Глава 7. Компьютеры
Любая достаточно развитая технология неотличима от магии.
Артур Кларк
Бесчисленные и разнообразные машины были изобретены для решения задач. Существует много типов компьютеров: от встроенных в роботов, которые бродят по Марсу, до тех, что управляют навигационными системами атомных подводных лодок. Почти все компьютеры, включая наши ноутбуки и телефоны, имеют тот же самый принцип работы, что и первая вычислительная машина, изобретенная фон Нейманом в 1945 году. А вы знаете, как устроены компьютеры? В этой главе вы научитесь:
 понимать основы компьютерной архитектуры;
понимать основы компьютерной архитектуры;
 выбирать компилятор для трансляции вашего исходного кода на язык компьютеров;
выбирать компилятор для трансляции вашего исходного кода на язык компьютеров;
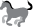 разменивать память на быстродействие при помощи иерархии памяти.
разменивать память на быстродействие при помощи иерархии памяти.
В конце концов, программирование должно выглядеть как волшебство только для непрограммистов — но не для нас с вами.
7.1. Архитектура
Компьютер — машина, которая подчиняется командам, управляющим данными. Он имеет два главных компонента: процессор и память. Память, она же ОЗУ, — это то место, где мы пишем команды. Она также хранит данные, которыми компьютер оперирует. Процессор, или ЦП, получает команды и данные из памяти и выполняет соответствующие вычисления. Давайте разберемся, как работают эти два компонента.
Память
Память поделена на множество ячеек. Каждая хранит крошечный объем данных и имеет числовой адрес. Чтение или запись данных в памяти выполняется посредством операций, которые воздействуют на одну ячейку за раз. Чтобы прочитать ячейку памяти или произвести запись в нее, мы должны передать ее числовой адрес (рис. 7.1).
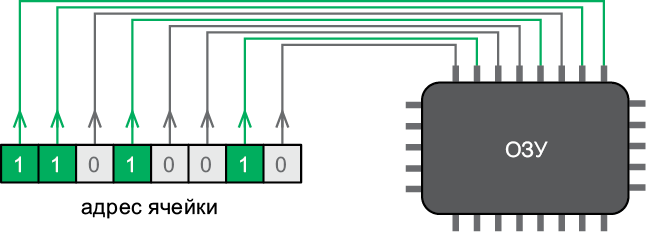
Рис. 7.1. Сообщение для ОЗУ выполнить операцию в ячейке № 210 (11010010)
Поскольку память является электрической схемой, мы передаем адреса ячеек по проводам в виде двоичных чисел. Каждый провод передает двоичную цифру. Высокое напряжение соответствует сигналу «единица», низкое — сигналу «ноль».
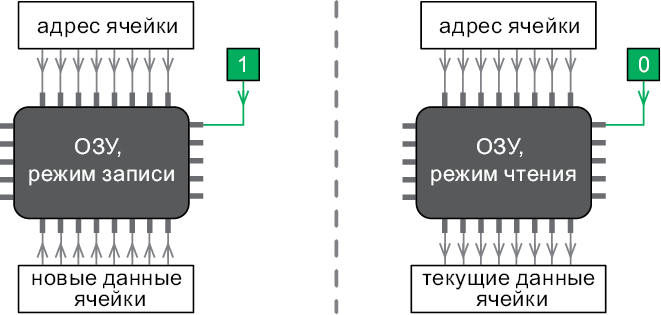
Рис. 7.2. Память может работать в режиме чтения или записи
Память способна выполнить с адресом ячейки две операции: получить хранящееся в ней значение или записать новое. Память имеет специальный входной контакт для установки ее рабочего режима (рис. 7.2).
Каждая ячейка памяти хранит 8-разрядное двоичное число, которое называется байтом. В режиме чтения память получает хранящийся в ячейке байт и выводит его по восьми проводам, которые передают данные (рис. 7.3).
Когда память находится в режиме записи, она получает байт по этим проводам и записывает его в указанную ячейку (рис. 7.4).
Группа проводов, используемых для передачи одинаковых данных, называется шиной. Восемь проводов для передачи адресов формируют адресную шину. Другие восемь, используемых для передачи информации в ячейки памяти и обратно, формируют шину данных. Адресная шина является однонаправленной (используется только для получения данных), а шина данных – двунаправленной (используется для отправки и для получения данных).
Рис. 7.3. Чтение числа 32 из ячейки с адресом 211
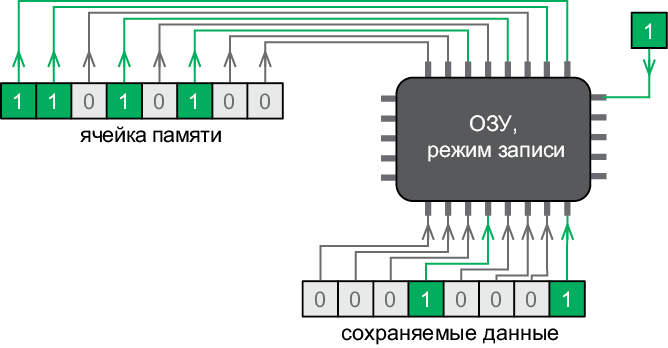
Рис. 7.4. Запись числа 33 в ячейку с адресом 212
В любом компьютере ЦП и ОЗУ постоянно обмениваются данными: процессор выбирает команды и данные из памяти и иногда сохраняет туда данные для вывода и промежуточные результаты вычислений (рис. 7.5).
