Книга: О чём не пишут в книгах по Delphi
Назад: 3.2. Неочевидные особенности вещественных чисел
Дальше: 3.4. Прочие "подводные камни"
3.3. Тонкости работы со строками
В этом разделе мы рассмотрим некоторые тонкости работы со строками, которые позволяют лучше понять, какой код генерирует компилятор при некоторых, казалось бы, элементарных действиях. Не все приведенные здесь примеры работают не так, как можно было бы ожидать, так что этот материал немного выходит за рамки главы. Но "подводные камни" здесь мы тоже встретим.
3.3.1. Виды строк в Delphi
Для работы с кодировкой ANSI в Delphi существует три вида строк: AnsiString, ShortString и PChar. Различие между ними заключается в способе хранения строки, а также выделения и освобождения памяти для нее. Зарезервированное слово string по умолчанию означает тип AnsiString, но если после нее следует число в квадратных скобках, то это означает тип ShortString, а число — ограничение по длине. Кроме того, существует опция компилятора Huge strings (управляется также директивами компилятора {$H+/-} и {$LONGSTRINGS ON/OFF}, которая по умолчанию включена, но если ее выключить, то слово string станет эквивалентно ShortString; или, что то же самое, string[255]. Эта опция введена для обратной совместимости с Turbo Pascal, в новых программах отключать ее нет нужды. Внутреннее устройство этих типов данных иллюстрирует рис. 3.2.
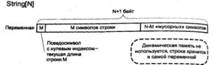
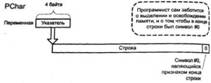
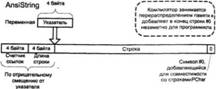
Рис. 3.2. Устройство различных строковых типов Delphi
Наиболее просто устроен тип ShortString. Это массив символов с индексами от 0 до N, где N — число символов, указанное при объявлении переменной (в случае использования идентификатора ShortString N явно не указывается и равно 255). Нулевой элемент массива хранит текущую длину строки, которая может быть меньше или равна объявленной (эту длину мы будем далее обозначать M), элементы с индексами от 1 до M — это символы, составляющие строку. Значения элементов с индексами M+1..N не определены. Все стандартные функции для работы со строками игнорируют эти символы. В памяти такая переменная всегда занимает N+1 байтов.
Ограничения типа ShortString очевидны: на хранение длины отводится только один байт, поэтому такая строка не может содержать больше 255 символов. Кроме того, такой способ записи длины не совпадает с принятым в Windows, поэтому ShortString несовместим с системными строками.
В системе приняты так называемые нуль-терминированные строки: строка передается указателем на ее первый символ, длина строки отдельно нигде не хранится, признаком конца строки считается встретившийся в цепочке символов #0. Длина таких строк ограничена только доступной памятью и способом адресации (т.е. в Windows теоретически это 4 294 967 295 символов). Для работы с такими строками предусмотрен тип PChar. Переменная такого типа является указателем на начало строки. В литературе нередко можно встретить утверждение, что PChar = ^Сhar, однако это неверно: тип PChar встроен в компилятор и не выводится из других типов. Это позволяет выполнять с ним операции, недопустимые для других указателей. Во-первых, если P — переменная типа PChar, то допустимо обращение к отдельным символам строки с помощью конструкции P[N], где N — целочисленное выражение, определяющее номер символа (в отличие от типа ShortString, здесь символы нумеруются с 0, а не с 1). Во-вторых, к указателям типа PChar разрешено добавлять и вычитать целые числа, смещая указатель на соответствующее число байтов вверх или вниз (здесь речь идет только об операторах "+" и "-"; адресная арифметика с помощью процедур Inc и Dec доступна для любых типизированных указателей, а не только для PChar).
При работе с PChar программист целиком и полностью отвечает за выделение памяти для строки и за ее освобождение. Именно это и служит основным источником ошибок у новичков: они пытаются работать с такими строками так же, как и с AnsiString, надеясь, что операции с памятью будут выполнены автоматически. Это очень грубая ошибка, способная привести к самым непредсказуемым последствиям.
Хотя программист имеет полную свободу выбора в том, как именно выделять и освобождать память для нуль-терминированных строк, в большинстве случаев самыми удобными оказываются специально предназначенные для этого функции StrNew, StrDispose и т.п. Их преимущество заключается в том, что менеджер памяти выделяет чуть больше места, чем требуется для хранения строки, и в эту дополнительную память записывается, сколько байтов было выделено. Благодаря этому функция StrDispose удаляет ровно столько памяти, сколько было выделено, даже если в середину выделенного блока был записан символ #0, уменьшающий длину строки.
Компилятор также позволяет рассматривать статические массивы типа Char, начинающиеся с нулевого индекса, как нуль-терминированные строки. Такие массивы совместимы с типом PChar, что позволяет обойтись без использования динамической памяти при работе со строками.
Тип AnsiString объединяет достоинства типов ShortString и PChar: строки имеют фактически неограниченную длину, заботиться о выделении памяти для них не нужно, в их конец автоматически добавляется символ #0, что делает их совместимыми с системными строками (впрочем, эта совместимость не абсолютная; как и когда можно использовать AnsiString в функциях API, мы рассматривали в разд. 1.1.13.).
Переменная типа AnsiString — это указатель на первый символ строки, как и в случае PChar. Разница в том, что перед этой строкой в память записывается дополнительная информация: длина строки и счетчик ссылок. Это позволяет компилятору генерировать код, автоматически выделяющий, перераспределявший и освобождающий память, выделяемую для строки. Работа с памятью происходит совершенно прозрачно для программиста, в большинстве случаев со строками AnsiString можно работать, вообще не задумываясь об их внутреннем устройстве. Символы в таких строках нумеруются с единицы, чтобы облегчить перенос старых программ, использовавших строки типа ShortString.
Счетчик ссылок позволяет реализовать то, что называется copy-on-demand, копирование по необходимости. Если у нас есть две переменные S1, S2 типа AnsiString, присваивание вида S1 := S2 не приводит к копированию всей строки. Вместо этого в указатель S1 копируется значение указателя S2, а счетчик ссылок строки увеличивается на единицу. В дальнейшем, если одну из этих строк потребуется модифицировать, она сначала будет скопирована (а счетчик ссылок оригинала, естественно, уменьшен) и только потом изменена, чтобы это не затрагивало остальные переменные.
Далее мы рассмотрим, какие проблемы могут возникнуть при использовании строк разного вида.
3.3.2. Хранение строковых литералов
Литералами называются значения, записываемые в программе буквально. В частности, строковые литералы в Delphi — это последовательности символов, заключенных в кавычки или записанных в виде ANSI-кодов с использованием префикса #.
Когда в программе встречается строковый литерал, компилятор должен поместить его в какую-либо область памяти, чтобы это значение стало доступным программе. Компилятор Delphi размещает строковые литералы в сегменте кода, в участках, управление которым никогда не передается. В данном разделе мы рассмотрим, к каким последствиям это может привести.
Положим на форму пять кнопок и напишем следующие обработчики для нажатия на них (листинг 3.17, пример Constants на компакт-диске).
Листинг 3.17. Примеры работы со строковыми литералами
procedure TForm1.Button1Click(Sender: TObject);
var
P: PChar;
begin
P := 'Xest';
P[0] := 'T'; { * }
Label1.Caption := P;
end;
procedure TForm1.Buttom2Click(Sender: TObject);
var
S: string;
P: PChar;
begin
S:= 'Xest';
P := PChar(S);
P[0] := 'T'; { * }
Label1.Caption := P;
end;
procedure TForm1.Button3Click(Sender: TObject);
var
S: string;
begin
S := 'Xest';
S[1] := 'T';
Label1.Caption := S;
end;
procedure TForm1.Button4Click(Sender: TObject);
var
S: ShortString;
begin
S := 'Xest';
S[1] := 'T';
Label1.Caption := S;
end;
procedure TForm1.Button5Click(Sender: TObject);
var
S: ShortString;
P: PChar;
begin
S := 'Xest';
P := @S[1];
P[0] := 'T';
Label1.Caption := P;
end;
В этом примере только нажатие на третью и четвертую кнопку приводит к появлению надписи Test. Первые два обработчика вызывают исключение Access violation в строках, отмеченных звездочками, а при нажатии пятой кнопки программа обычно работает без исключении (хотя в некоторых случаях оно все же может возникнуть), но к слову "Test" добавляется какой-то мусор. Разберемся, почему так происходит.
