Книга: Вычислительное мышление: Метод решения сложных задач
Назад: Простая магия
Дальше: Глава 11 Медицинские чудеса на просвет
Увидеть мир таким, какой он есть
Чтобы компьютер видел, важно найти границы
Давайте теперь перейдем к более сложному явлению — возможности компьютера увидеть мир. Для этого мало подсоединить к нему камеру. Компьютер должен уметь определять, что присутствует на картинке, — находить шаблоны и понимать, каким предметам они соответствуют, то есть знать, чтó он видит. Только в этом случае мы и правда сможем утверждать, что он «видит».
Наш мозг постоянно находит шаблоны в изображениях и сопоставляет их с образцами. Свет, поступающий в глаз, преобразуется в сетчатке, которая находится в задней части глазного яблока, в сигналы, идущие в мозг. Эта информация обрабатывается с целью нахождения интересных шаблонов, форм и в конечном итоге предметов. Мы продолжаем узнавать новое о зрении человека, но возможность снабдить компьютер или робота способностью видеть — важная и трудная техническая задача. Она подразумевает разработку алгоритмов, которые обучат компьютеры замечать образцы в увиденном. Одна из фундаментальных способностей человеческого мозга, позволяющая распознавать предметы, — умение находить их границы. Мозг видит линии. Как стало понятно в случае с векторными изображениями, линии — это первый шаг к формам, а затем — к предметам. Так как же «увидеть» линии?
Во-первых, давайте рассмотрим очень-очень скучную картинку (рис. 64a). Как и все компьютерные изображения, она представлена в цифровом виде и состоит из пикселов. Обычно изображение состоит из многих тысяч пикселов. Конечно же, реальный мир из них не состоит! Это просто представление изображения. У каждого пиксела есть присвоенные ему место, особый цвет и яркость. В нашей скучной картинке всего 32 пиксела и два оттенка серого — посветлее и потемнее. Но при взгляде на нее становится ясно, что здесь есть кое-что интересное — вертикальная граница там, где светло-серый с одной стороны сменяется темно-серым с другой. Сама по себе эта граница не является линией пикселов, это всего лишь разница между ними. Мы видим ее только потому, что наш мозг совершает много операций по обработке изображения.
Чтобы написать алгоритм, который позволит компьютеру определить края, необходимо хорошее представление. Изображение легко представить в виде набора чисел, используя разные значения для светло-серого и темно-серого. Благодаря этому мы используем математику в алгоритмах обработки. Условимся, что светло-серый — это число 3, а темно-серый — 4. Например, эти числа могли бы показывать количество чернил, необходимое для печати пиксела. Изображение только из чисел показано на рис. 64b.

Граница никуда не делась, но нам, людям, теперь гораздо сложнее ее увидеть. Она существует только в виде численной закономерности, а мы от природы не обладаем способностью обрабатывать такие закономерности так же хорошо, как изображения. Но, как мы увидим далее, представление облегчит этот процесс для машины.

Теперь давайте посмотрим на еще более мелкий и скучный образец, представленный на рис. 65. Он состоит всего лишь из трех пикселов, однако, надо признать, в нем есть отрицательное число, что делает его немного более интересным. Но как это поможет компьютеру видеть нечто простое? В информатике такой шаблон называется цифровым фильтром. Как и любой фильтр, например в кофеварке, он пропускает лишь нечто определенное. В данном случае — определенные наборы чисел вместо кофе.
Чтобы цифровой фильтр заработал, его накладывают на исходный набор чисел, и элемент за элементом по шаблону умножается на коэффициент. Результаты по всем элементам суммируются, и на выходе получается окончательное значение.