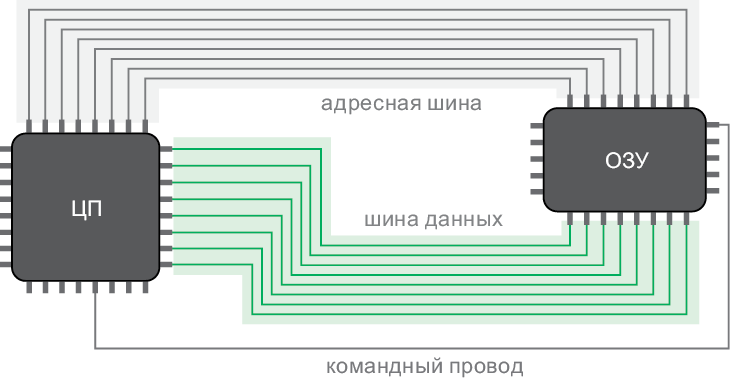
Рис. 7.5. ЦП подключен проводами к ОЗУ
Процессор
Центральный процессор имеет несколько ячеек внутренней памяти, которые называются регистрами. Он может выполнять простые математические операции с числами, хранящимися в этих регистрах. Он также может перемещать данные между регистрами и ОЗУ. Вот примеры типичных операций, которые приходится исполнять центральному процессору:
• скопировать данные из ячейки памяти № 220 в регистр № 3;
• сложить число в регистре № 3 с числом в регистре № 1.
Набор всех операций, которые может выполнять ЦП, называется его набором команд. Каждой операции в наборе команд присвоено число. Машинный код по существу — последовательность чисел, представляющих операции центрального процессора. Они хранятся в виде чисел в ОЗУ. Мы сохраняем входные/выходные данные, промежуточные результаты и машинный код — все вперемешку — в ОЗУ.
Рис. 7.6 показывает, как некоторым процессорным командам ставятся в соответствие числа в том виде, в котором они приводятся в руководствах по ЦП. По мере совершенствования технологии производства процессоры стали поддерживать дополнительные операции. Набор команд современных ЦП огромен. Однако самые важные операции существовали уже несколько десятилетий назад.
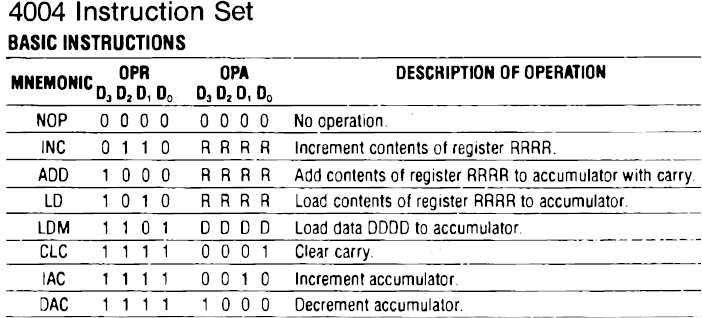
Рис. 7.6. Часть технического описания Intel 4004, показывающая, как операциям ставятся в соответствие числа. Это был первый в мире ЦП, выпущенный в 1971 году
ЦП работает в бесконечном цикле, постоянно выбирая и исполняя команды из памяти. В ядре цикла находится регистр PC, или счетчик команд. Это специальный регистр, который хранит адрес памяти следующей исполняемой команды. Вот что делает ЦП:
1) выбирает команду в адресе памяти, заданном регистром PC;
2) увеличивает PC на 1;
3) выполняет команду;
4) возвращается к шагу 1.
Когда ЦП включается, PC присваивается значение по умолчанию, то есть адрес первой команды, выполняемой машиной. Это обычно неизменяемая встроенная программа, ответственная за загрузку основных функций компьютера.
После включения ЦП начинает выполнять этот бесконечный цикл выборки и исполнения, пока вы не выключите компьютер. Однако если бы ЦП мог выполнять только упорядоченный, последовательный список операций, то компьютер был бы не более чем продвинутым калькулятором. ЦП удивителен, потому что ему можно поручить записать новое значение в регистр PC, заставив процесс исполнения команд выполнить переход — «перепрыгнуть» куда-то в другое место в памяти. Такое ветвление может быть условным выражением. Например, команда ЦП может сообщить: «Записать в PC адрес № 200, если регистр № 1 хранит ноль». Это позволяет компьютерам выполнять операторы, подобные следующему:
if x = 0
compute_this() # вычислить это
else
compute_that() # вычислить то
Вот и все, что вам надо знать. Открываете ли вы сайт, играете ли в компьютерную игру или редактируете электронную таблицу, вычисления всегда одинаковы: это серия простых операций, которые могут лишь суммировать, сравнивать или перемещать данные в памяти.
При помощи множества этих простых операций можно выражать запутанные процедуры. Например, код классической игры Space Invaders (рис. 7.7) включает порядка 3000 машинных команд.

Рис. 7.7. Игру Space Invaders, выпущенную в 1978 году, многие называют самой влиятельной за всю историю
Тактовая частота ЦП. В 1980-х годах чрезвычайно популярной стала игра Space Invaders. Люди играли в нее на игровых автоматах, оборудованных процессорами с тактовой частотой 2 МГц. Этот показатель — число базовых операций, которые процессор выполняет в секунду. Процессор с тактовой частотой 2 МГц выполняет примерно 2 млн базовых операций в секунду. Для выполнения машинной команды требуется от пяти до десяти базовых операций. Следовательно, винтажные игровые автоматы выполняли сотни тысяч машинных команд каждую секунду.