Встретив в первом обработчике литерал 'Xest' и определив, что он относится к типу PChar, компилятор выделяет в подходящей области сегмента кода пять байтов (четыре значащих символа и один завершающий ноль), а в указатель P заносится адрес этого литерала. Сегмент кода доступен только для чтения, прав на его изменение система программе в целях безопасности не дает, поэтому попытка изменить то, что находится в этом сегменте, приводит к закономерному результату — выдаче сообщения "Access violation".
В обработчике второй кнопки происходит почти то же самое, с той лишь разницей. что для литерала выделяется на восемь байтов больше: т.к. в данном случае литерал имеет тип AnsiString, ему нужны еще 4 байта для хранения длины и 4 — для счетчика ссылок. В переменную S записывается указатель на этот литерал. Приводя эту переменную к типу PChar, мы, по сути, просто копируем этот указатель в переменную P, а дальше происходит то же самое — попытка изменить страницу памяти, доступную программе только для чтения с тем же самым результатом.
В третьем случае литерал, как и раньше, размещается в сегменте кода. Счетчик ссылок у таких литералов всегда равен -1 — это значение указывает менеджеру памяти, что это константа, которая не может быть изменена и память для которой не нужно освобождать. Поэтому при любой попытке изменить переменную, которой присвоен литерал, срабатывает механизм копирования по необходимости: для строки выделяется место в динамической памяти, затем значение литерала копируется в эту область, обновляется значение указателя S, а затем выполняется изменение копии, находящейся в динамической памяти. Так как эта память доступна и для чтения, и для записи, исключение не возникает, и все работает так, как и было задумано.
В четвертом случае литерал также хранится в сегменте кода, но работы с указателем уже нет. Этот литерал занимает там пять байтов: один байт на длину и четыре — на символы. Переменная S размешается в стеке, занимая там 256 байтов, а присваивание ей литерала — это копирование значения литерала из сегмента кода в область памяти, занятую переменной. Таким образом, в дальнейшем мы работаем не с константой в сегменте кода, а с ее копией в стеке, которую можно без проблем модифицировать.
В пятом случае мы получаем указатель на этот участок стека. Обратите внимание, что приведение типов в данном случае не работает: для записи в P адреса первого символа строки приходится использовать оператор получения адреса @. Модификация строки проходит, как и в предыдущем случае, успешно, но при присваивании выражения типа PChar свойству типа AnsiString длина строки определяется по правилам, принятым для PChar, т.е. строка сканируется до обнаружения нулевого символа. Но поскольку ShortString "не отвечает" за то, что будет содержаться в неиспользуемых символах, там может остаться всякий мусор от предыдущего использования стека. Никакой гарантии, что сразу после последнего символа будет #0, нет. Отсюда и появление непонятных символов на экране.
Общий вывод таков: пока мы не вмешиваемся в работу компилятора с типами ShortString и AnsiString, получаем ожидаемый результат. Работа с этими же строками через PChar в обход стандартных механизмов приводит к появлению проблем. Кроме того, при работе со строками PChar необходимо четко представлять, где и как выделяется для них память, иначе можно получить неожиданную ошибку.
3.3.3. Приведение литералов к типу PChar
В разд. 1.1.13 мы уже говорили, что когда у функции есть параметр типа PChar, и этот параметр не будет изменяться функцией, при вызове ей можно передавать строковый литерал (см. листинг 1.20). Компилятор размещает литерал в сегменте кода и передает функции указатель на эту память.
В примерах кода, приведенных на различных сайтах, можно нередко встретить такую ситуацию, когда литерал, передаваемый в качестве параметра типа PChar, явно приводится к этому типу. Разберемся, что это дает. Для этого положим на форму четыре кнопки и напишем в обработчиках их нажатия следующий код (листинг 3.18. пример PCharLit на компакт-диске).
Листинг 3.18. Приведение литералов к типу PChar
procedure TForm1.Button1Click(Sender: TObject);
begin
Application.MessageBox('Text', nil, 0);
end;
procedure TForm1.Button2Click(Sender: TObject);
begin
Application.MessageBox('A', nil, 0);
end;
procedure TForm1.Button3Click(Sender: TObject);
begin
Application.MessageBox(PChar('Text'), nil, 0);
end;
procedure TForm1.Button4Click(Sender: TObject);
begin
Application.MessageBox(PChar('A'), nil, 0);
end;
Метод TApplication.MessageBox по каким-то непонятным причинам имеет параметры типа PChar вместо string, и мы этим воспользуемся. При его вызове будет показано диалоговое окно с текстом, переданным в качестве первого параметра (в заголовке будет написано Ошибка, т.к. второй параметр у нас nil). Нажатие на первую и вторую кнопку не приводит ни к каким неожиданностям — мы видим на экране Text и А соответственно. Теперь перейдем к коду с явным приведением литерала к PChar. Нажатие на третью кнопку к сюрпризам не приведет, а вот нажатие на четвертую даст исключение Access violation.
Происходит это потому, что тип литерала зависит не только от его вида, но и оттого, в каком контексте он упомянут. Например, в предыдущем разделе мы видели, что литерал 'Xest' мог иметь тип string или PChar в зависимости от того, какой переменной он присваивался. Там, где явного приведения типов нет, тип литерала однозначно определяется по типу формального параметра, и в обработчиках нажатия первых двух кнопок компилятор создает правильные литералы 'Text' и 'А' типа PChar. Явное приведение литерала к типу PChar меняет контекст, в котором литерал упомянут, и компилятор может сделать неправильный вывод о его типе. В обработчике третьей кнопки компилятор правильно понимает, что литерал имеет тип PChar и генерирует код, полностью эквивалентный коду обработчика первой кнопки. А вот в случае приведения к типу PChar литерала 'А' компилятор принимает этот литерал не за строковый, а за символьный (т.е. за литерал типа Char), состоящий из одного символа без всяких добавлений длины, символа #0 и т.п. При приведении выражения типа Char к любому указателю (в том числе и к PChar) оно рассматривается как выражение любого порядкового типа, и его численное значение становится численным значением указателя. В нашем случае это символ с кодом 65 ($41 в шестнадцатиричной записи), поэтому в функцию передается указатель $00000041. Такой указатель указывает на ту область виртуальной памяти, которая никогда не отображается на физическую память, поэтому его использование приводит к ошибке Access violation.
Итак, мы увидели, что явное приведение литерала к типу PChar либо никак не отражается на генерируемом компилятором коде (в случае литералов из нескольких символов), либо приводит к генерированию заведомо некорректного кода (в случае односимвольных литералов). Если еще учесть, что приведение литералов к PChar загромождает код, легко сделать вывод, что приводить литералы к PChar не нужно, поскольку это потенциальный источник проблем и признак плохого оформления кода.
3.3.4. Сравнение строк
Для типов PChar и AnsiString, которые являются указателями, понятие равенства двух строк может толковаться двояко: либо как равенство указателей, либо как равенство содержимого памяти, на которую эти указатели указывают. Второй вариант предпочтительнее, т.к. он ближе к интуитивному понятию равенства строк. Для типа AnsiString реализован именно этот вариант, т.е. сравнивать такие строки можно, ни о чем не задумываясь. Более сложные ситуации мы проиллюстрируем примером Companions. В нем одиннадцать кнопок, и обработчик каждой из них иллюстрирует одну из возможных ситуаций.
Начнем со сравнения двух строк типа PChar (листинг. 3.19).
Листинг 3.19. Сравнение строк типа PChar
procedure TForm1.Button1Click(Sender: TObject);
var
P1, P2: PChar;
begin
P1 := StrNew('Test');
P2 := StrNew('Test');
if P1 = P2 then Label1.Caption := 'Равно';
else Label1.Caption := 'Не равно';
StrDispose(P1);
StrDispose(P2);
end;
В данном примере мы увидим надпись Не равно. Это происходит потому, что в этом случае сравниваются указатели, а не содержимое строк, а указатели здесь будут разные. Попытка сравнить строки с помощью оператора сравнения — весьма распространенная ошибка у начинающих. Для сравнения таких строк следует применять специальную функцию — StrComp. Следующий пример, на первый взгляд, в плане сравнения ничем не отличается от только что рассмотренного (листинг 3.20).
Листинг 3.20. Сравнение строк типа PChar, заданных одинаковыми литералами
procedure TForm1.Button2Click(Sender: TObject);
var
P1, P2: PChar;
begin
P1 := 'Test';
P2 := 'Test';
if P1 = P2 then Label1.Caption := 'Равно'
else Label1.Caption := 'Не равно';
end;
Разница только в том, что строки хранятся не в динамической памяти, a в сегменте кода. Тем не менее на экране появится надпись Равно. Это происходит, разумеется, не потому, что сравнивается содержимое строк, а потому, что в данном случае два указателя оказываются равными. Компилятор поступает достаточно интеллектуально: видя, что в разных местах указаны литералы с одинаковым значением, он выделяет для такого литерала место только один раз, а потом помещает в разные указатели один адрес. Поэтому сравнение дает правильный (с интуитивной точки зрения) результат.
