17. Границы: проведение разделяющих линий

Разработка архитектуры программного обеспечения — это искусство проведения разделяющих линий, которые я называю границами. Границы отделяют программные элементы друг от друга и избавляют их от необходимости знать, что находится по ту сторону. Некоторые из этих линий можно провести на самых ранних этапах развития проекта — даже до появления первого программного кода. Другие проводятся намного позже. Границы, проводимые на ранних этапах, призваны отложить принятие решений на как можно долгий срок и предотвратить загрязнение основной бизнес-логики этими решениями.
Напомню, что целью архитектора является минимизация трудозатрат на создание и сопровождение системы. Что может помешать достижению этой цели? Зависимость — и особенно зависимость от преждевременных решений.
Какие решения можно назвать преждевременными? Решения, не имеющие ничего общего с бизнес-требованиями — вариантами использования — системы. К ним можно отнести решения о выборе фреймворка, базы данных, веб-сервера, вспомогательных библиотек, механизма внедрения зависимостей и т.п. В хорошей архитектуре подобные решения носят вспомогательный характер и откладываются на потом. Хорошая архитектура не зависит от таких решений. Хорошая архитектура позволяет принимать эти решения в самый последний момент без существенного влияния на саму архитектуру.
Пара печальных историй
Расскажу одну печальную историю о компании P, которая послужит предупреждением всем, кто торопится принимать решения. В 1980-х годах основатели компании P написали простое монолитное приложение для настольного компьютера. Оно пользовалось большим успехом, и в 1990-е годы этот продукт превратили в популярное и успешное приложение с графическим интерфейсом.
Но потом, в конце 1990-х годов, началось бурное развитие Всемирной паутины. Многие внезапно решили, что у них должны быть свои веб-решения, и P не стала исключением. Клиенты компании P настойчиво требовали написать версию продукта для Веб. Чтобы удовлетворить это требование, компания наняла двадцать с лишним крутых программистов на Java и приступила к проектированию веб-версии своего продукта.
Парни грезили о фермах серверов, поэтому решили выбрать богатую трехуровневую «архитектуру», которую они могли бы развернуть на такой ферме. Они предполагали, что у них будут отдельные серверы для обслуживания интерфейса с пользователем, серверы для промежуточного программного обеспечения и серверы для баз данных. Но красиво было на бумаге, да забыли про овраги.
Программисты слишком рано решили, что все предметные объекты должны иметь по три экземпляра: один для уровня графического интерфейса, один для промежуточного уровня и один для уровня базы данных. Так как все эти экземпляры находились на разных серверах, была создана разветвленная система взаимодействий между процессами и уровнями. Вызовы методов между уровнями преобразовывались в объекты, которые подвергались сериализации и передавались по сети.
Теперь представьте, во что выливается простое изменение, такое как добавление нового поля в существующую запись. Поле нужно добавить в классы на всех трех уровнях, а также в некоторые сообщения, циркулирующие между уровнями. Так как передача данных происходит в обоих направлениях, необходимо спроектировать четыре протокола обмена сообщениями. Каждый протокол имеет отправляющую и принимающую стороны, итого необходимо реализовать восемь обработчиков протоколов. Нужно собрать три выполняемых файла, в каждом из которых находятся три измененных бизнес-объекта, четыре новых сообщения и восемь новых обработчиков.
А теперь задумайтесь, что все эти выполняемые файлы должны делать, чтобы выполнить простейшее действие. Они создают экземпляры объектов, выполняют их сериализацию, маршалинг и демаршалинг, конструируют и анализируют сообщения, выполняют операции с сокетами, обрабатывают тайм-ауты и производят повторные попытки и много чего еще только ради выполнения одной простой операции.
Конечно, во время разработки у программистов не было фермы серверов. В действительности они просто запускали все три выполняемых файла в трех разных процессах на одной машине. Так они развивали проект в течение нескольких лет, но были уверены, что их архитектура правильная. И поэтому даже когда система выполнялась на одной машине, она по-прежнему продолжала создавать объекты, выполнять их сериализацию, маршалинг и демаршалинг, конструировать и анализировать сообщения, оперировать сокетами и много чего еще, ненужного на одной машине.