В условиях современного технологического прогресса обычные настольные компьютеры и смартфоны обычно имеют процессоры с тактовой частотой 2 ГГц. Они способны выполнять сотни миллионов машинных команд каждую секунду. А с недавних пор массовое применение получили многоядерные ЦП. Четырехъядерный процессор с тактовой частотой 2 ГГц может выполнять почти миллиард машинных команд в секунду. И, похоже, в перспективе у наших процессоров будет все больше ядер.
Архитектуры ЦП. Вы когда-нибудь задавались вопросом, почему нельзя вставить компакт-диск для Sony PlayStation в настольный компьютер и начать играть? Или почему приложения для iPhone не запускаются на Mac? Причина проста: разные архитектуры ЦП.
В наше время архитектура x86 является довольно стандартной, и потому одинаковый код может выполняться на большинстве персональных компьютеров. Однако сотовые телефоны, например, имеют процессоры с другой, более энергоэффективной архитектурой. Разные архитектуры означают разные наборы процессорных команд и, следовательно, разные способы их кодирования числами. Числа, которые транслируются как команды для ЦП вашего настольного компьютера, не являются допустимыми командами для ЦП в вашем сотовом телефоне, и наоборот.
32-разрядная архитектура против 64-разрядной. Первый ЦП под названием Intel 4004 был основан на 4-разрядной архитектуре. Это означает, что он мог оперировать двоичными числами (суммировать, сравнивать, перемещать их) до 4 разрядов в одной машинной команде. Шина данных и шина адресов на Intel 4004 состояли всего из четырех проводов каждая.
Вскоре после этого широкое распространение получили 8-разрядные ЦП. Они использовались в ранних персональных компьютерах, работавших под DOS. Game Boy, популярный в 1980–1990-х годах переносной игровой компьютер, тоже имел 8-разрядный процессор. Одиночная команда в таких ЦП может оперировать 8-разрядными двоичными числами.
Быстрый технологический прогресс позволил занять доминирующее положение 16-разрядной, а затем — 32-разрядной архитектуре. Емкость регистров ЦП была увеличена до 32 разрядов. Для более емких регистров естественно потребовалось расширить шины данных и адресов. Адресная шина с 32 проводами позволяет адресовать 232 байт (4 Гб) памяти.
А затем наша жажда вычислительной мощи стала просто неудержимой. Компьютерные программы быстро усложнялись и использовали все больше памяти. 4Гб ОЗУ оказалось слишком мало. И обращение к памяти большего объема с числовыми адресами, которые укладываются в 32-разрядные регистры, превратилась в непростой процесс. Это ознаменовало появление доминирующей сегодня 64-разрядной архитектуры. 64-разрядные процессоры могут оперировать в одной команде чрезвычайно большими числами. При этом 64-разрядные регистры хранят адреса в огромном пространстве памяти — 264 байт, что составляет более 17 млрд гигабайт.
Прямой порядок байтов против обратного. Некоторые разработчики компьютеров посчитали, что в ОЗУ и ЦП целесообразно хранить числа слева направо (от младших разрядов к старшим), способом, известным как обратный порядок байтов. Другие предпочли записывать данные справа налево, способом, который называется прямым порядком байтов. Двоичная последовательность 1-0-0-0-0-0-1-1 может представлять разные числа в зависимости от порядка байтов:
• прямой порядок байтов: 27 + 21 + 20 = 131;
• обратный порядок байтов: 20 + 26 + 27 = 193.
Большинство ЦП сегодня имеют обратный порядок байтов, вместе с тем существует много компьютеров с прямым порядком. Если данные, сгенерированные ЦП с обратным порядком байтов, должны интерпретироваться процессором с прямым порядком, то необходимо принять меры, чтобы избежать несоответствия порядка байтов. Программисты, манипулирующие двоичными числами напрямую, в особенности во время разбора данных, выходящих из сетевых коммутаторов, должны об этом помнить. Несмотря на то что большинство компьютеров сегодня имеет обратный порядок байтов, интернет-трафик стандартизировал прямой порядок, потому что большинство ранних сетевых маршрутизаторов имели соответствующие ЦП. Данные с прямым порядком окажутся искажены, если их прочитать так, как если бы порядок в них был обратным, и наоборот.
Эмуляторы. Иногда бывает полезно на своем компьютере выполнить некоторый программный код, разработанный для другого ЦП. Это позволяет протестировать приложение для iPhone без iPhone или сыграть в вашу любимую старинную игру для Super Nintendo. Для этих задач существуют компоненты программного обеспечения, которые называются эмуляторами.
Эмулятор имитирует целевую машину: компьютер притворяется, что имеет тот же ЦП, ОЗУ и другие аппаратные средства. Команды декодируются программой эмулятора и выполняются в эмулированной машине. Как вы понимаете, очень сложно эмулировать одну машину внутри другой, когда у них разная архитектура. Но поскольку наши компьютеры намного быстрее старых, это стало возможным. Если вы раздобудете эмулятор Game Boy и позволите своему компьютеру создать виртуальную игровую приставку, то сможете играть в игры точно так же, как если бы вы играли на настоящем Game Boy.
7.2. Компиляторы
Мы программируем компьютеры, чтобы они могли делать МРТ, распознавать речь, исследовать далекие планеты и выполнять много других сложных задач. Удивительно, но все, на что способен компьютер, в конечном счете осуществляется посредством простых команд ЦП, которые просто суммируют и сравнивают числа. Сложные приложения, например интернет-браузер, требуют миллионов или миллиардов таких машинных команд.