Такое положение дел только запутывает ситуацию со сравнением PChar: написав подобный тест, человек может сделать вывод, что строки PChar сравниваются не по указателю, а по значению, и действовать под руководством этого заблуждения.
Раз уж мы столкнулись с такой особенностью компилятора, немного отвлечемся от сравнения строк и "копнем" этот вопрос немного глубже. В частности, выясним, распространяется ли "интеллект" компилятора на литералы типа AnsiString (листинг 3.21).
Листинг 3.21. Сравнение переменных типа AnsiString как указателей
procedure TForm1.Button3Click(Sender: TObject);
var
S1, S2: string;
begin
S1 := 'Test';
S2 := 'Test';
if Pointer(S1) = Pointer(S2) then Label1.Caption := 'Равно'
else Label1.Caption := 'He равно';
end;
В этом примере на экран будет выведено Равно. Как мы видим, указатели равны, т.е. и здесь компилятор проявил "интеллект".
Рассмотрим чуть более сложный случай (листинг 3.22).
Листинг 3.22. Сравнение переменных AnsiString и PChar как указателей
procedure TForm1.Button4Click(Sender: TObject);
var
P: PChar;
S: string;
var
S := 'Test';
P := 'Test';
if Pointer(S) = P then Label1.Caption := 'Равно'
else Label1.Caption := 'He равно';
end;
В этом случае указатели окажутся не равны. Действительно, с формальной точки зрения литерал типа AnsiString отличается от литерала типа PChar: в нем есть счетчик ссылок (равный -1) и длина. Однако если забыть с существовании этой добавки, эти два литерала одинаковы: четыре значащих символа и один #0, т.е. компилятор, в принципе, мог бы обойтись одним литералом. Тем не менее на это ему "интеллекта" уже не хватило. Рассмотрим еще один пример: сравнение строк по указателям (листинг 3.23).
Листинг 3.23. Сравнение глобальных переменных типа AnsiString как указателей
var
GS1, GS2: string;
procedure TForm1.Button5Click(Sender: TObject);
begin
GS1 := 'Test';
GS2 := 'Test';
if Pointer(GS1) = Pointer(GS2) then Label1.Caption := 'Равно';
else Label1.Caption := 'Не равно';
end;
Этот пример отличается от приведенного в листинге 3.21 только тем, что теперь переменные глобальные, а не локальные. Однако этого достаточно, чтобы результат оказался другим — на экране мы увидим надпись Не равно. Для глобальных переменных компилятор всегда создаст уникальный литерал, на обнаружение одинаковых литералов ему "интеллекта" не хватает. Более того, если поставить точки останова в методах Button3Click и Button4Click, легко убедиться, что указатель, который будет помещен в переменную S в методе Button4Click, отличается от того, который будет помещен в переменные S1 и S2 в методе Button3Click, хотя литералы в обоих случаях одинаковые. Компилятор умеет обнаруживать равенство литералов типа AnsiString только в пределах одной функции.
Теперь посмотрим, что будет с глобальными переменными типа PChar при присваивании им одинакового литерала (листинг 3.24).
Листинг 3.24. Сравнение глобальных переменных типа PChar
var
GP1, GP2: PChar;
procedure TForm1.Button6Click(Sender: TObject);
begin
GP1 := 'Test';
GP2 := 'Test';
if GP1 = GP2 then Label1.Caption := 'Равно'
else Label1.Caption := 'He равно';
end;
После выполнения этого кода мы увидим надпись Равно, т.е. здесь компилятор смог обнаружить равенство литералов, несмотря на то, что переменные глобальные. Однако переменные типа PChar, которым присваиваются одинаковые литералы в разных функциях, как и переменные типа AnsiString, получат разные значения.
Но вернемся к сравнению строк. Как мы знаем, строки AnsiString сравниваются по значению, а PChar — по указателю. А что будет, если сравнить AnsiString с PChar? Ответ на этот вопрос даёт листинг 3.25.
Листинг 3.25. Сравнение переменных типа AnsiString и PChar
procedure TForm1.Button7Click(Sender: TObject);
var
P: PChar;
S: string;
begin
S := 'Test';
P := 'Тest';
it S = Р then Label1.Caption := 'Равно'
else Label1.Caption := 'Не равно';
end;
Этот код выдаст Равно. Как мы знаем из предыдущих примеров (см. листинг 3.22), значения указателей не будут равны, следовательно, производится сравнение по содержанию, т.е. именно то, что к требуется. Если исследовать код, который генерирует компилятор, то можно увидеть, что сначала неявно создается строка AnsiString, в которую копируется содержимое строки PChar, а потом сравниваются две строки AnsiString. Сравниваются, естественно, по значению.
Для строк ShortString сравнение указателей невозможно, две таких строки всегда сравниваются по значению. Правила хранения литералов и сравнения с другими типами следующие:
1. Литералы типа ShortString размещаются в сегменте кода только один раз на одну функцию, сколько бы раз они ни повторялись в ее тексте.
2. При сравнении строк ShortString и AnsiString первая сначала конвертируется в тип AnsiString, а потом выполняется сравнение.
3. При сравнении строк ShortString и PChar строка PChar конвертируется в ShortString, затем эти строки сравниваются.
Последнее правило таит в себе «подводный камень», который иллюстрируется следующим примером (листинг 3.26).
Листинг 3.26. Ошибка при сравнении переменных типа ShortString и PChar
procedure TForm1.Button8Click(Sender: TObject);
var
P: PChar;
S: ShortString
begin
P := StrAlloc(300);
FillChar(P^, 299, 'A');
P[299] := #0;
S[0] := #255;
FillChar(S[1], 255, 'A');
if S = P then Label1.Caption := 'Равно'
else Label1.Caption := 'Не равно';
StrDispose(Р);
end;
Здесь формируется строка типа PChar, состоящая из 299 символов "A". Затем формируется строка ShortString, состоящая из 255 символов "А". Очевидно, что эти строки не равны, потому что имеют разную длину. Тем не менее на экране появится надпись Равно.
Происходит это вот почему: строка PChar оказывается больше, чем максимально допустимый размер строки ShortString. Поэтому при конвертировании лишние символы просто отбрасываются. Получается строка длиной 255 символов, совпадающая со строкой ShortString, с которой мы ее сравниваем. Отсюда вывод: если строка ShortString содержит 255 символов, а строка PChar — более 255 символов, и ее первые 255 символов совпадают с символами строки ShortString, операция сравнения ошибочно даст положительный результат, хотя эти строки не равны.
Избежать этой ошибки поможет либо явное сравнение длины перед сравнением строк, либо приведение одной из сравниваемых строк к типу AnsiString (второй аргумент при этом также будет приведен к этому типу). Следующий пример (листинг 3.27) дает правильный результат Не равно.
Листинг 3.27. Правильное сравнение переменных типа ShortString и PChar
procedure TForm1.Button9Click(Sender: TObject);
var
P: PChar;
S: ShortString;
begin
P := StrAlloc(300);
FillChar(P^, 299, 'A');
P[299] := #0;
S[0] := #255;
FillChar(S[1], 255, 'A');
if string(S) = P then Label1.Caption := 'Равно'
else Label1.Caption := 'He равно';
StrDispose(P);
end;
Учтите, что конвертирование в AnsiString — операция дорогостоящая в смысле процессорного времени (в этом примере будут выделены, а потом освобождены два блока памяти), поэтому там, где нужна производительность, целесообразнее вручную сравнить длину, а еще лучше вообще по возможности избегать сравнения строк разных типов, т.к. без конвертирования это в любом случае не обходится.
Теперь зададимся глупым, на первый взгляд, вопросом: если мы приведем строку AnsiString к PChar, будут ли равны указатели? Проверим это (листинг 3.28).
Листинг 3.28. Равенство указателей после приведения AnsiString к PChar
procedure TForm1.Button10Click(Sender: TObject);
var
S: string;
P: PChar;
begin
S := 'Test';
P := PChar(S);
if Pointer(S) = P then Label1.Caption := 'Равно'
else Label1.Caption := 'Не равно';
end;
Вполне ожидаемый результат — Равно. Можно, например, перенести строку из сегмента кода в динамическую память с помощью UniqueString — результат не изменится. Однако выводы делать рано. Рассмотрим следующий пример (листинг 3.29).