По иронии ни одна из систем, проданных компанией P, не требовала фермы серверов. Все системы, когда-либо развертывавшиеся компанией, размещались на единственном сервере. И на этом единственном сервере три выполняемых файла продолжали создавать объекты, выполнять их сериализацию, маршалинг и демаршалинг, конструировать и анализировать сообщения, оперировать сокетами и много чего еще в ожидании фермы серверов, которая никогда не существовала и никогда не будет существовать.
Трагедия в том, что архитекторы, приняв преждевременное решение, чрезмерно увеличили трудозатраты на разработку.
История с компанией P не единственная. Я наблюдал нечто подобное много раз и во многих местах. Фактически компания P является лишь одним из примеров.
Но есть еще более печальные примеры, чем пример компании P.
Представьте себе компанию W, местное предприятие, управляющее парками служебных автомобилей. Недавно они наняли «Архитектора», чтобы взять под контроль разрозненные усилия по разработке программного обеспечения. И, хочу вам сообщить, «Контроль» — это второе имя того парня. Он быстро решил, что требуется создать полномасштабную, корпоративную, сервис-ориентированную «АРХИТЕКТУРУ». Он создал гигантскую предметную модель всех возможных «бизнес-объектов», спроектировал набор служб для управления этими объектами и направил разработчиков по пути в Ад. Чтобы было понятнее, представьте, что вам понадобилось добавить имя, адрес и номер телефона контактного лица в запись о продаже. Для этого нужно обратиться в ServiceRegistry, запросить идентификатор службы ContactService. Затем послать сообщение CreateContact в ContactService. Конечно, это сообщение имеет десятки полей, каждое из которых должно содержать достоверные данные — данные, к которым у программиста не было доступа, потому что программист имел только имя, адрес и номер телефона. После заполнения полей ложными данными программист должен был вставить идентификатор вновь созданного контакта в запись и послать сообщение UpdateContact службе SaleRecordService.
Чтобы протестировать все это, нужно по порядку запустить все необходимые службы, поднять шину сообщений и сервер BPel и... И затем все эти сообщения перемещались от службы к службе и ждали обработки то в одной очереди, то в другой.
Чтобы добавить что-то новое, представьте только зависимости между всеми этими службами и объем кода WSDL, который нужно изменить, а потом повторно развернуть модули, в которые были внесены изменения...
В сравнении с этим ад начинает казаться не таким плохим местом.
В программной системе, организованной в виде набора служб, нет ничего принципиально неправильного. Ошибка компании W заключалась в преждевременном решении внедрить комплекс инструментов для поддержки SOA — то есть массивного набора служб для работы с предметными объектами. За эту ошибку пришлось заплатить человеко-часами — большим количеством человеко-часов, — сброшенными с вершины SOA.
Я мог бы описывать архитектурные провалы один за другим. Но давайте лучше поговорим об успешных примерах.
FitNesse
Мой сын Майка и я начали работу над проектом FitNesse в 2001 году. Мы намеревались создать простую вики-страницу, обертывающую инструмент FIT Уорда Каннингема для разработки приемочных тестов.
Это было еще до того, как в Maven «решили» проблему jar-файла. Я был абсолютно уверен: все, что мы производим, не должно вынуждать людей загружать больше одного jar-файла. Я назвал это правило «Загрузи и вперед». Это правило управляло многими нашими решениями.
Одним из первых решений было создание собственного веб-сервера, отвечающего потребностям FitNesse. Это решение может показаться абсурдным. Даже в 2001 году существовало немало веб-серверов с открытым исходным кодом, которые мы могли бы использовать. Тем не менее решение написать свой сервер оправдало себя, потому что реализовать простой веб-сервер совсем несложно и это позволило нам отложить решение о выборе веб-фреймворка на более поздний срок.