Но мы редко пишем программы непосредственно как команды ЦП. Человеку не под силу написать реалистичную трехмерную компьютерную игру подобным образом. Чтобы выражать свои предписания более естественным и компактным образом, люди создали языки программирования. Мы пишем программный код на этих языках, а затем используем программу, которая называется компилятором, для перевода наших предписаний в машинные команды, понятные процессору.
Чтобы объяснить, что делает компилятор, давайте представим простую математическую аналогию. Если мы хотим попросить кого-то вычислить факториал числа 5, мы можем задать вопрос:
5! = ?
Однако если человек, которого мы спрашиваем, не знает, что такое факториал, то вопрос не будет иметь смысла. Нам придется его перефразировать, используя более простые операции:
5 × 4 × 3 × 2 × 1 = ?
А вдруг человек, которого мы спрашиваем, умеет только суммировать? Нам придется упростить наше выражение еще больше:
5 + 5 + 5 + 5 + 5 + 5 + 5 + 5 + 5 + 5 + 5 + 5+
5 + 5 + 5 + 5 + 5 + 5 + 5 + 5 + 5 + 5 + 5 + 5 = ?
По мере того как мы переписываем наше вычисление во все более простой форме, требуется все больше операций. Так же обстоит дело и с машинным кодом. Компилятор переводит сложные предписания на языке программирования в эквивалентные команды ЦП. Задействуя мощные возможности внешних библиотек, мы выражаем сложные программы, состоящие из миллиардов команд ЦП, посредством относительно небольшого числа строк программного кода, которые понятны и легко изменяемы.
Алан Тьюринг, основоположник компьютерных вычислений, обнаружил, что простые машины способны вычислить все, что в принципе поддается вычислению. Чтобы обладать универсальными вычислительными возможностями, машина должна уметь выполнять программу, которая содержит команды:
• чтения и записи данных в памяти;
• условного ветвления (если адрес памяти имеет заданное значение, то перейти к другой точке в программе).
Машины, обладающие универсальными вычислительными возможностями, называются полными по Тьюрингу. Не имеет значения, насколько длинным или запутанным является вычисление, оно всегда может быть выражено с точки зрения простых команд чтения/записи и перехода. При достаточном количестве времени и памяти эти команды способны вычислять что угодно.
Недавно было показано, что команда ЦП под названием MOV («перемещение») является полной по Тьюрингу. Это значит, что ЦП, который выполняет только команду MOV, способен делать все то, что может полноценный ЦП. Другими словами, любой тип программного кода вполне реально выразить исключительно с помощью команды MOV.
Важный вывод из этой новости состоит в том, что если программу можно записать на языке программирования, то ее можно переписать для выполнения на любой полной по Тьюрингу машине, какой бы простой та ни была. Компилятор — это волшебная программа, которая автоматически транслирует код из сложного языка в более простой.
Рис. 7.8
Операционные системы
Скомпилированные компьютерные программы по существу являются последовательностями команд ЦП. Как мы выяснили, код, скомпилированный для настольного компьютера, не станет работать на смартфоне, потому что эти машины имеют процессоры различной архитектуры. Но скомпилированная программа может не работать и на одном из двух компьютеров, имеющих одинаковую архитектуру ЦП. Дело в том, что программы, чтобы запускаться без проблем, должны взаимодействовать с операционной системой (ОС) компьютера.
Чтобы осуществлять контакты с внешним миром, программе нужно вводить и выводить информацию: открывать файлы, писать сообщения на экране, устанавливать сетевое соединение и т.д. Но разные компьютеры имеют разные аппаратные средства. Программа сама по себе не способна поддерживать все существующие типы экранов, звуковых карт или сетевых плат.
Вот почему в своей работе программы опираются на операционную систему. Благодаря ее помощи они легко работают с различными аппаратными средствами. Программы совершают специальные системные вызовы, чтобы ОС выполнила необходимые операции ввода-вывода. Компиляторы переводят команды ввода-вывода в надлежащие системные вызовы.
Однако разные ОС часто используют несовместимые системные вызовы. Системный вызов печати чего-либо на экране в Windows отличается от такового в Mac OS или Linux.
Вот почему, если вы компилируете программу для выполнения в Windows с процессором x86, она не будет работать в Mac с таким же процессором. Скомпилированный программный код должен быть ориентирован не только на конкретную архитектуру процессора, но и на конкретную операционную систему.
Оптимизация при компиляции
Хорошие компиляторы стараются оптимизировать машинный код, который они генерируют. Если они видят, что части вашего кода можно заменить более эффективными эквивалентами, они это сделают. Компиляторы порой применяют сотни правил оптимизации, прежде чем произвести двоичный код.
Именно поэтому вам не следует жертвовать простотой чтения кода в пользу его микрооптимизации. Компилятор так или иначе применит все тривиальные оптимизации. Посмотрите на этот фрагмент кода:
function factorial(n)
if n > 1
return factorial(n - 1) * n
else
return 1
Кто-то скажет, что его лучше заменить на этот эквивалент:
function factorial(n)
result ← 1
while n > 1
result ← result * n
n ← n - 1
return result
Да, выполнение процедуры factorial без рекурсии использует меньше вычислительных ресурсов. Но это еще не повод менять программный код. Современные компиляторы автоматически перепишут простые рекурсивные функции. Вот еще один пример:
i ← x + y + 1
j ← x + y
Компиляторы избавятся от повторного вычисления x + y и сделают вот такое преобразование:
t1 ← x + y
i ← t1 + 1
j ← t1
Сосредоточьтесь на написании чистого и ясного программного кода. Если у вас есть проблемы, связанные с производительностью, используйте инструменты профилирования для обнаружения узких мест в вашем программном коде и пробуйте реализовать эти части более умными способами. Не стоит напрасно тратить время на ненужную микрооптимизацию.
