Архитектурная археология

Чтобы определить принципы хорошей архитектуры, совершим путешествие по последним 45 годам и познакомимся с некоторыми проектами, над которыми я работал начиная с 1970 года. Некоторые из этих проектов представляют определенный интерес с архитектурной точки зрения. Другие интересны извлеченными уроками, повлиявшими на последующие проекты.
Это приложение несколько автобиографично. Я старался придерживаться темы обсуждения архитектуры, но, как в любой автобиографической истории, иногда в нее вторгаются другие факторы. ;-)
Профсоюзная система учета
В конце 1960-х годов компания ASC Tabulating подписала контракт с местным профсоюзом водителей грузовиков на разработку системы учета. Компания ASC решила реализовать эту систему на машине GE Datanet 30, изображенной на рис. П.1.

Рис. П.1. GE Datanet 30 (фотографию предоставил Эд Телен (Ed Thelen), ed-thelen.org)
Как можно видеть на фотографии, это была огромная машина. Она занимала целую комнату и требовала поддержания определенного микроклимата.
Эта ЭВМ была построена еще до появления интегральных микросхем. Она была собрана на дискретных транзисторах, и в ней имелось даже несколько радиоламп (хотя они использовались только в усилителях для управления ленточными накопителями).
По сегодняшним меркам машина была огромная, медлительная и примитивная. В ней имелось 16 К × 18 бит оперативной памяти с временем цикла порядка 7 микросекунд. Она занимала большую комнату с климатической установкой. Имела приводы для магнитной ленты с семью дорожками и жесткий диск емкостью около 20 Мбайт.
Этот диск был настоящим монстром. Вы можете увидеть его на рис. A.2, но эта фотография не позволяет оценить размеры чудовища. Он был выше моего роста. Пластины были 36 дюймов (примерно 91 сантиметр) в диаметре и 3/8 дюйма (9,5 миллиметра) в толщину. Одна из пластин изображена на рис. A.3.
Теперь подсчитайте пластины на первой фотографии. Их было более десятка. Для каждой имелась своя лапа с головкой, приводившаяся в движение пневматическим приводом. В процессе работы можно было видеть, как головки перемещаются поперек пластин. Время позиционирования головки колебалось от половины секунды до секунды.
Когда этот зверь включался, он рычал, как самолет. Пол ходил ходуном, пока тот набирал скорость.
ЭВМ Datanet 30 была знаменита своей возможностью асинхронно управлять большим количеством терминалов с относительно высокой скоростью. Именно это требовалось компании ASC.

Рис. П.2. Жесткий диск с пластинами (фотографию предоставил Эд Телен (Ed Thelen), ed-thelen.org)
Компания ASC находилась в Лейк Блафф, штат Иллинойс, в 30 милях к северу от Чикаго. Офис профсоюза размещался в центре Чикаго. Профсоюз нанял примерно десять человек для ввода данных в систему через терминалы CRT (рис. П.4). Они также могли печатать отчеты на телетайпах ASR35 (рис. П.5).
Терминалы CRT поддерживали скорость обмена 30 символов в секунду. Это была хорошая скорость для конца 1960-х, потому что модемы в те дни были очень простенькими.
ASC арендовала у телефонной компании с десяток выделенных телефонных линий и вдвое больше 300-бодовых модемов для соединения Datanet 30 с этими терминалами.
В те времена компьютеры поставлялись без операционной системы. Они не имели даже файловых систем. У вас имелся только ассемблер.

Рис. П.3. Одна из пластин диска: 3/8 дюйма толщиной, 36 дюймов в диаметре (фотографию предоставил Эд Телен (Ed Thelen), ed-thelen.org)

Рис. П.4. Терминал CRT (фотографию предоставил Эд Телен (Ed Thelen), ed-thelen.org)

Рис. П.5. Телетайп ASR35 (с разрешения Джо Мейбла (Joe Mabel))
Если вам нужно было сохранить данные на диске, вы записывали их на диск. Не в файл. Не в каталог. Вы должны были определить дорожку, пластину и сектор для сохраняемых данных и затем управлять диском, чтобы записать туда данные. Да, это означало необходимость писать свой драйвер диска.
В системе учета имелось три вида записей с информацией об агентах, работодателях и членах профсоюза. Для этих записей поддерживались все четыре CRUD-операции, но кроме этого система включала операции для рассылки квитанций на уплату взносов, определения изменений в общем реестре и другие.
Первоначальная версия системы была написана на ассемблере консультантом, которому чудом удалось впихнуть ее в 16 К.
Как нетрудно догадаться, такая большая ЭВМ, как Datanet 30, была очень дорогой в обслуживании и эксплуатации. Услуги консультанта, поддерживавшего программное обеспечение, тоже обходились очень дорого. Более того, на рынке уже появились и стали набирать популярность более дешевые мини-компьютеры.
В 1971 году, когда мне было 18, компания ASC наняла меня и двух моих друзей-гиков, чтобы переписать систему учета для мини-компьютера Varian 620/f (рис. П.6). Компьютер стоил недорого. Наши услуги стоили недорого. Для ASC это было отличной сделкой.
Машина Varian имела 16-битную шину и 32 К × 16 оперативной памяти. Длительность цикла составляла примерно 1 микросекунду. Эта машина была намного мощнее, чем Datanet 30. В ней использовалась дико успешная дисковая технология 2314, разработанная в IBM, позволявшая хранить 30 мегабайт на пластинах, имевших всего 14 дюймов в диаметре, которые уже не могли пробивать бетонные стены!
Конечно, у нас все еще не было операционной системы. Не было файловой системы. Не было и высокоуровневого языка программирования. У нас имелся только ассемблер. Но мы справились с заданием.

Рис. П.6. Мини-компьютер Varian 620/f (взято с сайта The Minicomputer Orphanage)
Вместо попытки втиснуть всю систему в 32 К, мы создали систему оверлеев. Приложения могли загружаться с диска в блок памяти, выделенной для оверлеев. Они могли выполняться в этой памяти и вытесняться со своими данными в памяти обратно на диск, чтобы дать возможность поработать другим программам.
Программы могли загружаться в область оверлеев, выполняться ровно столько, сколько необходимо для заполнения выходных буферов, и затем выгружаться на диск, чтобы освободить память для следующей программы.
Конечно, когда пользовательский интерфейс работает со скоростью 30 символов в секунду, программы тратят массу времени на ожидание. У нас в запасе оставалось достаточно времени, чтобы программы могли загружаться и записываться на диск, обеспечивая максимальную скорость обмена с терминалами. Никто и никогда не жаловался на проблемы с временем отклика.
Мы написали вытесняющего диспетчера задач, управляющего прерываниями и вводом/выводом. Мы написали приложения; мы написали драйверы диска и драйверы терминалов, драйверы накопителей на магнитной ленте и все остальное в этой системе. В этой системе не было ни одного бита, написанного не нами. Это был тяжелый труд в течение множества 80-часовых недель, но мы запустили этого зверя за 8 или 9 месяцев.
Система имела простую архитектуру (рис. П.7). Когда приложение запускалось, оно генерировало данные до заполнения выходного буфера заданного терминала. Затем диспетчер задач выгружал это приложение и загружал новое. При этом диспетчер продолжал выводить информацию со скоростью 30 символов в секунду почти до его опустошения. Затем он вновь загружал приложение, чтобы снова заполнить буфер.
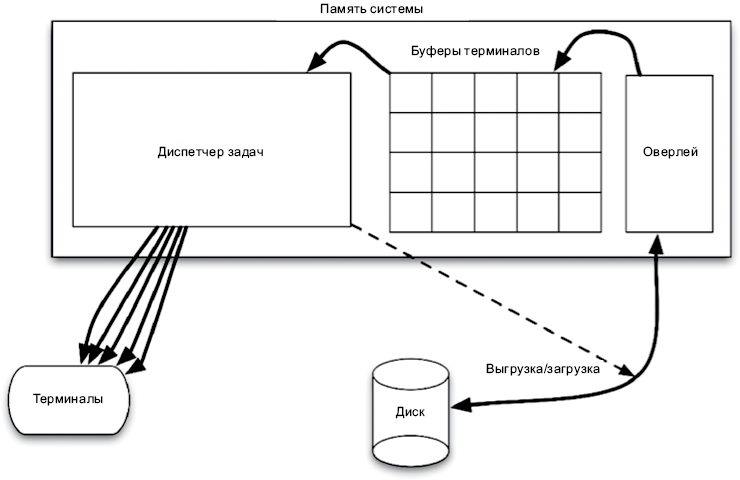
Рис. П.7. Архитектура системы
В этой системе есть две границы. Первая — вывод символов. Приложения не знали, что их вывод посылается терминалам со скоростью 30 символов в секунду. В действительности для приложений вывод символов был полностью абстрагирован. Приложения просто передавали строки диспетчеру задач, а тот заботился о загрузке их в буферы, отправке символов терминалам и загрузке приложений в память и выгрузке их из памяти.
Зависимости пересекали эту границу в прямом направлении, то есть их направленность совпадала с направленностью потока управления. Приложения имели зависимости времени компиляции от диспетчера задач, и поток управления следовал от приложений в сторону диспетчера. Граница оберегает приложения от просачивания в них информации о типе устройства, в который производится вывод.
Вторая граница пересекалась зависимостями в обратном направлении. Диспетчер задач мог запускать приложения, но не имел зависимости времени компиляции от них. Поток управления следовал от диспетчера к приложениям. Полиморфный интерфейс, инвертирующий зависимость, был прост: каждое приложение запускалось переходом по одному и тому же адресу в области оверлея. Граница оберегает диспетчера от просачивания в него информации об устройстве приложений, кроме адреса точки запуска.
Laser Trim
В 1973 году я поступил на работу в компанию Teradyne Applied Systems (TAS) в Чикаго. Это было подразделение корпорации Teradyne Inc. со штаб-квартирой в Бостоне. Мы занимались системой, управлявшей довольно мощными лазерами для обработки электронных компонентов с высокой точностью.
В ту пору производители электронных компонентов использовали метод шелкотрафаретной печати на керамической подложке. Подложки имели размер примерно 1 квадратный дюйм. Компонентами были обычные резисторы — устройства, создающие сопротивление электрическому току.
Величина сопротивления резистора зависела от множества факторов, включая состав и геометрию. Чем шире был резистор, тем меньшее сопротивление он оказывал.
Наша система позиционировала керамическую подложку в жгуте проводов, соединяющих датчики с резисторами. Система должна была измерять сопротивление и затем с помощью лазера отсекать части резистора, делая его тоньше и тоньше, пока не будет достигнута желаемая величина сопротивления с точностью до десяти процентов.