Еще одно решение, принятое на ранней стадии, — не думать о базе данных. У нас была задумка использовать MySQL, но мы намеренно отложили это решение, использовав дизайн, сделавший это решение несущественным. Суть его заключалась в том, чтобы вставить интерфейс между всеми обращениями к данным и самим хранилищем.
Мы поместили методы доступа к данным в интерфейс с именем WikiPage. Эти методы обеспечивали все необходимое для поиска, извлечения и сохранения страниц. Конечно, мы не реализовали эти методы с самого начала, а просто добавили «заглушки», пока работали над функциями, не связанными с извлечением и сохранением данных.
В действительности в течение трех месяцев мы работали над переводом текста вики-страницы в HTML. Это не потребовало использования какого-либо хранилища данных, поэтому мы создали класс с именем MockWikiPage, содержащий простые заглушки методов доступа к данным.
В какой-то момент этих заглушек оказалось недостаточно для новых функций, которые мы должны были написать. Нам понадобился настоящий доступ к данным, без заглушек. Поэтому мы создали новый класс InMemoryPage, производный от WikiPage. Этот класс реализовал методы доступа к данным в хеш-таблице с вики-страницами, хранящейся в ОЗУ.
Это позволило нам целый год писать функцию за функцией. В результате мы получили первую версию программы FitNesse, действующую именно так. Мы могли создавать страницы, ссылаться на другие страницы, применять самое причудливое форматирование и даже выполнять тесты под управлением FIT. Мы не могли только сохранять результаты нашего труда.
Когда пришло время реализовать долговременное хранение, мы снова подумали о MySQL, но решили, что в краткосрочной перспективе это необязательно, потому что хеш-таблицы было очень легко записывать в простые файлы. Как результат, мы реализовали класс FileSystemWikiPage, который работал с простыми файлами, и продолжили работу над созданием новых возможностей.
Три месяца спустя мы пришли к заключению, что решение на основе простых файлов достаточно хорошее, и решили вообще отказаться от идеи использовать MySQL. Мы отложили это решение до неопределенного будущего и никогда не оглядывались назад.
На этом история закончилась бы, если бы не один из наших клиентов, решивший, что ему очень нужно сохранить свою вики-страницу в MySQL. Мы показали ему архитектуру WikiPages, позволившую нам отложить решение. Через день он вернулся с законченной системой, работавшей в MySQL. Он просто написал производный класс MySqlWikiPage и получил необходимое.
Мы включили этот вариант в FitNesse, но никто больше не использовал его, по крайней мере, поэтому мы отбросили его. Даже клиент, написавший производный класс, в конечном счете отказался от него.
Начиная работу над FitNesse, мы провели границу между бизнес-правилами и базами данных. Эта граница позволила реализовать бизнес-правила так, что они вообще никак не зависели от выбора базы данных, им требовались только методы доступа к данным. Это решение позволило нам больше года откладывать выбор и реализацию базы данных. Оно позволило опробовать вариант с файловой системой и изменить направление, когда мы увидели лучшее решение. Кроме того, оно не препятствовало и даже не мешало движению в первоначальном направлении (к MySQL), когда кто-то пожелал этого.
Факт отсутствия действующей базы данных в течение 18 месяцев разработки означал, что 18 месяцев мы не испытывали проблем со схемами, запросами, серверами баз данных, паролями, тайм-аутами и прочими неприятностями, которые непременно начинают проявляться, как только вы включаете в работу базу данных. Это также означало, что все наши тесты выполнялись очень быстро, потому что не было базы данных, тормозившей их.
Проще говоря, проведение границ помогло нам задержать и отложить принятие решений, и это сэкономило нам немало времени и нервов. Именно такой должна быть хорошая архитектура.
Какие границы проводить и когда?
Отделять линиями нужно все, что не имеет значения. Графический интерфейс не имеет значения для бизнес-правил, поэтому между ними нужно провести границу. База данных не имеет значения для графического интерфейса, поэтому между ними нужно провести границу. База данных не имеет значения для бизнес-правил, поэтому между ними нужно провести границу.