Листинг 3.29. Сравнение указателя после приведения пустой строки к PChar
procedure TForm1.Button11Click(Sender: TObject);
var
S: string;
P: PChar;
begin
S := '';
P := PChar(S);
if Pointer(S) = P then Label1.Caption : = 'Равно'
else Label1.Caption := 'He равно';
end;
От предыдущего он отличается только тем, что строка S имеет пустое значение. Тем не менее на экране мы увидим Не равно. Связано это с тем, что приведение строки AnsiString к типу PChar на самом деле не является приведением типов. Это скрытый вызов функции _LStrToPChar, и сделано так для того, чтобы правильно обрабатывать пустые строки.
Значение '' (пустая строка) для строки AnsiString означает, что память для нее вообще не выделена, а указатель имеет значение nil. Для типа PChar пустая строка — это ненулевой указатель на символ #0. Нулевой указатель также может рассматриваться как пустая строка, но не всегда — иногда это рассматривается как отсутствие какого бы то ни было значения, даже пустого (аналог NULL в базах данных). Чтобы решить это противоречие, функция _LStrToPChar проверяет, пустая ли строка хранится в переменной, и, если не пустая, возвращает этот указатель, а если пустая, то возвращает не nil, а указатель на символ #0, который специально для этого размещен в сегменте кода. Таким образом, для пустой строки PChar(S) <> Pointer(S), потому что приведение строки AnsiString к указателю другого типа — это нормальное приведение типов без дополнительной обработки значения.
3.3.5. Побочное изменение
Из-за того, что две одинаковые строки AnsiString разделяют одну область памяти, на неожиданные эффекты можно натолкнуться, если модифицировать содержимое строки в обход стандартных механизмов. Следующий код (листинг 3.30, пример SideChange на компакт-диске) иллюстрирует такую ситуацию.
Листинг 3.30. Побочное изменение переменной S2 при изменении S1
procedure TForm1.Button1Click(Sender: TObject);
var
S1, S2: string;
P: PChar;
begin
S1 := 'Test';
UniqueString(S1);
S2 := S1;
P := PChar(S1);
P[0] := 'F';
Label1.Caption := S2;
end;
В этом примере требует комментариев процедура UniqueString. Она обеспечивает то, что счетчик ссылок на строку будет равен единице, т.е. для этой строки делается уникальная копия. Здесь это понадобилось для того, чтобы строка S1 хранилась в динамической памяти, а не в сегменте кода, иначе мы получили бы Access violation, как и во втором случае рассмотренного ранее примера Constants (см. листинг 2.17).
В результате работы этого примера на экран будет выведено не Test, a Fest, хотя значение S2, казалось бы, не должно меняться, потому что изменения, которые мы делаем, касаются только S1. Но более внимательный анализ подсказывает объяснение: после присваивания S2 := S1 счетчик ссылок строки становится равным двум, а сама строка разделяется двумя указателями: S1 и S2. Если бы мы попытались изменить непосредственно S2, то сначала была бы создана копия этой строки, а потом сделаны изменения в этой копии, а оригинал, на который указывала бы S2, остался без изменений. Но, использовав PChar, мы обошли механизм копирования, поэтому строка осталась в единственном экземпляре, и изменения затронули не только S1, но и S2.
В данном примере все достаточно очевидно, но в более сложных случаях разработчик программы может и не подозревать, что строка, с которой он работает, разделяется несколькими переменными. Справка Delphi советует сначала обеспечить уникальность копии строки с помощью UniqueString и только потом работать с ней через PChar, если в этом есть необходимость.
Рассмотрим еще один пример, практически не отличающийся от предыдущего (листинг 3.31).
Листинг 3.31. Отсутствие побочного изменения переменной S2 при изменении S1
procedure TForm1.Button2Click(Sender: TObject);
var
S1, S2: string;
P: PChar;
begin
S1 := 'Test';
UniqueString(S1);
S2 := S1;
P := @S1[1];
P[0] := 'F';
Label1.Caption := S2;
end;
В этом случае на экран будет выведено Test, т.е. побочного изменения переменной не произойдёт, хотя переменная S1 по прежнему изменяется в обход стандартных механизмов Delphi.
Вся разница между двумя примерами заключается в том, как получается указатель на строку. В первом примере он является результатом приведения типа строки к PChar, а во втором — операции взятия адреса первого символа строки. По идее, это должно приводить к одинаковому результату, однако компилятор, зная, что указатель получается, возможно, для того, чтобы с его помощью менять содержимое строки, вставляет сюда неявный вызов UniqueString. В результате этого для S1 выделяется в динамической памяти другая область, чем для S2, и манипуляции с содержимым S1 больше не затрагивают S2.
Неявный вызов UniqueString при обращении к символу строки по индексу выполняется всегда, когда у компилятора есть основания ожидать изменения строки. Это снижает производительность, т.к. многие вызовы UniqueString оказываются излишними. Например, если выполняется посимвольная модификация строки в цикле, UniqueString будет вызываться на каждой итерации цикла, хотя достаточно одного вызова — перед началом цикла. Поэтому в тех случаях, когда производительность критична, посимвольную модификацию строки лучше выполнять низкоуровневыми методами, обращаясь к символам через указатели и обеспечив уникальность строки самостоятельно. Что же касается скорости получения указателя, то тут наиболее быстрым является приведение переменной типа AnsiString к типу Pointer, т.к. это вообще не приводит к генерации дополнительного кода. Приведение к типу PChar работает медленнее потому, что выполняется неявный вызов функции _LStrToPChar, а получение адреса первого символа снижает производительность из-за неявного вызова UniqueString.
Примечание
Еще раз напомним, что низкоуровневые операции с указателями небезопасны в том смысле, что компилятор почти не способен указать разработчику на ошибки в коде, если такие будут. Поэтому применять быстрые низкоуровневые средства доступа к отдельным символам строки следует только тогда, когда в этом действительно есть необходимость.
3.3.6. Нулевой символ в середине строки
Хотя символ #0 и добавляется в конец каждой строки AnsiString, он уже не является признаком ее конца, т.к. длина строки хранится отдельно. Это позволяет размещать символы #0 и в середине строки. Но нужно учитывать, что полноценное преобразование такой строки в PChar невозможно — это иллюстрируется примером Zero на компакт-диске (листинг 3.32).
Листинг 3.32. Потеря остатка строки после символа #0
procedure TForm1.Button1Click(Sender: TObject);
var
S1, S2, S3: string;
P: PChar;
begin
S1 := 'Test'#0'Test';
S2 := S1;
UniqueString(S2);
P := PChar(S1);
S3 := P;
Label1.Caption := IntToStr(Length(S2));
Label2.Caption := IntToStr(Length(S3));
end;
В первую метку будет выведено число 9 (длина исходной строки), во вторую — 4. Мы видим, что при копировании одной строки AnsiString в другую символ #0 в середине строки — не помеха (вызов UniqueString добавлен для того, чтобы обеспечить реальное копирование строки, а не только копирование указателя). А вот как только мы превращаем эту строку PChar, информация о ее истинной длине теряется, и при обратном преобразовании компилятор ориентируется на символ #0, в результате чего строка "обрубается".
Потеря куска строки после символа #0 происходит всегда, когда есть преобразование ShortString или AnsiString в PChar, даже неявное. Например, все API-функции работают с нуль-терминированными строками, а визуальные компоненты — просто обертки над этими функциями, поэтому вывести с их помощью на экран строку, содержащую #0, целиком невозможно. Но главный "подводный камень", связанный с символом #0 в середине строки, заключается в том, что целый ряд стандартных функций для работы со строками AnsiString на самом деле вызывают API-функции (или даже библиотечные функции Delphi, предназначенные для работы с PChar, что приводит к игнорированию "хвоста" после #0. Следующий код (листинг 3.33. пример ZeroFind на компакт-диске) иллюстрирует эту проблему.
Листинг 3.33. Некорректная работа функции AnsiPos с символом #0
procedure TForm1.Button1Click(Sender: TObject);
begin
Label1.Caption := IntToStr(AnsiPos('Z', 'A'#0'Z'));
end;
Хотя символ "Z" присутствует в строке, в которой производится поиск, на экран будет выведен "0", что означает отсутствие искомой подстроки. Это связано с тем, что функция AnsiPos использует функции StrPos и CompareString, предназначенные для работы со строками PChar, поэтому поиск за символом #0, не производится. Если заменить в этом примере функцию AnsiPos на Pos, которая работает с типом AnsiString должным образом, на экран будет выведено правильное значение "3".
Описанные проблемы заставляют очень осторожно относиться к возможному появлению символа #0 в середине строк AnsiString — это может стать источником неожиданных проблем.
