5. Читаем отличный код
Программисты читают много кода. И один из основных принципов, лежащих в основе дизайна Python, — читаемость. Ключ к тому, чтобы стать хорошим программистом, — читать и понимать отличный код. Такой код обычно следует принципам, которые мы перечисляли в разделе «Стиль кода» в начале главы 4, и его предназначение легко понять.
В этой главе приводятся выдержки из наиболее читаемых проектов Python, которые иллюстрируют темы, рассмотренные в главе 4. По мере их описания мы также поделимся приемами чтения кода.
Перед вами список проектов, которые продемонстрированы в этой главе, они приведены в том порядке, в котором появляются:
• HowDoI () — консольное приложение, которое ищет в Интернете ответы на вопросы, связанные с программированием; написано на Python;
• Diamond () — демон Python, который собирает метрики и публикует их на Graphite или других бэкендах. Может собирать метрики для процессора, памяти, сети, ввода-вывода, загрузки и дисков. Предоставляет API для реализации пользовательских сборщиков метрик из практически любого источника;
• Tabli () — независимая от формата библиотека, позволяющая работать с таблицами данных;
• Requests () — библиотека для протокола передачи гипертекста (HyperText Transfer Protocol, HTTP) для людей (90 % из нас хотят иметь HTTP-клиент, который автоматически выполняет авторизацию и соответствует многим стандартам (/) для выполнения таких заданий, как многокомпонентная загрузка файла с помощью единственного вызова функции);
• Werkzeug () изначально был коллекцией различных утилит для приложений стандарта Web Service Gateway Interface (WSGI), а теперь стал одним из наиболее мощных вспомогательных модулей WSGI;
• Flask () — микрофреймворк для Python, основанный на Werkzeug и Jinja2. Подойдет для быстрого создания веб-страниц.
Эти проекты могут решать и другие задачи (не только те, что мы упомянули), и мы надеемся, что после прочтения текущей главы вы захотите загрузить и прочесть подробнее хотя бы один-два этих проекта самостоятельно (а затем, возможно, даже рассказать о них другим).
Типичные функции
Некоторые функции одинаковы у всех проектов: детали снепшотов для каждого из них показывают, что их функции состоят из очень малого количества строк кода (меньше 20, исключая пробелы и комментарии) и множества пустых строк. Крупные и более сложные проекты включают строки документации и/или комментарии; обычно больше пятой части содержимого базы кода составляет документация. Как вы можете видеть на примере HowDoI, в котором нет строк документации (поскольку он не предназначен для интерактивного использования), комментарии необязательны, если код простой и ясный. В табл. 5.1 описаны стандартные характеристики этих проектов.
Таблица 5.1. Типичные функции рассматриваемых проектов
| Пакет | Лицензия | Количество строк | Строки документации (% от общего количества строк) | Комментарии документации (% от общего количества строк) | Пустые строки документации (% от общего количества строк) | Средняя длина функций |
| HowDoI | MIT | 262 | 0 | 6 | 20 | 13 строк |
| Diamond | MIT | 6021 | 21 | 9 | 16 | 11 строк |
| Tablib | MIT | 1802 | 19 | 4 | 27 | 8 строк |
| Requests | Apache 2.0 | 4072 | 23 | 8 | 19 | 10 строк |
| Flask | BSD 3-clause | 10 163 | 7 | 12 | 11 | 13 строк |
| Werkzeug | BSD 3-clause | 25 822 | 25 | 3 | 13 | 9 строк |
В каждом разделе мы будем использовать разные приемы чтения кода для того, чтобы понять, чему посвящен проект. Далее мы приведем фрагменты кода, которые демонстрируют темы, описанные в этом руководстве. (Если мы не выделили какую-то функцию в одном проекте, это не означает, что ее там нет; мы лишь хотим охватить большое количество концепций с помощью этих примеров.) После завершения чтения этой главы вы будете более уверенно работать с кодом. Приведенные примеры продемонстрируют, что такое хороший код (некоторые идеи вы, возможно, захотите применить в своем коде в будущем).
HowDoI
Проект HowDoI, написанный Бенджамином Гляйтсманом (Benjamin Gleitzman), станет отличной стартовой точкой нашей одиссеи, несмотря на то что он состоит менее чем из 300 строк.
Читаем сценарий, состоящий из одного файла
Сценарий обычно имеет четко определенные точку входа, параметры и точку выхода. Благодаря этому читать его проще, чем библиотеки, которые предоставляют API или фреймворк.
Загрузите модуль HowDoI с GitHub:
$ git clone
$ virtualenv -p python3 venv # Или используйте mkvirtualenv, на ваш выбор...
$ source venv/bin/activate
(venv)$ cd howdoi/
(venv)$ pip install --editable .
(venv)$ python test_howdoi.py # Запустите юнит-тесты
Теперь у вас должен быть установлен исполняемый файл howdoi в каталоге venv/bin. (Вы можете увидеть его, введя cat 'which howdoi' в командной строке.) Он был сгенерирован автоматически, когда вы ввели команду pip install.
Читаем документацию к HowDoI
Документация к HowDoI находится в файле README.rst, который располагается в репозитории на GitHub (). Это небольшое приложение для командной строки, позволяющее пользователям искать в Интернете ответы на вопросы, связанные с программированием.
В командной строке терминальной оболочки можно ввести команду howdoi --help, чтобы узнать, как пользоваться HowDoI:
(venv)$ howdoi --help
usage: howdoi [-h] [-p POS] [-a] [-l] [-c] [-n NUM_ANSWERS] [-C] [-v]
[QUERY [QUERY ...]]
instant coding answers via the command line
positional arguments:
QUERY the question to answer
optional arguments:
-h, --help show this help message and exit
-p POS, --pos POS select answer in specified position (default: 1)
-a, --all display the full text of the answer
-l, --link display only the answer link
-c, --color enable colorized output
-n NUM_ANSWERS, --num-answers NUM_ANSWERS
number of answers to return
-C, --clear-cache clear the cache
-v, --version displays the current version of howdoi
Из документации мы знаем, что HowDoI получает ответы на вопросы, связанные с программированием, из Интернета. В руководстве указано, что можно выбрать ответ в определенной позиции, раскрасить выводимую информацию, получить несколько ответов, а также то, что модуль имеет кэш, который можно очистить.
Использование HowDoI
Мы можем подтвердить, что понимаем, как работает HowDoI. Рассмотрим пример:
(venv)$ howdoi --num-answers 2 python lambda function list comprehension
--- Answer 1 ---
[(lambda x: x*x)(x) for x in range(10)]
--- Answer 2 ---
[x() for x in [lambda m=m: m for m in [1,2,3]]]
# [1, 2, 3]
Мы установили HowDoI, прочли его документацию и теперь можем его использовать. Перейдем к чтению кода!