Мы продавали эти системы производителям, а также использовали некоторые свои системы для производства небольших партий по заказам менее крупных производителей.
Система работала на компьютере M365. Это было время, когда многие компании строили свои компьютеры: корпорация Teradyne строила M365 и передавала их своим подразделениям. M365 был усовершенствованной версией PDP-8 — популярного в те дни мини-компьютера.
M365 управлял координатным столом, который перемещал керамические подложки между датчиками. Также он управлял системой измерения и лазером. Позиционирование лазера осуществлялось посредством вращающихся X-Y зеркал. Компьютер также управлял мощностью лазера.
Среда разработки для M365 была довольно примитивной. Этот компьютер не имел диска. Данные сохранялись на картриджах с магнитной лентой, которые выглядели как старые 8-дорожечные аудиокассеты. Лента и приводы производились компанией Tri-Data.
Так же как 8-дорожечные аудиокассеты того времени, лента была склеена в петлю. Привод мог прокручивать ее только в одном направлении — в них не было функции перемотки! Если требовалось установить ленту в начальную позицию, нужно было прокручивать ее вперед до достижения «точки загрузки».
Лента прокручивалась со скоростью примерно 1 фут в секунду (примерно 30 сантиметров в секунду). То есть петля из ленты длиной 25 футов (чуть больше 7,5 метра) перематывалась до точки загрузки самое большее за 25 секунд. По этой причине Tri-Data выпускала картриджи с лентой разной длины, от 10 до 100 футов (примерно от 3 до 30 метров).
На передней панели M365 имелась кнопка, по нажатии которой производилась загрузка начальной программы в память и ее запуск. Эта программа могла прочитать первый блок с ленты и запустить его. Обычно в этом блоке хранился загрузчик, загружавший операционную систему, хранящуюся в остальных блоках на ленте.
Операционная система запрашивала у пользователя имя программы для запуска. Эти программы хранились на ленте, сразу вслед за операционной системой. Пользователь мог ввести имя программы — например, ED-402 Editor, — а операционная система отыскивала ее на ленте, загружала и запускала.
Консолью служил ASCII CRT терминал с зеленым свечением, шириной 72 символа и высотой 24 строки. Он мог отображать только символы верхнего регистра.
Чтобы отредактировать программу, нужно было загрузить редактор ED-402 Editor и затем вставить ленту с исходным кодом. Редактор позволял прочитать с ленты в память один блок с исходным кодом и вывести его на экран. В одном блоке можно было сохранить до 50 строк кода. Для внесения изменений нужно было переместить курсор в требуемую строку и ввести текст, примерно так, как это делается в редакторе vi. По завершении требовалось записать блок на другую ленту и прочитать следующий блок с исходной ленты. Вы должны были продолжать эти манипуляции, пока не закончите.
Не было никакой возможности прокрутить блоки в обратном направлении. Правка программы производилась линейно, от начала до конца. Чтобы вернуться в начало, нужно было закончить копирование исходного кода на выходную ленту и затем начать новый сеанс редактирования уже с этой лентой в качестве исходной. Неудивительно, что при таких ограничениях мы сначала писали свои программы на бумаге, вносили все правки вручную красным карандашом и только потом правили программу блок за блоком, сверяясь с пометками в листинге на бумаге.
Закончив правку программы, мы возвращались в операционную систему и вызывали ассемблер. Ассемблер читал код с исходной ленты и записывал двоичный код на другую ленту, при этом выводил листинг на наш последовательный принтер.
Ленты не были на 100% надежными, поэтому мы выполняли запись сразу на две ленты. Это увеличивало вероятность, что хотя бы одна из них не будет содержать ошибок.
Наша программа состояла примерно из 20 000 строк кода, а ее компиляция занимала примерно 30 минут. Шансы получить в это время ошибку чтения с ленты были 1 : 10. Если ассемблер сталкивался с такой ошибкой, он издавал сигнал на консоли и затем начинал выводить поток ошибок на принтер. Этот сигнал можно было услышать во всей лаборатории. Также можно было услышать проклятия несчастного программиста, только что узнавшего, что ему придется вновь запустить 30-минутный процесс компиляции.
Программа имела типичную для тех дней архитектуру. У нас имелась главная операционная программа (Master Operating Program), которую мы называли «the MOP». Она осуществляла управление базовыми функциями ввода/вывода и предоставляла рудиментарную «командную оболочку» для консоли. Многие подразделения Teradyne использовали общий исходный код MOP, адаптируя его под собственные нужды. Как следствие, мы пересылали друг другу изменения в исходном коде в форме бумажных листингов с поправками, которые затем (очень тщательно) вносили вручную.
Измеряющим оборудованием, координатными столами и лазером управляла специальная утилита. Граница между этим уровнем и MOP была запутанной. Уровень утилиты часто вызывал уровень MOP, а специально модифицированная версия MOP часто вызывала утилиту. В действительности мы не разделяли их на два уровня. Для нас это был лишь некоторый код, добавляемый нами в MOP и создающий тесные связи.
Затем появился уровень изоляции. Этот уровень поддерживал интерфейс виртуальной машины для прикладных программ, которые писались на совершенно другом, предметно-ориентированном языке (Domain-Specific Language; DSL). Язык включал операции перемещения лазера и координатного стола, выполнения реза и измерений и т.д. Наши клиенты писали на этом языке свои программы управления лазером, а изолирующий уровень выполнял их.
Этот подход не предусматривал создания машинно-независимого языка программирования для управления лазером. В действительности язык имел множество связей с уровнями, лежащими ниже. Скорее этот подход дал прикладным программистам более «простой» язык, чем ассемблер M356, на котором они описывали свои задания для лазерной обработки.
Система могла загружать такие программы с ленты и выполнять их. По сути, наша система была операционной системой для приложений лазерной обработки.
Система была написана на ассемблере M365 и компилировалась в единственную единицу компиляции с абсолютным двоичным кодом.
Границы в этом приложении в лучшем случае были мягкими. Даже граница между системным кодом и приложениями на DSL не имела строгой силы. Повсюду были связи.
Но это было типично для программного обеспечения начала 1970-х.
Контроль алюминиевого литья под давлением
В середине 1970-х годов, когда организация ОПЕК вводила эмбарго на поставки нефти, а дефицит бензина провоцировал на заправочных станциях драки между озлобленными водителями, я поступил на работу в Outboard Marine Corporation (OMC). Это была головная компания, объединившая Johnson Motors и Lawnboy Lawnmowers.
OMC имела большое производство в Уокигане, штат Иллинойс, по производству литых алюминиевых деталей для всех видов двигателей и изделий, изготавливаемых компанией. Алюминий расплавлялся в огромных печах и затем в ковшах перевозился к десяткам и десяткам машин для литья. Каждой машиной управлял человек-оператор, отвечавший за установку изложниц, выполнение цикла литья и извлечение готовых деталей. Зарплата операторов зависела от количества отлитых деталей.
Меня наняли для разработки проекта по автоматизации цеха. OMC приобрела ЭВМ IBM System/7, которая была ответом IBM на появление мини-компьютеров. Они связали этот компьютер со всеми машинами для литья в цехе, чтобы мы могли подсчитать время работы и количество циклов каждой машины. Наша задача заключалась в том, чтобы собрать всю эту информацию и вывести ее на зеленые экраны терминалов 3270.
Программы для этой машины писались на языке ассемблера. И снова весь код, выполнявшийся на этом компьютере, был написан нами до последнего бита. У нас не было ни операционной системы, ни библиотек подпрограмм, ни фреймворков. Это был просто код.
Причем это был код, управляемый прерываниями и действующий в режиме реального времени. Каждый раз, когда какая-то машина завершала цикл, мы обновляли пакет статистических данных и посылали сообщение большой ЭВМ IBM 370, где работала программа на CICS-COBOL, выводившая эти данные на зеленые экраны.
Я ненавидел эту работу. Боже, как я ее ненавидел. Нет, сама работа была интересной! Но культура... Достаточно сказать, что я был обязан носить галстук.
Я старался. Я очень старался. Но я был очень недоволен этой работой, и мои коллеги знали об этом. Они понимали это, потому что я забывал важные даты или просыпал в дни, когда надо было рано вставать, чтобы прийти на важное совещание. Это была единственная работа, связанная с программированием, с которой меня уволили, — и поделом.
С архитектурной точки зрения в этой системе нет ничего поучительного, кроме одного. ЭВМ System/7 имела очень интересную инструкцию установки программного прерывания SPI (Set Program Interrupt). Она позволяла вызвать прерывание процессора, чтобы обработать любые другие низкоприоритетные прерывания, стоящие в очереди. В современном языке Java имеется схожий аналог, который называется Thread.yield().
4-TEL
В октябре 1976 года, после увольнения из OMC, я вернулся в Teradyne, но в другое подразделение, где я проработал следующие 12 лет. Там я занимался проектом под названием 4-TEL. Его целью было еженощное тестирование всех телефонных линий, обслуживаемых компанией, и создание отчета с перечислением всех линий, требующих ремонта. Это позволяло сосредоточить внимание обслуживающего персонала на конкретных телефонных линиях.
Эта система начинала свой путь с той же архитектуры, что и система Laser Trim. Это было монолитное приложение, написанное на языке ассемблера и не имевшее каких-то значительных границ. Но в то время, когда я вернулся в компанию, все должно было измениться.
Система использовалась сотрудниками сервисного центра (Service Center; SC). Сервисный центр охватывал несколько телефонных станций (Central Offices; CO), каждый из которых мог обслуживать до 10 000 телефонных линий. Аппаратура переключения линий и измерения уровня сигнала должна была размещаться в телефонных станциях (CO). Поэтому мы установили там компьютеры M365. Мы называли их тестерами линий в телефонных станциях (Central Office Line Testers; COLTs). Еще один M365 находился в сервисном центре (SC); он назывался компьютером зоны обслуживания (Service Area Computer; SAC). К компьютеру SAC было подключено несколько модемов для обмена данными с несколькими компьютерами COLT на скорости 300 бод (30 символов в секунду).
Сначала всю работу выполняли компьютеры COLT, включая все взаимодействия с консолями, обслуживание меню и составление отчетов. Компьютер SAC играл роль простого мультиплексора, получавшего данные от компьютеров COLT и выводившего их на экран.
Проблема такой организации состояла в том, что скорость 30 символов в секунду действительно была слишком маленькой. Работникам не очень нравилось наблюдать, как появляются символы на экране, особенно если учесть, что их интересовал небольшой объем ключевых данных. Кроме того, в те дни оперативная память в M365 стоила очень дорого, а программа была большой.
