ГЛАВА 2
Качество данных
80% времени я трачу на очистку данных. Качественные данные всегда выигрывают у качественных моделей.
Данные — это фундамент, на котором держится компания с управлением на основе данных.
Если люди, принимающие решения, не располагают своевременной, релевантной и достоверной информацией, у них не остается другого выхода, как только положиться на собственную интуицию. Качество данных — ключевой аспект.

В этой главе понятие «качество» употребляется в самом широком смысле и рассматривается преимущественно с точки зрения аналитической работы.
Специалистам-аналитикам нужны правильные данные, собранные правильным образом и в правильной форме, в правильном месте, в правильное время. (Они просят совсем не много.) Если какое-то из этих требований не выполнено или выполнено недостаточно хорошо, у аналитиков сужается круг вопросов, на которые они способны дать ответ, а также снижается качество выводов, которые они могут сделать на основании данных.
Эта и следующая главы посвящены обширной теме качества данных. Во-первых, мы обсудим, как обеспечить правильность процесса сбора данных. С этой точки зрения качество данных выражается в их точности, своевременности, взаимосвязанности и так далее. Затем, в следующей главе, мы поговорим о том, как убедиться, что мы собираем правильные данные. С этой точки зрения качество выражается в выборе оптимальных источников данных, чтобы обеспечить максимально эффективные выводы. Иными словами, мы начнем с того, как правильно собирать данные, и перейдем к тому, как собирать правильные данные.
В этой главе мы сосредоточимся на способах определения достоверности данных и рассмотрим случаи, когда данные могут оказаться ненадежными. Для начала разберем критерии качества — все характеристики чистых данных. Затем рассмотрим самые разные факторы, влияющие на ухудшение качества. Этой теме мы уделим особое внимание по ряду причин. Во-первых, подобных факторов может быть великое множество, и они носят практический, а не теоретический характер. Если вам доводилось работать с данными, то, скорее всего, вы сталкивались с большинством из них. Они неотъемлемая часть нашей реальности и возникают гораздо чаще, чем нам бы того хотелось. Именно поэтому у большинства специалистов по работе с данными подавляющая часть рабочего времени уходит на очистку. Более того, вероятность возникновения этих факторов повышается с увеличением объема данных. Мой бывший коллега Самер Масри однажды заметил: «При работе с большими масштабами данных всегда помните, что вещи, которые случаются “один раз на миллион”, могут произойти в каждую секунду!» Во-вторых (и, возможно, это даже важнее), активная проверка и сохранение качества данных — совместная обязанность всех сотрудников. Каждый участник аналитической цепочки ценности должен следить за качеством данных. Таким образом, каждому участнику будет полезно на более глубоком уровне разбираться в этом вопросе.
Итак, учитывая все сказанное, давайте рассмотрим, что означает качество данных.
Аспекты качества данных
Качество данных невозможно свести к одной цифре. Качество — это не 5 или 32. Причина в том, что это понятие охватывает целый ряд аспектов, или направлений. Соответственно, начинают выделять уровни качества, при которых одни аспекты оказываются более серьезными, чем другие. Важность этих аспектов зависит от контекста анализа, который должен быть выполнен с этими данными. Например, если в базе данных с адресами клиентов везде указаны коды штатов, но иногда пропущены почтовые индексы, то отсутствие данных по почтовым индексам может стать серьезной проблемой, если вы планировали построить анализ на основе показателя почтового индекса, но никак не повлияет на анализ, если вы решили проводить его на уровне показателя по штатам.
Итак, качество данных определяется несколькими аспектами. Данные должны отвечать ряду требований.
Доступность
У аналитика должен быть доступ к данным. Это предполагает не только разрешение на их получение, но также наличие соответствующих инструментов, обеспечивающих возможность их использовать и анализировать. Например, в файле дампа памяти SQL (Structured Query Language — языка структурированных запросов при работе с базой данных) содержится информация, которая может потребоваться аналитику, но не в той форме, в которой он сможет ее использовать. Для работы с этими данными они должны быть представлены в работающей базе данных или в инструментах бизнес-аналитики (подключенных к этой базе данных).
Точность
Данные должны отражать истинные значения или положение дел. Например, показания неправильно настроенного термометра, ошибка в дате рождения или устаревший адрес — это все примеры неточных данных.
Взаимосвязанность
Должна быть возможность точно связать одни данные с другими. Например, заказ клиента должен быть связан с информацией о нем самом, с товаром или товарами из заказа, с платежной информацией и информацией об адресе доставки. Этот набор данных обеспечивает полную картину заказа клиента. Взаимосвязь обеспечивается набором идентификационных кодов или ключей, связывающих воедино информацию из разных частей базы данных.
Полнота
Под неполными данными может подразумеваться как отсутствие части информации (например, в сведениях о клиенте не указано его имя), так и полное отсутствие единицы информации (например, в результате ошибки при сохранении в базу данных потерялась вся информация о клиенте).
Непротиворечивость
Данные должны быть согласованными. Например, адрес конкретного клиента в одной базе данных должен совпадать с адресом этого же клиента в другой базе. При наличии разногласий один из источников следует считать основным или вообще не использовать сомнительные данные до устранения причины разногласий.
Однозначность
Каждое поле, содержащее индивидуальные данные, имеет определенное, недвусмысленное значение. Четко названные поля в совокупности со словарем базы данных (подробнее об этом чуть позже) помогают обеспечить качество данных.
Релевантность
Данные зависят от характера анализа. Например, исторический экскурс по биржевым ценам Американской ассоциации землевладельцев может быть интересным, но при этом не иметь никакого отношения к анализу фьючерсных контрактов на грудинную свинину.
Надежность
Данные должны быть одновременно полными (то есть содержать все сведения, которые вы ожидали получить) и точными (то есть отражать достоверную информацию).