Читаем код HowDoI
Если вы заглянете в каталог howdoi/, то увидите два файла: __init__.py, который состоит всего из одной строки, указывающей номер версии, и howdoi.py, который мы откроем и прочитаем.
Просматривая файл howdoi.py, мы увидим, что каждое новое определение функции использовано в следующей функции; это упрощает чтение кода. Каждая функция выполняет всего одну задачу (она вынесена в ее имя). Главная функция command_line_runner() располагается в нижней части файла howdoi.py.
Вместо того чтобы приводить здесь исходный код HowDoI, мы можем проиллюстрировать структуру его вызовов с помощью графа, показанного на рис. 5.1. Этот граф создан с помощью Python Call Graph (/), который предоставляет визуализацию функций, вызываемых при запуске сценария Python. Он хорошо работает с приложениями командной строки благодаря тому, что они имеют одну точку входа и относительно небольшое количество путей выполнения, по которым может пойти код. (Обратите внимание, что мы вручную удалили из отрисованного изображения функции, которые отсутствуют в проекте HowDoI, дабы вместить граф на страницу, а также немного переформатировали его.)
Код мог бы выглядеть как одна большая спагетти-функция, сложная для восприятия. Вместо этого код был намеренно разбит на отдельные функции, имеющие понятные имена. Кратко рассмотрим граф, изображенный на рис. 5.1: функция command_line_runner() анализирует входные данные и передает флаги и запрос, полученные от пользователя, в функцию howdoi(). Далее функция howdoi() оборачивает функцию _get_instructions() в блок try/except, чтобы можно было отловить ошибки соединения и вывести адекватное сообщение об ошибке (поскольку код приложения не должен завершать работу при наличии исключения).
Основную работу делает функция _get_instructions(): она вызывает функцию _get_links(), чтобы выполнить поиск ссылок, соответствующих запросу, в Google или на сайте Stack Overflow, а затем — функцию _get_answer() для каждого полученного результата (вплоть до предельного количества ссылок, указанного пользователем в командной строке, — по умолчанию одной).
Функция _get_answer() следует ссылке на ресурс Stack Overflow, извлекает код из ответа, раскрашивает его и возвращает функции _get_instructions(), которая объединяет все ответы в одну строку и возвращает их. Функции _get_links() и _get_answer() вызывают _get_result(), чтобы выполнить HTTP-запрос: _get_links() для запроса Google и _get_answer() для получения ссылок из запроса Google.
Функция _get_result() лишь оборачивает функцию requests.get() блоком try/except, чтобы можно было отловить ошибки SSL, вывести сообщение об ошибке и повторно сгенерировать исключение, дабы блок try/except верхнего уровня мог отловить его и выйти (это правило хорошего тона для любых программ).
| Упаковка HowDoI Файл setup.py проекта HowDoI, который находится выше каталога howdoi/, — отличный пример модуля установки, поскольку в дополнение к обычной установке пакета он также устанавливает исполняемый файл (к которому вы можете обратиться при упаковке собственной утилиты командной строки). Функция установки tools.setup() использует аргументы с ключевым словом для определения всех параметров конфигурации. Та часть, которая отвечает за исполняемый файл, использует аргумент с ключевым словом entry_points. |
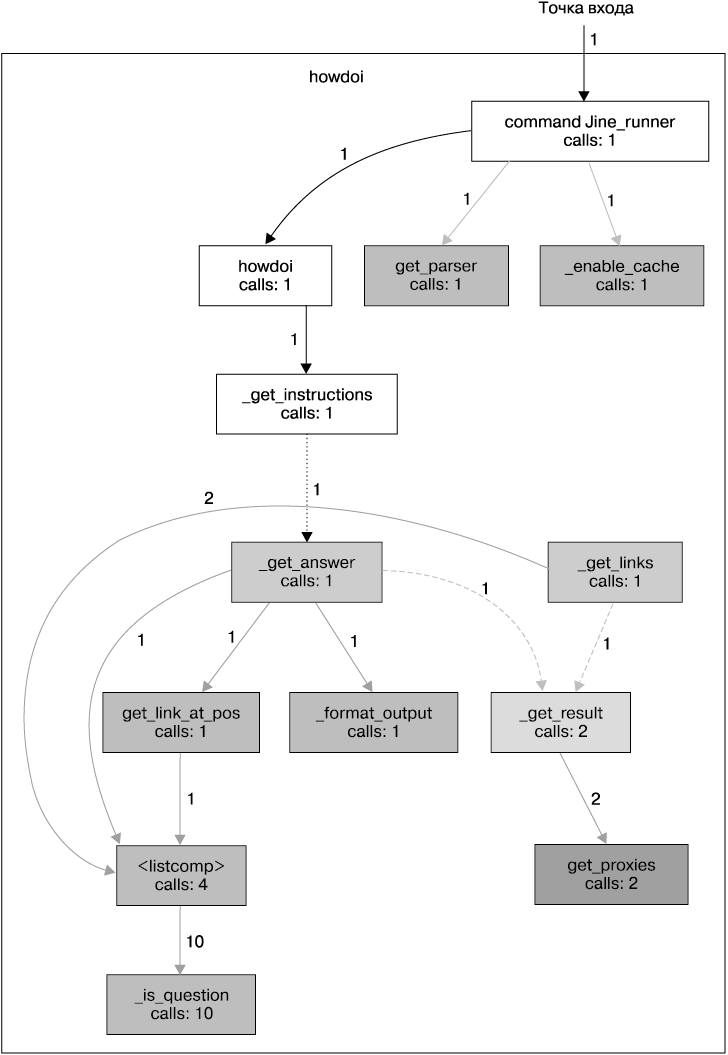
Рис. 5.1. Прозрачные пути и прозрачные имена функций в графе вызовов проекта howdoi

 Ключевое слово для перечисления сценариев консоли — console_scripts.
Ключевое слово для перечисления сценариев консоли — console_scripts.
 Объявляет, что исполняемый файл с именем howdoi в качестве цели будет иметь функцию howdoi.howdoi.command_line_runner(). Поэтому мы будем знать, что функция command_line_runner() является стартовой точкой для всего приложения.
Объявляет, что исполняемый файл с именем howdoi в качестве цели будет иметь функцию howdoi.howdoi.command_line_runner(). Поэтому мы будем знать, что функция command_line_runner() является стартовой точкой для всего приложения.
Примеры из структуры HowDoI
HowDoI — это небольшая библиотека (в других разделах мы рассмотрим ее архитектуру более подробно, а здесь лишь скажем пару слов).