Поэтому было решено отделить часть программы, осуществляющую тестирование линий, от части, анализирующей результаты и печатающей отчеты. Последнюю предполагалось перенести на компьютер SAC, а первая должна была продолжать работать на компьютерах COLT. Это должно было позволить использовать в качестве COLT машины поменьше, с меньшим объемом памяти, и значительно повысить скорость вывода информации на терминал, потому что отчеты должны были генерироваться на компьютере SAC.
Результат превзошел самые смелые ожидания. Информация на экране обновлялась очень быстро (после соединения с соответствующим компьютером COLT), а объем памяти в компьютерах COLT значительно уменьшился.
Граница получилась очень четкой и надежной. Компьютеры SAC и COLT обменивались очень короткими пакетами. Эти пакеты были очень простой формой предметно-ориентированного языка с такими командами, как «DIAL XXXX» или «MEASURE».
Загрузка M365 осуществлялась с магнитной ленты. Накопители на магнитной ленте были дорогими и не очень надежными, особенно в промышленном окружении телефонных станций. Кроме того, сама машина M365 стоила довольно дорого в сравнении с остальной электроникой в компьютерах COLT. Поэтому мы приступили к реализации проекта по замене M365 микрокомпьютером на базе микропроцессора 8085.
Новый компьютер состоял из процессорной платы с микропроцессором 8085, платы ОЗУ с 32 Кбайт памяти и трех плат с ПЗУ, содержащих 12 Кбайт памяти, доступной только для чтения. Все эти платы помещались в шасси с измерительным оборудованием, благодаря чему можно было убрать громоздкое шасси, в котором размещалась ЭВМ M365.
Платы ПЗУ содержали по 12 микросхем Intel 2708 EPROM (Erasable Programmable Read-Only Memory — стираемое программируемое постоянное запоминающее устройство, СППЗУ). На рис. П.8 показано, как выглядела такая микросхема. Мы записывали программы в эти микросхемы, вставляя их в специальное устройство, которое назвалось программатором ППЗУ и управлялось нашей средой разработки. Информацию на микросхемах можно было стирать, подвергая их облучению ультрафиолетовым светом большой интенсивности.
Мой друг и я занялись переводом программ для COLT с языка ассемблера M365 на язык ассемблера 8085. Перевод выполнялся вручную и занял почти 6 месяцев. В результате получилось около 30 Кбайт кода 8085.
Наша среда разработки имела 64 Кбайт ОЗУ и не имела ПЗУ, поэтому скомпилированный двоичный код мы могли быстро загрузить в ОЗУ и протестировать.
Получив работоспособную программу, мы переключались на использование СППЗУ (EPROM). Мы программировали 30 микросхем и вставляли их в соответствующие гнезда в трех платах ПЗУ. Каждая микросхема подписывалась, поэтому мы точно знали, какую из них в какое гнездо нужно вставить.
30 Кбайт программного кода — это был единый двоичный блок длиной 30 Кбайт. Чтобы записать этот код в микросхемы ПЗУ, мы просто делили двоичный образ на 30 сегментов по 1 Кбайт и записывали каждый сегмент в микросхему с соответствующей надписью.

Рис. П.8. Микросхема СППЗУ (EPROM)
Эта схема прекрасно работала, и мы начали массовое производство оборудования и развертывание системы в поле.
Но программное обеспечение в первую очередь является программным. Требовалось добавлять новые возможности, исправлять ошибки. А так как базовая система разрасталась, логистика обновления программного обеспечения путем программирования 30 микросхем на каждый экземпляр и замены всех 30 микросхем в каждом офисе превращалась в кошмар.
Возможны были все виды проблем. Иногда микросхемы подписывались неправильно или наклейки с подписями отваливались. Иногда инженер службы эксплуатации мог по ошибке заменить не ту микросхему или поломать один из выводов новой микросхемы. Как следствие, инженерам приходилось носить с собой все 30 микросхем.
Зачем менять все 30 микросхем? Каждый раз, когда добавлялся или удалялся код из 30-килобайтного блока выполняемого кода, изменялись адреса всех машинных инструкций. Изменялись также адреса подпрограмм и функций. То есть затрагивалась каждая микросхема, каким бы простым ни было изменение.
Однажды ко мне зашел мой начальник и попросил решить эту проблему. Он сказал, что нужно найти какой-то способ изменения микропрограммы без замены всех 30 микросхем ПЗУ. Мы в коллективе обсудили эту проблему и приступили к проекту «Векторизация». На его реализацию ушло 3 месяца.
Идея была до смешного простой. Мы разбили 30 Кбайт программного кода на 32 файла с исходным кодом, компилирующихся независимо в блоки меньше одного 1 Кбайт. В начало каждого файла с исходным кодом мы вставили инструкцию, сообщающую компилятору, в какой адрес должен компилироваться данный код (например, ORG C400 для микросхемы ПЗУ, вставляемой в гнездо C4).
Также в начало каждого файла с исходным кодом мы добавили структуру фиксированного размера с адресами всех подпрограмм в этом блоке (вектор переходов). Эта структура имела размер 40 байт, поэтому могла хранить до 20 адресов. Это означало, что блок для одной микросхемы не мог содержать более 20 подпрограмм.
Затем мы создали особую область в ОЗУ, которую называли массивом векторов. Она содержала 32 таблицы по 40 байт — достаточный объем для хранения указателей на начало каждого блока в отдельных микросхемах.
Наконец, мы заменили вызовы подпрограмм в каждом блоке косвенными вызовами через соответствующий вектор в ОЗУ.
Когда происходила загрузка программы, в массив векторов в ОЗУ загружались векторы переходов из всех микросхем ПЗУ, а затем осуществлялся переход в точку запуска главной программы.
У нас все получилось. Теперь, когда исправлялась ошибка или добавлялось что-то новое, мы могли перекомпилировать только один или два файла, записать их на соответствующие микросхемы и передать только эти микросхемы инженеру службы эксплуатации для замены.
Мы сделали блоки кода независимо развертываемыми. Мы изобрели полиморфную диспетчеризацию. Мы изобрели объекты.
Это была архитектура с подключаемыми модулями (плагинами). Мы подключали микросхемы. Мы разработали ее так, чтобы новые возможности можно было включать в наши продукты установкой микросхем с этими возможностями в соответствующие гнезда. Управляющее меню появлялось автоматически, и так же автоматически происходила привязка новых возможностей к приложению.
Конечно, тогда мы не знали о принципах объектно-ориентированного программирования и также ничего не знали об отделении пользовательского интерфейса от бизнес-правил. Но кое-какие основы были заложены, и они здорово нам помогли.
Описанный подход дал одно неожиданное преимущество: мы получили возможность обновлять микропрограмму через модемное соединение. Обнаружив ошибку, мы могли через модемное соединение связаться с устройством и посредством специальной программы-монитора изменить вектор в ОЗУ, ссылающийся на подпрограмму с ошибкой, подставив адрес в пустой области ОЗУ, и затем загрузить в эту область ОЗУ исправленную подпрограмму, вводя машинные коды в шестнадцатеричном формате.
Это было большим благом для службы эксплуатации и для наших клиентов. Если у них возникала проблема, им не требовалось заказывать у нас срочную отправку микросхем с исправленным кодом. Систему можно было исправить немедленно, а новые микросхемы установить в ближайший период обслуживания.
Компьютер зоны обслуживания
Роль компьютера зоны обслуживания (Service Area Computer; SAC) в 4-TEL играл мини-компьютер M365. Эта система взаимодействовала со всеми компьютерами COLT посредством выделенных или коммутируемых линий. Она могла отдавать компьютерам COLT команды на выполнение проверки телефонных линий, принимать результаты и анализировать их для выявления любых проблем.
Выбор ремонтников для отправки
Одним из экономических обоснований для создания этой системы было эффективное распределение ремонтников. Ремонтники делились на три категории согласно требованиям профсоюза: обслуживающие телефонные станции, кабели и точки подключения. Ремонтники, обслуживающие телефонные станции, исправляли проблемы в телефонных станциях. Ремонтники, обслуживающие кабели, исправляли проблемы, связанные с нарушением целостности кабелей, соединяющих телефонные станции с клиентами. Ремонтники, обслуживающие точки подключения, исправляли проблемы в помещениях клиентов и в линиях, соединяющих внешний кабель с этими помещениями.
Когда клиент сообщал о проблеме, наша система могла диагностировать ее и определить, каких ремонтников следует направить на ее исправление. Это экономило телефонным компаниям уйму денег, потому что выбор не того ремонтника означал задержку для клиента и впустую потраченное время на поездку ремонтника.
Код, делающий выбор, был разработан и написан талантливым программистом, но жутким собеседником. Процесс создания этого кода можно описать так: «Три недели он смотрел в потолок, потом два дня из него, как из рога изобилия, лился код, а потом он уволился».
Никто не понимал этот код. Каждый раз, пытаясь добавить что-то новое или исправить ошибку, мы что-то да ломали в нем. А поскольку этот код был одним из основных экономических преимуществ нашей системы, каждая новая найденная ошибка вызывала глубокое замешательство.
В конце концов наше руководство предложило нам просто «заморозить» этот код и никогда не менять его. Этот код официально стал незыблемым.
Этот опыт показал мне, насколько ценным может быть хороший, чистый код.
Архитектура
Система была написана в 1976 году на ассемблере M365. Это была единая, монолитная программа, состоявшая примерно из 60 000 строк кода. Операционная система была собственной разработки. Она реализовала невытесняющую многозадачность на основе опроса. Мы назвали ее MPS, от Multiprocessing System (многозадачная система). Процессор M365 не имел встроенного стека, поэтому локальные переменные задач хранились в специальной области памяти и копировались при каждом переключении контекста. Доступ к общим переменным регулировался с применением блокировок и семафоров. Проблемы реентерабельности и состояния гонки преследовали нас постоянно.
Бизнес-правила системы не были изолированы ни от логики управления устройствами, ни от логики пользовательского интерфейса. Например, код управления модемом можно было найти повсюду в бизнес-правилах и в пользовательском интерфейсе. В системе не было даже намека на попытку собрать код в модули или использовать абстрактные интерфейсы. Модемы управлялись на уровне битов кодом, разбросанным по всей системе.
То же можно сказать о пользовательском интерфейсе и управлении терминалами. Код, управляющий сообщениями и форматированием текста, не был изолирован. Его можно было найти повсюду в кодовой базе из 60 000 строк.