Своевременность
Между сбором данных и их доступностью для использования в аналитической работе всегда проходит время. На практике это означает, что аналитики получают данные как раз вовремя, чтобы завершить анализ к необходимому сроку. Недавно мне довелось узнать об одной крупной корпорации, у которой время ожидания при работе с хранилищем данных составляет до одного месяца. При такой задержке данные становятся практически бесполезными (при сохранении издержек на их хранение и обработку), их можно использовать только в целях долгосрочного стратегического планирования и прогнозирования.
Ошибка всего в одном из этих аспектов может привести к тому, что данные окажутся частично или полностью непригодными к использованию или, хуже того, будут казаться достоверными, но приведут к неправильным выводам.
Далее мы остановимся на процессах и проблемах, способных ухудшить качество данных, на некоторых подходах для определения и решения этих вопросов, а также поговорим о том, кто отвечает за качество данных.
ДАННЫЕ С ОШИБКАМИ
Ошибки могут появиться в данных по многим причинам и на любом этапе сбора информации. Давайте проследим весь жизненный цикл данных с момента их генерации и до момента анализа и посмотрим, как на каждом из этапов в данные могут закрадываться ошибки.
В данных всегда больше ошибок, чем кажется. По результатам одного из исследований, ежегодно американские компании терпят ущерб почти в 600 млн долл. из-за ошибочных данных или данных плохого качества (это 3,5% ВВП!).
Во многих случаях аналитики лишены возможности контролировать сбор и первичную обработку данных. Обычно они бывают одним из последних звеньев в длинной цепочке по генерации данных, их фиксированию, передаче, обработке и объединению. Тем не менее важно понимать, какие проблемы с качеством данных могут возникнуть и как их потенциально можно разрешить.
Цель этой части книги — выделить общие проблемы с качеством данных и возможные подводные камни, показать, как избежать этих проблем и как понять, что эти проблемы присутствуют в наборе данных. Более того, чуть позже вы поймете, что это призыв ко всем специалистам, работающим с данными, по возможности активно участвовать в проверке качества данных.
Итак, начнем с самого начала — с источника данных. Почему в данные могут закрасться ошибки и как с этим бороться?
ГЕНЕРАЦИЯ ДАННЫХ
Генерация данных — самый очевидный источник возможных ошибок, которые могут появиться в результате технологического (приборы), программного (сбои) или человеческого факторов.
В случае технологического фактора приборы могут быть настроены неправильно, что может сказаться на полученных данных. Например, термометр показывает 35 °С вместо 33 °С на самом деле. Это легко исправить: прибор или датчик можно настроить по другому, «эталонному», прибору, отражающему достоверные данные.
Иногда приборы бывают ненадежными. Мне довелось работать в грантовом проекте Агентства передовых оборонных исследовательских проектов Министерства обороны США (DARPA), посвященном групповой робототехнике. В нашем распоряжении была группа простейших роботов, задача которых заключалась в совместном картографировании местности. Сложность состояла в том, что инфракрасные датчики, установленные на роботах, были очень плохого качества. Вместо того чтобы сосредоточиться на разработке децентрализованного алгоритма для нанесения здания на карту, большую часть времени я потратил на работу с алгоритмическими фильтрами, пытаясь справиться с качеством информации от этих датчиков, измерявших расстояние до ближайшей стены или до других роботов. Значения сбрасывались, или показатель расстояния до ближайшей стены мог неожиданно измениться на целый метр (неточность > 50%), притом что робот оставался неподвижным. Информации от этих датчиков просто нельзя было верить.
Когда в сборе данных принимают участие люди, ошибки в данных могут появиться по самым разным причинам. Сотрудники могут не знать, как правильно пользоваться оборудованием, они могут торопиться или быть невнимательными, они могут неправильно понять инструкции или не следовать им. Например, в двух больницах могут по-разному измерять вес пациентов: в обуви и без обуви. Для исправления ошибок такого рода требуются четкие инструкции и обучение персонала. Как с любым экспериментом, необходимо попытаться контролировать и стандартизировать как можно больше этапов процесса, чтобы данные оставались максимально достоверными, сравнимыми и удобными в использовании.
ВВОД ДАННЫХ
Когда данные генерируются вручную, например при измерении веса пациентов, их необходимо зафиксировать. Несмотря на обещания электронного офиса, большой объем данных сегодня по-прежнему сначала попадает на бумагу в качестве промежуточного шага до попадания в компьютер. На этом этапе может возникнуть множество ошибок.
Ошибки случаются при расшифровке документов, заполненных от руки. (Если бы вы видели мой почерк, у вас бы не осталось в этом сомнений.) Больше всего исследований в этой области проведено в сфере здравоохранения, частично потому что последствия использования неточной информации могут быть слишком серьезными, как с точки зрения здоровья пациентов, так и с точки зрения стоимости проведения ненужных медицинских тестов. Согласно результатам одного из исследований, 46% медицинских ошибок (при базовом уровне 11% от всех записей) обусловлено неточностью при расшифровке. Уровень ошибок в базах данных некоторых клинических исследований достигал 27%. Подобные ошибки могли быть результатом того, что медицинский персонал неправильно читал или понимал написанное от руки, не слышал или не понимал информацию из-за плохого качества аудиоисточника или непривычных слов или неправильно вносил информацию в компьютер.
Например, я работал в одной из компаний в сфере здравоохранения, и основными базами данных, которые компания использовала чаще всего, были данные статистических опросов населения в рамках Национальной программы проверки здоровья и питания (NHANES). Мобильные клиники по всей стране проводили опросы населения: измеряли вес и артериальное давление, выясняли, есть ли в семье больные диабетом или раком, и так далее. Когда мы изучили информацию о человеческом росте в одной из баз данных по этому проекту, то обнаружили целый ряд людей с показателем роста пять дюймов (примерно 12,5 см)! Эти данные вносили в базу специально обученные сотрудники, которые изо дня в день проводили опросы населения. Поскольку измерение роста — относительно простая процедура, наиболее вероятной причиной ошибки кажется некорректный ввод информации. Возможно, рост респондентов на самом деле был пять футов и пять дюймов (примерно 162 см) или шесть футов и пять дюймов (примерно 192 см). К сожалению, поскольку мы не знали этого наверняка, нам пришлось отметить эти значения как неизвестные.
