показано на рис. 15. Мы можем допускать или не допускать исследовательское тестирование вручную до завершения всех автоматических проверок — если допускаем, это позволит раньше получить обратную связь, но может привести к затратам времени на сборки, не прошедшие автоматизированное тестирование.
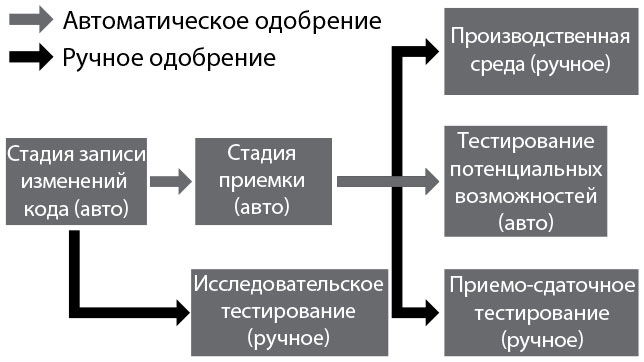
Рис. 15. Параллельный запуск автоматизированных тестов и тестирования вручную (источник: Джез Хамбл, Дэвид Фарли «Непрерывное развертывание ПО. Автоматизация процессов сборки, тестирования и внедрения новых версий программ»)
Любую сборку, прошедшую все наши автоматизированные тесты, мы делаем доступной для исследовательского тестирования, равно как и для других форм ресурсоемкого тестирования (вручную, например тестирование производительности). Мы хотим проводить такие тесты настолько часто, насколько возможно — либо непрерывно, либо по расписанию.
Любой, кто тестирует (включая и всех наших разработчиков), должен использовать самую последнюю сборку, прошедшую все автоматизированные тесты, а не ожидать, пока разработчики пометят конкретную сборку как готовую к тестированию. При этом мы можем обеспечить, чтобы процесс тестирования начался как можно раньше.
Пишите автоматизированные тесты до того, как начнете писать код («разработка через тестирование»)
Один из наиболее эффективных путей обеспечения надежными автоматизированными тестами — написание тестов в ходе повседневной деятельности с использованием таких методов, как «разработка через тестирование» (TDD — test-driven development) и «разработка через приемочное тестирование» (ATDD — acceptance test-driven development). При использовании этих методов мы начинаем любое изменение в системе с того, что пишем автоматизированный тест, проверяющий, не будет ли сбоев в ожидаемом поведении кода, и лишь затем пишем код, который будет проходить эти тесты.
Этот метод был разработан Кентом Беком в конце 1990-х гг. как часть его концепции экстремального программирования и состоит из трех шагов.
1. Убедиться, что тест не пройден. «Напишите тест для проверки следующего кусочка функциональности, который вы хотите добавить». Запишите эти изменения.
2. Убедиться, что тест пройден. «Пишите функциональный код, пока тест не начнет успешно проходить». Запишите эти изменения.
3. Выполните рефакторинг как старого, так и нового кода, чтобы обеспечить его хорошую структурированность. Убедитесь, что тест успешно проходит. Снова запишите изменения кода.
Наборы автоматизированных тестов фиксируются в системе контроля версий наряду с нашим кодом, что обеспечивает документированность текущего состояния нашей системы. Разработчики, желающие понять, как использовать систему, могут обратиться к этим наборам тестов, чтобы найти рабочие примеры использования системных API.
Автоматизируйте как можно больше тестов
Наша цель — найти как можно больше ошибок в коде с помощью наборов автоматизированных тестов, снижая зависимость от тестирования вручную. В своей презентации «В заботе о циклах обратной связи и их поддержании» (On the Care and Feeding of Feedback Cycles) на конференции Flowcon в 2013 г. Элизабет Хендриксон отмечала: «Хотя тестирование может быть автоматизировано, создание качества автоматизировать невозможно. Выполнение вручную тестов, нуждающихся в автоматизации, — пустая трата человеческого потенциала».
При этом мы даем возможность всем нашим тестировщикам (разумеется, включая разработчиков) заниматься деятельностью, имеющей высокую ценность. Она не может быть автоматизирована: это аналитическое тестирование или улучшение самого процесса тестирования.