Модемные модули, которые мы использовали, были предназначены для монтажа на печатных платах. Мы закупали их у сторонней компании и монтировали на наши собственные платы. Они стоили очень дорого. Поэтому, спустя несколько лет, мы решили спроектировать свой модем. Мы, члены группы программирования, попросили конструктора использовать те же битовые форматы для управления новым модемом. Мы объяснили, что код управления модемом разбросан по всей системе и что в будущем этой системе предстоит работать с обоими типами модемов. Мы умоляли и умоляли его: «Пожалуйста, сконструируй новый модем так, чтобы с точки зрения программного управления он ничем не отличался от старого».
Но когда мы получили новый модем, управление им было структурировано иначе. Не просто чуть-чуть иначе, а совершенно иначе.
Спасибо тебе, конструктор.
И что же нам было делать? Мы могли просто взять и заменить все старые модемы новыми. Мы должны были организовать в своих системах управление модемами обоих видов. Программное обеспечение должно было работать с обоими типами модемов одновременно. Мы были обречены окружать код, управляющий модемами, флагами и специальными случаями. Но количество таких мест исчислялось сотнями!
В конечном итоге мы выбрали еще более плохое решение.
Запись данных в последовательную шину, управлявшую всеми нашими устройствами, включая модемы, осуществляла единственная подпрограмма. Мы изменили ее так, чтобы она распознавала битовые шаблоны для управления старым модемом и транслировала их в битовые шаблоны управления новым модемом.
Это было непросто. Команды управления модемами состояли из последовательностей операций записи в разные адреса ввода/вывода в последовательной шине. Новая подпрограмма должна была интерпретировать последовательности этих команд и транслировать их в другие последовательности, с другими адресами ввода/вывода, другими временными задержками и иным расположением установленных и сброшенных битов.
Мы реализовали это решение, но это было самое худшее из всего, что только можно представить. Но благодаря этому я понял ценность абстрактных интерфейсов и изоляции аппаратуры от бизнес-правил.
Великая модернизация
К началу 1980-х годов идея создания собственных мини-компьютеров и собственных компьютерных архитектур стала выходить из моды. На рынке появилось много более стандартных микрокомпьютеров, использовать которые было проще и дешевле, чем продолжать полагаться на компьютерные архитектуры из конца 1960-х годов. Это, а также жуткая архитектура программного обеспечения SAC вынудили наше техническое руководство инициировать полную реорганизацию системы SAC.
Новая система должна была быть написана на C для дисковой ОС UNIX, действующей на микрокомпьютере с процессором Intel 8086. Наши конструкторы приступили к созданию нового компьютерного оборудования, а отобранная группа программистов, «The Tiger Team», занялась разработкой новой системы.
Не буду утомлять вас подробностями первого провала. Скажу лишь только, что первая команда «Tiger Team» полностью провалилась, потратив два или три человеко-года на проект, который так и не был закончен.
Спустя год или два, примерно в 1982 году, была предпринята новая попытка. Ее целью была полная и всеобщая переделка SAC на C, UNIX и нашем заново спроектированном оборудовании с впечатляюще производительным процессором 80286. Мы назвали новый компьютер «Deep Thought».
Прошли годы, потом еще несколько лет, затем еще несколько и еще. Я не знаю, когда, наконец, была развернута первая система SAC на базе UNIX; полагаю, что это случилось уже после моего ухода (в 1988 году). На самом деле я вообще не уверен, что она была хоть когда-то развернута.
Почему так долго? Просто потому, что команде, занимавшейся созданием новой системы, было сложно угнаться за огромной командой, активно развивавшей старую систему. Вот лишь некоторые из трудностей, с которыми они столкнулись.
Европа
Примерно в то же время, когда система SAC переписывалась на C, компания начала расширять продажи в Европе. Руководство не могло ждать, пока закончится переделка программного обеспечения, поэтому в Европе стали развертываться старые системы на M365.
Проблема в том, что телефонные системы в Европе сильно отличались от телефонных систем в США. Организация труда рабочих и служащих также существенно отличалась. Поэтому один из наших лучших программистов был отправлен в Великобританию для руководства группой британских разработчиков, занимающихся адаптацией программного обеспечения SAC под европейские требования.
Разумеется, не предпринималось никаких серьезных попыток интегрировать произведенные изменения с программным обеспечением в США. Эта работа велась задолго до появления сетей, позволявших передавать большие объемы кода через океан. Британские разработчики просто взяли за основу код из США и исправляли его под свои нужды.
Это, конечно, вызывало трудности. Ошибки обнаруживались по обе стороны Атлантики, и их требовалось исправлять на обеих же сторонах. Но модули значительно изменились, поэтому было трудно определить, будет ли исправление, сделанное в США, работать в Великобритании.
После нескольких лет изнуряющей гонки и появления скоростной линии, связавшей офисы в США и Великобритании, была предпринята серьезная попытка интегрировать две системы, переместив все различия в настройки. И первая, и вторая, и третья попытки провалились. Две базы кода, хотя и очень похожие, имели слишком много отличий для успешной реинтеграции, особенно в быстро меняющейся рыночной среде тех лет.
Между тем разработчики из команды «Tiger Team», пытавшиеся переписать все на C и UNIX, заметили, что им также приходится иметь дело с этой двойственностью Европа/США. И конечно, это не способствовало ускорению их движения вперед.
В заключение о SAC
Я мог бы продолжать рассказывать истории об этой системе, но это неприятные для меня воспоминания. Достаточно сказать, что многие из этих горьких уроков в моей карьере программиста были получены в процессе погружений в ужасный ассемблерный код SAC.
Язык C
Оборудование на базе микропроцессора 8085, которое мы использовали в проекте 4-Tel Micro, дало нам относительно недорогую компьютерную платформу, пригодную для реализации многих разных промышленных проектов. Мы имели 32 Кбайт ОЗУ и еще 32 Кбайт ПЗУ и чрезвычайно гибкую и мощную схему управления периферией. Чего у нас не было, так это гибкого и удобного языка программирования. На ассемблере 8085 было просто неинтересно писать код.
Кроме того, ассемблер, которым мы пользовались, был написан нашими же программистами. Он работал на наших ЭВМ M365 и использовал ленточный накопитель на картриджах, описанный в разделе «Laser Trim».
Так сложилось, что наш ведущий инженер-электронщик убедил генерального директора в необходимости иметь настоящий компьютер. На самом деле он не знал, что с ним делать, но он имел большое политическое влияние. Поэтому мы купили PDP-11/60.
Я, в то время скромный программист, был в восторге. Я точно знал, что я хочу сделать с этим компьютером. Я решил, что это будет моя машина.
Когда пришли инструкции и руководства, за несколько месяцев до того, как пришла сама машина, я забрал их домой и буквально проглотил. К моменту, когда был доставлен компьютер, я довольно глубоко изучил, как действует аппаратное и программное обеспечение, настолько глубоко, насколько это возможно в домашних условиях.
Я помогал писать заказ на поставку. В частности, я указал, что новый компьютер должен иметь дисковый накопитель. Я решил, что мы должны купить два дисковых привода, в которые можно устанавливать сменные пакеты дисков емкостью по 25 мегабайт каждый.
Пятьдесят мегабайт! Этот объем казался неисчерпаемым! Я помню, как по ночам я гулял по коридорам офиса, подобно злой ведьме Бастинде, и восклицал: «Пятьдесят мегабайт! Ха-ха-ха-ха-ха-ха-ха-ха-ха!»
Руководитель службы эксплуатации здания отгородил небольшую комнату, в которой могло поместиться шесть терминалов VT100. Я украсил ее стены картинами с изображениями космоса. Наши программисты могли бы использовать эту комнату для написания и компиляции кода.
Когда пришла машина, я потратил несколько дней на ее установку, подключение терминалов и проверку работоспособности всех ее компонентов. Этот труд был в радость.
Мы закупили стандартные ассемблеры для 8085 в компании Boston Systems Office и переписали код 4-Tel Micro с использованием нового синтаксиса. Мы построили систему кросс-компиляции, позволявшую нам выгружать скомпилированный двоичный код из PDP-11 в наши вычислительные комплексы на базе 8085 и в программаторы ПЗУ. И план удался — все работало как часы.
C
Но у нас оставалась еще проблема в виде языка ассемблера 8085, который мы продолжали использовать. Это было ложкой дегтя в бочке меда. Я уже слышал про «новый» язык, широко использовавшийся в Bell Labs. Они назвали его «C». Поэтому я купил книгу The C Programming Language Кернигана и Ритчи. Как и руководства для PDP-11, несколькими месяцами раньше, я проглотил эту книгу.
Я был поражен простотой и элегантностью этого языка. Он обладал мощностью языка ассемблера, но открывал доступ к этой мощности, предоставляя более удобный синтаксис. Я был в восторге.
Я купил компилятор C в компании Whitesmiths и запустил его на PDP-11. Он производил код на языке ассемблера, синтаксис которого был совместим с компилятором 8085 от Boston Systems Office. То есть у нас появилась возможность писать программы на C для 8085! Мы были готовы к работе.
Теперь оставалась единственная проблема — убедить программистов, пишущих на ассемблере, что они должны перейти на C. Но эту кошмарную историю я расскажу в другой раз...
BOSS
Наша платформа на процессоре 8085 не имела операционной системы. Мой опыт работы с системой MPS на ЭВМ M365 и знание простейших механизмов прерываний в IBM System 7 подсказывали, что нам нужен простой диспетчер задач для 8085. Поэтому я задумал написать BOSS: Basic Operating System and Scheduler (базовая операционная система с планировщиком).
Значительная часть BOSS была написана на C. Она могла конкурентно выполнять несколько задач. Многозадачность не была вытесняющей — переключение происходило не по прерываниям, а так же, как в системе MPS для M365, с помощью простого механизма опроса. Опрос происходил всякий раз, когда задача блокировалась в ожидании события.
Вызов, блокирующий задачу, выглядел в BOSS так:
block(eventCheckFunction);
Этот вызов приостанавливал текущую задачу, помещал eventCheckFunction в список опроса и связывал ее с только что заблокированной задачей. Затем выполнялся цикл опроса, в котором последовательно вызывались функции из списка, пока одна из них не возвращала true. Затем возобновлялось выполнение задачи, связанной с этой функцией.
То есть, как я говорил выше, это был простой невытесняющий диспетчер задач.
Это программное обеспечение стало основой для большого количества проектов, разрабатывавшихся в следующие несколько лет. Но одним из первых был pCCU.
pCCU
Конец 1970-х — начало 1980-х годов было шумным временем для телефонных компаний. Одной из причин волнений стала цифровая революция.
В предыдущем веке коммутационный узел и телефон клиента связывала пара медных проводов. Эти провода связывались в кабели, образующие разветвленную сеть по всей стране. Иногда их подвешивали на столбах, иногда прокладывали под землей.