К счастью, показатель роста человека пять дюймов — это настолько очевидная ошибка, что нам удалось определить ее с помощью простой гистограммы, и мы точно понимали, что это ошибка. Однако так бывает не всегда. Есть разные степени очевидности ошибки. Предположим, что при расшифровке записей, сделанных от руки, сотрудник вместо «аллергия на кошек и собак» написал: «аллергия на окшек и собак». Слова «окшек» не существует. Очевидно, что это опечатка, а смысл легко поддается восстановлению по контексту. Более сложными могут оказаться случаи, когда при перестановке букв могут образоваться другие слова, имеющие смысл. Тогда заметить ошибку сложнее. Разобраться со смыслом можно с помощью контекста, но он не всегда служит гарантией. Наконец, представьте, что местами случайно переставили не буквы, а цифры, например в числе 56,789 поменяли две последние цифры: 56,798. Заметить ошибку в этом случае будет чрезвычайно сложно или даже невозможно.
В целом ошибки при вводе информации можно свести к четырем типам.
Запись
Введенные слова или показатели не те, что были в оригинале.
Вставка
Появление дополнительного символа: 56,789 → 564,789.
Удаление
Один или несколько символов теряются: 56,789 → 56,89.
Перемена мест
Два или более символов меняются местами: 56,789 → 56,798.
В качестве отдельных категорий «Вставки» и «Удаления» можно выделить диттографию — случайное повторение символа (56,789 → 56,7789) и гаплографию — пропуск повторяющегося символа (56,779 → 56,79). Эти термины употребляют ученые, занимающиеся восстановлением поврежденных и переписанных от руки древних текстов, и обозначают разновидность проблемы с некачественными данными.
Особенно часто опечатки встречаются в написании дат. Например, я британец, и в английской культуре принят определенный формат написания даты: день/месяц/год. Однако я живу в США, где формат написания даты отличается: месяц/день/год. Первые несколько лет жизни в США я постоянно путался, и могу предположить, что эта проблема знакома не только мне. Представьте себе сайт, на котором пользователи со всего мира вводят в специальное поле дату. У пользователей из разных стран могут быть разные ожидания относительно формата ввода этой информации, и без необходимых подсказок могут возникнуть ошибки при вводе данных. Некоторые их них легко заметить: например, 25 марта (3/25 в американском варианте) — 25 явно не может быть обозначением месяца. А как насчет 4/5? Вы уверены, что для всех пользователей эта дата обозначает 5 апреля?
Как бороться с такого рода ошибками?
Снижение количества ошибок при вводе данных
Первый шаг, если он возможен, заключается в сокращении количества этапов от генерации данных до ввода. Скажу очевидное: если есть возможность избежать бумажной формы, лучше сразу вносить данные в компьютер.
Везде, где возможно, добавьте проверку значения каждого поля в свою электронную форму (рис. 2.1). То есть если данные четко структурированы и имеют установленный формат (например, почтовый индекс в США содержит от пяти до девяти цифр, а номер социальной страховки состоит из девяти цифр), проверяйте данные на соответствие этому формату, в противном случае предложите пользователю исправить возможные ошибки. Процесс проверки не ограничен только числовыми значениями. Например, можно проверять, чтобы дата или время вылета «обратно» были позже, чем вылета «туда». Иными словами, проверяйте все что можно, чтобы максимально избежать «мусора» в самом начале.
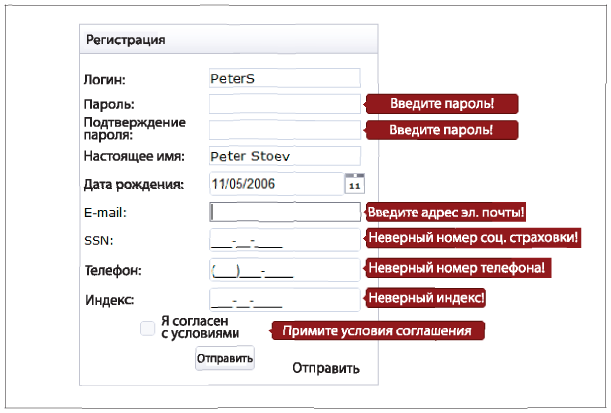
Рис. 2.1. Пример проверки значений в онлайновой регистрационной форме
Источник:
Если есть ограниченный набор допустимых значений, например аббревиатуры названий штатов в США, предложите пользователю выбрать нужный вариант из меню выпадающего списка. Автозаполнение может стать еще одним вариантом. В целом стремитесь к тому, чтобы пользователю пришлось вводить как можно меньше данных: лучше предложить варианты ответа на выбор, если, конечно, это позволяет формат требуемой информации.
В идеале постарайтесь максимально исключить человеческий фактор при сборе данных и по возможности автоматизируйте этот процесс.
Если вы располагаете временем и ресурсами, поручите двум сотрудникам независимо друг от друга расшифровывать данные (или пусть это дважды делает один сотрудник), сравнивать результаты и перепроверять данные в случае расхождений. Этот метод известен как «принцип двойной записи». Однажды я поручил стажеру расшифровать параметры из набора технических чертежей, он сделал это, а затем по собственной инициативе выполнил работу еще раз с последующей проверкой на различия. Мне как получателю данных это обеспечило уверенность в том, что точность данных максимально соответствует моим ожиданиям.