Однако простая автоматизация всех тестов, проводящихся вручную, может дать нежелательные результаты, ведь мы не хотим, чтобы автоматизированные тесты были ненадежны или давали ложно-положительный результат (то есть тесты должны быть проходимыми, только если код правильно функционирует, но должны сообщать о сбоях, если возникнут проблемы: низкая производительность, задержки при выполнении, неконтролируемое начальное состояние или непредусмотренное состояние из-за использования заглушек баз данных либо общих сред тестирования).
Ненадежные тесты, генерирующие ложные срабатывания, создают значительные проблемы — они отнимают драгоценное время (например, вынуждая разработчиков повторно запускать тест, чтобы определить, существует ли проблема на самом деле), увеличивают общее количество усилий, требующихся для запуска тестирования и интерпретации его результатов. Зачастую они же приводят к стрессовым нагрузкам на разработчиков; те начинают полностью игнорировать результаты тестов или выключают автоматическое тестирование и сосредоточиваются на создании кода.
Результат всегда один и тот же: мы обнаруживаем проблемы позднее, чем могли бы, их исправление оказывается более сложным делом, а наши заказчики получают неудачный результат, что, в свою очередь, создает излишнюю нагрузку на весь поток создания ценности.
Для смягчения ситуации предпочтительно иметь небольшое число надежных автоматизированных тестов, а не много проводимых вручную или ненадежных автоматических. Поэтому мы ориентированы на автоматизацию только тех тестов, которые действительно подтверждают желанные для нас бизнес-цели. Если отказаться от тестирования дефектов, обнаруживающихся в производственной среде, то мы должны добавить их обратно в набор тестов, осуществляемых вручную, и в идеале обеспечить их автоматизацию.
Гэри Грувер, ранее работавший вице-президентом по качеству разработок, релиза ПО и эксплуатации компании , так описывал свои впечатления: «На нашем сайте электронной коммерции крупного розничного продавца мы перешли от 1300 тестов, выполняемых вручную каждые десять дней, к десяти автоматизированным, запускаемым при каждой записи изменений кода. Гораздо лучше выполнить несколько надежных тестов, чем много ненадежных. С течением времени мы расширили этот набор до сотен тысяч автоматизированных тестов».
Другими словами, мы начинаем с небольшого числа надежных автоматических проверок и с течением времени увеличиваем их количество, все сильнее укрепляя уверенность, что мы быстро обнаружим любые изменения в системе, способные вывести ее из состояния готовности к развертыванию.
Встраиваем тесты производительности в программу тестирования
Слишком часто мы обнаруживаем во время интеграционного тестирования или уже после развертывания в производственную среду, что наше приложение имеет низкую производительность. Проблемы производительности зачастую трудно обнаружить, например, когда работа замедляется с течением времени, и они остаются незамеченными, пока не становится слишком поздно (к примеру, запросы к базе данных без использования индекса). И многие из этих проблем сложно решать, особенно когда они вызваны принятыми нами архитектурными решениями или непредвиденными ограничениями нашей сети, базы данных, системы хранения данных или других систем.
Наша цель — написать и запустить автоматические тесты производительности, проверяющие производительность всего стека приложения (код, базы данных, хранилища, сети, виртуализация и так далее) в рамках конвейера развертывания, чтобы мы могли обнаруживать проблемы на раннем этапе, когда внесение исправлений делается быстро и обходится малой ценой.
Поняв, как наше приложение и среды ведут себя под нагрузкой, близкой к реальной, мы можем гораздо лучше планировать мощности нашей системы, а также выявлять нижеперечисленные ситуации и подобные им:
• время выполнения запроса к базе данных растет нелинейно (например, мы забыли включить индексирование базы данных, и время загрузки страницы увеличивается с тридцати секунд до ста минут);
• изменение кода вызывает десятикратное увеличение количества вызовов базы данных, нагрузки на системы хранения или сетевого трафика.
Если у нас проводятся приемочные испытания и они могут выполняться параллельно, то мы используем их как основу для наших тестов производительности. Например, предположим, что мы работаем с сайтом электронной торговли и определили, что операции «поиск» и «оформить заказ» важны и должны хорошо выполняться даже под нагрузкой. Для проверки этого мы можем запустить одновременно тысячи приемочных тестов поиска и тысячи приемочных тестов оформления заказа.
Из-за большого объема вычислений и операций ввода-вывода, необходимых для выполнения тестов производительности, создание среды для такого тестирования может оказаться более сложным, чем создание производственной среды для самого приложения. Поэтому мы должны создавать среду для тестирования производительности в начале любого проекта и обеспечивать выделение всех ресурсов, необходимых, чтобы она функционировала корректно и на начальных этапах.