Медь — дорогой металл, и телефонные компании владели тоннами, буквально тоннами этого металла в виде проводов, опутывающих страну. Капиталовложения были огромными. Большую часть этих капиталовложений можно было сэкономить передачей телефонных разговоров через цифровые соединения. Одна пара медных проводов могла бы переносить сотни диалогов в цифровой форме.
В ответ телефонные компании приступили к замене старого аналогового коммутационного оборудования современными цифровыми коммутаторами.
Наш продукт 4-Tel тестировал медные провода, но не мог тестировать цифровые соединения. В цифровой среде все еще использовались медные провода, но они были намного короче, чем раньше, и сосредоточены в основном рядом с телефонами клиентов. Сигнал от телефонной станции передавался в цифровой форме до местного распределительного пункта, где преобразовывался обратно в аналоговую форму и доставлялся до клиента по обычной паре медных проводов. Это означало, что наша измеряющая аппаратура должна находиться там, где начинаются медные провода, но устройство соединения с ним должно было оставаться в телефонной станции. Проблема в том, что все наши компьютеры COLT объединяли устройство соединения и аппаратуру измерения в одном корпусе. (Мы могли бы сэкономить целое состояние, узнав об этой очевидной архитектурной границе на несколько лет раньше!)
В результате мы задумали продукт с новой архитектурой: CCU/CMU (COLT control unit/COLT measurement unit — модуль управления COLT/модуль измерения COLT). По задумке модуль CCU должен находиться в телефонной станции и обеспечивать выбор телефонных линий для тестирования. Модуль CMU должен находиться в местных распределительных пунктах и измерять уровень сигнала в медных проводах, идущих к телефону клиента.
Проблема состояла в том, что на каждый модуль CCU приходилось много модулей CMU. Информация о том, какой модуль CMU использовать для каждого телефонного номера, содержалась в самом цифровом коммутаторе. То есть модуль CCU должен был опросить цифровой коммутатор, чтобы определить, с каким модулем он должен взаимодействовать.
Мы пообещали телефонным компаниям, что создадим эту новую архитектуру к моменту их перехода. Мы знали, что это займет месяцы, если не годы, поэтому чувствовали себя раскованно. Мы также знали, что для разработки нового программно-аппаратного комплекса CCU/CMU потребуется несколько человеко-лет.
Ловушка планирования
С течением времени у нас постоянно всплывали какие-то неотложные вопросы, для решения которых мы были вынуждены откладывать разработку архитектуры CCU/CMU. Мы были уверены в своем решении, потому что телефонные компании тоже все время откладывали разработку цифровых коммутаторов. Заглядывая в их графики, мы были уверены, что у нас еще масса времени, поэтому мы постоянно откладывали нашу разработку.
Но настал день, когда мой начальник вызвал меня к себе в кабинет и сказал: «Один из наших клиентов развертывает цифровой коммутатор в следующем месяце. К тому времени у нас должен быть рабочий комплекс CCU/CMU».
Я был в ужасе! Как за месяц выполнить работы, требующие одного человеко-года? Но у моего начальника был план...
На самом деле нам не нужна была полная архитектура CCU/CMU. Телефонная компания, устанавливающая цифровой коммутатор, была маленькой. У них была только одна телефонная станция и всего два местных распределительных пункта. Важно отметить, что «местные» распределительные пункты были не совсем местными. Фактически они являлись старыми добрыми аналоговыми коммутаторами, к которым было подключено несколько сотен клиентов. К тому же эти коммутаторы принадлежали к типу, который успешно можно тестировать компьютерами COLT. Но самое замечательное, что телефонные номера клиентов включали всю информацию, необходимую для определения распределительного пункта. Если номер телефона включал цифру 5, 6 или 7 в определенной позиции, это означало, что он подключен к распределительному пункту 1; иначе — к распределительному пункту 2.
Итак, как объяснил мне мой начальник, нам в действительности нужна не полная архитектура CCU/CMU, а только простой компьютер в телефонной станции, связанный модемными линиями с двумя стандартными компьютерами COLT в распределительных пунктах. Компьютер SAC мог бы связываться с нашим компьютером в телефонной станции, а тот, в свою очередь, мог бы декодировать телефонный номер и посылать команды на выполнение тестирования в компьютер COLT, находящийся в соответствующем распределительном пункте.
Так родилась система pCCU.
Это был первый продукт, написанный на C и использующий BOSS, развернутый у клиента. На разработку мне понадобилось что-то около недели. Эта история ничем не выделяется с архитектурной точки зрения, но она служит хорошим предисловием для следующего проекта.
DLU/DRU
В начале 1980-х годов в числе наших клиентов была телефонная компания из Техаса. Она обслуживала обширную географическую область. Область была настолько большой, что для ее обслуживания требовалось несколько сервисных центров с ремонтниками. В этих центрах находились люди, которым требовались терминалы, связанные с нашим компьютером SAC.
Возможно, вы подумали, что это даже не проблема, но вспомните, что история происходила в начале 1980-х годов. Удаленные терминалы были редким явлением. Хуже того, оборудование SAC предполагало размещение терминалов поблизости. Наши терминалы фактически подключались к нашей собственной высокоскоростной последовательной шине.
У нас имелась возможность подключить удаленные терминалы только через модемы, которые в начале 1980-х годов могли передавать данные со скоростью не более 300 бит в секунду. Наши клиенты были недовольны такой низкой скоростью.
В то время уже существовали высокоскоростные модемы, но они стоили очень дорого и им требовалось «условно» постоянное соединение. Качество коммутируемых соединений было определенно недостаточно высоким.
Наши клиенты требовали найти решение. Нашим ответом стала система DLU/DRU.
Аббревиатура DLU/DRU расшифровывалась как «Display Local Unit» (локальное устройство отображения) и «Display Remote Unit» (удаленное устройство отображения). Устройство DLU — это компьютерная плата, включаемая в шасси SAC и играющая роль платы диспетчера терминала. Но вместо управления последовательной шиной, соединяющей локальные терминалы, это устройство принимало поток символов и мультиплексировало его через единственное модемное соединение с пропускной способностью 9600 бит/с.
Устройство DRU размещалось удаленно, у клиента. Оно подключалось к другому концу модемного соединения с пропускной способностью 9600 бит/с и включало оборудование для управления терминалами, подключенными к разработанной нами последовательной шине. Оно демультиплексировало символы, принимаемые из модема, и передавало их соответствующим локальным терминалам.
Странно, правда? Нам пришлось разрабатывать решение, настолько обыденное в наши дни, что о нем никто не задумывается. Но тогда...
Нам пришлось даже придумать свой протокол связи, потому что тогда стандартные протоколы не были общедоступны в виде исходных кодов. Фактически все происходило задолго до того, как у нас появилось подключение к Интернету.
Архитектура
Система имела очень простую архитектуру, но в ней были некоторые интересные особенности, которые я хотел бы подчеркнуть. Во-первых, оба устройства были сконструированы на нашей технологии 8085, программное обеспечение для обоих было написано на C и использовало BOSS. Но на этом их сходство заканчивается.
Над проектом работали два человека. Я, как руководитель проекта, и Майк Карев (Mike Carew), мой близкий друг. Я взял на себя проектирование и разработку DLU, а Майк — DRU.
Архитектура DLU основывалась на модели потока данных. Каждая задача выполняла небольшую узкоспециализированную работу и передавала свои результаты следующей задаче в конвейере, используя очередь. Представьте модель конвейеров и фильтров в UNIX. Архитектура получилась сложной. Добавлять данные в очередь могла одна задача, а извлекать их из нее — несколько.
Представьте сборочную линию. На каждом участке такой сборочной линии выполняется единственная, простая, узкоспециализированная операция. После выполнения операции на одном участке продукт перемещается по конвейеру к следующему. Иногда сборочная линия может разветвляться на несколько линий. Иногда несколько линий могут сливаться в одну линию. Такова была архитектура устройства DLU.
Устройство DRU, созданное Майком, было основано на совершенно другой схеме. Он создал по одной задаче на каждый терминал и просто выполнял в ней всю работу, имеющую отношение к данному терминалу. Никаких очередей. Никаких потоков данных. Просто несколько больших и одинаковых задач, каждая из которых управляет своим терминалом.
Это полная противоположность сборочной линии. В данном случае можно провести аналогию с несколькими опытными сборщиками, каждый из которых собирает свой продукт целиком.
В то время я думал, что моя архитектура лучше. Майк, конечно, думал, что его архитектура лучше. У нас было много интересных дискуссий на эту тему. Но, так или иначе, мы оба неплохо поработали. И мне оставалось лишь уяснить, что программные архитектуры могут быть совершенно разными, но одинаково эффективными.
VRS
На протяжении 1980-х годов появлялись все более и более новые технологии. Одной из таких технологий было голосовое управление компьютером.
Одной из функций системы 4-Tel было оказание помощи ремонтнику в поиске места повреждения кабеля. Процедура выглядела так:
• Тестировщик, работающий на телефонной станции, с помощью нашей системы определял расстояние в футах до точки повреждения с точностью около 20%. Затем он направлял ремонтника к точке доступа, ближайшей к повреждению.
• Ремонтник, прибыв на место, вызывал тестировщика и просил начать процесс определения места повреждения. Тестировщик запускал процедуру поиска неисправности в системе 4-Tel. Система измеряла электрические характеристики поврежденной линии и выводила на экран сообщения, описывающие действия, которые требовалось выполнить дальше, такие как вскрыть кабель или закоротить кабель.
• Тестировщик сообщал ремонтнику, какие операции требуется выполнить, а ремонтник сообщал, когда та или иная операция была выполнена. После этого тестировщик сообщал системе, что затребованная операция выполнена, и она возобновляла тестирование.
• После двух-трех операций система рассчитывала новое расстояние до повреждения. После этого ремонтник мог переехать в указанное место и процесс повторялся вновь.
Представьте, насколько проще было бы, если бы ремонтник, поднявшись на столб или опору, мог бы сам управлять системой. Именно эту возможность дали нам новые голосовые технологии. Ремонтник мог бы вызвать систему непосредственно, управлять ею с помощью тонального набора и прослушивать ответы, читаемые приятным голосом.
Название
Компания провела небольшой конкурс по выбору названия для новой системы. Одним из самых необычных предложений было имя SAM CARP. Оно расшифровывалось как «Still Another Manifestation of Capitalist Avarice Repressing the Proletariat» (еще одно проявление капиталистической алчности, подавляющей пролетариат). Разумеется, это название не было выбрано.
Еще одно название — Teradyne Interactive Test System (интерактивная тест-система Tradyne) — тоже не было выбрано.
Также не было выбрано название Service Area Test Access Network (сеть доступа к тест-системе зоны обслуживания).
Победило название VRS: Voice Response System (система с голосовым ответом).