Интересный метод проверки применяется при передаче важных данных в цифровой форме, например номеров банковских счетов, номеров социальной страховки или даже номера ISBN этой книги. Этот метод называется контрольное число. После передаваемого номера добавляется число, которое представляет собой определенную функцию остальных цифр номера, и это число используется для проверки того, что предыдущие цифры были переданы из системы в систему без ошибок. Предположим, вам нужно передать индекс 94121. Воспользуемся самой простой схемой. Последовательно сложим все цифры, составляющие наш индекс, и получим 17. Сложим и эти цифры, получим 8. Передаем число 941218. Принимающая система выполняет все те же самые операции, но в обратной последовательности. Она отсекает последнюю цифру: 94121 → 17 → 8. Проверяет сумму цифр и получает в итоге 8. Почтовый индекс передан верно. В случае ошибки при передаче данных, например если бы вы передали почтовый индекс 841218, система обнаружила бы ошибку при проверке: 84121 → 16 → 7 ≠ 8.
Эта схема не отличается надежностью: 93221 (случайное повторение символа) или 94211 (перестановка символов местами) эту проверку пройдут. В случае необходимости контрольного числа в реальной жизни применяются более сложные математические функции, которые способны выявить в том числе и две указанные выше ошибки. Маршрутный номер (код банка, присваиваемый Американской банковской ассоциацией) — уникальное девятизначное число, стоящее в нижней части чека перед номером счета, — один из таких примеров. Контрольное число маршрутного номера — функция
3 × (d1 + d4 + d7) + 7 × (d2 + d5 + d8) + d3 + d6 + d9 mod 10 = 0
(mod означает получение остатка от целочисленного деления. Так, 32 mod 10 = 2, поскольку 32 = 3 × 10 + 2), которая проверяется простым кодом на языке Python:
routing_number = "122187238"
d = [int(c) for c in routing_number]
checksum = ( # do the math!
7 * (d[0] + d[3] + d[6]) +
3 * (d[1] + d[4] + d[7]) +
9 * (d[2] + d[5])
) % 10
print(d[8] == checksum)
Как видите, есть ряд способов, позволяющих сохранить высокое качество данных на стадии ввода информации. Но, к сожалению, и их нельзя считать абсолютно надежными. Итак, у вас в системе есть данные, которые переходят на стадию анализа. Что дальше?
РАЗВЕДОЧНЫЙ АНАЛИЗ ДАННЫХ
При получении любой информации аналитику в первую очередь следует в той или иной форме провести разведочный анализ данных (глава 5) для оценки их качества. Простой способ проверки на вопиющие ошибки, как в приведенном выше примере с людьми пятидюймового роста, — сделать сводку из данных. Для каждого показателя можно составить пятичисловую сводку: два крайних значения (максимальное и минимальное значение), нижний (25-й процентиль) и верхний (75-й процентиль) квартили и медиану. Посмотрите на крайние значения. Насколько они адекватны? Они выше или ниже значений, которые вы могли бы ожидать? Пять дюймов — это очевидно слишком мало.
Вот пример того, как выглядит классификация набора данных по ирисам, представленная с помощью R — бесплатной и открытой программной среды для статистических вычислений и построения графиков, которой часто пользуются специалисты по статистике и работе с данными. Американский ботаник Эдгар Андерсон собрал данные о 150 экземплярах ириса, по 50 экземпляров из трех видов, а Рональд Фишер на примере этого набора данных продемонстрировал работу созданного им метода для решения задачи классификации.

В этом виде можно легко получить общее представление о данных (1-й кв. = 1-й квартиль, или 25-й процентиль; 3-й кв. = 75-й процентиль). Ту же самую информацию можно представить в виде коробчатой диаграммы (рис. 2.2).
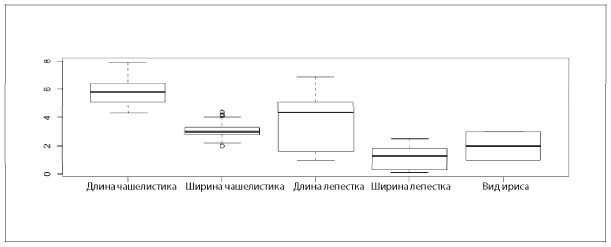
Рис. 2.2. Коробчатая диаграмма классификации набора данных по ирисам
На рис. 2.3 отражены некоторые ошибки, которые можно определить с помощью представления данных в виде простой гистограммы. В базе данных NHANES меня также интересовали данные, касающиеся артериального давления. После классификации выборки я получил максимальные значения артериального давления, которые показались мне гораздо выше нормы. Сначала я решил, что это тоже ошибка. Однако распределение показало, что эти значения хоть и находятся в хвосте распределения, но с разумной частотой. Я сверился с медицинской литературой и убедился, что значения артериального давления действительно могут быть такими высокими. Однако респондентами были люди, которые, скорее всего, не получали лечения. Как вы помните, опрос проводился среди всего населения США, а не среди пациентов медицинских учреждений, где им была бы оказана помощь, — все зависит от контекста.
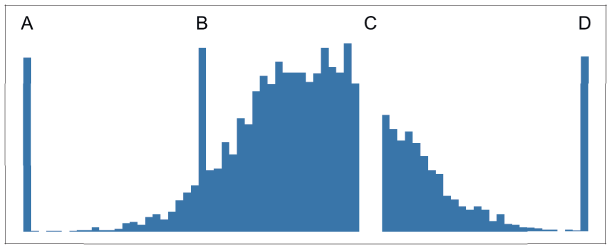
Рис. 2.3. Примеры типов ошибок, которые можно выявить с помощью простой гистограммы: А — значения по умолчанию, такие как –1, 0 или 1/1/1900; B — неправильный ввод или повтор данных; C — пропущенные данные; D — значения по умолчанию, такие как 999
Два важных навыка, которые должны развивать в себе аналитики, — прогнозирование возможных результатов и способность предварительно оценивать данные. Я ошибся относительно значений артериального давления, так как оценивал их с точки зрения нормы для обычных здоровых людей. Тем не менее я узнал нечто новое для себя, скорректировал свои ожидания и убедился, что данные, скорее всего, верные.