Пусть каждая функция делает что-то одно
Мы не устанем повторять, насколько полезно разделять внутренние функции HowDoI таким образом, чтобы они делали лишь что-то одно. Существуют функции, чье единственное предназначение — оборачивание других функций в оператор try/except. (Единственная функция, имеющая оператор try/except, которая не следует этой практике, — _format_output(). Она задействует операторы try/except не для обработки исключений, а для определения языка программирования с целью подсветки синтаксиса.)
Пользуйтесь данными, доступными системе
HowDoI проверяет и использует текущие системные значения, например с помощью функции urllib.request.getproxies() обрабатывается применение прокси-серверов (это подойдет для организаций вроде школ, которые имеют промежуточный сервер, фильтрующий соединение с Интернетом). Обратите внимание на этот сниппет:
XDG_CACHE_DIR = os.environ.get(
'XDG_CACHE_HOME',
os.path.join(os.path.expanduser('~'), '.cache')
)
Как вам узнать, что эти переменные существуют? Необходимость urllib.request.getproxies() обусловлена необязательными аргументами в requests.get(), поэтому часть этой информации доступна из сведений API о вызываемых вами библиотеках. Переменные среды зачастую нужны для определенной функциональности, поэтому, если библиотека предназначена для использования с конкретной базой данных или другим родственным приложением, в документации к этим приложениям будут перечислены актуальные переменные среды. Для систем POSIX хорошей стартовой точкой будет список стандартных переменных среды Ubuntu () или список переменных среды в спецификации POSIX (), который указывает на другие важные списки.
Примеры из стиля HowDoI
HowDoI в основном следует PEP 8, но не в тех случаях, когда это вредит читаемости. Например, операторы импорта находятся в верхней части файла, но стандартная библиотека и внешние модули перемешаны. И несмотря на то что строковые константы в USER_AGENTS гораздо длиннее 80 символов, в строках нет места, где их можно было бы разбить естественным образом, поэтому они остаются целыми.
В нескольких следующих фрагментах кода показываются другие решения, связанные со стилем, о которых мы говорили в главе 4.
Имена функций, которые начинаются с нижнего подчеркивания (мы все — ответственные пользователи)
Имя почти каждой функции в HowDoI начинается с нижнего подчеркивания. Это показывает, что функции предназначены лишь для внутреннего использования. Для большинства из них это нужно, потому что при их прямом вызове появляется вероятность генерации необработанного исключения (этим грешат все функции, которые вызывают функцию _get_result()), до тех пор пока не будет вызвана функция howdoi(), обрабатывающая все возможные исключения.
Остальные внутренние функции (_format_output(), _is_question(), _enable_cache() и _clear_cache()) не предназначены для использования за пределами пакета. Тестирующий сценарий howdoi/test_howdoi.py вызывает только функции без префиксов, проверяя, что средство форматирования работает, и передавая аргумент командной строки для раскрашивания в функцию верхнего уровня howdoi.howdoi() вместо того, чтобы передавать код в функцию howdoi._format_output().
Обрабатывайте вопросы совместимости только в одном месте (читаемость имеет значение)
Разница между версиями возможных зависимостей обрабатывается перед выполнением основного кода, поэтому пользователь знает, что проблем с зависимостями не возникнет, а проверка версий не засоряет код в других местах. Это хорошо, поскольку HowDoI поставляется как инструмент командной строки и дополнительные усилия, затрачиваемые пользователями, будут означать, что им не потребуется менять свою среду Python, чтобы установить инструмент. Рассмотрим фрагмент кода, в котором решается эта проблема:
try:
from urllib.parse import quote as url_quote
except ImportError:
from urllib import quote as url_quote
try:
from urllib import getproxies
except ImportError:
from urllib.request import getproxies
В следующем сниппете разница подходов к обработке Unicode в Python 2 и Python 3 нивелируется всего за семь строк путем создания функции u(x), которая либо эмулирует Python 3, либо не делает ничего. Кроме того, он следует новым принципам цитирования Stack Overflow ( 71080), приводя оригинальный исходный код:
# Разрешаем разницу обработки Unicode между Python 2 и 3
# 33040/3 05414
if sys.version < '3':
import codecs
def u(x):
return codecs.unicode_escape_decode(x)[0]
else:
def u(x):
return x Питонские решения (красивое лучше, чем уродливое)
В следующем фрагменте кода из файла howdoi.py показываются продуманные, питонские решения. Функция get_link_at_pos() возвращает значение False, если результаты не найдены, или определяет ссылки на вопросы, касающиеся Stack Overflow, и возвращает ту из них, которая находится на желаемой позиции (либо последнюю, если ссылок недостаточно).


 Функция _is_question() определяется в отдельной строке, что указывает четкое значение непонятному в противном случае поиску с использованием регулярных выражений.
Функция _is_question() определяется в отдельной строке, что указывает четкое значение непонятному в противном случае поиску с использованием регулярных выражений.
 Списковое включение читается как предложение благодаря отдельному определению функции _is_question() и информативным именам переменных.
Списковое включение читается как предложение благодаря отдельному определению функции _is_question() и информативным именам переменных.
 Раннее использование оператора возврата упрощает код.
Раннее использование оператора возврата упрощает код.
 Дополнительный шаг, который тратится на присваивание значения переменной link, здесь…
Дополнительный шаг, который тратится на присваивание значения переменной link, здесь…
 …и здесь вместо использования двух отдельных операторов возврата, не имеющих именованных переменных, подчеркивает предназначение функции get_link_at_pos() с помощью прозрачных имен переменных. Код самозадокументирован.
…и здесь вместо использования двух отдельных операторов возврата, не имеющих именованных переменных, подчеркивает предназначение функции get_link_at_pos() с помощью прозрачных имен переменных. Код самозадокументирован.
 Единый оператор возврата, находящийся на высшем уровне отступов, явно показывает, что все пути по коду завершатся либо сразу (поскольку ссылки не найдены), либо в конце функции, вернув ссылку. Работает наше правило: мы можем прочесть первую и последнюю строки этой функции и понять, что она делает. (Получив несколько ссылок и позицию, функция get_link_at_pos() возвращает одну ссылку, которая находится на заданной позиции.)
Единый оператор возврата, находящийся на высшем уровне отступов, явно показывает, что все пути по коду завершатся либо сразу (поскольку ссылки не найдены), либо в конце функции, вернув ссылку. Работает наше правило: мы можем прочесть первую и последнюю строки этой функции и понять, что она делает. (Получив несколько ссылок и позицию, функция get_link_at_pos() возвращает одну ссылку, которая находится на заданной позиции.)
Diamond
Diamond — это демон (приложение, постоянно работающее как фоновый процесс), который собирает метрики системы и публикует их в программах вроде MySQL, Graphite (/) (платформа с открытым исходным кодом, созданная компанией Orbitz в 2008 году, которая сохраняет, получает и по возможности строит графики на основе временных рядов) и др. У нас есть возможность взглянуть на хорошую структуру пакетов, поскольку Diamond состоит из нескольких файлов и гораздо крупнее HowDoI.