Впрочем, иногда этап компиляции просто отсутствует. Давайте посмотрим, что это за ситуации.
Языки сценариев
Некоторые языки программирования, так называемые языки сценариев, выполняются без прямой компиляции в машинный код. К ним относятся JavaScript, Python и Ruby. Код на этих языках выполняет не центральный процессор непосредственно, а интерпретатор — программа, которая должна быть установлена на компьютере.
Так как интерпретатор переводит программный код в машинный в режиме реального времени, тот обычно работает намного медленнее скомпилированного кода. С другой стороны, программист может выполнить код, не ожидая окончания компиляции. Когда проект очень большой, компиляция иногда занимает несколько часов.
Инженерам Google приходилось постоянно компилировать большие пакеты кода. Это заставляло разработчиков терять (рис. 7.9) много времени. В Google не могли переключиться на языки сценариев — нужна была максимальная производительность скомпилированного двоичного файла. Поэтому они разработали Go — язык, который компилируется невероятно быстро и имеет очень высокую производительность.

Рис. 7.9. Компиляция
Дизассемблирование и обратный инженерный анализ
Восстановить исходный код скомпилированной программы — тот, что был до момента компиляции, — нельзя. Но можно декодировать бинарную программу, трансформировав числа, в которых закодированы команды ЦП, в последовательность команд, более-менее понятную для человека. Этот процесс называется дизассемблированием.
Затем можно рассмотреть команды ЦП и попытаться выяснить, что они делают, — такой процесс называется обратным инженерным анализом. Некоторые программы дизассемблирования значительно помогают в этом, автоматически обнаруживая и аннотируя системные вызовы и часто используемые функции. Благодаря инструментам дизассемблирования хакер может разобраться в любом аспекте работы двоичного кода. Я уверен, что многие лучшие компании в области ИТ имеют секретные лаборатории обратного инженерного анализа, где изучают программное обеспечение конкурентов.
Хакеры часто анализируют двоичный код лицензируемых программ, таких как Microsoft Windows, Adobe Photoshop и Grand Theft Auto, чтобы определить, какая часть кода проверяет лицензию. Они модифицируют двоичный код, помещая команду JUMP для прямого перехода в ту часть кода, которая выполнятся после проверки лицензии. Когда модифицированный двоичный файл выполняется, он добирается до введенной команды JUMP прежде, чем будет сделана проверка достоверности лицензии. Таким образом люди запускают незаконные пиратские копии программы, не платя за лицензию.
Исследователи и инженеры по безопасности, работающие на секретные правительственные структуры, также имеют лаборатории для изучения популярного потребительского программного обеспечения, такого как iOS, Microsoft Windows или Internet Explorer. Они идентифицируют потенциальные нарушения защиты в этих программах, чтобы обезопасить людей от кибератак или предотвратить взлом целей, имеющих большую ценность. Самой известной атакой такого рода был Stuxnet — кибероружие, созданное агентствами из США и Израиля. Оно замедлило ядерную программу Ирана, инфицировав компьютеры, которые управляли подземными термоядерными реакторами.
Программное обеспечение с открытым исходным кодом
Как мы уже объясняли, вы можете проанализировать команды дизассемблированной программы, но вам не удастся восстановить исходный код, который использовался для генерирования двоичного кода, так называемого бинарника.
Не имея исходного кода, вы можете лишь слегка изменить двоичный код, но у вас не выйдет внести в программу какое-либо существенное изменение, например добавить новый функционал. Некоторые люди считают, что намного лучше разрабатывать программы сообща. Они оставляют свой код открытым для других людей, чтобы те могли вносить свои изменения. Главная идея здесь — создавать программное обеспечение, которое всякий может свободно использовать и модифицировать. Основанные на Linux операционные системы (такие как Ubuntu, Fedora и Debian) являются открытыми, тогда как Windows и Mac OS — закрытыми.
Интересное преимущество операционных систем с открытым исходным кодом состоит в том, что любой может проинспектировать исходный код в поисках уязвимостей. Уже не раз было подтверждено, что государственные учреждения шпионят за миллионами граждан, используя неисправленные уязвимости защиты в повседневном потребительском программном обеспечении.
Надзор за ПО с открытым исходным кодом осуществляет куда больше глаз, поэтому лицам с дурными намерениями и правительственным учреждениям становится все труднее находить лазейки для слежки. Когда вы используете Mac OS или Windows, вам приходится доверять Microsoft или Apple, что они не поставят под угрозу вашу безопасность и приложат все усилия для предотвращения любого серьезного дефекта. А вот системы с открытым исходным кодом открыты для общественного контроля, потому в случае с ними меньше вероятность, что брешь в системе безопасности останется незамеченной.
7.3. Иерархия памяти
Мы знаем, что компьютер работает за счет ЦП, который исполняет простые команды. Мы знаем также, что эти команды могут оперировать только данными, хранящимися в регистрах ЦП. Однако их емкость обычно намного меньше тысячи байтов. Это означает, что регистрам ЦП постоянно приходится перемещать данные в ОЗУ и обратно.