Это наглядный пример того, что изначально вы, возможно, будете ставить под сомнение все источники данных. Я всегда исхожу из базового предположения, что данные могут быть ошибочными, и моя работа в том, чтобы выяснить источник проблемы. Я не впадаю в крайности, но непременно провожу определенную работу (например, пользуюсь функциями summary(), pairs() и boxplot() в R, чтобы убедиться, что в данных нет очевидных ошибок. При работе с базами данных NHANES мы с коллегами создали гистограммы всех показателей, чтобы отследить случайные образцы, бимодальное распределение и другие резко выделяющиеся значения. Подсчет числа записей на конкретную дату может послужить еще одним простым тестом. Подобный разведочный анализ данных может быть простым, быстрым и чрезвычайно ценным.
ПРОПУЩЕННЫЕ ДАННЫЕ
Одна из наиболее существенных проблем — неполные или пропущенные данные (). Эта ошибка может быть двух видов: пропуск данных в записи или пропуск всей записи.
ЗАПОЛНЯЕМ ПРОПУСКИ: МЕТОД ВОССТАНОВЛЕНИЯ
Существуют статистические подходы, которые можно применить для восстановления пропущенных данных или подстановки на их место наиболее вероятных значений (мне нравятся инструмент Amelia package от R и сервис подстановки Google). Их успех зависит от ряда факторов, в том числе от размера выборки, количества и характера пропущенных данных, типа переменных (являются ли они однозначными, непрерывными, дискретными и так далее), а также зашумленности данных. Один из наиболее простых подходов заключается в том, чтобы заполнить пропущенные значения средним значением этой переменной. В более сложных подходах применяются вариации EM-алгоритма. Рекомендуемые к прочтению книги по этой теме: Missing Data (автор — П. Эллисон) и Statistical Analysis with Missing Data (авторы — Р. Литтл и Д. Рубин). Это эффективный инструмент, но в зависимости от типа данных сделанные с его помощью прогнозы в некоторых случаях могут быть неверными.
Зачем тогда рисковать и использовать этот подход? Во многих случаях, особенно в медицине и социальных науках, сбор данных может быть очень дорогим, к тому же возможность для сбора может быть только одна. Например, если вам нужно узнать значение артериального давления пациента на третий день клинического исследования, вы не можете вернуться в этот день, чтобы еще раз его измерить. Основная проблема заключается в том парадоксе, что чем меньше размер выборки, тем более ценна каждая запись. При этом чем меньше информации, с которой приходится работать алгоритму по восстановлению данных, тем менее точным получится результат.
Какое-то из пропущенных значений в записи способно сделать бесполезной всю эту запись. Это происходит в случае отсутствия ключевой информации, то есть показателя, определяющего тему записи (например, идентификационные данные клиента или заказа) и необходимого для объединения с другими данными. Кроме того, это может иметь место в случае, когда анализ строился на пропущенных данных. Например, если вы решили проанализировать продажи по почтовому индексу, а в какой-то записи индекс отсутствует, очевидно, что вы эту запись использовать не сможете. Если вам повезло и пропущенные данные не требуются для анализа, то выборка может и не сократиться.
Как уже говорилось ранее, причины пропуска данных могут быть самыми разными. Например, при проведении опроса респондент может не понять или пропустить вопрос, человек, обрабатывающий анкеты, может не разобрать почерк, или респондент может «на полпути» отказаться от участия в опросе. Бывает, что подводят технические средства: выходит из строя сервер или датчик. Поскольку эти причины в значительной мере влияют на качество данных, важно выяснить, почему данные отсутствуют.
Предположим, сломался сервер, на котором локально хранились нужные вам данные. Это может быть примером полностью потерянных записей. При наличии выравнивателя нагрузки, работающего на 20 серверов, один из которых вышел из строя, вы потеряли 5% информации — это неприятно, но, так как это случайная выборка, не все данные потеряны полностью. При этом, если наблюдалась какая-то закономерность, у вас могут быть проблемы. Например, если на сломавшийся сервер обычно поступала информация из конкретного географического региона, вы можете лишиться несоразмерного объема данных по этому отдельному региону, что может существенно повлиять на результаты анализа.
Возможны и другие сценарии, при которых выборка окажется необъективной. Например, представьте, что вы проводите опрос среди своих клиентов и даете респондентам две недели на то, чтобы прислать ответы. Ответы, полученные после указанной даты, рассматриваться не будут. А теперь предположим, что из-за проблем с доставкой группа клиентов получила свои заказы с опозданием. Возможно, они недовольны этой ситуацией и хотели бы выразить свое мнение, также ответив на ваш опрос и прислав его даже с опозданием. Если вы не учтете их ответы при анализе данных, то можете исключить из выборки большую долю недовольных клиентов. Оставшаяся выборка будет нерепрезентативной. В своих обучающих материалах по статистике Дэниел Минтц приводит пример формирования необъективной выборки: «Вопрос, нравится ли вам участвовать в опросах: да или нет?» Как вы думаете, кто примет участие в этом опросе, а кто нет?
Причина, по которой пропущены данные, чрезвычайно важна. (Далее мы воспользуемся терминологией из области статистики, хотя она и ужасна.) Необходимо изучить, являются ли данные:
MCAR
Пропуски совершенно случайны, например распределяемый случайным образом трафик веб-сервера.
MAR
Пропуски случайны, но есть закономерности. Пропущенные данные — это функция от наблюдаемых, непропущенных данных, например веб-сервер, обслуживающий определенный регион, результатом чего стало уменьшение размера выборки почтовых индексов.
MNAR
Пропуски неслучайны, а пропущенные данные — функция других пропущенных данных, например недовольные покупатели и их ответы на опрос. Это наиболее опасный случай, где присутствует серьезная необъективность.