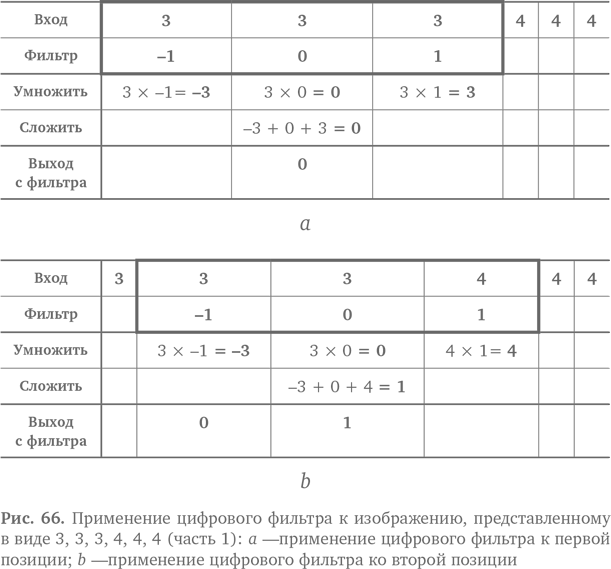
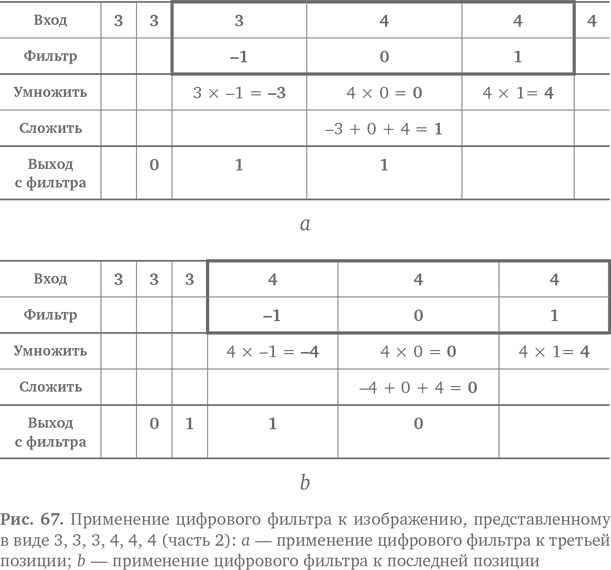
Рассмотрим пример. Допустим, входной набор чисел, представляющий изображение, — 3, 3, 3, 4, 4, 4. Мы применяем к нему фильтр. Как это будет выглядеть для первых трех чисел, показано на рис. 66а. Мы умножаем фильтр на соответствующие числа, получаем −3, 0 и 3, потом складываем их и получаем 0. Это новое значение на выходе фильтра. Теперь фильтр перемещается, словно на конвейере, на один элемент. Он накладывается на новые входные цифры и дает следующий результат на выходе, как показано на рис. 66b. Пожалуйста, двигайтесь дальше! Фильтр сдвигается еще на один шаг, нависает над новыми числами и дает следующий результат. Получается как на рис. 67a. Наконец, передвинувшись еще на один шаг вправо, наш трудолюбивый фильтр доходит до конца, и на выходе появляется последний результат, как на рис. 67b.
Что вообще такое структура изображения?
И где мы оказались после всех этих математических операций? Давайте посмотрим, что у нас есть, не обращая внимания на процесс обработки (рис. 68).
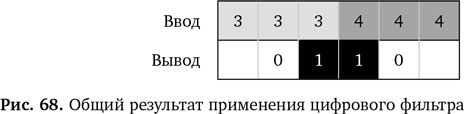
После фильтра на выходе числа оказались больше только там, где была замена значений на входе. Конечно, результат на выходе немного меньше, чем изображение на входе, ведь два значения оказываются пустыми. Однако он гораздо полезнее. Вместо того чтобы считать эти значения на входе в виде цифр, представьте их в виде пикселов. Это картинка.
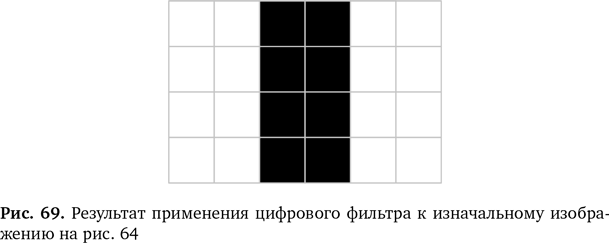
Теперь подумайте, что происходит, когда вы прогоняете через этот фильтр первую строчку нашего скучного изображения на рис. 64, затем продвигаетесь ниже и проходите следующую, а затем и еще одну строку, пока не отфильтруете все изображение на входе. У вас получится новое изображение немного меньшего размера, как на рис. 69, где мы приняли 0 для белого и 1 для черного. У него есть особое свойства. Все области, где были вертикальные границы, оказались выделенными — они стали линиями. Немного математики, и из исходного изображения возник новый шаблон. Границы превратились в линии, и теперь компьютер их видит.
Программисты изобрели много разных фильтров, каждый из которых может обнаружить в изображениях разные элементы. За этим стоит тот же математический процесс, который мы только что рассмотрели. Правда, сами фильтры становятся все сложнее. Каждый из них — это шаблон. Использование шаблонов в фильтрах является основополагающим элементом компьютерного «зрения» при поиске закономерностей в изображениях. Кроме того, таким образом мы имитируем все, что знаем о человеческом зрении: похоже, что у клеток человеческого мозга есть определенные закономерности восприятия изменений интенсивности света, а это и есть линии.
