10. Принцип разделения интерфейсов

Происхождение названия принципа разделения интерфейсов (Interface Segregation Principle; ISP) наглядно иллюстрирует схема на рис. 10.1.
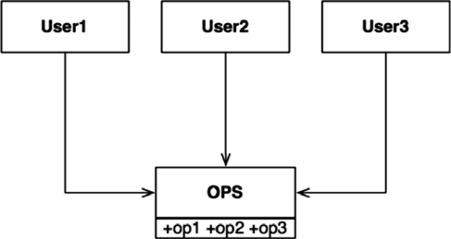
Рис. 10.1. Принцип разделения интерфейсов
В данной ситуации имеется несколько классов, пользующихся операциями в классе OPS. Допустим, что User1 использует только операцию op1, User2 — только op2 и User3 — только op3.
Теперь представьте, что OPS — это класс, написанный на таком языке, как Java. Очевидно, что в такой ситуации исходный код User1 непреднамеренно будет зависеть от op2 и op3, даже при том, что он не пользуется ими. Эта зависимость означает, что изменения в исходном коде метода op2 в классе OPS потребуют повторной компиляции и развертывания класса User1, несмотря на то что для него ничего не изменилось.
Эту проблему можно решить разделением операций по интерфейсам, как показано на рис. 10.2.
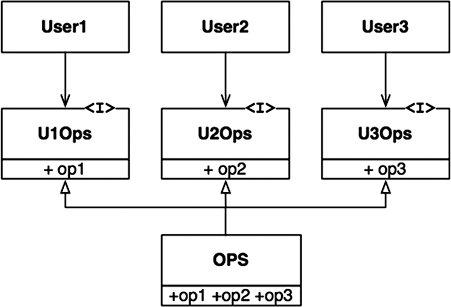
Рис. 10.2. Разделение операций
Если снова представить, что этот интерфейс реализован на языке со строгим контролем типов, таком как Java, исходный код User1 будет зависеть от U1Ops и op1, но не от OPS. То есть изменения в OPS, которые не касаются User1, не потребуют повторной компиляции и развертывания User1.
Принцип разделения интерфейсов и язык
Очевидно, что описание выше в значительной степени зависит от типа языка. Языки со статическими типами, такие как Java, вынуждают программистов создавать объявления, которые должны импортироваться или подключаться к исходному коду пользователя как-то иначе. Именно эти инструкции подключения в исходном коде пользователя создают зависимости и вынуждают выполнять повторную компиляцию и развертывание.
В языках с динамической типизацией, таких как Ruby или Python, подобные объявления отсутствуют в исходном коде — они определяются автоматически во время выполнения. То есть в исходном коде отсутствуют зависимости, вынуждающие выполнять повторную компиляцию и развертывание. Это главная причина, почему системы на языках с динамической типизацией получаются более гибкими и с меньшим количеством строгих связей.
Этот факт ведет нас к заключению, что принцип разделения интерфейсов является проблемой языка, а не архитектуры.
Принцип разделения интерфейсов и архитектура
Если отступить на шаг назад и взглянуть на коренные мотивы, стоящие за принципом разделения интерфейсов, можно заметить более глубинные проблемы. В общем случае опасно создавать зависимости от модулей, содержащих больше, чем требуется. Это справедливо не только в отношении зависимостей в исходном коде, которые могут вынуждать выполнять без необходимости повторную компиляцию и развертывание, но также на более высоком уровне — на уровне архитектуры.
Рассмотрим, например, действия архитектора, работающего над системой S. Он пожелал включить в систему некоторый фреймворк F. Теперь представьте, что авторы F связали его с поддержкой конкретной базы данных D. То есть S зависит от F, который зависит от D (рис. 10.3).

Рис. 10.3. Проблемная архитектура
Теперь представьте, что D включает функции, которые не используются фреймворком F и, соответственно, не используются системой S. Изменения в этих функциях внутри D могут вынудить повторно развернуть F и, соответственно, повторно развернуть S. Хуже того, ошибка в одной из таких функций внутри D может спровоцировать появление ошибок в F и S.
Заключение
Из вышесказанного следует вывод: зависимости, несущие лишний груз ненужных и неиспользуемых особенностей, могут стать причиной неожиданных проблем.
Мы развернем эту мысль подробнее при обсуждении принципа совместного использования (Common Reuse Principle; CRP) в главе 13 «Связность компонентов».