Чем ниже по списку, тем больше у вас может возникнуть сложностей и тем меньше шансов справиться с ситуацией.
Самое важное — понимать, что может послужить источником необъективности. В некоторых случаях можно намеренно ввести ограничения или проследить влияние на показатели. Как ни странно, бывают даже такие необычные ситуации, при которых пропущенные предвзятые данные могут не оказать никакого влияния на показатели.
Когда я преподавал статистику, то приводил следующий пример, чтобы показать свойства медианного значения. Есть такой необычный спорт — голубиная гонка. Владельцы почтовых голубей отвозят своих питомцев за сотни миль от дома, выпускают, а затем мчатся домой и ждут их возвращения. Так как это «гонка», то по возвращении каждого голубя фиксируется время, за которое он долетел до дома: например, голубь номер шесть вернулся через два часа три минуты, голубь номер одиннадцать — через два часа тринадцать минут и так далее. Неизбежно некоторые голуби не возвращаются: возможно, они сбились с курса или стали жертвой хищников. Мы не можем вычислить среднее время возвращения всех птиц, так как по некоторым из них нет данных. При этом, если больше половины вернулись, можно вычислить медианное значение времени полета. Нам известна величина выборки, известна продолжительность времени полета более половины участников выборки, мы знаем, что все пропущенные данные будут меньше значения последней прилетевшей птицы. Таким образом, мы вполне можем вывести медианное значение: оно будет достоверным с этим набором пропущенных данных. Иногда выбор правильных показателей может спасти ситуацию (выбору системы показателей посвящена ).
ДУБЛИРОВАНИЕ ДАННЫХ
Еще одна распространенная проблема — дублирование данных. Это означает, что одна и та же запись появляется несколько раз. Причины могут быть разными: например, предположим, у вас десять файлов, которые нужно внести в базу данных, и вы случайно загрузили файл номер шесть дважды, или при загрузке файла возникала ошибка, вы остановили процесс, устранили ошибку и повторили загрузку, но при этом первая половина данных загрузилась в вашу базу дважды. Дублирование данных может возникнуть при повторной регистрации. Например, пользователь прошел регистрацию несколько раз, указал тот же самый или другой адрес электронной почты, в результате чего у него появилась другая учетная запись с той же самой персональной информацией. (Звучит просто, но подобная неопределенность может оказаться весьма коварной.) Дублирование информации также может возникнуть в результате того, что несколько приборов фиксируют ее по одному событию. В исследовании медицинских ошибок, о котором шла речь ранее, в 35% случаев причиной ошибки был неправильный перенос данных из одной системы в другую: иногда данные терялись, иногда дублировались. По данным госпиталя Джонса Хопкинса, в 92% случаев дублирование информации в их базе данных происходило в момент регистрации стационарных больных.
Когда речь идет о базах данных, есть несколько способов предотвратить дублирование. Наиболее эффективный — добавление ограничений в таблицу с базой данных. Вы можете создать составной ключ, который определяет одно или несколько полей и делает запись уникальной. После добавления этого ограничения у вас будет появляться оповещение, если вводимая комбинация данных совпадет с уже существующей в таблице. Второй способ — выбор варианта загрузки данных по принципу «все или ничего». Если в момент загрузки данных обнаруживается проблема, происходит откат на изначальные позиции, а новая информация в базе данных не сохраняется. Это дает шанс разобраться с причиной проблемы и повторить процесс загрузки данных без дублирования информации. Наконец, третий (менее эффективный) подход — выполнять две операции при загрузке: первая операция — SELECT, чтобы выяснить, не присутствует ли уже такая запись, вторая операция — INSERT, добавление новой записи.
Подобное дублирование данных случается чаще, чем вы думаете. Если вы не знаете, что в ваших данных встречается продублированная информация, это может повлиять на ваши показатели. Но хуже всего, что в какой-то момент времени это все равно обнаружится. А если качество данных будет поставлено под сомнение хотя бы однажды, это снизит доверие к выводам аналитиков, и эти выводы не будут учитываться в процессе принятия бизнес-решений.
УСЕЧЕННЫЕ ДАННЫЕ
При загрузке информации в базу данных часть ее может потеряться (Anderson → anders или 5456757865 → 54567578). В лучшем случае можно лишиться пары символов в форме обратной связи. В худшем может произойти усечение и объединение идентификационных данных двух разных клиентов и вы непреднамеренно объедините данные двух разных клиентов или заказов в один.
Как такое может произойти? В обычных реляционных базах данных при создании таблицы задаются название и тип каждого поля: например, должен быть столбец под названием «Фамилия» с ячейками, содержащими до 32 символов, или столбец «ID клиента» с целым числом в диапазоне от 0 до 65535. Проблема в том, что не всегда заранее известно максимальное количество символов или максимальное значение идентификатора, с которыми вам придется столкнуться. Возможно, вы получите образец данных, рассчитаете длину ячейки и для подстраховки увеличите это значение в два раза. Но вы никогда не узнаете наверняка, достаточно ли этого, пока не начнете работать с реальными данными. Более того, в базах ошибки с усечением данных, как правило, относятся к категории предупреждений: появляется оповещение, но процесс загрузки данных не прекращается. В результате такие проблемы легко не заметить. Один из способов предотвратить это — изменить настройки в базе данных, чтобы предупреждения отображались как полноценные ошибки и заметить их было легче.
ЕДИНИЦЫ ИЗМЕРЕНИЯ
Еще один источник проблем с качеством данных — несовпадение единиц измерения, особенно когда речь идет о международных командах и наборах данных. CNN сообщает:
Агентство NASA потеряло орбитальный аппарат по исследованию Марса стоимостью 125 млн долл. из-за того, что команда технических специалистов корпорации Lockheed Martin использовала при расчетах английские единицы измерения [фунт-секунда], в то время как специалисты самого агентства пользовались более привычной метрической системой [ньютон-секунда] для управления аппаратом.