Архитектура
Мне не довелось работать над этой системой, но я был в курсе происходящего. Историю, которую я собираюсь рассказать, вы узнаете из вторых рук, но это не повлияло на ее правдивость.
Это был период эйфории, связанной с микрокомпьютерами, операционными системами UNIX, C и базами данных SQL. Мы были полны решимости использовать все это.
Из множества баз данных мы выбрали UNIFY — систему управления базами данных для UNIX, что было идеально для нас.
База данных UNIFY поддерживала также новую технологию с названием Embedded SQL, позволявшую внедрять команды SQL в виде строк прямо в код на языке C. Что мы и не преминули сделать, причем повсюду.
Я имею в виду, это было так необычно — иметь возможность поместить код SQL прямо в программный код, в любое место, куда захотите. И куда мы захотели? Да повсюду! В результате код SQL оказался размазан ровным слоем по всему программному коду.
В те времена SQL еще не был солидным стандартом. Каждый производитель добавлял в язык SQL какие-то свои особенности. Поэтому нестандартный код SQL и нестандартные вызовы UNIFY API можно было увидеть повсюду в программном коде.
Но все работало замечательно! Система оказалась успешной. Ремонтники пользовались ею, и телефонные компании полюбили ее. Жизнь улыбалась нам.
Затем поддержка продукта UNIFY прекратилась.
Ой-ё!
Поэтому мы решили переключиться на SyBase. Или это была Ingress? Я не помню. Но важно не это, а то, что нам пришлось отыскать в коде на C весь код SQL и вызовы нестандартного API и заменить их аналогичным кодом, взаимодействующим с новой базой данных.
Через три месяца мы прекратили бесплодные попытки. Мы не могли заставить систему работать с новой базой данных. Мы оказались настолько привязанными к UNIFY, что не было никакой надежды реструктурировать код с более или менее разумными издержками.
В результате мы наняли сторонних специалистов, поддерживавших UNIFY для нас, заключив с ними контракт на техническое обслуживание. И конечно, с каждым годом затраты на обслуживание росли.
В заключение о VRS
Таким способом я узнал, что базы данных — это деталь, которую следует изолировать от общей бизнес-цели системы. Это также одна из причин, почему мне не нравится зависимость от сторонних систем.
Электронный секретарь
В 1983 году наша компания оказалась на стыке компьютерных, телекоммуникационных и голосовых систем. Наш генеральный директор считал, что такое положение может способствовать разработке новых продуктов. Он поручил команде из трех человек (включая меня) придумать, спроектировать и реализовать новый продукт для компании.
Нам не потребовалось много времени, чтобы прийти к идее создания электронного секретаря (Electronic Receptionist; ER). Суть была проста. Когда вы звонили в компанию, электронный секретарь (ER) поднимал трубку и спрашивал, с кем бы вы хотели поговорить. Вы могли ответить на вопрос, нажимая кнопки на телефоне в режиме тонального набора, и таким способом сообщить имя человека, а ER соединял вас с ним. То есть пользователи могли позвонить на номер электронного секретаря и, используя простые тональные команды, связаться с нужным человеком, где бы тот ни находился. Фактически система могла попробовать несколько альтернативных номеров.
Когда кто-то звонил электронному секретарю и набирал RMART (мой код), тот, в свою очередь, звонил по первому номеру в моем списке. В случае неудачи он звонил по следующему номеру, и т.д. Если связаться со мной не удалось, электронный секретарь мог бы записать голосовое сообщение для меня.
Затем электронный секретарь предпринимал периодические попытки найти меня и доставить сообщение, оставленное для меня кем-то другим.
Это была первая система голосовой почты, и мы получили патент на нее.
Мы собрали все необходимое оборудование для этой системы — компьютерную плату, плату памяти, платы для связи и записи голоса и все остальное. Роль компьютерной платы играла плата компьютера Deep Thought (Думатель) на процессоре Intel 80286, о котором я уже рассказывал.
Для каждой телефонной линии была создана отдельная голосовая плата. Эти платы содержали телефонный интерфейс, аппаратуру для кодирования/декодирования голоса, некоторый объем памяти и микрокомпьютер Intel 80186.
Программное обеспечение для главной компьютерной платы было написано на C. В качестве операционной системы использовалась MP/M-86, одна из первых многозадачных дисковых систем, управляемых из командной строки. MP/M — это UNIX для бедных.
Программное обеспечение для голосовых плат было написано на ассемблере и действовало без операционной системы. Взаимодействие компьютера Deep Thought с голосовыми платами осуществлялось через общую память.
Архитектуру этой системы в наши дни назвали бы сервис-ориентированной. Каждая телефонная линия обслуживалась отдельным процессом, действующим под управлением MP/M.
Когда поступал входящий звонок, запускался начальный процесс для обработки и звонок передавался ему. По мере перехода обслуживания звонка из одной стадии в другую запускался соответствующий процесс-обработчик и управление передавалось ему.
Сообщения передавались между этими службами через дисковые файлы. Текущая выполняющаяся служба могла определить, какую службу запустить далее; записать необходимую информацию в дисковый файл; выполнить команду для запуска этой службы и затем завершиться.
Я впервые занимался созданием такой системы. В действительности это был первый раз, когда я выступал в роли главного архитектора продукта. Все, что имело отношение к программному обеспечению, было моим — и все работало как надо.
Я не могу сказать, что архитектура этой системы была «чистой» в том смысле, в каком предполагает эта книга; она не была архитектурой «сменных модулей» (плагинов). Однако в ней имелись явные признаки истинных границ. Службы развертывались независимо, и каждая отвечала за определенную предметную область. В системе имелись процессы высокого и низкого уровня, и многие зависимости простирались в правильном направлении.
Конец электронного секретаря
К сожалению, попытки продать этот продукт оказались неудачными. Компания Teradyne специализировалась на производстве контрольно-измерительного оборудования. Мы не представляли, как проникнуть на рынок конторского оборудования.
После неоднократных попыток, продолжавшихся в течение более двух лет, наш генеральный директор отказался от них и — к сожалению — отозвал заявку на патент. Патент был получен другой компанией, подавшей заявку через три месяца после нашей; так мы сдали рынок голосовой почты и электронной переадресации звонков.
Ой-ёй!
Зато теперь вы не сможете поставить мне в вину появление всех этих раздражающих машин, отравляющих наше существование.
Система командирования ремонтников
Электронный секретарь потерпел неудачу как продукт, но у нас оставалось программное обеспечение и оборудование, которые мы могли бы использовать для расширения линейки имеющихся продуктов. Кроме того, успех VRS на рынке убедил нас, что мы должны предложить систему с голосовым ответом для организации взаимодействий с ремонтниками, которые не зависят от наших систем тестирования.
Так родилась CDS — система командирования ремонтников (Craft Dispatch System). По сути, система CDS была электронным секретарем (ER), но ориентированным на решение узкого круга задач в области управления ремонтниками.
Когда в телефонной линии обнаруживалась проблема, в сервисный центр посылалась заявка. Заявки хранились в автоматизированной системе. Когда ремонтник, работающий в поле, завершал обслуживание заявки, он звонил в сервисный центр, чтобы получить следующее назначение. Оператор сервисного центра извлекал следующую заявку и читал ее вслух ремонтнику.
Мы приступили к автоматизации этого процесса. Наша цель состояла в том, чтобы создать систему CDS, которой мог бы позвонить ремонтник, работающий в поле, и запросить следующее назначение. Система должна была обратиться к системе заявок и зачитать извлеченную из нее заявку. Система CDS могла бы следить за назначением заявок ремонтникам и информировать систему заявок о приеме заявки к исполнению.
Эта система имела немало интересных особенностей, связанных с взаимодействием с системой заявок, системой управления предприятием и системами автоматизированного тестирования.
Опыт разработки сервис-ориентированной архитектуры ER пробудил во мне желание еще раз опробовать эту идею. Машина состояний для обработки заявок оказалась намного сложнее, чем машина состояний для обработки звонков в электронном секретаре. Я приступил к созданию архитектуры, которая в наши дни называется архитектурой микрослужб.
Каждый переход между этапами обслуживания любого звонка, каким бы незначительным он ни был, вынуждал систему запускать новую службу. В действительности все переходы описывались в текстовом файле, который читала система. Каждое событие, поступающее в систему по телефонной линии, вызывало соответствующий переход между службами. Существующий процесс мог запускать для обработки события новый процесс, в соответствии с текущим состоянием; затем существующий процесс мог завершиться или ждать в очереди.
Такое решение позволяло нам изменять порядок выполнения операций без изменения кода (принцип открытости/закрытости). Мы легко могли добавлять новые службы независимо от других и внедрять их в поток, просто изменяя текстовый файл с описаниями переходов. Мы могли делать это даже в процессе работы системы. Иными словами, у нас появился механизм горячей замены и эффективный язык выполнения бизнес-процессов (Business Process Execution Language; BPEL).
Старый прием использования дисковых файлов для взаимодействий между службами, реализованный в электронном секретаре, был слишком медленным для этих быстро сменяющих друг друга служб, поэтому мы изобрели механизм общей памяти, который назвали 3DBB. Механизм 3DBB позволял обращаться к данным по именам; в качестве имен использовались названия, присвоенные экземплярам машины состояний.
Общая память прекрасно подходила для хранения строк и констант, но ее нельзя было использовать для хранения сложных структур данных. Причина была чисто технической. Каждый процесс в MP/M находился в собственном сегменте памяти. Указатели на данные в одном сегменте не имели смысла в другом. Как следствие, данные в общей памяти не могли содержать указатели. Строки можно хранить без ограничений, но деревья, связные списки и любые другие структуры данных с указателями — нет.
Система заявок получала заявки из разных источников. Некоторые добавлялись автоматически, некоторые — вручную. Заявки, добавляемые вручную, создавались операторами, общавшимися с клиентами. По мере того как клиент описывал проблему, оператор вводил жалобы и наблюдения в структурированный поток текста. Он выглядел примерно так:
/pno 8475551212 /noise /dropped-calls
Идея должна быть понятна. Символ / начинал новую тему. За этим символом следовал код, за кодом — параметры. Таких кодов были тысячи, а в описании каждой заявки их могло быть до нескольких десятков. Хуже того, операторы часто допускали опечатки или ошибались в форматировании. Люди прекрасно справлялись с интерпретацией таких заявок, но не машины.
Перед нами стояла задача — декодировать эти строки, интерпретировать, исправить возможные ошибки и преобразовать их в голосовые сообщения, которые могли бы прослушивать ремонтники по телефону. Для этого кроме всего прочего требовалось реализовать очень гибкий анализ и формат представления данных. Данные в этом формате должны были передаваться через общую память, которая могла обслуживать только строки.