Читаем более крупное приложение
Diamond также является приложением командной строки, поэтому, как и в случае с HowDoI, существуют четкая стартовая точка и четкие пути выполнения, однако теперь поддерживающий код находится в нескольких файлах.
Загрузите Diamond с GitHub (в документации говорится, что программа работает только в ОС CentOS или Ubuntu, но код, находящийся в ее файле setup.py, позволяет ей запускаться на всех платформах. Однако отдельные команды, которые стандартные сборщики используют для наблюдения за памятью, дисковым пространством и другими системными метриками, отсутствуют в Windows). На момент написания этой книги программа все еще использует Python 2.7:
$ git clone
$ virtualenv -p python2 venv # Она все еще несовместима с Python 3...
$ source venv/bin/activate
(venv)$ cd Diamond/
(venv)$ pip install --editable .
(venv)$ pip install mock docker-py # Эта зависимость нужна для тестирования.
(venv)$ pip install mock # Эта зависимость также нужна для тестирования.
(venv)$ python test.py # Запускаем юнит-тесты.
Как и в случае с библиотекой HowDoI, сценарий установки Diamond добавляет исполняемые файлы diamond и diamond-setup в каталог venv/bin/. В этот раз они не генерируются автоматически, а являются заранее написанными сценариями и лежат в каталоге Diamond/bin/. В документации говорится, что файл diamond запускает сервер, а diamond-setup — необязательный инструмент, который позволяет пользователям интерактивно изменять настройки сборщика в конфигурационном файле.
Существует множество дополнительных каталогов, пакет diamond находится внутри каталога Diamond/src. Мы взглянем на файлы из каталогов Diamond/src (в которых содержится основной код), Diamond/bin (хранится исполняемый файл diamond) и Diamond/conf (содержится пример конфигурационного файла). Остальные каталоги и файлы могут представлять интерес для тех, кто хочет распространять подобные приложения (в рамках этой книги мы их опустим).
Читаем документацию к Diamond
Для начала можно попытаться понять идею проекта, взглянув на онлайн-документацию (/). Цель Diamond — упрощение сборки системных метрик для кластеров машин. Появилась в 2011 году благодаря компании BrightCove, Inc., на сегодняшний день в ее базу кода внесли вклад более 200 человек.
После описания истории и предназначения в документации говорится, как установить и запустить демон: вам нужно лишь модифицировать предложенный файл конфигурации (у нас он находится по адресу conf/diamond.conf.example), поместить в стандартное место (/etc/diamond/diamond.conf) или по пути, который вы укажете в командной строке, — и вы готовы приступить к работе. Кроме того, на вики-странице проекта Diamond () вы можете найти полезный раздел о конфигурации.
Из командной строки мы можем вывести на экран руководство по использованию с помощью команды diamond --help:
(venv)$ diamond --help
Usage: diamond [options]
Options:
-h, --help show this help message and exit
-c CONFIGFILE, --configfile=CONFIGFILE
config file
-f, --foreground run in foreground
-l, --log-stdout log to stdout
-p PIDFILE, --pidfile=PIDFILE
pid file
-r COLLECTOR, --run=COLLECTOR
run a given collector once and exit
-v, --version display the version and exit
--skip-pidfile Skip creating PID file
-u USER, --user=USER Change to specified unprivileged user
-g GROUP, --group=GROUP
Change to specified unprivileged group
--skip-change-user Skip changing to an unprivileged user
--skip-fork Skip forking (damonizing) process
Из него мы узнаем, что демон использует файл конфигурации; по умолчанию работает в фоновом режиме; имеет возможность журналирования. Вы можете указать файл PID (process ID, «идентификатор процесса»), протестировать сборщики, можете изменить пользователя и группу процесса. По умолчанию он демонизирует (создаст копию) процесс.
Используем Diamond
Для того чтобы еще лучше понять Diamond, запустим его. Нам нужен модифицированный файл конфигурации, который мы можем поместить в созданный нами каталог Diamond/tmp. Находясь в нем, введите следующий код:
(venv)$ mkdir tmp
(venv)$ cp conf/diamond.conf.example tmp/diamond.conf
Далее отредактируйте файл tmp/diamond.conf, чтобы он выглядел так:

Из этого примера конфигурации видно следующее.
 Существует несколько обработчиков, каждый из которых мы можем выбрать по имени класса.
Существует несколько обработчиков, каждый из которых мы можем выбрать по имени класса.
 Мы можем управлять пользователем и группой, под которыми запущен демон (пустое значение означает, что будут задействованы текущий пользователь и группа).
Мы можем управлять пользователем и группой, под которыми запущен демон (пустое значение означает, что будут задействованы текущий пользователь и группа).
 Мы можем указать путь, который будет применен для поиска модулей сборщиков. Так Diamond узнает, где находятся пользовательские подклассы класса Collector (мы явно указываем это в файле конфигурации).
Мы можем указать путь, который будет применен для поиска модулей сборщиков. Так Diamond узнает, где находятся пользовательские подклассы класса Collector (мы явно указываем это в файле конфигурации).
 Конфигурацию обработчиков мы храним отдельно.
Конфигурацию обработчиков мы храним отдельно.
Далее запустите Diamond, указав, что журнал будет сохраняться по адресу /dev/stdout (будет использована стандартная конфигурация форматирования), что приложение не должно работать в фоновом режиме, что нужно опустить запись в файл PID и использовать новые файлы конфигурации:
(venv)$ diamond -l -f --skip-pidfile --configfile=tmp/diamond.conf
Для того чтобы завершить процесс, нажимайте Ctrl+C до тех пор, пока снова не появится командная строка. Журнал показывает, что делают сборщики и обработчики: сборщики собирают разные метрики (вроде объема общей, свободной памяти и памяти подкачки от MemoryCollector), которые обработчики форматируют и отправляют в разные точки назначения вроде Graphite, MySQL (в нашем тестовом случае — как сообщения журнала в /dev/stdout).
Читаем код Diamond
Для чтения более крупных проектов лучше использовать IDE — с их помощью вы можете быстро обнаружить оригинальное определение функций и классов исходного кода (при наличии определения можете найти все места в проекте, где задействованы функция или класс). Для использования этой функциональности укажите интерпретатору Python вашей IDE применять одну из виртуальных сред.
Вместо того чтобы разбирать каждую функцию, как мы сделали это для HowDoI, изучим рис. 5.2 (показаны операторы импорта). Схема демонстрирует, какие модули Diamond импортируют другие модули. Подобные рисунки помогают понять более крупные проекты. Можно начать с исполняемого файла diamond в левом верхнем углу и следовать всем операторам импорта в проекте Diamond. Помимо исполняемого файла diamond, в каждом квадрате указывается файл (модуль) или папка (пакет) в каталоге src/diamond.