Да, это действительно настолько важно. Единственный способ избежать подобного — иметь четко налаженную систему коммуникации. Разработайте нормативный документ, утверждающий процедуру всех проводимых измерений, то, как они должны выполняться, и в каких единицах измерения должен указываться результат. Необходимо, чтобы документ был однозначным и не допускал иных толкований, а итоговая база данных сопровождалась подробным словарем базы данных.
Другая область, где единицы измерения имеют критическое значение, — денежные валюты. Представим сайт для электронной коммерции, на котором размещен заказ стоимостью 23,12. В США по умолчанию будет считаться, что это 23,12 долл., в то время как во Франции это будет 23,12 евро. Если заказы из разных стран окажутся объединены в одну базу данных учета информации по валютам, то итоговый анализ будет иметь отклонения в сторону более слабой валюты (поскольку в числовом выражении цена за тот же предмет будет выше) и фактически окажется бесполезен.
Базы данных должны обеспечивать столько метаданных и контекста, сколько необходимо, чтобы избежать подобного недопонимания.
Кроме того, можно просто принять метрическую систему и придерживаться ее (проснись, Америка!).
ЗНАЧЕНИЯ ПО УМОЛЧАНИЮ
Следующая проблема с данными, которую в некоторых случаях бывает сложно отследить, это значения по умолчанию (). Пропущенные данные могут отражаться в базе данных как NULL, но также может использоваться определенное значение, которое можно задать. Например, 1 января 1900 года — стандартная дата по умолчанию. С ней могут быть разные проблемы. Во-первых, если вы забудете о том, что эта дата появляется по умолчанию, результаты анализа могут вас весьма озадачить. Предположим, вы оставили это значение по умолчанию в ячейке с датой рождения. Аналитиков может смутить тот факт, что столько людей в вашей базе данных старше 100 лет. Во-вторых, при неудачном значении по умолчанию есть риск перестать различать пропущенные и актуальные данные. Например, если вы устанавливаете «0» как значение по умолчанию для пропущенных данных, а значение актуальных данных тоже может быть равным 0, впоследствии вы не сможете определить, в какой ячейке отражены результаты измерения, а в какой просто пропущены данные. Отнеситесь к выбору значений по умолчанию внимательно.
Происхождение данных
При обнаружении проблемы с качеством данных важно отследить источник данных. В этом случае можно будет извлечь из анализа проблемную выборку или предложить более эффективные процессы и протоколы работы с этими данными. Для метаданных, хранящих информацию об источнике данных и историю их изменений, я использую термин «происхождение данных».
Эти метаданные делятся на два типа: история источников (отслеживает, откуда появились данные) и история преобразований (отслеживает, какие изменения претерпевали данные).
В моей команде мы, например, ежедневно собираем файлы данных от разных разработчиков и загружаем их в нашу базу данных для проведения анализа и составления отчетов. Обычно промежуточные таблицы, в которые мы заносим всю информацию, содержат два дополнительных поля: время начала загрузки (конкретного файла или группы файлов) и название файла. Таким образом, если у нас возникают проблемы с качеством данных, мы легко можем определить, из какого файла эти данные, и уточнить их у разработчиков. Это пример истории источников.
В транзакционных базах данных (то есть тех, которые поддерживают работающие приложения и используются, например, для обработки заказов, а не для составления отчетов) довольно часто встречаются два поля: created_at (время создания) и last_modified (последнее изменение). Как следует из названия полей, они содержат уточняющую информацию о времени создания записи (эта метаинформация заносится один раз и больше не меняется) и о времени, когда было сделано самое недавнее изменение (эта метаинформация обновляется в режиме реального времени каждый раз, когда в запись вносятся любые изменения). Иногда в таблице может быть дополнительное поле modified_by, в котором фиксируется имя пользователя, внесшего последнее изменение. Это помогает определить, например, было ли изменение в заказе или адресе электронной почты сделано самими пользователями или представителем, действующим от имени клиента. В данном случае элемент created_at — история источников, в то время как элементы last_modified и modified_by отражают историю преобразований. Наиболее детальный инструмент отслеживания происхождения — таблицы с журналом событий, где четко протоколируется, какие именно изменения, кем и когда были внесены.
Метаданные о происхождении должны быть элементом проактивной стратегии проверки, поддержания и улучшения качества данных.
Велика вероятность, что важность фактора происхождения данных будет только расти. Сегодня становится все легче создавать системы для сбора и хранения собственных данных и предлагать для коммерческого использования подходящие дополнительные данные от третьих сторон (такие как демографические данные по почтовым индексам или история покупок по адресам электронной почты). Этим компаниям необходимо создавать более обширный контекст вокруг своих клиентов, а также вокруг своих открытых и внутренних данных по событиям и транзакциям. Это требует создания объектов на основе многочисленных источников данных, а также изменения существующих данных, например восстановления пропущенных данных или пояснения данных дополнительными характеристиками, такими как предполагаемый пол, цель и так далее. При этом всегда должна оставаться возможность отследить первоначальные значения данных, их источник, а также причину или метаинформацию по любому изменению данных.
Качество данных как совместная ответственность
Причины, обусловливающие снижение качества данных, могут быть самыми разными. Помимо уже перечисленных ранее, могут возникнуть проблемы с определением окончания строк, проблемы с кодировкой, когда данные в кодировке Юникод сохраняются в ASCII (это происходит сплошь и рядом), могут быть поврежденные данные, усеченные файлы, несовпадения в именах и адресах (см. табл. 2.1). Вопросами качества данных должны заниматься не только специалисты по сбору и обработке данных — эту ответственность должны разделять все сотрудники компании.