Если доступ к памяти медленный, то ЦП приходится простаивать, ожидая, пока ОЗУ выполнит свою работу. Время, которое требуется, чтобы прочитать и записать данные в память, непосредственно отражается на производительности компьютера. Увеличение скорости памяти может разогнать ваш компьютер так же, как увеличение скорости ЦП. Данные в регистрах ЦП выбираются почти моментально самим процессором всего в одном цикле. А вот ОЗУ гораздо медленнее.
Разрыв между памятью и процессором
Недавние технические разработки позволили экспоненциально увеличивать скорость ЦП. Быстродействие памяти тоже растет, но гораздо медленнее. Эта разница в производительности между ЦП и ОЗУ называется разрывом между памятью и процессором: команды ЦП «дешевы» — мы можем выполнять их в огромном количестве, тогда как получение данных из ОЗУ занимает намного больше времени и потому обходится «дорого». По мере увеличения этого разрыва возрастала важность эффективного доступа к памяти (рис. 7.10).
В современных компьютерах требуется приблизительно тысяча циклов ЦП, чтобы получить данные из ОЗУ, — около 1 микросекунды. Это невероятно быстро, но составляет целую вечность по сравнению со временем доступа к регистрам ЦП. Программистам приходится искать способы сократить количество операций с ОЗУ.
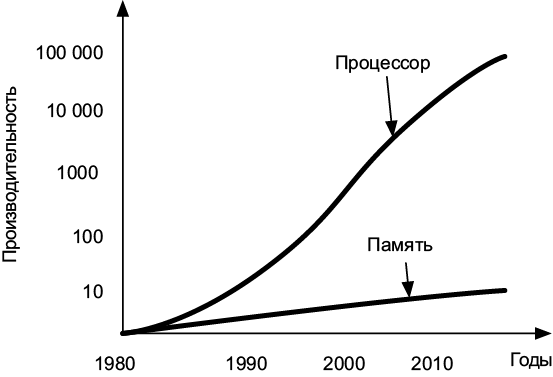
Рис. 7.10. Разрыв в быстродействии между памятью и процессором в последние десятилетия
Временная и пространственная локальность
Пытаясь свести к минимуму количество обращений к ОЗУ, специалисты в области computer science стали замечать две закономерности, получившие следующие названия:
• временная локальность — если выполняется доступ к некоему адресу памяти, то вполне вероятно, что к нему вскоре обратятся снова;
• пространственная локальность — если выполняется доступ к адресу памяти, то вполне вероятно, что к смежным с ним адресам вскоре обратятся тоже.
Если исходить из вышеприведенных наблюдений, можно подумать, что хранить такие адреса памяти в регистрах ЦП — отличная идея. Это позволило бы избежать большинства дорогостоящих операций с ОЗУ. Однако отраслевые инженеры не нашли надежного способа разработать микросхемы ЦП с достаточным количеством внутренних регистров. И тем не менее они обнаружили отличный способ опереться на временную и пространственную локальность. Давайте посмотрим, как он работает.
Кэш L1
Есть возможность сформировать чрезвычайно быструю вспомогательную память, интегрированную в ЦП. Мы называем ее кэшем первого уровня, или кэшем L1. Получение данных из этой памяти в регистры осуществляется чуть-чуть медленнее, чем получение данных из самих регистров.
При помощи кэша L1 мы можем копировать содержимое адресов памяти, причем скорость доступа с высокой вероятностью будет близка к скорости регистров ЦП. Данные очень быстро загружаются в регистры ЦП. Требуется где-то 10 циклов ЦП, чтобы переместить данные из кэша L1 в регистры. Это в сто раз быстрее ситуации, когда их приходится брать из ОЗУ.
Более половины обращений к ОЗУ можно выполнить за счет кэша L1 объемом 10 Кб и умного использования временной и пространственной локальности. Это новаторское решение привело к коренному изменению вычислительных технологий. Оборудование ЦП кэшем L1 позволило кардинально сократить время, которое процессору прежде приходилось тратить на ожидание данных. Вместо простоев он теперь занят выполнением фактических вычислений.
Кэш L2
Можно было бы дальше увеличивать размер кэша L1 — выборка данных из ОЗУ тогда стала бы еще более редкой операцией, а время ожидания ЦП еще больше сократилось бы. Однако такое усовершенствование сопряжено с трудностями. Когда кэш L1 достигает размера около 50 Кб, его дальнейшее увеличение становится очень дорогостоящим. Куда лучшее решение состоит в том, чтобы сформировать дополнительный кэш памяти — кэш второго уровня, или кэш L2. Он будет медленнее, зато намного больше кэша L1 по объему. Современный ЦП имеет кэш L2 объемом около 200 Кб. Чтобы переместить данные из кэша L2 в регистры, требуется примерно 100 циклов процессора.

Рис. 7.11. Микрофотография процессора Intel Haskell-E. Квадратные структуры в центре — это кэш L3 объемом 20 Мб
Адреса, имеющие очень высокую вероятность доступа, мы копируем в кэш L1. Адреса с относительно высокой вероятностью — в кэш L2. Если адреса нет в кэше L1, процессор может попытаться найти его в кэше L2, и только если этот поиск закончится неудачей, ему придется обращаться к ОЗУ.
Многие производители теперь поставляют процессоры с кэшем L3: он больше и медленнее, чем L2, но по-прежнему быстрее ОЗУ. Кэши L1/L2/L3 имеют настолько важное значение, что занимают большую часть кремниевого пространства внутри микросхемы ЦП (рис. 7.11).
