Книга: О чём не пишут в книгах по Delphi
Назад: 4.9. Однопроходный калькулятор и функции с несколькими переменными
Дальше: Приложение 1 Сайт "Королевство Delphi"
4.10. Еще немного теории
Теперь, познакомившись с синтаксическим анализом на практике, вернемся к теории и немного поговорим о типах грамматик и об альтернативных методах синтаксического анализа и вычисления выражений. Эти вопросы мы здесь рассмотрим только ознакомительно, а более детальное их описание можно найти в [6–8].
Грамматики языков по способу описания можно разделить на четыре типа, причем каждый следующий тип является подмножеством предыдущего.
1. Общие грамматики. Синтаксические правила в этих грамматиках имеют вид a ::= b, где а и b — произвольные цепочки из терминальных и нетерминальных символов (возможно, пустые). Единственное требование — хотя бы в одной из этих цепочек должен быть хотя бы один нетерминальный символ.
2. Контекстно-зависимые грамматики. Здесь правила имеют следующий вид a<X>b ::= acb, где а, b и c — произвольные цепочки терминальных и нетерминальных символов, <X> — некоторый нетерминальный символ. Таким образом, символ <X> может заменяться на последовательность символов c только в контексте цепочек a и b.
3. Контекстно-свободные грамматики. Это контекстно-зависимые грамматики, из которых убран контекст, т.е. правила записываются в виде <X> ::= с. В контекстно-свободных грамматиках нетерминальный символ <X> заменяется на цепочку c в любом контексте.
4. Регулярные (они же — автоматные) грамматики. Это контекстно-свободные грамматики, в которых запрещены любые формы рекурсивных определений.
Из этих определений легко сделать вывод, что в данной главе, пока мы не ввели в выражения скобки, наши грамматики относились к классу регулярных, а со скобками — к классу контекстно-свободных грамматик. Что же касается первых двух классов грамматик, то они неудобны ни для распознавания человеком, ни для написания анализаторов, поэтому данные грамматики применяются, в основном, только для описания естественных языков.
Регулярные грамматики описывают множество синтаксических правил, встречающихся в жизни, поэтому их часто применяют. Существует также альтернативный способ записи регулярной грамматики — регулярные выражения (мы их здесь рассматривать не будем). Различные библиотеки для распознавания регулярных выражений очень популярны, классы для распознавания регулярных выражений входят в .NET. Функция поиска в Delphi (меню Search/Find…. и т.п.) включает в себя возможности поиска последовательностей символов, заданных регулярным выражением (опция Regular expressions в диалоговом окне), поэтому краткое описание синтаксиса регулярных выражений можно найти в справке Delphi.
Примечание
Рекурсии в регулярных выражениях очень не хватает, когда нужно описать, например, возможность бесконечной вложенности скобок. Поэтому в некоторых анализаторах к регулярным выражениям добавляется возможность описывать бесконечное вложение структур. Эти выражения строго говоря, уже не являются регулярными, хотя их обычно продолжают так называть.
С регулярными грамматиками тесно связаны конечные автоматы. Конечный автомат — это устройство (виртуальное), с входом, на который подаются данные, набором состояний и набором правил перехода из одного состояния в другое. Правила перехода определяются символами, подаваемыми на вход, и формулируются следующим образом: "Если автомат находится в состоянии А, и на вход поступил символ X, автомат переходит в состояние В". Таким образом, выражение посимвольно передается на вход конечного автомата, и каждый символ вызывает переход автомата из одного состояния в другое (допустима ситуация, когда символ оставляет текущее состояние неизменным). Если при поступлении очередного символа автомат не находит правила, которое определяет очередной переход, считается, что на вход подан некорректный символ, т.е. выражение ошибочно. Допустимость выражения определяется также тем, в каком состоянии оказывается автомат после того, как все выражение подано на его вход. Часть состояний считается допустимыми в качестве конечного состояния, часть — недопустимыми. Если по окончании своей работы автомат оказывается в недопустимом состоянии, выражение также признается ошибочным.
Можно доказать, что для каждой регулярной грамматики можно построить конечный автомат, и, наоборот, для каждого конечного автомата можно (построить регулярную грамматику. Именно поэтому регулярные грамматики напиваются также автоматными.
Конечный автомат очень наглядно представляется с помощью графа, углами которого служат состояния автомата, ребрами — переходы между состояниями. Каждое ребро помечается символами, при поступлении на вход которых этот переход становится возможным. На рис. 4.3 показан пример такого изображения конечного автомата, соответствующего грамматике вещественного числа. Кружки с одинарной границей изображают состояния, недопустимые в качестве конечного, с двойной границей — допустимые. До начала работы автомат находится в состоянии 0, каждый следующий символ переводит его в соответствующее состояние. Конечное состояние 1 соответствует числу без дробной части и экспоненты, состояние 3 — числу с дробной частью без экспоненты, состояние 6 — числу с экспонентой.
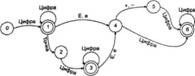
Рис. 4.3. Конечный автомат для грамматики вещественного числа
Контекстно-свободные автоматы не пригодны для распознавания контекстно-свободных грамматик с рекурсией. Для этого класса грамматик можно применить МП-автоматы (автоматы с магазинной памятью). Эти автоматы обладают стеком, и символ, поступающий на вход, не только определяет правило перехода, но и может быть сохранен в стеке, а правила перехода могут учитывать не только поступивший на вход символ, но и символ, лежащий на вершине стека. Если символ на вершине стека учитывается правилом, при применении этого правила символ извлекается из стека.