Таблица 2.1. Краткий обзор некоторых типов проблем с качеством данных и потенциальные варианты их решения. Более подробный список можно найти у Singh and Singh. A descriptive classification of causes of data quality problems in data warehousing, IJCSI Intl. J. Comp. Sci 7, no. 3 (2010): 41–50
| Аспект | Проблема | Решение |
| Точность | Ввод данных: вставка символа | Веб: выпадающее меню, автозаполнение. Аналог: двойной ввод |
| Точность | Ввод данных: удаление символа | Веб: выпадающее меню, автозаполнение. Аналог: двойной ввод |
| Точность | Ввод данных: изменение символа | Веб: выпадающее меню, автозаполнение. Аналог: двойной ввод |
| Точность | Ввод данных: перестановка символов местами | Веб: выпадающее меню, автозаполнение. Аналог: двойной ввод |
| Точность | Ввод данных: недопустимые значения | Веб: проверка формы на соответствие. База данных: ограничение ячейки |
| Точность | Ввод данных: формат даты | Веб:автоматическая вставка формата даты. База данных: словарь базы данных, унификация (например, в формате ГГГГ-ММ-ДД) |
| Точность | Дублирующиеся записи | База данных: ограничения в виде комбинации клавиш, устранение повторов |
| Точность | Повреждение данных | Контрольная цифра или контрольная сумма |
| Точность | Разная кодировка данных (например, в одной таблице данные в кодировке UTF-8, а в другой — в ASCII) или ошибки при смене кодировки (например, в кодировке ASCII имя Jose может сохраниться как Jos) | База данных: стандартизация на базе одной широко принятой кодировки, например Latin1 или UTF-16 |
| Точность / взаимосвязанность | Усечение значения | База данных: увеличение поля для ввода данных, смена статуса предупреждений на ошибки |
| Взаимосвязанность | Объединение ячеек (например, «Doe, Joe» может быть сложно вставить в другую таблицу, где этот же человек записан как «Joe Doe») | Приложение или база данных: используйте отдельные ячейки |
| Взаимосвязанность | Разные первичные ключи для одной информационной единицы в разных системах осложняют правильное объединение данных | Приложение или база данных: унифицированная система идентификации |
| Непротиворечивость | Противоречивые данные (например, разные адреса одного человека в разных системах) | База данных: центральная пользовательская система, решение на основе установленного правила, какие данные более надежные |
| Путаница | Противоречивые временные зоны | Веб: автоматический выбор времени. База данных: словарь базы данных, унификация (например, на основе всемирного координированного времени (UTC) |
| Путаница | Заполнение ячеек другими данными (например, использование пустой ячейки middle_name для сохранения статуса заказа) | Приложение или база данных: наиболее эффективные методы, четкая, прописанная схема работы |
| Путаница | Путаница с кодировкой (например, HiLowRangeTZ3) | База данных: словарь базы данных |
| Путаница | Двусмысленные пропущенные данные (например, означает ли значение «0» пропущенные данные или актуальное значение «0»?) | Приложение или база данных: выбор разумных значений по умолчанию вне пределов возможных значений |
| Полнота | Частичные ошибки при загрузке | База данных: оповещения (возвращение к начальной стадии до загрузки) |
| Полнота | Пропуски совершенно случайны (MCAR) | Анализ: выборка с запасом, веса для категорий |
| Полнота | Пропуски случайны, но есть закономерности (MAR): данные пропущены как функция наблюдаемых или непропущенных данных | Анализ: ограничение анализа до того, когда данные можно использовать безопасно |
| Полнота | Пропуски неслучайны (MNAR): пропущенные данные — функция других пропущенных данных | Анализ: изменение или повторение процесса сбора данных |
| Полнота | Неправильное число или разделитель данных, вызывающие появление дополнительных столбцов или удаление | Поля данных (Quote fields), проверка качества источника данных |
| Своевременность | Устаревшие данные из-за медленных обновлений (например, журнал изменений адресов) | Более быстрая и качественная обработка данных |
| Происхождение | Сложность в определении, когда или почему было изменено значение | Приложение или база данных: более качественное отслеживание изменений, добавление в базу данных ячеек для фиксирования происхождения |
Разработчик внешнего интерфейса может добавить в форму на сайте функцию контроля правильности ввода почтового индекса. Специалист по обработке данных может добавить контрольную цифру при передаче данных в другое хранилище. Администратор базы данных может проверить и предотвратить дублирование информации или отследить ошибки при загрузке данных. Однако сложно ожидать, что им известно, какие показатели систолического артериального давления находятся в пределах нормы, а какие нет. Когда компания получает данные на основе заполненных форм, руководители подразделений, эксперты в предметных областях и аналитики должны быть в тесном контакте с разработчиками внешнего интерфейса, чтобы допустимые границы ввода данных были заданы правильно. Кроме того, они должны принимать участие в процессе формулирования требований и управления проектом, чтобы обеспечить контроль качества данных там, где это возможно. Как уже отмечалось ранее, специалисты по аналитике должны активно участвовать в процессе сбора данных.
Далее руководители направлений и эксперты в предметных областях должны проверить качество данных. Аналитики должны провести разведочный анализ или воспользоваться собственными методами определения, находятся ли значения в допустимых границах, соблюдаются ли ожидаемые закономерности (например, соотношение систолического и диастолического давления), оценить объем пропущенных данных и так далее. На фермерском рынке шеф-повар ресторана сам выбирает продукты, пробует авокадо, нюхает базилик. Образно говоря, это его сырые ингредиенты. У аналитиков должно быть такое же отношение к данным. Это их сырые ингредиенты, которые они должны тщательно отобрать.
Руководители направлений, как правило, принимают решения о покупке баз данных у третьих сторон, о разработке инструментов по сегментированию аудитории в ходе опроса клиентов или о проведении A/B-тестирования онлайн. Они тоже должны задумываться об объективности данных, на которые опираются. Они должны проводить сами или делегировать проведение разведочного анализа данных, составлять диаграммы распределения и обнаруживать «пятидюймовых» людей.