В наш век перемен все меняется
Важные закономерности проявляются и во времени. Для этого мы создаем ПО, которое наблюдает за людьми, отслеживая выражение лица, и за предметами, которые двигаются и меняются. Для компьютера видео не более чем большой набор чисел. Оно состоит из последовательности картинок, снятых в течение определенного времени, а, как мы уже говорили, каждое изображение — это и есть набор чисел. Чтобы найти в видео интересные вещи, нужно эти числа фильтровать. Можно создать фильтры, которые работают не только во времени, но и в пространстве. Это так называемые временные фильтры — они ищут сходство или различие в значениях пикселов в конкретных участках видеоизображений по ходу фильма. Возьмем фильтр из нашего примера [−1, 0, +1]. Он представляет собой маленькую компактную абстракцию того, что мы хотим найти. У него те же характеристики, что и у границы, — он начинается с меньшего значения и заканчивается наибольшим.
Когда нам нужно проследить за более сложными моделями во времени, мы порой слабо представляем, что это за модели, поэтому трудно создать исходный фильтр. Чтобы решить эту проблему, обычно используют алгоритмы, способные изучить необходимые нам модели. Это подразумевает создание фильтров на основе сотен образцов. Такие фильтры бывают очень сложными. Например, можно взять сотни видео с обычным поведением людей, входящих в поезд метро и выходящих из него, и извлечь из них наиболее вероятные модели. Если прогнать через эти усвоенные фильтры настоящую сцену, происходящую на платформе, они выделят подозрительное поведение. Это могут быть модели движения, которые мы не ожидаем здесь увидеть, — например, кто-то слишком долго ждет у края платформы или на ней стоит сумка, которую никто не забирает. То есть мы увидим исключения из изученных моделей.
Временные модели важны и в музыке. В конечном итоге это, в сущности, и есть музыка — ноты меняются во времени на основе интересных моделей, что доставляет нам удовольствие. Чтобы устранить несовершенства из музыкальной записи, можно использовать фильтры. Например, скандально известное программное обеспечение для «автотюна», которое «исправляет» дребезжащие голоса поп-звезд, и после обработки они звучат безупречно. Программа изучает образец звука, полученный от певца, и образец необходимого звука и меняет вокальный сигнал, приводя его в соответствие с моделью. Программы, распознающие музыку, используют аудиоотпечатки. Это всего лишь образцы звуковых элементов — частота, темп и так далее, — извлеченные из музыкального произведения. Они дают уникальный набор значений — музыкальный отпечаток, который сопоставляют со значениями в объемной базе данных из уже помеченных произведений и таким образом узнают произведение.
В медицине и генетике тоже изучают образцы. Например, чтобы предсказать, какие болезни вероятны для человека, исходя из особенностей его генотипа, или понять, как генетические особенности повлияют на взаимодействие организма с конкретными лекарствами, и адаптировать методы лечения к индивидуальным потребностям. Такое применение информатики и выявление шаблонов открывают перспективы для появления в медицине новых способов, с помощью которых можно находить новые лекарства и новые методы лечения. Например, со временем при поступлении в больницу будут сразу же проводить анализ вашей ДНК, и к тому времени, как вы окажетесь в палате, для вас уже подготовят индивидуальные лекарства, которые гарантированно произведут минимальный побочный эффект лично на вас. Сейчас это уже реальная возможность. Все сводится к тому, чтобы научить компьютеры вычислительному мышлению.
Шаблоны, предсказания, пациенты и тюрьмы
Все перечисленные варианты могут быть очень полезны, но, как мы убедились, программисты должны осознавать, что их алгоритмы и математические ухищрения могут наделить машины способностями, которые можно использовать во вред. Этика, учение о хорошем и плохом, верном и неверном, давно занимает важное место в человеческой философии и истории права. Будет ли создан фильтр, который сумеет по шаблонам, выявленным в информации о человеке, определить, что он собирается совершить преступление? Если да, будет ли правильно арестовать этого человека до совершения преступления? Должны ли присяжные в судах иметь представление о сильных и слабых сторонах математических и вычислительных методов, которые в наши дни все чаще применяют, чтобы выявить предположительно преступное поведение? И если при анализе ваших генов выясняется, что вы, вероятно, заболеете конкретным видом рака, что делать в этом случае? И должны ли страховые компании знать о подобном и требовать больше денег за страховку? Или представьте, что в детстве проанализировали ваши гены и определили, что вы вырастете опасным преступником, — как поступить в этом случае? Все это важные вопросы, на которые сложно дать ответ, но ученые должны играть свою роль в обществе и показывать другим, чем они заняты и как это происходит, — в противном случае сторонние наблюдатели будут воспринимать науку как магию. И хотя волшебные фокусы — отличный способ повеселиться и развлечь других, они точно не подходят для того, чтобы определять развитие нашего общества.
Назад: Простая магия
Дальше: Глава 11 Медицинские чудеса на просвет