3.3.7. Функция, возвращающая AnsiString
Очень интересный "подводный камень", связанный с типом AnsiString рассмотрен в статье [4]. Проиллюстрируем его следующим кодом (листинг 3.34, пример StringResult на компакт-диске).
Листинг 3.34. Неожиданное значение результата
function AddOne: string;
begin
Result := Result + '1';
end;
procedure TForm1.Button1Click(Sender: TObject);
var
S: string;
begin
S := 'Test';
S := AddOne;
Label1.Caption := S;
end;
Если человека, не знакомого с этой особенностью компилятора, попросить предсказать, что появится на экране в результате выполнения этого кода, его рассуждения будут звучать, скорее всего, примерно так: "Так как Result в функции AddOne — это локальная переменная типа string, то, как и все такие переменные, она будет инициализирована пустым значением. Добавление символа '1' к пустой строке даст в результате строку '1', которая и будет выведена на экран. Кстати, на строке S := 'Test' компилятор должен выдать предупреждение, что значение, присвоенное переменной S, нигде не используется".
Однако эти рассуждения неверны. На экране появится надпись Test1, т.е. первоначальное значение переменной S будет учтено в функции AddOne. Это происходит потому, что с точки зрения двоичного кода переменная Result это не локальная переменная, а параметр-переменная, как если бы функции AddOne была объявлена так:
procedure AddOne(var Result: string);
Именно так компилятор обрабатывает функции, тип результата которых AnsiString (и ShortString, кстати, тоже). Какая переменная будет передана в качестве параметра, — это зависит от того, как вызвана функция, точнее, куда идет ее результат. Иногда компилятору приходится неявно имитировать какую-то переменную, а иногда он может воспользоваться реально существующей переменной. В нашем случае он воспользовался переменной S, передав её в качестве параметра. Строковые параметры-переменные, в отличие от локальных переменных, по понятным причинам не инициализируются пустой строкой, поэтому переменная Result сохраняет значение переменной S, что и приводит к наблюдаемому результату.
Из этого следует правило, которое должен помнить разработчик: функция, возвращающая строковое значение, не должна делать никаких предположений о первоначальном значении переменной Result, т.к. оно может оказаться любым.
Следует заметить, что аналогичным образом компилятор обходится и с другими сложными типами: если функция возвращает такой тип, то Result становится не локальной переменной, а неявным параметром-переменной. Просто с другими типами это не так заметно, потому что от них никто не ожидает автоматической инициализации в прологе функции, и обращаются с переменной Result так, будто она содержит случайный мусор.
3.3.8. Строки в записях
Поля в записях могут иметь любой строковый тип без дополнительных ограничений. Однако следует учитывать, что, в отличие от полей простых типов, значения полей типа PChar и AnsiString лежат вне пределов структуры, причем в случае AnsiString это не так бросается в глаза, т.к вручную выделять и освобождать память не приходится. Это может привести к неприятному сюрпризу, если работать со структурой как с цельным блоком данных. Чаще всего проблема появляется при записи структуры в поток, файл и т.п. В этом случае записывается только значение указателя, которое не имеет никакого смысла для того, кто потом эти данные читает, такой указатель указывает либо в никуда, либо на данные, никакого отношения к строке не имеющие.
Для иллюстрации этой проблемы, а также методов её решения нам понадобятся два проекта: RecordRead и RecordWrite (на компакт-диске они оба находятся в папке RecordReadWrite). Обойтись одним проектом здесь нельзя — указатель, переданный в пределах проекта, остается корректным, поэтому проблема маскируется. В проекте RecordWrite три кнопки, соответствующие трем методам сохранения записи в поток TFileStream (в файлы Method1.stm, Method2.stm и Method3.stm соответственно). В три целочисленных поля заносятся текущие час, минута, секунда и сотая доля секунды, строка — произвольная, введенная пользователем в поле ввода Edit1. Файлы пишутся в текущую папку, из-за этого программы нельзя запускать непосредственно с компакт-диска. В проекте RecordRead три кнопки соответствуют трем методам чтения (каждый из своего файла). Сначала рассмотрим первый метод — как делать ни в коем случае нельзя.
В проекте RecordWrite имеем следующий код (листинг 3.35).
Листинг 3.35. Неправильный метод записи структуры со строкой в файл
type
TMethod1Record = packed record
Hour: Word;
Minute: Word;
Second: Word;
MSec: Word;
Msg: string;
end;
procedure TForm1.Button1Click(Sender: TObject);
var
Rec: TMethod1Record;
Stream: TFileStream;
begin
DecodeTime(Now, Rec.Hour, Rec.Minute, Rec.Second, Rec.MSec);
Rec.Msg := Edit1.Text;
Stream := TFileStream.Create('Method1.stm', fmCreate);
Stream.WriteBuffer(Rec, SizeOf(Rec));
Stream.Free;
end;
В проекте RecordRead соответствующий код (листинг 3.36).
Листинг 3.36. Неправильный метод чтения структуры со строкой из файла
procedure TForm1.Button1Click(Sender: TObject);
var
Rec: TMethod1Record;
Stream: TFileStream;
begin
Stream := TFileStream.Create('Method1.stm', fmOpenRead);
Stream.ReadBuffer(Rec, SizeOf(Rec));
Stream.Free;
Label1.Caption :=
TimeToStr(EncodeTime(Rec.Hour, Rec.Minute, Rec.Second, Rec.MSec));
Label2.Caption := Rec.Msg; { * }
end;
Примечание
В проекте RecordRead объявлена такая же запись TMethod1Record, описание которой во втором случае для краткости опущено.
Запись в файл происходит нормально, но при чтении в строке, отмеченной звездочкой, скорее всего, возникает исключение Access violation (в некоторых случаях исключения может не быть, но вместо сообщения будет выведен мусор). Причину этого мы уже обсудили ранее — указатель Msg, действительный в контексте процесса RecordWrite, не имеет смысла в процессе RecordRead, а сама строка передана не была. Без ошибок этим методом можно передать только пустую строку, потому что ей соответствует указатель nil, имеющий одинаковый смысл во всех процессах. Однако метод передачи строк, умеющий передавать только пустые строки, имеет весьма сомнительную ценность с практической точки зрения.
Самый простой способ исправить ситуацию— изменить тип поля Msg на ShortString. Больше ничего в приведенном коде менять не придется. Однако использование ShortString имеет два недостатка. Во-первых, длина строки в этом случае ограничена 255 символами. Во-вторых, если длина строки меньше максимально возможной, часть памяти, выделенной для структуры, останется незаполненной. Если средняя длина строки существенно меньше максимальной, то таких неиспользуемых кусков в потоке будет много, т.е. файл окажется неоправданно раздутым. Это всегда плохо, а в некоторых случаях — вообще недопустимо, поэтому ShortString можно посоветовать только в тех случаях, когда строки имеют примерно одинаковую длину (напомним, что ShortString позволяет ограничить длину строки меньшим, чем 255, числом символов — в этом случае поле будет занимать меньше места).
С одним из этих недостатков можно бороться: если заменить в записи ShortString статическим массивом типа Char, то можно передавать строки большей, чем 255 символов, длины. Второй метод демонстрирует этот способ.
В проекте RecordWrite этому соответствует код (листинг 3.37).
Листинг 3.37. Запись в файл структуры с массивом символов
const
MsgLen = 15;
type
TMethod2Record = packed record
Hour: Word;
Minute: Word;
Second: Word;
MSec: Word;
Msg: array[0..MsgLen - 1] of Char;
end;
procedure TForm1.Button2Click(Sender: TObject);
var
Rес: TMethod2Record;
Stream: TFileStream;
begin
DecodeTime(Now, Rec.Hour, Rec.Minute, Rес.Second, Rec.MSec);
StrPLCopy(Rec.Msg, Edit1.Text, MsgLen - 1);
Stream := TFileStream.Create('Method2.stm', fmCreate);
Stream.WriteBuffer(Rec, SizeOf(Rec));
Stream.Free;
end;
В проекте RecordRead это следующий код (листинг 3.38).