Возможно, кто-то из вас пожелал бы возразить против этих заявлений, особенно против заявления о независимости бизнес-правил от базы данных. Многие из нас привыкли считать, что база данных неразрывно связана с бизнес-правилами. Кое-кто может быть даже уверен, что база данных является воплощением бизнес-правил.
Но, как будет показано в другой главе, эта идея ошибочна. База данных — это инструмент, который бизнес-правила могут использовать опосредованно. Бизнес-правила не зависят от конкретной схемы, языка запросов и любых других деталей организации базы данных. Бизнес-правилам требуется только набор функций для извлечения и сохранения данных. Это позволяет нам скрыть базу данных за интерфейсом.
Это ясно видно на рис. 17.1. Класс BusinessRules использует интерфейс DatabaseInterface для загрузки и сохранения данных. Класс DatabaseAccess реализует интерфейс и выполняет операции в фактической базе данных Database.
Классы и интерфейсы на этой диаграмме носят символический характер. В настоящем приложении может иметься несколько классов бизнес-правил, несколько интерфейсов доступа данным и несколько классов, реализующих этот доступ. Но все они будут следовать примерно одному и тому же шаблону.
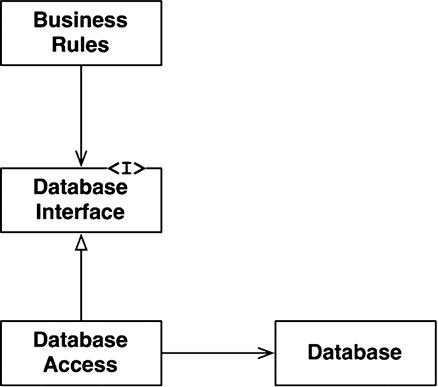
Рис. 17.1. База данных за интерфейсом
Где здесь граница? Граница пересекает отношение наследования чуть ниже DatabaseInterface (рис. 17.2).
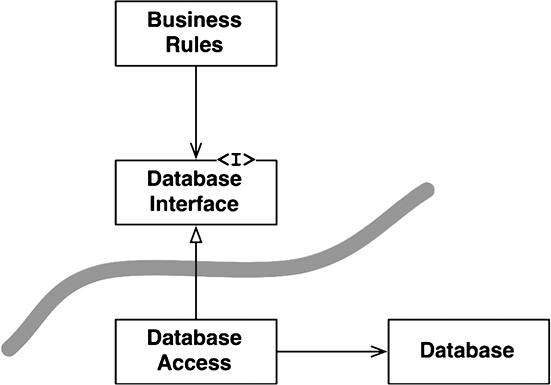
Рис. 17.2. Линия границы
Обратите внимание на стрелки, исходящие из класса DatabaseAccess. Они обе выходят из класса DatabaseAccess, а это значит, что никакой другой класс не знает о существовании DatabaseAccess.
Теперь отступим на шаг назад и рассмотрим компонент с несколькими бизнес-правилами и компонент с базой данных и всеми необходимыми классами доступа (рис. 17.3).
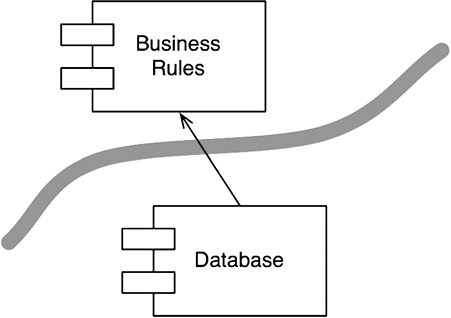
Рис. 17.3. Компоненты с бизнес-правилами и базой данных
Обратите внимание на направление стрелки. Компонент Database знает о существовании компонента BusinessRules. Компонент BusinessRules не знает о существовании компонента Database. Это говорит о том, что интерфейсы DatabaseInterface находятся в компоненте BusinessRules, а классы DatabaseAccess — в компоненте Database.
Направление этой стрелки важно. Оно показывает, что компонент Database не имеет значения для BusinessRules, но Database не может существовать без BusinessRules.