Чтобы в начале работы выявить проблемы с производительностью, мы должны регистрировать результаты тестов производительности и оценивать результаты каждого запуска по сравнению с предыдущими результатами. Например, мы можем посчитать, что тест не пройден, если производительность отличается более чем на 2 % от результатов предыдущего запуска.
Включайте проверку нефункциональных требований в программу тестирования
В дополнение к тестированию того, что код работает, как запланировано, и выдерживает нагрузку, близкую к производственной, мы также хотели бы проверить все другие атрибуты системы, о которых считаем нужным позаботиться. Это так называемые нефункциональные требования: доступность, масштабируемость, производительность, безопасность и так далее.
Многие из этих требований оказываются выполненными при правильной конфигурации наших сред, поэтому мы должны также создавать автоматические проверки, чтобы убедиться, что наши среды были созданы и настроены правильно. Например, мы хотим обеспечить согласованность и правильность следующих характеристик (на их основе выполняются и многие нефункциональные требования, в частности безопасности, производительности и доступности):
• поддержка приложений и баз данных, библиотек и так далее;
• интерпретаторы языков программирования, компиляторы и так далее;
• операционные системы (например, включение ведения журналов аудита и так далее);
• все зависимости.
Используя инструменты автоматизированного управления конфигурацией «infrastructure as a code» (например, Puppet, Chef, Ansible, Salt, Bosh), мы можем задействовать те же инструменты тестирования, что и для проверки кода, чтобы также выяснить, что наши среды настроены и работают правильно (например, используя проверки конфигурации сред в тестах Cucumber или Gherkin).
Кроме того, подобно тому как мы используем средства анализа приложений в конвейере развертывания (например, статический анализ кода, анализ тестового покрытия), мы должны запускать инструменты, анализирующие код автоматизированной конфигурации (например, Foodcritic for Chef, Puppet-lint for Puppet). Мы должны также выполнить проверки усиления безопасности как часть наших автоматических тестов, чтобы убедиться, что все настроено надежно и правильно (например, конфигурации серверов).
В любой момент времени наши автоматизированные тесты могут подтвердить, что у нас есть «зеленая» сборка и она находится в готовности к развертыванию. Теперь мы должны создать шнур-андон, чтобы, когда кто-либо нарушил работу конвейера развертывания, мы смогли предпринять все необходимые шаги для возвращения обратно в «зеленое» состояние сборки.
Дергайте за шнур-андон, если конвейер развертывания поврежден
Когда в конвейере развертывания «зеленая» сборка, мы обретаем высокую степень уверенности, что наши код и окружение при развертывании изменений в производственной среде будут работать именно так, как задумывалось.
Чтобы поддерживать конвейер развертывания в «зеленом» состоянии, создадим виртуальный шнур-андон, аналогичный физическому шнуру в системе производства Toyota. Когда кто-либо вносит изменение, нарушающее сборку или прохождение автоматизированных тестов, любая новая работа не подпускается в систему, пока проблема не устранена. И если кто-то нуждается в помощи для устранения этой проблемы, он может получить ее от всех членов команды, как и в примере с компанией Google, приведенном в .
Когда работа конвейера развертывания нарушена, мы по крайней мере должны уведомить о сбое всю команду, чтобы тот, из-за кого проблема возникла, мог ее исправить или откатить внесенные изменения. Мы даже можем настроить систему контроля версий для предотвращения дальнейшей записи изменений кода, пока первая стадия (то есть сборка и модульное тестирование) конвейера развертывания не перейдет обратно в «зеленое» состояние. Если эта проблема вызвана тем, что автоматизированная проверка выдала ложноположительную оценку, неправильная проверка должна быть переписана или удалена. Каждый член команды должен быть наделен полномочиями для совершения отката, чтобы вернуть сборку обратно в «зеленое» состояние.