Листинг 3.38. Чтение из файла структуры с массивом символов
procedure TForm1.Button2Click(Sender: TObject);
var
Rес: TMethod2Record;
Stream: TFileStream;
begin
Stream := TFileStream.Create('Method2.stm', fmOpenRead);
Stream.ReadBuffer(Rec, SizeOf(Rec));
Stream.Free;
Label1.Caption :=
TimeToStr(EncodeTime(Rec.Hour, Rec.Minute, Rec.Second, Rec.MSec));
Label2.Caption := Rec.Msg;
end;
Константа MsgLen задаёт максимальную (вместе с завершающим нулём) длину строки. В приведенном примере она взята достаточно маленькой, чтобы наглядно продемонстрировать, что данный метод имеет ограничения на длину строки. Переделки по сравнению с кодом предыдущего метода минимальны: при записи для копирования значения Edit1.Text вместо присваивания нужно вызывать функцию StrPLCopy. В коде RecordRead изменений (за исключением описания самой структуры) вообще нет — это достигается за счёт того, что массив Char считается компилятором совместимым с PChar, а выражения типа PChar могут быть присвоены переменным типа AnsiString — конвертирование выполнится автоматически.
Однако проблему неэффективного использования файлового пространства мы таким образом не решили. Более того, мы до конца не решили и проблему максимальной длины: хотя ограничение на длину строки теперь может быть произвольным, всё равно оно должно быть известно на этапе компиляции. Чтобы полностью избавиться от этих проблем, необходимо вынести строку за пределы записи и сохранить её отдельно, вместе с длиной, чтобы при чтении сначала читалась длина строки, затем выделялась для неё память, и в эту память читалась строка. Именно так работает третий метод. В проекте Record Write это будет следующий код (листинг 3.39)
Листинг 3.39. Запись в файл строки отдельно от структуры
type
TMethod3Record = packed record
Hour: Word;
Minute: Word;
Second: Word;
MSec: Word;
end;
procedure TForm1.Butrton3Click(Sender: TObject);
var
Rec: TMethod3Record;
Stream: TFileStream;
Msg: string;
MsgLen: Integer;
begin
DecodeTime(Now, Rec.Hour, Rec.Minute, Rec.Second, Rec.MSec);
Msg := Edit1.Text;
MsgLen := Length(Msg);
Stream := TFileStream.Create('Method3.stm', fmCreate);
Stream.WriteBuffer(Rec, SizeOf(Rec));
Stream.WriteBuffer(MsgLen, SizeOf(MsgLen);
if MsgLen > 0 then Stream.WriteBuffer(Pointer(Msg)^, MsgLen);
Stream.Free;
end;
В проекте RecordRead это следующий код (листинг 3.40).
Листинг 3.40. Чтение из файла строки отдельно от структуры
procedure TForm1.Button3Click(Sender: TObject);
var
Rec: TMethod3Record;
Stream: TFileStream;
Msg: string; MsgLen:
Integer;
begin
Stream := TFileStream.Create('Method3.stm', fmOpenRead);
Stream.ReadBuffer(Rec, SizeOf(Rec));
Stream.ReadBuffer(MsgLen, SizeOf(Integer));
SetLength(Msg, MsgLen);
if MsgLen > 0 then Stream.ReadBuffer(Pointer(Msg)^, MsgLen);
Stream.Free;
Label1.Caption :=
TimeToStr(EncodeTime(Rec.Hour, Rec.Minute, Rec.Second, Rec.MSec));
Label2.Caption := Msg;
end;
Наконец-то мы получили код, который безошибочно передает строку, не имея при этом ограничений длины (кроме ограничения на длину AnsiString) и не расходуя понапрасну память. Правда, сам код получился сложнее. Во-первых, из записи исключено поле типа string, и теперь ее можно без проблем читать и писать в поток. Во-вторых, в поток после нее записывается длина строки. В-третьих, записывается сама строка.
Параметры вызова методов ReadBuffer и WriteBuffer для чтения/записи строки требуют дополнительного комментария. Метод WriteBuffer пишет в поток ту область памяти, которую занимает указанный в качестве первого параметра объект. Если бы мы указали саму переменную Msg, то записалась бы та часть памяти, которую занимает эта переменная, т.е. сам указатель. А нам не нужен указатель, нам необходима та область памяти, на которую он указывает, поэтому указатель следует разыменовать с помощью оператора ^. Но просто взять и применить этот оператор к переменной Msg нельзя — с точки зрения синтаксиса она не является указателем. Поэтому приходится сначала приводить ее к указателю (здесь подошел бы любой указатель, не обязательно нетипизированный). То же самое относится и к ReadBuffer: чтобы прочитанные данные укладывались не туда, где хранится указатель на строку, а туда, где хранится сама строка, приходится прибегнуть к такой же конструкции. И обратите внимание, что прежде чем читать строку, нужно зарезервировать для нее память с помощью SetLength.
Вместо приведения строки к указателю с последующим его разыменованием можно было бы использовать другие конструкции:
Stream.ReadBuffer(Msg[1], MsgLen);
и
Stream.WriteBuffer(Msg[1], MsgLen);
Это дает требуемый результат и даже более наглядно: действительно, при чтении и записи мы работаем с той областью памяти, которая начинается с первого символа строки, т.е. с той, где хранится сама строка. Но такой способ менее производителен из-за неявного вызова UniqueString. В нашем случае мы и так защищены от побочных изменений других строк (при записи строка не меняется, при чтении она и так уникальна — это обеспечивает SetLength), поэтому вполне можем обойтись без этой в данном случае излишней опеки со стороны компилятора.
Примечание
Если сделать MsgLen не независимой переменной, а полем записи, можно сэкономить на одном вызове ReadBuffer и WriteBuffer.
Недостатком этого метода является то, что мы вынуждены переделывать под него запись. В нашем примере это не составило проблемы, но в реальных проектах запись обычно предназначена не только для чтения и сохранения в поток, и если взять и выкинуть из нее строки, то все прочие участки кода станут более громоздкими. Поэтому в реальности приходится писать отдельные процедуры, которые сохраняют запись не как единое целое, а по отдельным полям.
Ранее мы говорили о том, что копирование записей, содержащих поля типа AnsiString, в рамках одного процесса маскирует проблему, т.к. указатель остается допустимым и даже (какое-то время) правильным. Но сейчас с помощью приведенного в листинге 3.41 кода (пример RecordCopy на компакт-диске) мы увидим, что проблема не исчезает, а просто становится менее заметной.
Листинг 3.41. Побочное изменение переменной после низкоуровневого копирования
type
TSomeRecord = record
SomeField: Integer;
Str: string;
end;
procedure TForm1.Button1Click(Sender: TObject);
var
Rec: TSomeRecord;
S: string;
procedure CopyRecord;
var
LocalRec: TSomeRecord;
begin
LocalRec.SomeField := 10;
LocalRec.Str := 'Hello!!!';
UniqueString(LocalRec.Str);
Move(LocalRec, Rec, SizeOf(TSomeRecord));
end;
begin
CopyRecord;
S := 'Good bye';
UniqueString(S);
Label1.Caption := Rec.Str;
Pointer(Rec.Str) := nil;
end;
На экране вместо ожидаемого Hello!!! появится Good bye. Это происходит вот почему: процедура Move осуществляет простое побайтное копирование одной области памяти в другую, механизм изменения счетчика ссылок при этом не срабатывает. В результате менеджер памяти не будет знать, что после завершения локальной процедуры CopyRecord остаются ссылки на строку "Hello!!!". Память, выделенная этой строке, освобождается. Но Rec.Str продолжает ссылаться на эту уже освобожденную память. Для строки S выделяется свободная память — та самая, где раньше была строка LocalRec.Str. А поскольку Rec.Str продолжает ссылаться на эту область памяти, поэтому обращение к ней дает строку "Good bye", которая теперь там размещена.
Обратите внимание на последнюю строку — приведение Rec.Str к типу Pointer и обнулению. Это сделано для того, чтобы менеджер памяти не пытался финализировать строку Rec.Str после завершения процедуры, иначе он попытается освободить память, которая уже освобождена, и возникнет ошибка.
Чтобы показать, насколько коварна эта ошибка, рассмотрим следующий код (листинг 3.42, из того же примера RecordCopy на компакт-диске).
Листинг 3.42. Сокрытие ошибки при низкоуровневом копировании записи со строкой
procedure TForm1.Button2Click(Sender: TObject);
var
Rec: TSomeRecord;
S: string;
procedure CopyRecord;
var
LocalRec: TSomeRecord;
begin
LocalRec.SomeField := 10;
LocalRec.Str := 'Привет!';
Move(LocalRec, Rec, SizeOf(TSomeRecord));
end;
begin
CopyRecord; S := 'Пока!';
Label1.Caption := Rec.Str;
end;
Or предыдущего случая этот пример отличается только тем, что в нем нет вызовов UniqueString, и строки указывают на литералы в сегменте кода, которые никогда не удаляются. На экране получаем вполне ожидаемое Привет!. Обнулять указатель здесь уже нет смысла, потому что освобождать литерал менеджер памяти все равно не будет. Так ошибка оказалась скрытой.