Если вам это кажется странным, просто вспомните, что компонент Database содержит код, транслирующий вызовы, выполняемые компонентом BusinessRules, на язык запросов базы данных. Именно этот транслирующий код знает о существовании BusinessRules.
Проведя границу между двумя компонентами и направив стрелку в сторону BusinessRules, мы видим, что компонент BusinessRules мог бы использовать базу данных любого типа. Компонент Database можно заменить самыми разными реализациями — для BusinessRules это совершенно неважно.
Хранение данных можно организовать в базе данных Oracle, MySQL, Couch, Datomic или даже в простых файлах. Для бизнес-правил это совершенно неважно. А это означает, что выбор базы данных можно отложить и сосредоточиться на реализации и тестировании бизнес-правил.
О вводе и выводе
Разработчики и клиенты часто неправильно понимают, что такое система. Они видят графический интерфейс и думают, что он и есть система. Они определяют систему в терминах графического интерфейса и считают, что должны сразу начать работу с графическим интерфейсом. Они не понимают важнейшего принципа: ввод/вывод не важен.
В первый момент это может быть трудно понять. Мы часто рассуждаем о поведении системы в терминах ввода/вывода. Возьмем, например, видеоигру. В вашем представлении наверняка доминирует интерфейс: экран, мышь, управляющие клавиши и звуки. Вы забываете, что за этим интерфейсом находится модель — сложный комплекс структур данных и функций, — управляющая им. Что еще важнее, эта модель не нуждается в интерфейсе. Она благополучно будет решать свои задачи, моделируя все игровые события даже без отображения игры на экране. Интерфейс не важен для модели — для бизнес-правил.
И снова мы видим, что компоненты GUI и BusinessRules разделены границей (рис. 17.4). И снова мы видим, что менее важный компонент зависит от более важного компонента. Стрелки показывают, какой компонент знает о существовании другого и, соответственно, какой компонент зависит от другого. Компонент GUI зависит от BusinessRules.
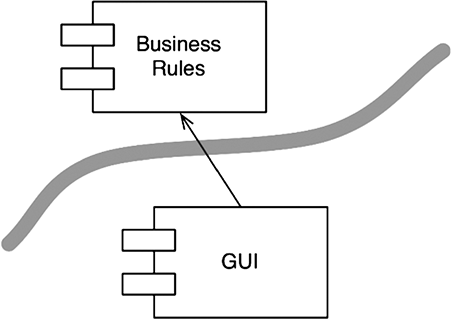
Рис. 17.4. Граница между компонентами GUI и BusinessRules
Проведя границу и нарисовав стрелку, мы теперь видим, что GUI можно заменить интерфейсом какого-то другого вида — для BusinessRules это не важно.
Архитектура с плагинами
Вместе эти два решения о базе данных и графическом интерфейсе образуют шаблон для добавления других компонентов. Это тот же шаблон, что используется в системах, допускающих подключение сторонних сменных модулей — плагинов.
Фактически история технологий разработки программного обеспечения — это история создания плагинов для получения масштабируемой и управляемой архитектуры. Основные бизнес-правила хранятся отдельно и не зависят от компонентов, которые являются необязательными или могут быть реализованы в множестве разных форм (рис. 17.5).
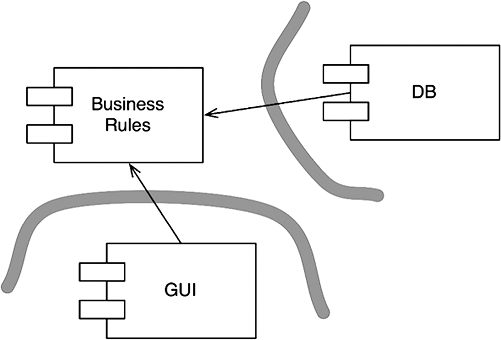
Рис. 17.5. Подключение модулей к бизнес-правилам
Так как в таком дизайне пользовательский интерфейс считается плагином, мы можем позволить подключать множество разных пользовательских интерфейсов. Это могут быть веб-интерфейсы, интерфейсы клиент/сервер, интерфейсы служб, консольные интерфейсы или основанные на других способах взаимодействия с пользователем.