Хорошо организованные и удачно названные модули Diamond позволяют понять идею кода, просто взглянув на схему: модуль diamond получает версию из util, затем настраивает журналирование с помощью utils.log и запускает экземпляр сервера с помощью server. Сервер импортирует почти все вспомогательные модули, используя классы utils.classes, чтобы получить доступ к обработчикам в handler и сборщикам, config — для чтения файла конфигурации и получения настроек для сборщиков (дополнительные пути для сборщиков, определенных пользователем), scheduler и signals — для установки интервала опроса для сборщиков, чтобы подсчитать их метрики, а также для настройки обработчиков и указания им приступать к обработке очереди метрик, которые нужно отправить.
Схема не включает в себя вспомогательные модули convertor.py и gmetric.py, используемые определенными сборщиками, а также более 20 реализаций обработчиков, определенных в подпакете handler, и более 100 реализаций сборщиков, определенных в каталоге проекта Diamond/src/collectors/ (которые находятся в другом месте, если процесс установки Diamond отличается от того, который мы выполнили при чтении, то есть использовали дистрибутивы пакетов PyPI или Linux вместо исходного кода). Они импортируются с помощью функции diamond.classes.load_dynamic_class(), которая затем вызывает функцию diamond.util.load_class_from_name() для загрузки классов на основе имен, представленных в строках конфигурационного файла, поэтому операторы импорта могут не вызывать их явно.
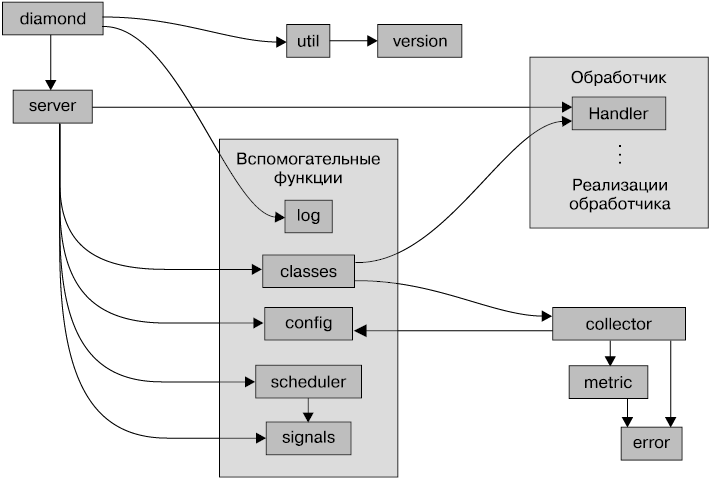
Рис. 5.2. Структура импортированных модулей в Diamond
Чтобы понять, для чего в проекте присутствуют пакет utils и модуль util, нужно открыть код: модуль util предоставляет функции, связанные с упаковкой Diamond (а не с его работой): функцию для получения номера версии на основе version.__VERSION__ и две функции, которые анализируют строки, позволяющие определить модули или классы и импортировать их.
| Журналирование в Diamond Функция diamond.utils.log.setup_logging(), которая находится в файле src/diamond/utils/log.py, вызывается из функции main() исполняемого файла diamond при запуске демона: # Инициализация журналирования log = setup_logging(options.configfile, options.log_stdout) Если значение options.log_stdout равно True, функция setup_logging() настроит средство ведения журнала со стандартным форматированием так, чтобы оно |
| отправляло записи в стандартный поток выхода на уровне DEBUG. Это делается в следующем фрагменте кода: ##~~ ... Пропускаем все остальное ... def setup_logging(configfile, stdout=False): log = logging.getLogger('diamond') if stdout: log.setLevel(logging.DEBUG) streamHandler = logging.StreamHandler(sys.stdout) streamHandler.setFormatter(DebugFormatter()) streamHandler.setLevel(logging.DEBUG) log.addHandler(streamHandler) else: ##~~ ... Пропускаем это ... В противном случае он анализирует файл конфигурации с помощью функции logging.config.file.fileConfig() из стандартной библиотеки Python. Перед вами вызов функции — он выделен отступами, поскольку находится внутри предшествующего оператора if/else и блока try/except: logging.config.fileConfig(configfile, disable_existing_loggers=False) Конфигурация журналирования игнорирует ключевые слова в конфигурационном файле, которые не связаны с журналированием. Так Diamond может использовать один и тот же конфигурационный файл как для своей конфигурации, так и для конфигурации журналирования. В примере конфигурационного файла, который располагается по адресу Diamond/conf/diamond.conf.example, среди прочих обработчиков определяется и обработчик журналирования: ### Настройки обработчиков [handlers] # обработчик(и) для журналирования keys = rotated_file Далее в файле конфигурации под заголовком «Настройки для журналирования» определяются примеры средств ведения журнала. Для получения более подробной информации смотрите документацию к конфигурационным файлам для журналирования (). |
Примеры из структуры Diamond
Diamond — это больше чем исполняемое приложение. Он также является библиотекой, которая предоставляет пользователям возможность создавать и применять собственные сборщики.
Мы продемонстрируем те элементы структуры пакета, которые нам нравятся, а затем изучим, как именно Diamond позволяет приложению импортировать и использовать определенные извне сборщики.
Разбиваем функциональность между пространствами имен (поскольку пространства имен — это отличная штука!)
На схеме рис. 5.2 показан модуль сервера, взаимодействующий с тремя другими модулями проекта: diamond.handler, diamond.collector и diamond.utils.
В подпакете utils можно было бы разместить все классы и функции в одном большом модуле util.py, однако можно подключить пространства имен для того, чтобы разбить код на отдельные файлы, — и команда разработчиков ею воспользовалась. Отличный выбор!
Все реализации обработчиков содержатся в каталоге diamond/handler (это логично), но структура для сборщиков отличается. Для них не предусмотрен каталог — только модуль diamond/collector.py, в котором определяются базовые классы Collector и ProcessCollector. Все реализации подклассов класса Collector определены в каталоге Diamond/src/collectors/, в виртуальной среде они будут установлены по адресу venv/share/diamond/collectors, если вы устанавливали Diamond с помощью PyPI (рекомендованный способ), а не с помощью GitHub (как это сделали мы). Это помогает пользователю создать новые реализации сборщиков: размещение всех сборщиков в одном месте упрощает их поиск для приложения, а также создание аналогичных сборщиков. Наконец, каждая реализация сборщика в Diamond/src/collectors находится в своем каталоге (а не в отдельном файле), что позволяет разделить тесты для каждой реализации класса Collector. Также отлично придумано!