Итак, в короткие перерывы между посещениями клиентов я изобрел схему, которую назвал FLD: Field Labeled Data (данные с маркированными полями). В наши дни мы назвали бы этот формат XML или JSON. Формат представления отличался, но идея была той же. Схема FLD представляла данные в виде бинарного дерева, которые ассоциировали имена с данными в рекурсивной иерархии. Данные в формате FLD можно было получить с применением простого API и преобразовать в строковое представление, идеально подходящее для передачи через общую память.
То есть уже в 1985 году микрослужбы обменивались информацией через общую память — аналог сокетов, — используя формат, аналогичный XML.
Ничто не ново под луной.
Clear Communications
В 1988 году группа сотрудников Teradyne покинула компанию, чтобы основать новую фирму под названием Clear Communications. Я присоединился к ним несколькими месяцами позже. Нашей целью было создание программного обеспечения для системы, осуществлявшей контроль качества связи по линиям T1 — цифровым линиям для междугородной связи по всей стране. Мы видели ее как огромный монитор с картой США и пересекающей ее сеткой линий T1, которые начинали мигать красным, если обнаруживались проблемы.
В 1988 году графические пользовательские интерфейсы только стали появляться. Модели Apple Macintosh было всего пять лет. Windows в ту пору не стоила доброго слова. Но компания Sun Microsystems строила станции Sparc, имевшие превосходный графический интерфейс X-Window. Поэтому мы пошли с Sun, а значит, с языком C и операционной системой UNIX.
Это был период становления новой компании. Мы работали по 70–80 часов в неделю. У нас было видение. У нас была мотивация. У нас была воля. У нас была энергия. У нас был опыт. Мы были равны. Мы мечтали стать миллионерами. Мы были безрассудны.
Код на C лился из нас как из рога изобилия. Мы вталкивали и впихивали его то туда, то сюда. Мы строили огромные воздушные замки. У нас были процессы, очереди сообщений и великолепные архитектуры. Мы написали семиуровневый ISO-стек взаимодействий с нуля — вплоть до канального уровня передачи данных.
Мы писали код графического интерфейса. ГРЯЗНЫЙ КОД! Бог мой! Мы писали СЛИШКОМ ГРЯЗНЫЙ КОД.
Я лично написал на C функцию с именем gi() длиной в 3000 строк; ее имя расшифровывалось как Graphic Interpreter (графический интерпретатор). Это был шедевр грязи. Это не единственный грязный код, который я написал в Clear, но этот был самым позорным.
Архитектура? Вы шутите? Это был период становления. У нас не было времени на архитектуру. Только код, черт возьми! Код, от которого зависело наше будущее благополучие!
Поэтому мы писали, писали и писали код. А через три года мы прогорели. Нет, мы смогли продать один или два экземпляра системы. Но рынок не особенно интересовался нашим грандиозным видением, и наши инвесторы были уже сыты по горло.
В тот момент я ненавидел свою жизнь. Я видел, как прахом идут все мои усилия и рушатся мои мечты. У меня стали возникать конфликты на работе, конфликты дома из-за работы и конфликты с самим собой.
И тогда я принял телефонный звонок, который все изменил.
Обстановка
За два года до этого звонка произошло два важных события.
Во-первых, мне удалось настроить uucp-соединение с соседней компанией, имевшей uucp-соединение с другим объектом, подключенным к Интернету. Это, конечно же, были коммутируемые соединения. Наша основная Sparc-станция (стоявшая на моем рабочем столе) использовала модем со скоростью передачи 1200 бит/с для соединения с нашим uucp-хостом дважды в день. Это дало нам электронную почту и доступ к Netnews (первой социальной сети, где люди обсуждали разные интересные вопросы).
Во-вторых, Sun выпустила компилятор C++. Я интересовался языком C++ и объектно-ориентированным программированием начиная с 1983 года, но компилятор тогда было трудно найти. Поэтому, как только представилась возможность, я сразу же сменил язык. Я оставил функции на C из 3000 строк и начал писать код на C++ для Clear. И я учился...
Я читал книги. Конечно, я прочитал The C++ Programming Language и The Annotated C++ Reference Manua Бьёрна Страуструпа. Я прочитал прекрасную книгу Ребекки Вирфс-Брок о проектировании, основанном на ответственности: Designing Object Oriented Software. Я прочитал OOA, OOD и OOP Петера Коуда. Я прочитал Smalltalk-80 Адель Голдберг. Я прочитал Advanced C++ Programming Styles and Idioms Джеймса О. Коплиена. Но самое главное, пожалуй, я прочитал Object Oriented Design with Applications Гради Буча.
Какое имя! Гради Буч. Как можно забыть такое имя. Более того, он был главным научным консультантом в компании с названием Rational! Как я хотел быть главным научным консультантом! И поэтому я читал его книгу. И учился, учился, учился...
Одновременно с учебой я начал вступать в дискуссии на Netnews, подобно тому, как ныне люди дискутируют в Facebook. Я участвовал в обсуждениях на тему C++ и ООП. В течение двух лет я освобождался от разочарований, которые приобретал на работе, обсуждая с сотнями пользователей Usenet лучшие особенности языка и принципы проектирования. Через какое-то время многое для меня стало проясняться.
Именно в одной из таких дискуссий были заложены принципы SOLID.
И все эти обсуждения и, возможно, даже некоторый смысл, который я вносил, сделали меня заметным...
Дядюшка Боб
В Clear работал один молодой инженер, Билли Фогель. Билли всем давал прозвища. Меня он называл дядюшкой Бобом. Мое имя действительно Боб, но я подозреваю, что он намекал на Дж. Р. «Боба» Доббса (рис. П.9).

Рис. П.9. Дж. Р. «Боб» Доббс (J. R. «Bob» Dobbs)
Сначала я терпел это. Но проходили месяц за месяцем, и его непрекращающееся: «дядюшка Боб... дядюшка Боб», — на фоне неудач и разочарования новой компанией стали вызывать раздражение.
А потом однажды зазвонил телефон.
Телефонный звонок
Это был сотрудник из кадрового агентства. Он узнал мое имя, подыскивая человека, знающего C++ и принципы объектно-ориентированного проектирования. Я не знаю, как он его узнал, но предполагаю, что это как-то связано с моим присутствием в Netnews.
Он сказал, что у него есть свободная вакансия в Кремниевой долине, в компании Rational. Они искали специалиста для помощи в разработке CASE-инструмента.
Кровь отхлынула от моего лица. Я знал, что это за компания. Не знаю, откуда я это узнал, но я знал. Это была компания Гради Буча. Я увидел возможность оказаться в одной команде с Гради Бучем!
ROSE
Я поступил на работу в компанию Rational, как программист по контракту, в 1990 году. Я работал над продуктом с названием ROSE. Это был инструмент, позволявший программистам рисовать диаграммы Буча — диаграммы, которые Гради использовал в книге Object-Oriented Analysis and Design with Applications (пример такой диаграммы изображен на рис. П.10).
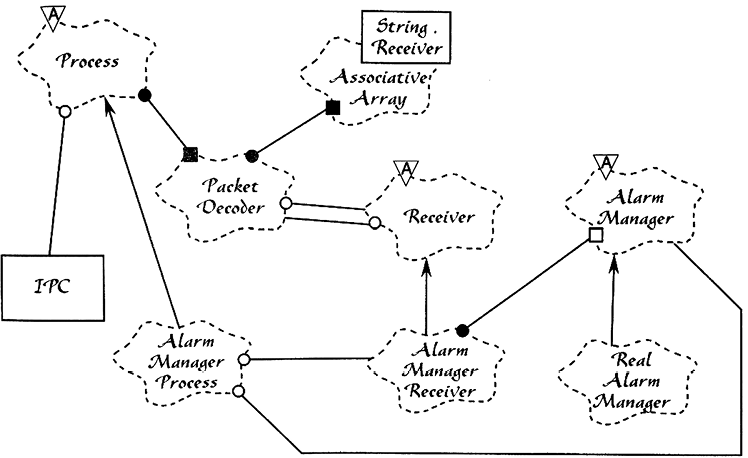
Рис. П.10. Диаграмма Буча
Диаграммы Буча были очень выразительными. Они предвосхитили такие диаграммы, как UML.
Продукт ROSE имел архитектуру — настоящую архитектуру. Она состояла из истинных уровней, и все зависимости между уровнями были ориентированы как должно. Архитектура обеспечила этому продукту возможность раздельного выпуска, разработки и развертывания его компонентов.
О, он не был идеальным. Мы еще многого не понимали в архитектурных принципах. Например, мы не создали истинную структуру со сменными модулями (плагинами).
Мы также попались на одно из самых неудачных увлечений тех дней — мы использовали так называемую объектно-ориентированную базу данных.
Но в целом опыт был отличным. Я проработал полтора прекрасных года с командой из Rational над ROSE. Это был один из самых познавательных опытов в моей профессиональной жизни.
Продолжение дискуссий
Конечно, я не прекратил участвовать в обсуждениях на Netnews. В действительности я резко увеличил свое присутствие в сети. Я начал писать статьи для C++ Report. И с помощью Гради приступил к своей первой книге: Designing Object-Oriented C++ Applications Using the Booch Method.
Одна мысль беспокоила меня. Пусть она была недостойной, но тем не менее. Никто не называл меня «дядюшкой Бобом». Я обнаружил, что мне этого не хватает. Поэтому я допустил ошибку, добавив подпись «Uncle Bob» (дядюшка Боб) в мои электронные письма и сообщения в Netnews. И это имя прилипло ко мне. В конце концов я понял, что это довольно неплохой бренд.
...Под любым другим именем
ROSE — это гигантское приложение на C++. Оно состояло из уровней со строго соблюдаемым правилом зависимости. Это не то правило, что я описал в данной книге. Мы ориентировали наши зависимости не в сторону политик более высокого уровня, а в более традиционном направлении — в направлении потока управления. Пользовательский интерфейс зависел от представления, которое зависело от правил выполнения операций с данными, которые зависели от базы данных. В результате эта, не совсем удачная ориентация зависимостей способствовала кончине продукта.
Архитектура ROSE была похожа на архитектуру хорошего компилятора. Графическая нотация «преобразовывалась» во внутреннее представление; затем это представление обрабатывалось правилами и сохранялось в объектно-ориентированной базе данных.