То же верно в отношении базы данных. Решив считать ее плагином, мы можем заменить ее любой базой данных SQL или NOSQL, простыми файлами или любыми другими технологиями хранения данных, которые мы сочтем необходимыми в будущем.
Такие замены осуществляются не всегда просто. Если первоначально система опиралась на веб-интерфейс, создание плагина для интерфейса клиент/сервер может оказаться сложной задачей. Вполне вероятно, что придется переделать какие-то взаимодействия между бизнес-правилами и новым пользовательским интерфейсом. И все же, допустив существование архитектуры со сменными модулями (плагинами), мы сделали подобную замену практически возможной.
Аргумент в пользу плагинов
Рассмотрим отношения между ReSharper и Visual Studio. Эти компоненты производятся совершенно разными коллективами разработчиков в совершенно разных компаниях. И действительно, компания JetBrains, создатель ReSharper, находится в России. Компания Microsoft, конечно, находится в Редмонде, штат Вашингтон, США. Трудно представить себе более разные команды разработчиков.
Какая команда может помешать другой? Какая команда защищена от влияния другой? Структура зависимости четко отвечает на оба вопроса (рис. 17.6). Исходный код ReSharper зависит от исходного кода Visual Studio. То есть команда ReSharper никак не сможет помешать команде Visual Studio. Но команда Visual Studio может полностью заблокировать команду ReSharper, если пожелает.
Это крайне асимметричное отношение, и именно его желательно воспроизводить в своих системах. Некоторые модули должны иметь абсолютную
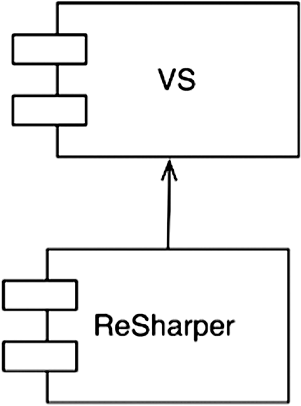
Рис. 17.6. ReSharper зависит от Visual Studio
защиту от влияния других. Например, работа бизнес-правил не должна нарушаться из-за изменения формата веб-страницы или схемы базы данных. Изменения в одной части системы не должны нарушать работу не связанных с ней других частей системы. Наши системы не должны быть настолько хрупкими.
Архитектура плагинов в наших системах создает защитные барьеры, препятствующие распространению изменений. Если графический интерфейс подключается к бизнес-правилам, изменения в графическом интерфейсе не смогут повлиять на бизнес-правила.
Границы проводятся там, где есть ось изменения. Компоненты по разным сторонам границы изменяются с разными скоростями и по разным причинам.
Графические интерфейсы изменяются в иное время и с иной скоростью, чем бизнес-правила, поэтому их должна разделять граница. Бизнес-правила изменяются в иное время и по иным причинам, чем фреймворки внедрения зависимостей, поэтому их должна разделять граница.
Это снова простой принцип единственной ответственности, подсказывающий, где провести границы.
Заключение
Прежде чем провести линии границ в архитектуре программного обеспечения, систему нужно разделить на компоненты. Некоторые из этих компонентов реализуют основные бизнес-правила; другие являются плагинами, содержащими функции, которые не имеют прямой связи с бизнес-правилами. Затем можно организовать код в компонентах так, чтобы стрелки между ними указывали в одном направлении — в сторону бизнес-правил.
В этом без труда можно заметить принципы инверсии зависимостей (Dependency Inversion Principle) и устойчивости абстракций (Stable Abstractions Principle). Стрелки зависимостей направлены от низкоуровневых деталей в сторону высокоуровневых абстракций.
Слово «архитектура» взято в кавычки, потому что трехуровневая архитектура в действительности не является архитектурой — это топология. Вот вам яркий пример решения, принятие которого хорошая архитектура стремится отложить.
Много лет спустя мы смогли перенести фреймворк Velocity на FitNesse.