Продолжим наши эксперименты. Запустим пример RecordCopy и понажимаем попеременно кнопки Button1 и Button2. Мы видим, что результат не зависит от порядка, в котором мы нажимаем кнопки.
Модифицируем код в локальной процедуре обработчика Button1Click: уберем из строки "Hello!!!" восклицательные знаки, сократив ее до "Hello". Теперь можно наблюдать интересный эффект: если после запуска нажать сначала Button1, то никаких изменений мы не заметим. А вот если кнопка Button2 будет нажата раньше, чем Button1, то при последующих нажатиях Button1 никаких видимых эффектов не будет. Это связано с тем, что теперь строка "Hello" не равна по длине строке "Good bye", поэтому разместится ли "Good bye" в том же месте памяти, где раньше была "Hello", или в каком-то другом, зависит от истории выделения и освобождения памяти. Если мы начинаем "с чистого листа", память после строки "Hello" останется свободной, поэтому туда можно поставить более длинную строку. А вот если раньше память уже выделялась и освобождалась (внутри методов TLabel), то тот кусочек свободной памяти, который достаточен для "Hello", слишком мал для "Good bye", и эта строка размещается в другом месте. А там, куда указывает Rec.Str, остается мусор, работать с которым нормально невозможно, поэтому при попытке присвоить его свойству Label1.Caption последнее не меняется (эффект наблюдается только до Delphi 7 включительно; в более новых версиях Delphi используется новый менеджер памяти FastMem, который немного по-другому размещает строки в памяти, поэтому с ним зависимости от порядка нажатия кнопок не будет).
Примечание
Если увеличить длину строки "Привет!" хотя бы на один символ, чтобы она была не короче, чем "Good bye" (или наоборот, сократить его так. чтобы оно стало короче "Hello"), мы снова увидим, что порядок нажатия кнопок не влияет на результат. Это происходит потому, что строка "Hello" размещается там, где раньше была строка "Привет!", а вот "Good bye" там уже не помещается. Если же обе строки там помещаются (или обе не помещаются), они снова оказываются в одной области памяти. Внимательный читатель может спросить: а при чем здесь длина строки "Привет!", если эта строка хранится в сегменте кода и никогда не освобождается? Дело в том, что когда мы присваиваем эту строку свойству Label1.Caption, внутри методов TLabel происходит ее перенос в динамическую память для внутренних нужд этого класса.
Даже на таком простом примере видно, насколько коварна эта ошибка и как незначительные изменения в коде могут кардинально изменить ее проявления. Между тем приведенный здесь код — плод долгого "приручения" этой ошибки, чтобы она всегда проявлялась предсказуемым образом. Но даже сейчас мы не можем дать полной гарантии, что у кого-то из читателей из-за какой-то неучтенной мелочи не возникнет ситуация, когда эта ошибка проявляется как-то по-другому (как мы уже видели, даже в разных версиях Delphi эта ошибка проявляет себя немного по-разному). В реальных проектах все гораздо сложнее, и поведение программы из-за этой ошибки может стать таким неожиданным, а проявление этой ошибки — настолько далеким от того места, где она сделана, что впору будет "прыгать вокруг компьютера с бубном", изгоняя бесов. Чтобы не оказаться в таком положении, нужно очень аккуратно работать со строками (а также с другими автоматически финализируемыми типами: динамическими массивами, интерфейсами, вариантами), чтобы тот код, который неявно генерирует компилятор, не оказался в тупике. Чаще всего проблемы возникают при побайтном копировании переменной типа AnsiString (не обязательно в составе записи) или при работе с ней как с указателем другого типа. Это не значит, что приводить AnsiString к другим указателям категорически нельзя — ранее мы уже делали это, и вполне успешно. Но, применяя любой низкоуровневый инструмент к таким строкам, разработчик должен четко представлять, как это отразится на внутренних механизмах работы с ними. Иначе — вот такая непонятная ошибка.
Еще одна ситуация, когда записи со строками могут преподнести сюрприз — выделение динамический памяти для них. Динамическую память можно выделить двумя способами: с помощью процедуры New или GetMem (освобождать ее надо, соответственно, с помощью Dispose или FreeMem). Для записей, не содержащих строки, эти способы практически эквивалентны, за исключением того, что при использовании New объем выделяемой памяти определяет компилятор, поэтому New считается более безопасным вариантом. Если же запись содержит строку, то эта строка должна быть инициализирована, иначе попытка работы с ней приведет к ошибке. Процедура GetMem ничего не делает с содержимым выделяемой ею памяти, и строка остается неинициализированной, в то время как New выполняет инициализацию. Это не значит, что GetMem непригодна для выделения памяти для такой записи, просто после вызова GetMem нужно не забыть вызвать специальную процедуру Initialize, которая правильно инициализирует строки в записи. Соответственно, прежде чем удалить такую запись с помощью FreeMem, необходимо вызвать процедуру Finalize для финализации строк. Это создает дополнительные проблемы, не давая никаких преимуществ, поэтому целесообразнее все-таки использовать New и Dispose.
Преимущество GetMem перед New заключается в том, что за один вызов GetMem можно выделить память сразу для нескольких записей (с последующей их ручной инициализацией, конечно же), в то время как New выделяет память только для одного экземпляра записи. Но с появлением в языке динамических массивов это преимущество тоже перестало быть особо полезным. Проще объявить динамический массив из записей и создать требуемое число элементов в нем — компилятор сам позаботится об инициализации таких переменных. Поэтому мы рекомендуем отказаться от GetMem при выделении памяти под записи со строками, а если уж вы столкнулись с ситуацией, когда без этого совсем никак, не забывайте вызывать Initialize и Finalize.
Примечание
Память для записей можно выделять и в обход менеджера памяти Delphi напрямую вызывая системные функции типа HeapAlloc, VirtualAlloc или CoTaskMemAlloc. Разумеется, компилятор в этом случае не сможет инициализировать и финализировать выделяемую память, поэтому, как и в случае с GetMem, для строк с записями необходимо пользоваться процедурами Initialize и Finalize.
3.3.9. Использование ShareMem
Пример, который мы сейчас рассмотрим, — это даже не "подводный камень", это то, что в форумах обычно называется "грабли". Все новые и новые программисты с завидным упорством наступают на эти грабли и получают по лбу, хотя, казалось бы, вокруг стоят таблички, предупреждающие об опасности, только не ленись читать.
Итак, создаем новую динамически компонуемую библиотеку (DLL). Delphi предлагает нам следующую заготовку (листинг 3.43).
Листинг 3.43. Базовый
library Project1;
{ Important note about DLL memory management: ShareMem must be the first unit in your library's USES clause AND your project's (select Project-View Source) USES clause if your DLL exports any procedures or functions that pass strings as parameters or function results. This applies to all strings passed to and from your DLL--even those that are nested in records and classes. ShareMem is the interface unit to the BORLNDMM.DLL shared memory manager, which must be deployed along with your DLL. To avoid using BORLNDMM.DLL, pass string information using PChar or ShortString parameters. }
uses
SysUtils, Classes;
{$R *.RES}
begin
end.
Самое важное здесь — комментарий. Его следует внимательно прочитать и осознать, а главное — выполнить эти советы, иначе при передаче строк AnsiString между DLL и программой вы будете получать ошибку Access violation в самых неожиданных местах. Почему-то многие им пренебрегают, а потом бегут с вопросами в разные форумы, хотя минимум внимательности и отсутствия снобизма по отношению "к этим, из Borland'а, которые навставляли тут никому не нужных комментариев" могли бы уберечь от ошибки.
Для начала выясним источник ошибки. Менеджер памяти Delphi работает следующим образом: он берет у системы большие блоки памяти, а потом по мере необходимости выделяет их по частям. Это позволяет избежать частых выделений памяти системными средствами и тем самым повышает производительность. Следствием этого становится то. что менеджер памяти должен иметь информацию о том, какими блоками он распределил полученную от системы память между различными потребителями.
Менеджер памяти реализуется модулем System. Так как DLL компонуется отдельно от использующего ее exe-файла, у нее будет своя копия кода System, и, следовательно, свой менеджер памяти. И если объект, память для которого была выделена в коде основного модуля программы, попытаться освободить в коде DLL, то получится, что освобождать память будет совсем не тот менеджер, который ее выделил. А сделать он этого не сможет, т.к. не обладает информацией о выделенном блоке. Результат — ошибка (скорее всего, Access violation при выходе из процедуры). А при работе со строками AnsiString память постоянно выделяется и освобождается, поэтому, попытавшись работать с одной и той же строкой и в главном модуле, и в DLL, мы получим ошибку.