Рэнди Шуп, бывший технический директор Google App Engine, писал о важности возвращения процесса развертывания обратно в «зеленое» состояние: «Мы ставим командные цели выше индивидуальных, когда мы можем помочь кому-нибудь из членов команды продвинуть его работу вперед, мы делаем это всей командой. Это правило применимо ко всем случаям, независимо от того, помогаем ли мы кому-то исправить сборку, автоматизированный тест или даже делаем для него обзор кода. И конечно же, мы уверены, что все будут делать то же самое для нас, если нам понадобится помощь. Эта система работала без особых формальностей или правил — все знали, что нашей задачей было не просто “написать код”, но “запустить сервис”. Вот почему мы сделали приоритетными все вопросы качества, особенно связанные с надежностью и масштабированием, и рассматривали их как наиболее приоритетные задачи, а их невыполнение — как ошибку, приводящую к неработоспособности системы. С точки зрения системы эти методы удерживали нас от соскальзывания назад».
Когда на более поздних этапах конвейера развертывания, таких как приемочные испытания или тесты производительности, происходит сбой, мы вместо остановки новых работ собираем оперативно всех разработчиков и тестировщиков, несущих ответственность за немедленное устранение этих проблем. Они должны также создать новые тесты, выполняемые на более ранней стадии конвейера развертывания, чтобы отловить появление этих проблем при возможных регрессиях. Например, если мы обнаружим дефект в ходе приемочных испытаний, то должны написать модульный тест для раннего выявления проблемы. Аналогично, обнаружив дефект в ходе аналитического тестирования, мы должны написать модульный или приемочный тест.
Чтобы повысить видимость сбоев в ходе автоматизированного тестирования, создадим хорошо заметные индикаторы, чтобы вся группа могла увидеть, когда сборки или автоматические тесты дают сбой. Многие команды используют специальные лампы, расположенные на стене и указывающие текущий статус сборки. Есть и другие забавные способы уведомить команду, что сборка сломана: включить гелевые светильники, воспроизвести голосовую запись, песню или гудок автомобильного клаксона, использовать светофоры и так далее.
Во многих отношениях этот шаг более сложный, чем создание сборок и тестовых серверов — то были чисто технические мероприятия, а описываемый шаг требует изменения стимулов поведения членов команды. Вместе с тем непрерывная интеграция и непрерывная поставка требуют проведения этих изменений, и мы изучим причины такой необходимости в следующем разделе.
Почему нужно дергать за шнур-андон
Если мы не потянем вовремя шнур-андон и, следовательно, не исправим немедленно какие-то проблемы конвейера развертывания, то столкнемся со слишком хорошо знакомыми проблемами — нам будет гораздо сложнее вернуть наши приложения и среды обратно в состояние готовности к развертыванию. Рассмотрим следующую ситуацию:
• кто-то записал изменения кода, «ломающие» сборку или автоматизированные тесты, но никто не исправляет ошибку;
• кто-то еще записывает другое изменение в «сломанной» сборке, также не проходящее автоматизированные тесты — но никто не видит результатов проверки этого кода, а ведь они дали бы возможность увидеть новый дефект, не говоря уже о его исправлении;
• имеющиеся у нас тесты не работают надежно, и поэтому маловероятно, что мы будем создавать новые тесты (зачем, если мы и имеющиеся-то тесты не можем заставить работать!).
Когда это происходит, развертывание в любой среде становятся ненадежным, поскольку у нас нет автоматизированных тестов или мы использовали метод водопада, когда большинство проблем обнаруживаются уже в производственной среде. Неизбежный результат порочного цикла — то, что мы в конце концов оказываемся там, где начинали. На непредсказуемом «этапе стабилизации», занимающем недели или месяцы, вся наша команда оказывается в пучине кризиса, пытаясь обеспечить прохождение продуктом всех тестов, срезая острые углы под давлением приближающихся сроков и увеличивая размер нашего технического долга.
Заключение
В этой главе мы рассмотрели создание всеобъемлющего набора автоматизированных тестов для подтверждения того, что у нас есть «зеленая» сборка, проходящая все тесты и находящаяся в состоянии, пригодном к развертыванию. Мы организовали выполнение этих тестов в рамках нашего конвейера развертывания. Мы также сделали нормой производственной культуры осуществление всего необходимого для возвращения сборки в «зеленое» состояние, если кто-то вносит изменение, «ломающее» любой из наших автоматизированных тестов.
Тем самым мы заложили основу для осуществления непрерывной интеграции, позволяющей большому количеству небольших команд самостоятельно и безопасно разрабатывать, тестировать и развертывать код в производственной среде, обеспечивая предоставление ценности клиентам.
Назад: Глава 9. Создание основы конвейера внедрения
Дальше: Глава 11. Запустить и практиковать непрерывную интеграцию