Объектно-ориентированные базы данных были относительно новой идеей, и мир ОО был взволнован возможными перспективами. Каждый объектно-ориентированный программист желал иметь объектно-ориентированную базу данных в своей системе. Идея была относительно простой и глубоко идеалистической. База данных хранила объекты, а не таблицы. База данных должна была выглядеть как ОЗУ. Когда производилось обращение к объекту, он просто возникал в памяти. Если этот объект ссылался на другой объект, тот другой объект тоже появлялся в памяти при первой попытке обратиться к нему. Это было похоже на волшебство.
Выбор этой базы данных стал, пожалуй, самой большой нашей ошибкой. Мы желали волшебства, а в результате получили большой, медленный, навязчивый, дорогостоящий сторонний фреймворк, который превратил нашу жизнь в ад, препятствуя нашему движению вперед почти на всех уровнях.
Выбор базы данных был не единственной нашей ошибкой. Гораздо более серьезной ошибкой фактически стало излишнее усердие в отношении к проектированию архитектуры. У нас получилось намного больше уровней, чем я описал здесь, и каждый привносил свои накладные расходы на взаимодействия. Это отрицательно сказалось также на продуктивности команды.
В итоге, после многих человеко-лет работы, тяжелой борьбы и выпуска двух слабых версий, весь инструмент был заменен маленьким приложением, написанным небольшой командой из Висконсина.
Так я узнал, что великие архитектуры иногда приводят к великим провалам. Архитектура должна быть достаточно гибкой, чтобы подстраиваться под размер задачи. Разработка архитектуры для уровня предприятия, когда в действительности нужен маленький и удобный инструмент для настольного компьютера, — это верный рецепт провала.
Регистрационные экзамены для архитекторов
В начале 1990-х годов я стал настоящим консультантом. Я ездил по миру и обучал людей новым объектно-ориентированным подходам. В своих консультациях я строго ограничивался дизайном и архитектурой объектно-ориентированных систем.
Одним из моих первых клиентов была компания Educational Testing Service (ETS). Она имела контракт с Национальным советом регистрационной коллегии по архитектуре (National Council of Architects Registry Board, NCARB) по проведению регистрационных экзаменов для новых кандидатов в архитекторы.
Любой желающий стать зарегистрированным архитектором (проектирующим здания) в США или Канаде должен сдать регистрационный экзамен. На этом экзамене кандидату предлагается решить несколько архитектурных задач, связанных с проектированием зданий. Кандидату передается ряд требований для проектирования общественной библиотеки, ресторана или церкви и затем предлагается нарисовать комплект архитектурных схем.
Результаты собираются и сохраняются, пока не соберется комиссия ведущих архитекторов для оценки. Создание комиссии — большое, дорогостоящее событие и вечный источник задержек и недопонимания.
Совет NCARB хотел автоматизировать процесс и организовать сдачу экзаменов с использованием компьютера, а оценку поданных решений производить с помощью другого компьютера. Совет NCARB предложил компании ETS разработать соответствующее программное обеспечение, а ETS наняла меня для создания команды разработчиков с целью разработки этого продукта.
Компания ETS разбила проблему на 18 экзаменационных заданий. Для каждого требовалось создать приложение с графическим интерфейсом в стиле систем автоматизированного проектирования, которое кандидат мог бы использовать для оформления своего решения. Анализ и оценку решений должны производить другие 18 приложений.
Мы с моим партнером Джимом Ньюкирком заметили, что эти 36 приложений имеют огромное сходство. Все 18 экзаменационных приложений с графическим интерфейсом должны реализовать схожие операции и использовать схожие механизмы. Другие 18 приложений, оценивающие решения, должны использовать один и тот же математический аппарат. Учитывая большое количество общих элементов, Джим и я решили разработать многократно используемую инфраструктуру, которая должна лечь в основу всех 36 приложений. Фактически мы продали эту идею компании ETS, заявив, что на разработку первого приложения потребуется много времени, зато все последующие будут выпущены в течение нескольких недель.
Прочитав эти строки, многие из вас могли бы выразить крайнее удивление. Но читатели постарше наверняка помнят, как объектно-ориентированный подход обещал «многократное использование». В ту пору мы все были убеждены, что если писать хороший, чистый, объектно-ориентированный код на C++, в результате получится много-много кода, пригодного для многократного использования.
Итак, мы приступили разработке первого приложения — самого сложного в пакете. Мы назвали его Vignette Grande.
Мы вдвоем работали над Vignette Grande с прицелом на создание инфраструктуры многократного использования. Нам понадобился год. К концу этого года у нас были 45 000 строк инфраструктурного и 6000 строк прикладного кода. Мы принесли этот продукт в ETS, и они заключили с нами контракт на создание других 17 приложений в ограниченный срок.
Мы с Джимом наняли еще трех разработчиков и приступили к созданию следующих нескольких экзаменационных приложений.
Но что-то пошло не так. Мы обнаружили, что наша инфраструктура оказалась почти непригодна для многоразового использования. Она не вписывалась в новые приложения. Имелись шероховатости, мешавшие работе.
Мы были сильно обескуражены, но считали, что знаем, как поступить с этим. Мы пришли в ETS и сказали, что задерживаемся — что 45 000-строчную инфраструктуру требуется переписать или хотя бы скорректировать и что для этого потребуется еще много времени.
Я думаю, излишне говорить, что в ETS не очень обрадовались этой новости. Тем не менее мы начали все сначала. Мы отложили старую инфраструктуру и приступили к созданию сразу четырех новых экзаменационных приложений. Мы заимствовали некоторые идеи и код из старой инфраструктуры, но переделывали их так, чтобы они вписывались во все четыре приложения без изменений.
На это ушел еще один год. Мы написали другую инфраструктуру с 45 000 строк кода плюс четыре экзаменационных приложения, содержавших от 3000 до 6000 строк каждое. Разумеется, отношения между приложениями и инфраструктурой следовали правилу зависимости. Приложения были плагинами для инфраструктуры. Все высокоуровневые политики находились в инфраструктуре. Прикладной код просто «склеивал» разные операции.
Отношения между инфраструктурой и приложениями оценки решений оказались намного сложнее. Высокоуровневая политика оценки находилась в приложении. Инфраструктура оценки подключалась как плагин к приложению оценки.
Конечно, приложения обоих видов компоновались статически, поэтому в наших головах полностью отсутствовало понятие «плагин». И тем не менее зависимости были выстроены в полном соответствии с правилом зависимости.
Закончив эти четыре приложения, мы приступили к следующим четырем. На этот раз они были готовы через несколько недель, как мы и предсказывали. Непредусмотренная задержка отняла у нас почти год, поэтому, чтобы ускорить процесс и уложиться в график, мы наняли еще одного программиста.
Мы уложились в срок и выполнили свои обязательства. Наш клиент был счастлив. Мы были счастливы. Жизнь была прекрасна.
Но мы получили хороший урок: нельзя создать универсальную инфраструктуру, не создав прежде работающую инфраструктуру. Универсальные инфраструктуры должны создаваться одновременно с несколькими приложениями, использующими их.
Заключение
Как я сказал в начале, это приложение несколько автобиографично. Я описал наиболее яркие моменты в проектах, которые, по моему мнению, имели большое архитектурное влияние. И конечно, я привел несколько эпизодов, не имеющих прямого отношения к технической стороне книги, но которые тем не менее имели большое значение.
Разумеется, это далеко не полная история. В моей карьере было много других проектов. Кроме того, я намеренно ограничил освещение истории началом 1990-х годов, потому что у меня есть еще одна книга, посвященная событиям конца 1990-х годов.
Я надеюсь, что вам понравился этот небольшой экскурс по волнам моей памяти и вы смогли почерпнуть что-то новое из моего опыта.
В ASC нам рассказали историю, как транспортировалась эта ЭВМ. Ее везли на большом грузовике с полуприцепом вместе с мебелью. По пути грузовик, двигаясь на высокой скорости, зацепил крышей мост. ЭВМ не пострадала, но она сместилась вперед и вдребезги раздавила мебель.
Сегодня мы могли бы сказать, что она работала с тактовой частотой 142 КГц.
Представьте массу диска, какой кинетической энергией он обладал! Однажды мы заметили металлическую стружку, вылетевшую из корпуса диска. Мы вызвали ремонтника, и он тут же попросил выключить диск. Закончив ремонт, он сказал, что износился один из подшипников. Затем он рассказал нам, как однажды вовремя не отремонтированный диск сорвался с креплений, пробил бетонную стену и застрял в автомобиле на стоянке рядом.
С электронно-лучевыми трубками зеленого свечения, способные отображать только символы ASCII.
CRUD — аббревиатура, обозначающая набор основных операций с данными: Create (создание), Read (чтение), Update (изменение) и Delete (удаление). — Примеч. пер.
Магическое число 72 пришло из эпохи перфокарт Hollerith, содержавших по 80 символов каждая. Последние 8 символов «резервировались» под порядковый номер на случай, если вы уроните и рассыплете колоду.
Да, я понимаю, что это оксюморон.
Для этого в микросхемах имелись прозрачные пластиковые окошки, через которые можно было видеть кремниевые кристаллы внутри и стирать данные ультрафиолетом.
Да, я знаю, что после записи программного обеспечения в ПЗУ оно превращается в микропрограмму, но микропрограмма не перестает быть программным обеспечением.
«Думатель», так назывался компьютер из фантастического романа Дугласа Адамса, давший «ответ на главный вопрос жизни, вселенной и всего такого» ()). — Примеч. пер.
RKO7.
Последнее переиздание на русском языке: Брайн Керниган, Денис Ритчи. Язык программирования C.М.: Вильямс, 2016. — Примеч. пер.
Позднее эта аббревиатура получила другую расшифровку: Bob’s Only Successful Software (успешное программное обеспечение Боба).
Держателем патента стала наша компания. В нашем контракте с работодателем однозначно говорилось, что права на любые наши изобретения будут принадлежать компании. Мой начальник сказал мне: «Вы продали нам это за один доллар, но мы не выплатили вам этот доллар».
Three-Dimensional Black Board — трехмерная черная доска. Если вы родились в 1950-х годах, вам наверняка более знакомой покажется фраза: Drizzle, Drazzle, Druzzle, Drone.
Страуструп Б. Язык программирования C++. М.: Бином, 2017. — Примеч. пер.
Эллис М., Строуструп Б. Справочное руководство по языку программирования С++ с комментариями. М.: Мир, 1992. — Примеч. пер.
Коплиен Д., Программирование на C++. Классика CS. СПб.: Питер, 2004. — Примеч. пер.
Гради Буч, Роберт А. Максимчук, Майкл У. Энгл, Бобби Дж. Янг, Джим Коналлен, Келли А. Хьюстон. Объектно-ориентированный анализ и проектирование с примерами приложений. М.: Вильямс, 2010. — Примеч. пер.
Computer Aided Software Engineering — автоматизация разработки программного обеспечения.