Использование кэшей L1/L2/L3 существенно увеличивает производительность компьютеров. Благодаря кэшу L2 емкостью 200 Кб менее 10 % запросов к памяти, которые делает ЦП, приходятся на выборку непосредственно из ОЗУ.
В следующий раз, когда вы пойдете покупать компьютер, не забудьте сравнить размеры кэшей L1/L2/L3 процессоров. Более хорошие ЦП будут иметь кэш большей емкости. Лучше взять ЦП с меньшей тактовой частотой, но с более объемным кэшем.
Первичная память против вторичной
Как показано на рис. 7.12, компьютер имеет разные типы памяти, организованные иерархически. Наиболее эффективные типы имеют ограниченную емкость и очень дорого стоят. Спускаясь по иерархии вниз, мы получаем больше памяти, но скорость доступа к ней становится все меньше.
После регистров ЦП и кэшей в иерархии памяти находится ОЗУ. Она отвечает за хранение данных и кода всех выполняющихся процессов. По состоянию на 2017 год компьютер обычно имеет ОЗУ емкостью от 1 до 10 Гб. Во многих случаях этого недостаточно, чтобы разместить операционную систему со всеми другими выполняющимися программами.
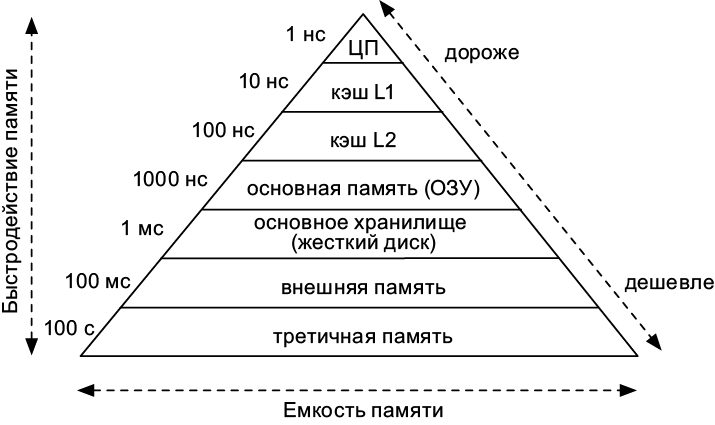
Рис. 7.12. Диаграмма иерархии памяти
В этих случаях приходится спускаться ниже по иерархической лестнице и использовать жесткий диск. По состоянию на 2017 год компьютеры обычно имеют жесткие диски емкостью в сотни гигабайт — этого более чем достаточно, чтобы уместить данные из всех выполняющихся программ. Когда ОЗУ заполнено, мы перемещаем временно не используемые данные на жесткий диск, чтобы высвободить немного оперативной памяти.
Но проблема в том, что жесткие диски работают чрезвычайно медленно. Как правило, на перемещение данных между диском и ОЗУ требуется миллион циклов ЦП — целая миллисекунда. Может показаться, что это все равно быстро, но не забывайте: в то время как доступ к ОЗУ занимает всего 1000 циклов, на доступ к диску их уходит миллион. ОЗУ нередко носит название первичной памяти, а программы и данные, хранящиеся на жестком диске, являются вторичной памятью.
ЦП не может обращаться к вторичной памяти напрямую. Программы, которые хранятся во вторичной памяти, нужно скопировать в первичную — только тогда они будут исполнены. В действительности всякий раз, когда вы загружаете компьютер, даже операционную систему приходится копировать с диска в ОЗУ, прежде чем ЦП сможет ее выполнить.
Никогда не истощайте ОЗУ! Очень важно, чтобы все данные и программы, которыми компьютер управляет во время обычной работы, могли уместиться в его ОЗУ. В противном случае он будет постоянно перемещать их между диском и ОЗУ. Поскольку этот процесс очень медленный, производительность компьютера сильно падает, и он становится бесполезным. В таком случае он большую часть времени ждет, пока данные будут перемещены, вместо того чтобы выполнять фактические вычисления.
Когда компьютер постоянно перемещает данные с диска в ОЗУ, мы говорим, что он вошел в режим интенсивной подкачки. Эту ситуацию необходимо постоянно отслеживать — особенно в случае с серверами: если они начинают обрабатывать данные, не умещающиеся в ОЗУ, такой режим работы может вывести их из строя. Следствием этого, например, становится длинная очередь в банке или у кассового аппарата, — и оператору ничего не останется, кроме как валить все на сбой компьютерной системы. Недостаточный объем ОЗУ, возможно, является одной из главных причин отказа серверов.
Внешняя и третичная память
Спустимся еще ниже по иерархической лестнице памяти. Если компьютер подключить к локальной или Глобальной сети, он может получить доступ к памяти, управляемой другими компьютерами. Но этот процесс требует еще больше времени: если на чтение локального диска уходит миллисекунда, то получение данных из сети может занимать сотни миллисекунд. Только на то, чтобы сетевой пакет переместился с одного компьютера на другой, требуется порядка десяти миллисекунд. Если сетевой пакет проходит через Интернет, то он часто движется намного дольше, от двухсот до трехсот миллисекунд — столько времени у нас уходит, чтобы моргнуть  .
.
В самом низу иерархии находится третичная память — устройства хранения, которые не всегда подключены к сети и доступны. Мы можем хранить десятки миллионов гигабайт данных на магнитном носителе или компакт-дисках. Доступ к таким данным, однако, требует, чтобы кто-то взял носитель и вставил его в считывающее устройство. Это может занимать минуты, а может и дни. Третичная память подходит только для архивации данных, к которым редко обращаются.