Главное достоинство МП-автоматов по сравнению с методом рекурсивного спуска (так называется метод построения синтаксического анализатора, который мы использовали) является то, что код автомата универсален и может быть применен к любому набору правил. Таким образом, появляется возможность создавать анализаторы, правила для которых хранятся, например, во внешнем файле или в базе данных, и грамматика может быть изменена без перекомпиляции анализатора. Недостатки МП-автоматов — малая наглядность кода и медленная работа из-за возможности захода в тупиковые ветки. Поэтому метод рекурсивного спуска применяется всегда, когда нет нужды менять грамматику во время работы программы.
В книге [6] описана интересная разновидность МП-автоматов — табличный анализатор, который в некоторых случаях может оказаться предпочтительнее метода рекурсивного спуска.
Арифметические выражения, которые мы разбирали в этой главе, записаны в привычной нам инфиксной форме, т.е. когда знак бинарной операции ставится между операндами. Кроме инфиксной, существует также префиксная и постфиксная формы записи выражения, в которых оператор записывается, соответственно, перед и после операндов. Например выражение "2+2" в префиксной форме запишется как "+2 2", в постфиксной — "2 2+". Префиксная форма называется польской записью, постфиксная — польской инверсной записью (в честь польского математика Яна Лукасевича, который разработал эти формы записи).
Достоинства префиксной и постфиксной форм записи — отсутствие скобок и одинаковый приоритет всех операций. Например, выражение "2+(2*2)" в постфиксной записи имеет вид "2 2 * 2 +", а выражение "(2+2)*2", соответственно, "2 2 + 2 *". Операции всегда выполняются в том порядке, в котором они следуют в выражении.
Примечание
Префиксная запись имеет много общего принятым обозначением функций. Представим, что в некотором языке программирования нет встроенной инфиксной операции сложения, но есть функция +, которая принимает два аргумента и возвращает их сумму и аналогичные функции для других бинарных операторов. В привычной форме записи функций, когда аргументы заключаются в скобки, приведенное выражение будет выглядеть так "+(2, +(2, 2)". Теперь достаточно убрать из него скобки и запятые, чтобы получить префиксную запись выражения в классическом виде. Постфиксная запись получается из функциональной подобным образом, надо только ввести правило, что имя функции пишется не перед списком аргументов, а после него.
По своим выразительным возможностям постфиксная и префиксная записи равноценны, но при вычислении выражения, заданного префиксной записью, требуется рекурсивный алгоритм, а при вычислении выражения в постфиксной записи достаточно линейного алгоритма и стека, поэтому чаще встречается постфиксная форма. Алгоритм вычисления постфиксного выражения очень прост. Если очередная лексема — это число, кладем его в стек. Если очередная лексема — бинарный оператор, выталкиваем из стека два верхних значения, применяем к ним операцию и результат помещаем обратно в стек. Алгоритм легко обобщается на операторы с любым количеством операндов: соответствующая операция выталкивает из стека не два, а нужное ей число параметров. Функция от N аргументов рассматривается как операция, применяющаяся к N операндам.
Простота постфиксной записи делает ее очень привлекательной для низкоуровневого программирования. Метолом рекурсивного спуска достаточно легко создать код, переводящий выражение из инфиксной формы в постфиксную, а затем вычислить выражение уже в постфиксной форме. В простейшем случае такой промежуточный перевод только замедляет вычисления, и поэтому не используется, но иногда (например, при многократном вычислении одного выражения) перевод в постфиксную запись может сильно ускорить вычисления, тем более что выражение в постфиксной форме можно хранить не в виде строки, а в виде списка лексем, что еще больше ускорит его вычисление. В частности, код для стековой Java-машины, вычисляющий выражения, по сути эквивалентен постфиксной записи выражения.
Конечно, синтаксический анализ — вещь непростая, и здесь мы рассмотрели только самые его основы. За рамками книги остались атрибутивные грамматики, семантические деревья, генераторы языков и многое другое. Этим сложным вопросам посвящены специализированные книги. Долгое время ощущалась нехватка книг по данной тематике, но за последние два года вышли сразу три книги ([6–8]), посвященные созданию трансляторов. В этих книгах детально разбираются фундаментальные основы теории и даются примеры ее использования. Особенно стоит отметить книгу [6], в которой описан очень интересный язык программирования — Оберон-2, созданный при участии Никлауса Вирта; в нем развиваются идеи, заложенные Виртом в Паскаль. Ряд идей, предложенных при создании различных версий Оберона, уже позаимствованы другими языками (Java, C#, Ада), и еще многие ждут своего часа, поэтому программисту следует хотя бы ознакомительно изучить Оберон, чтобы понимать, в каком направлении может пойти развитие языков программирования.
В качестве источника полезных сведений можно также посоветовать книги, посвященные не столько теории разработки языков программирования, сколько истории их развития, например, [5, 9]. Теория синтаксического и семантического анализа в них изложена относительно неглубоко, но тесная связь изложения с практическими примерами позволяет существенно расширить кругозор в данной области. Особенно рекомендуем [5]. Книга [9] содержит больше сведений, но написана более тяжелым языком, а ее авторы крайне предвзято относятся к Паскалю, ставя ему в вину его достоинства и упрекая в несуществующих недостатках. Тем не менее эту книгу тоже следует прочитать.
Назад: 4.9. Однопроходный калькулятор и функции с несколькими переменными
Дальше: Приложение 1 Сайт "Королевство Delphi"