Расширяемые пользователем классы (сложное лучше, чем запутанное)
Добавить новую реализацию класса Collector нетрудно: нужно создать подкласс абстрактного базового класса diamond.collector.Collector, реализовать метод Collector.collect() и поместить реализацию в отдельный каталог по адресу venv/src/collectors/.
Сама по себе реализация сложна, но пользователь этого не знает. В данном разделе рассматриваются простая часть API сборщиков, которая видна пользователю, и сложный код, благодаря которому появился подобный интерфейс.
Сложное против запутанного. Мы можем сравнить работу со сложным кодом со швейцарскими часами — они просто работают, но внутри находится множество маленьких деталей, взаимодействующих с высокой точностью, чтобы упростить работу с API. Использование запутанного кода похоже на управление самолетом — вы наверняка должны знать, что делать, чтобы не разбиться и не сгореть. Мы не хотим жить в мире без самолетов, но при этом желаем пользоваться часами, не вникая в тонкости их работы. Везде, где это возможно, создавайте менее сложные пользовательские интерфейсы.
Простой пользовательский интерфейс. Для того чтобы создать собственный сборщик данных, пользователь должен создать подкласс абстрактного класса Collector, а затем предоставить путь к нему с помощью конфигурационного файла. Рассмотрим пример нового определения класса Collector из класса Diamond/src/collectors/cpu/cpu.py. Когда Python ищет метод collect(), он сначала проверит на наличие CPUCollector, а затем, если оно не будет найдено, использует метод diamond.collector.Collector.collect(), что сгенерирует исключение NotImplementedError.
Код сборщика может выглядеть так:
# coding=utf-8
import diamond.collector
import psutil
class CPUCollector(diamond.collector.Collector):
def collect(self):
# В классе Collector содержится лишь инструкция raise(NotImplementedError)
metric_name = "cpu.percent"
metric_value = psutil.cpu_percent()
self.publish(metric_name, metric_value)
Стандартное место для размещения определений сборщиков — каталог venv/share/diamond/collectors/, но вы можете хранить их по тому адресу, который укажете в свойстве collectors_path конфигурационного файла. Имя класса CPUCollector уже указано в примере конфигурационного файла. За исключением добавления спецификаций hostname или hostname_method в общие стандартные свойства (расположенные под конфигурационным файлом) или в отдельные переопределенные значения для сборщика, как показано в следующем примере, не нужно вносить другие изменения (в документации перечислены дополнительные настройки сборщиков ()):
[[CPUCollector]]
enabled = True
hostname_method = smart
Более сложен внутренний код. За кулисами сервер вызовет метод utils.load_collectors(), используя путь, указанный в collectors_path. Рассмотрим большую часть этой функции (мы сократили ее для удобства).


 Разбиваем строку (первый вызов функции); в противном случае пути являются списками строк, содержащих пути, которые указывают места, где реализованы пользовательские подклассы класса Collector.
Разбиваем строку (первый вызов функции); в противном случае пути являются списками строк, содержащих пути, которые указывают места, где реализованы пользовательские подклассы класса Collector.
 Здесь мы рекурсивно проходим по заданным путям, добавляя каждую папку в sys.path, чтобы далее можно было импортировать подклассы класса Collector.
Здесь мы рекурсивно проходим по заданным путям, добавляя каждую папку в sys.path, чтобы далее можно было импортировать подклассы класса Collector.
 Здесь выполняется рекурсия — метод load_collectors() вызывает сам себя.
Здесь выполняется рекурсия — метод load_collectors() вызывает сам себя.
 После загрузки сборщиков из подкаталогов обновите оригинальный словарь пользовательских сборщиков, добавив туда загруженные сборщики из этих подкаталогов.
После загрузки сборщиков из подкаталогов обновите оригинальный словарь пользовательских сборщиков, добавив туда загруженные сборщики из этих подкаталогов.
 С момента введения Python 3.1 модуль importlib стандартной библиотеки Python является предпочтительным способом сделать это (с помощью модуля importlib.import_module; фрагменты importlib.import_module также были портированы в Python 2.7). Это показывает, как можно программно импортировать модуль, используя строку с его именем.
С момента введения Python 3.1 модуль importlib стандартной библиотеки Python является предпочтительным способом сделать это (с помощью модуля importlib.import_module; фрагменты importlib.import_module также были портированы в Python 2.7). Это показывает, как можно программно импортировать модуль, используя строку с его именем.
 Так можно программно получить доступ к атрибутам модуля, имея лишь строку с именем атрибута.
Так можно программно получить доступ к атрибутам модуля, имея лишь строку с именем атрибута.
 Метод load_dynamic_class здесь можно и не использовать. Он повторно импортирует модуль, проверяет, что названный класс является классом на самом деле, проверяет, что он является подклассом класса Collector, и, если это верно, — возвращает только что загруженный класс. Избыточность часто встречается в исходном коде, который пишут большие группы людей.
Метод load_dynamic_class здесь можно и не использовать. Он повторно импортирует модуль, проверяет, что названный класс является классом на самом деле, проверяет, что он является подклассом класса Collector, и, если это верно, — возвращает только что загруженный класс. Избыточность часто встречается в исходном коде, который пишут большие группы людей.
 Здесь они получают имя класса для дальнейшего использования при применении настроек из файла конфигурации (имея только строку, содержащую имя класса).
Здесь они получают имя класса для дальнейшего использования при применении настроек из файла конфигурации (имея только строку, содержащую имя класса).
Примеры из стиля Diamond
В Diamond вы можете найти отличный пример использования замыкания, который демонстрирует все, о чем мы говорили в пункте «Замыкания с поздним связыванием» подраздела «Распространенные подводные камни» раздела «Стиль кода» главы 4 по поводу того, что такое поведение зачастую весьма желательно.
Пример использования замыкания (когда подводный камень вовсе не подводный камень). Замыкание — это функция, использующая переменные, доступные в локальной области видимости, которые в противном случае будут недоступны при вызове функции. В других языках их, возможно, будет трудно реализовать и понять, но это не относится к Python, поскольку в нем функции обрабатываются так же, как и любые другие объекты. Например, функции могут быть переданы как аргумент, также их можно возвращать из других функций.
Рассмотрим фрагмент кода исполняемого файла diamond, который показывает, как реализовать замыкание в Python.



 Когда мы пропускаем код, отсутствующие части описываем в комментарии, перед которым стоят две тильды (##~~).
Когда мы пропускаем код, отсутствующие части описываем в комментарии, перед которым стоят две тильды (##~~).
 Мы пользуемся файлом PID, чтобы убедиться, что демон уникален (то есть мы не запустили его дважды случайно), а также для быстрого сообщения с другими сценариями при передаче им связанных идентификаторов процессов. Этот файл также нужен для того, чтобы удостовериться, что процесс завершился ненормально (поскольку в этом сценарии файл PID удаляется лишь при нормальном завершении работы).