Тенденции в технологии памяти
Технология, используемая в быстродействующих устройствах памяти (которые находятся в верхней части иерархической лестницы), с большим трудом поддается качественному улучшению. С другой стороны, «медленные» устройства памяти становятся быстрее и дешевле. Стоимость хранения данных на жестком диске десятилетиями падала, и, по всей видимости, эта тенденция будет продолжаться (рис. 7.13).
Кроме того, новые технологии приводят к ускорению дисков. Мы переключаемся с магнитных вращающихся дисков на твердотельные (SSD). Отсутствие подвижных частей делает их быстрее, надежнее и менее затратными в энергетическом плане.
SSD-диски становятся дешевле и быстрее каждый день, но они по-прежнему стоят дорого. Некоторые производители выпускают гибридные диски, сочетающие технологии SSD и магнитных дисков. Данные, к которым приходится обращаться часто, хранятся в SSD, а те, что бывают нужны реже, — в более медленном магнитном разделе. Когда последние начинают запрашиваться часто, они копируются в SSD-раздел гибридного диска — точно так же, как в случае с ОЗУ и кэшами в процессоре.
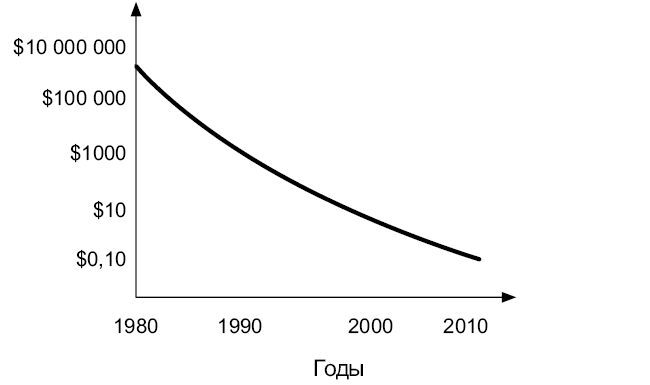
Рис. 7.13. Стоимость дисковой памяти в расчете на гигабайт объема
Подведем итоги
В этой главе мы разобрались с несколькими простыми принципами устройства компьютеров. Мы увидели, что всё, поддающееся вычислению, можно выразить в виде простых команд. Мы также узнали, что существует программа, называемая компилятором, которая транслирует наши сложные вычислительные команды в простые, понятные для ЦП. Компьютеры способны делать сложные вычисления просто потому, что их процессоры выполняют огромное количество базовых операций.
Мы узнали, что наши компьютеры имеют быстродействующие процессоры, но относительно медленную память. Доступ к памяти осуществляется не наугад, а согласно пространственной и временной локальностям. Это позволяет использовать более быстрые типы памяти для кэширования тех данных, доступ к которым производится наиболее часто. Мы проследили применение этого принципа на нескольких уровнях кэширования: от кэша L1 вниз по иерархической лестнице вплоть до третичной памяти.
Принцип кэширования, речь о котором шла в этой главе, применим во многих сценариях. Идентификация частей данных, которые используются вашим приложением чаще, и ускорение доступа к ним — одна из наиболее широко используемых стратегий, предназначенных для ускорения компьютерных программ.
Полезные материалы
• Таненбаум Э., Остин Т. Архитектура компьютера. — СПб.: «Питер», 2017.
• Современная реализация компилятора на C (Modern Compiler Implementation in C, Appel, ).
Оперативное запоминающее устройство (англ. RAM, random access memory). Более точное наименование на русском — запоминающее устройство (память) с произвольным доступом, сокращенно ЗУПД (ППД).
Центральный процессор (англ. CPU, central processing unit).
Двоичные числа выражены в системе счисления с основанием 2. Приложение I объясняет, как это следует понимать.
Программный код даже может изменять сам себя за счет включения команд, которые переписывают части собственного кода в ОЗУ. Нередко компьютерные вирусы поступают именно так, чтобы затруднить их обнаружение антивирусным ПО. Здесь можно провести удивительную параллель с биологическими вирусами, изменяющими свои ДНК, чтобы спрятаться от иммунной системы носителей.
Не путайте эту аббревиатуру с общепринятым акронимом для Personal Computer (PC) — «персональный компьютер».
Во многих персональных компьютерах эта программа называется BIOS (англ. basic input/output system, «базовая система ввода-вывода»).
О процессоре с 1000 ядер исследователи объявили еще в 2016 году.
Дисковая операционная система (Disk Operating System). Об операционных системах мы вскоре расскажем подробнее.
О языках программирования подробнее будет рассказано в следующей главе.
Можете взглянуть на компилятор, который превращает любой код на C в двоичный код лишь с одной машинной командой MOV: .
Любезно предоставлено .
Любезно предоставлено .
По крайней мере, на данный момент. С развитием искусственного интеллекта это когда-нибудь окажется возможным.
В ЦП с таковой частотой 1 ГГц один цикл длится порядка одной миллиардной секунды — время, которое необходимо, чтобы свет прошел расстояние от страницы этой книги до ваших глаз.
Нужно где-то 10 микросекунд, чтобы звуковые волны вашего голоса достигли человека, который стоит перед вами.
Стандартная фотографическая съемка фиксирует свет в течение примерно четырех миллисекунд.
Не верите? Тогда ближе к вечеру пятницы попросите ИТ-отдел сделать резервную копию магнитных лент.