Теперь, когда мы поняли, почему возникает проблема, разберемся, как ShareMem ее решает. Delphi предоставляет возможность заменить стандартный менеджер памяти своим: для этого нужно написать низкоуровневые функции выделения, освобождения и перераспределения памяти и сообщить их адреса через процедуру SetMemoryManager. После этого через них будут работать все высокоуровневые функции для манипуляций с памятью (New, GetMem и т.п.). Именно это и делает ShareMem в секции инициализации этого модуля содержится код, заменяющий функции работы с памятью своими, которые находятся во внешней библиотеке BORLNDMM.DLL. Получается, что и библиотека, и главный модуль работают с одним менеджером памяти, что решает описанные проблемы.
Если менеджер памяти попытаться поменять не в самом начале программы, то ему придется освобождать память, которую успел выделить предыдущий менеджер памяти, что приведет к той же самой проблеме. Поэтому заменить менеджер памяти нужно до того, как будет выполнена первая операция по её выделению. Отсюда возникает требование вставлять ShareMem первым модулем в dpr-файлах главного модуля и DLL — чтобы его секция инициализации была первым выполняемым программой кодом.
В Интернете часто можно встретить утверждения, что в новых версиях Delphi (BDS2006 и выше) ShareMem не нужен, потому что стандартный менеджер памяти там заменен на FastMM, который прекрасно обходится без ShareMem. Это неверно. Оригинальный FastMM действительно может функционировать без ShareMem при выполнении определённых условий. Модуль, использующий FastMM ("модуль" здесь значит модуль в понимании системы, т.е. module, а не unit), может предоставить свой менеджер памяти в общее пользование, а все остальные модули, подключившие FastMM будут пользоваться этим менеджером вместо своего. Получится, что все модули в процессе будут работать с одним менеджером памяти, и проблем не будет. В общее пользование свой менеджер памяти предоставляет тот модуль, который инициализируется самым первым (т.к. основной модуль программы инициализируется только после того, как будут проинициализированы все статически связанные с ним DLL, в общее пользование свой менеджер памяти предоставляет одна из DLL).
Тот вариант FastMM, который входит в состав новых версий Delphi, тоже может быть предоставлен в общее пользование, но по умолчанию этого не происходит, так что с передачей строк в DLL возникнут те же проблемы, что и в старых версиях Delphi. Но решить эти проблемы теперь можно двумя способами. Первый — это использовать ShareMem и распространять с программой библиотеку BORLNDMM.dll, точно так же, как и в более ранних версиях Delphi. Второй способ — подключить к dpr-файлам библиотек и главного модуля модуль SimpleShareMem. Этот модуль в своей секции инициализации проверяет, есть ли уже переданный в общее пользование менеджер памяти, и если есть, переключает свою программу или DLL на него, а если ещё нет, делает текущий менеджер памяти общим. Использование модулей SimpleShareMem и ShareMem идентично: его так же нужно указывать первым в списке uses главного файла проекта. Но никаких дополнительных библиотек распространять с программой не придется. Таким образом, новые версии Delphi действительно позволяют обойтись без библиотеки BORLNDMM.DLL, но это все-таки получается не автоматически, а после некоторых усилий.
Кстати, к данному в комментарии совету заменить AnsiString на PChar, чтобы избавиться от необходимости использования ShareMem, следует относиться осторожно: если мы попытаемся, например, вызвать StrNew в основной программе, а StrDispose — в DLL, то получим ту же проблему. Вопрос не в типах данных, а в том, как манипулировать памятью. Поэтому обычный способ работы с PChar следующий: программа выделяет буфер своим менеджером памяти и передает указатель на этот буфер, а также его длину в качестве параметров функции из DLL. Эта функция заносит в буфер требуемую строку, не перераспределяя память. Затем программа освобождает эту строку своим же менеджером памяти. В листинге 3.44 приведен пример кода такой функции в DLL.
Листинг 3.44. Код функции в DLL
function GetString(Buf: PChar; BufLen: Integer): Integer;
var
S: string;
begin
// Формируем строку для возврата программе
...
// Копируем строку в буфер
if BufLen > 0 then StrLCopy(Buf, PChar(S), BufLen - 1);
// возвращаем требуемый размер буфера
Result := Length(S) + 1;
end;
Здесь параметр Buf содержит указатель на буфер, выделенный вызывающей программой, BufLen — размер этого буфера в байтах. Для примера здесь взят случай, когда строка, которую нужно возвратить, формируется в переменной типа string, т.к. в большинстве случаев это наиболее удобный способ. После того как строка сформирована, ее содержимое копируется в буфер с учетом его длины. Результат, который возвращает функция, — это необходимый размер буфера. Программа по этому результату может сделать вывод, поместилась ли вся строка в выделенный ей буфер, и если не поместилась, принять меры, например, вызвать функцию еще раз. выделив под буфер больше памяти.
Если не существует ограничения на длину возвращаемой строки, программа "не знает", буфер какого размера потребуется. Наиболее простое решение этой проблемы следующее: программа сначала вызывает функцию GetString, передавая nil в качестве указателя на буфер и 0 в качестве размера буфера. Затем по результату функции определяется требуемый размер буфера, выделяется память и функция вызывается еще раз, уже с буфером нужного размера. Такой способ обеспечивает правильную передачу строки любой длины, но требует двукратного вызова функции, что снижает производительность, особенно в том случае, если на формирование строки тратится много времени.
Повысить среднюю производительность можно, применяя комбинированный метод получения буфера. Программа создает массив в стеке такого размера, чтобы в большинстве случаев возвращаемая строка вмещалась в нем. Этот размер определяется в каждом конкретном случае, исходя из особенностей функции и условий ее вызова. А на тот случай, если она все-таки там не поместилась, предусмотрен запасной вариант с выделением буфера в динамической памяти. Этот подход иллюстрирует листинг 3.45.
Листинг 3.45. Быстрый (в среднем) способ получения строки через буфер
const
StatBufSize = ...; // Размер, подходящий для данного случая
var
StatBuf: array[0..StatBufSize - 1] of Char;
Buf: PChar;
RealLen: Integer;
begin
// Пытаемся разместить строку в буфере StatBuf
RealLen := GetString(StatBuf, StatBufSize);
if RealLen > StatBufSize then
begin
// Если StatBuf оказался слишком мал, динамически выделяем буфер
// нужного размера и вызываем функции еще раз
Buf := StrAlloc(RealLen);
GetString(Buf, RealLen);
end
else
// Размера статического буфера хватило. Пусть Buf указывает
// на StatBuf, чтобы нижеследующий код мог в любом случае
// обращаться к буферу через переменную Buf
Buf := StatBuf;
// Что-то делаем с содержимым буфера
...
// Если выделяли память, ее следует очистить
if Buf <> StatBuf then StrDispose(Buf);
end;
Следует также упомянуть о еще одной альтернативе передачи строк в DLL — типе WideString, который хранит строку в кодировке Unicode и является, по сути, оберткой над системным типом BSTR. Работать с WideString так же просто, как и с AnsiString, перекодирование из ANSI в Unicode и обратно выполняется автоматически при присваивании значения одного типа переменной другого. В целях совместимости с СОМ и OLE при работе с памятью дли строк WideString используется специальный системный менеджер памяти (через API-функции SysAllocString, SysFreeString и т.п.), поэтому передавать эти строки из DLL в главный модуль и обратно можно совершенно безопасно даже без ShareMem. Правда, при этом не стоит забывать о расходовании процессорного времени на перекодировку, если основная работа идет не с Unicode, а с ANSI.
Отметим одну ошибку, которую делают новички, прочитавшие комментарий про ShareMem, но не умеющие работать с PChar. Они пишут, например, такой код для функции, находящейся в DLL и возвращающей строку (листинг 3.46).
Листинг 3.46. Неправильный способ возврата строки из DLL
function SomeFunction(...): PChar;
var
S: string;
begin
// Здесь присваивается значение S
Result := PChar(S);
end;
Такой код компилируется и даже, за редким исключением, дает ожидаемый результат. Но тем не менее, в этом коде грубая ошибка. Указатель, возвращаемый функцией, указывает на область памяти, которая считается свободной, поскольку после выхода переменной S за пределы области видимости память, которую занимала эта строка, освободилась. Менеджер памяти может в любой момент вернуть эту память системе (тогда обращение к ней вызовет Access violation) или задействовать для других целей (тогда новая информация уничтожит содержащуюся там строку). Проблема маскируется тем, что обычно результат используется немедленно, до того как менеджер памяти что-то сделает с этим блоком. Тем не менее полагаться на это и писать такой код не следует.