Мы пользуемся файлом PID, чтобы убедиться, что демон уникален (то есть мы не запустили его дважды случайно), а также для быстрого сообщения с другими сценариями при передаче им связанных идентификаторов процессов. Этот файл также нужен для того, чтобы удостовериться, что процесс завершился ненормально (поскольку в этом сценарии файл PID удаляется лишь при нормальном завершении работы).
 Весь этот код нужен для того, чтобы предоставить контекст, ведущий к замыканию. К этому моменту либо наш процесс запущен как демон (и теперь имеет другой PID), либо мы пропустим эту часть, поскольку правильный PID уже записан в файл.
Весь этот код нужен для того, чтобы предоставить контекст, ведущий к замыканию. К этому моменту либо наш процесс запущен как демон (и теперь имеет другой PID), либо мы пропустим эту часть, поскольку правильный PID уже записан в файл.
 sigint_handler() и есть замыкание. Оно определяется внутри функции main(), а не на высшем уровне, за пределами других функций, поскольку ему нужно знать, искать ли файл PID, и если да — то где.
sigint_handler() и есть замыкание. Оно определяется внутри функции main(), а не на высшем уровне, за пределами других функций, поскольку ему нужно знать, искать ли файл PID, и если да — то где.
 Позволяет получить информацию из параметров командной строки, которую нельзя получить до вызова функции main(). Это означает, что все параметры, связанные с файлом PID, являются локальными переменными пространства имен функции main.
Позволяет получить информацию из параметров командной строки, которую нельзя получить до вызова функции main(). Это означает, что все параметры, связанные с файлом PID, являются локальными переменными пространства имен функции main.
 Замыкание (функция sigint_handler()) отправляется обработчику сигналов; будет использовано для обработки сигналов SIGINT и SIGTERM.
Замыкание (функция sigint_handler()) отправляется обработчику сигналов; будет использовано для обработки сигналов SIGINT и SIGTERM.
Tablib
Tablib — это библиотека Python, которая преобразует данные в различные форматы, сохраняет их в объекте класса Dataset, а несколько объектов типа Datasets — в объекте класса Databook. Объекты класса Dataset хранятся в форматах JSON, YAML, DBF и CSV (файлы в этих форматах можно импортировать), наборы данных могут быть экспортированы в форматах XLSX, XLS, ODS, JSON, YAML, DBF, CSV, TSV и HTML. Библиотека Tablib выпущена Кеннетом Ритцем (Kenneth Reitz) в 2010 году, имеет интуитивный дизайн API, характерный для всех проектов Ритца.
Читаем небольшую библиотеку
Tablib — это библиотека, а не приложение, поэтому не имеет четко определенной точки входа, как в случае с HowDoI и Diamond.
Загрузите Tablib из GitHub:
$ git clone
$ virtualenv -p python3 venv
$ source venv/bin/activate
(venv)$ cd tablib
(venv)$ pip install --editable .
(venv)$ python test_tablib.py # Run the unit tests.
Читаем документацию Tablib
Документация Tablib (/) начинается с упоминания варианта использования, затем в ней более подробно описываются возможности библиотеки: она предоставляет объект типа Dataset, который имеет строки, столбцы и заголовки. Вы можете выполнять операции ввода/вывода из разных форматов для объекта типа Dataset. В разделе, содержащем более сложные варианты использования, говорится, что вы можете добавлять к строкам теги и создавать унаследованные столбцы, которые являются функциями других столбцов.
Используем Tablib
Tablib — это библиотека, а не исполняемый файл, как в случае с HowDoI или Diamond, поэтому вы можете открыть интерактивную сессию Python и использовать функцию help() для исследования API. Рассмотрим пример применения класса tablib.Dataset, разных форматов данных и способа работы I/O:
>>> import tablib
>>> data = tablib.Dataset()
>>> names = ('Black Knight', 'Killer Rabbit')
>>>
>>> for name in names:
... fname, lname = name.split()
... data.append((fname, lname))
...
>>> data.dict
[['Black', 'Knight'], ['Killer', 'Rabbit']]
>>>
>>> print(data.csv)
Black,Knight
Killer,Rabbit
>>> data.headers=('First name', 'Last name')
>>> print(data.yaml)
- {First name: Black, Last name: Knight}
- {First name: Killer, Last name: Rabbit}
>>> with open('tmp.csv', 'w') as outfile:
... outfile.write(data.csv)
...
64
>>> newdata = tablib.Dataset()
>>> newdata.csv = open('tmp.csv').read()
>>> print(newdata.yaml)
- {First name: Black, Last name: Knight}
- {First name: Killer, Last name: Rabbit}
Читаем код библиотеки Tablib
Структура файлов, находящихся в каталоге tablib/, выглядит так:
tablib
|--- __init__.py
|--- compat.py
|--- core.py
|--- formats/
|--- packages/
Каталоги tablib/formats/ и tablib/packages/ рассматриваются в следующих разделах.
Python поддерживает строки документации на уровне модулей, как и строки документации, которые мы уже описали, — строковые литералы, являющиеся первым выражением в функции, классе или методе. На сайте Stack Overflow приведены полезные советы о том, как задокументировать модули ( 57196). Для нас это означает, что существует еще один способ исследовать исходный код — мы можем ввести команду head *.py в терминальной оболочке, находясь на верхнем уровне пакета, чтобы показать все строки документации модуля. Вот что мы увидим для библиотеки Tablib:

Мы узнали следующее.
 API высшего уровня (содержимое файла __init__.py доступно в каталоге tablib после выполнения оператора import tablib) имеет всего девять точек входа: классы Databook и Dataset упоминаются в документации, detect может использоваться для определения форматирования, import_set и import_book должны импортировать данные, а последние три класса — InvalidDatasetType, InvalidDimensions и UnsupportedFormat — выглядят как исключения (если код следует принципам PEP 8, мы можем сказать, какие объекты являются пользовательскими классами на основе их регистра).
API высшего уровня (содержимое файла __init__.py доступно в каталоге tablib после выполнения оператора import tablib) имеет всего девять точек входа: классы Databook и Dataset упоминаются в документации, detect может использоваться для определения форматирования, import_set и import_book должны импортировать данные, а последние три класса — InvalidDatasetType, InvalidDimensions и UnsupportedFormat — выглядят как исключения (если код следует принципам PEP 8, мы можем сказать, какие объекты являются пользовательскими классами на основе их регистра).
 tablib/compat.py — это модуль совместимости. Беглый взгляд на него покажет, что он обрабатывает проблемы совместимости между Python 2 и Python 3 аналогично HowDoI, разрешая разные местоположения и имена к одинаковым символам, которые будут использованы в tablib/core.py.
tablib/compat.py — это модуль совместимости. Беглый взгляд на него покажет, что он обрабатывает проблемы совместимости между Python 2 и Python 3 аналогично HowDoI, разрешая разные местоположения и имена к одинаковым символам, которые будут использованы в tablib/core.py.
 В файле tablib/core.py в соответствии с его именем реализуются объекты Tablib вроде Dataset и Databook.
В файле tablib/core.py в соответствии с его именем реализуются объекты Tablib вроде Dataset и Databook.
| Документация к библиотеке Tablib в формате Sphinx Документация Tablib (/) содержит хороший пример использования Sphinx (), поскольку это маленькая библиотека, которая применяет много расширений для Sphinx. Документация к текущей версии Sphinx находится на странице документации Tablib (/). Если вы хотите построить документацию самостоятельно (пользователям Windows понадобится команда male — она старая, но работает как надо), сделайте следующее: (venv)$ pip install sphinx (venv)$ cd docs (venv)$ make html (venv)$ open _build/html/index.html # Для просмотра результата. Sphinx предоставляет несколько вариантов тем оформления (), которые настраиваются с помощью стандартных шаблонов представления кода и стилей CSS. Шаблоны Tablib для левой боковой панели находятся в каталоге docs/_templates/ в файле basic/layout.html. Вы можете найти этот файл в папке стилей Sphinx, введя в командной строке следующую команду: (venv)$ python -c 'import sphinx.themes;print(sphinx.themes.__path__)' Продвинутые пользователи также могут выполнять поиск в docs/_themes/kr/, пользовательском стиле, который расширяет базовую структуру. Его можно выбрать, добавив каталог _themes/ в системный путь, установив необходимые значения свойствам html_theme_path = ['_themes'] и html_theme = 'kr' в docs/conf.py. Для включения в ваш код документации API, которая генерируется автоматически на основе строк документации, используйте autoclass::. Вам нужно скопировать форматирование строк документации в Tablib, чтобы это сработало: .. autoclass:: Dataset :inherited-members: Для получения этой функциональности следует ответить «да» на вопрос о включении расширения Sphinx autodoc при запуске sphinx-quickstart, чтобы создать новый проект Sphinx. Директива :inherited-members: также добавит документацию для атрибутов, унаследованных от классов-предков. |
Примеры из структуры Tablib
Главная особенность, которую мы хотим подчеркнуть в Tablib, — отсутствие использования классов в модулях в tablib/formats/ (это идеально иллюстрирует наше утверждение, что не нужно везде применять классы). Далее мы приведем фрагменты кода, демонстрирующие использование синтаксиса декоратора в Tablib, а также задействуем класс property () для создания унаследованных атрибутов вроде ширины и высоты набора данных. Помимо этого, покажем, как динамически он регистрирует форматы файлов, чтобы избежать дупликации шаблонного кода для разных типов формата (CSV, YAML и т. д.).
В последних двух подразделах мы рассмотрим, как Tablib использует зависимости, полученные от третьей стороны, а затем обсудим свойство __slots__ объектов нового класса. Вы можете пропустить эти разделы и при этом продолжать жить счастливой питонской жизнью.
Отсутствие ненужного объектно-ориентированного кода в форматах (использование пространств имен для группирующих функций)
Каталог форматов содержит все определенные для ввода/вывода форматы файлов. Имена модулей _csv.py, _tsv.py, _json.py, _yaml.py, _xls.py, _xlsx.py, _ods.py и _xls.py начинаются с нижнего подчеркивания — это указывает пользователю библиотеки, что свойства не предназначены для непосредственного использования. Мы можем перейти в каталог formats и выполнять поиск классов и функций. Команда grep ^class formats/*.py показывает отсутствие определений классов, а команда grep ^def formats/*.py — что каждый модуль содержит одну или несколько следующих функций:
• detect(stream) определяет формат файла, основываясь на содержимом потока;
• dset_sheet(dataset, ws) форматирует клетки для таблиц Excel;
• export_set(dataset) экспортирует набор данных в заданный формат, возвращая отформатированную строку в новом формате (для Excel возвращает объект bytes или бинарную строку в Python 2);
• import_set(dset, in_stream, headers=True) заменяет содержимое набора данных содержимым входного потока;
• export_book(databook) экспортирует объекты Datasheet в Databook в заданном формате, возвращая объект типа string или bytes;
• import_book(dbook, in_stream, headers=True) заменяет содержимое databook содержимым входного потока.
Это примеры применения модулей как пространств имен (в конце концов, они же являются отличной штукой) для разделения функций вместо того, чтобы использовать ненужные классы. Мы узнаем предназначение каждой функции по ее имени, например formats._csv.import_set(), formats._tsv.import_set() и formats._json.import_set() импортируют наборы данных из файлов в формате CSV, TSV и JSON соответственно. Другие функции отвечают за экспорт данных и определение формата файла (где это возможно) для каждого доступного Tablib формата.
Дескрипторы и декораторы свойств (используйте неизменяемость, когда это идет на пользу API)
Tablib — наша первая библиотека, в которой используется синтаксис декораторов Python, описанный в подразделе «Декораторы» раздела «Структурируем проект» главы 4. Синтаксисом предусмотрено указывать символ @ перед именем функции, вся конструкция размещается над другой функцией. Декоратор изменяет (или декорирует) функцию, которая находится под ним. В следующем фрагменте кода свойство изменяет функции Dataset.height и Dataset.width, делая их дескрипторами — классами, в которых определен хотя бы один из следующих методов: __get__(), __set__() или __delete__() (геттер, сеттер и метод удаления). Например, поиск атрибута Dataset.height приведет к срабатыванию функции-геттера, сеттера или удаления в зависимости от контекста применения атрибута. Такое поведение присуще только новым классам (их мы вскоре обсудим). Для получения более подробной информации о дескрипторах обратитесь к довольно полезному руководству по Python по адресу .

 Именно так используется декоратор. В данном случае свойство изменяет Dataset.height, чтобы оно вело себя как свойство, а не как связанный метод. Он может работать только с методами классов.
Именно так используется декоратор. В данном случае свойство изменяет Dataset.height, чтобы оно вело себя как свойство, а не как связанный метод. Он может работать только с методами классов.
 Когда свойство применяется как декоратор, атрибут height вернет высоту Dataset, но вы не можете задать высоту множества данных, вызвав Dataset.height.
Когда свойство применяется как декоратор, атрибут height вернет высоту Dataset, но вы не можете задать высоту множества данных, вызвав Dataset.height.
Так выглядят атрибуты height и width при использовании:
>>> import tablib
>>> data = tablib.Dataset()
>>> data.header = ("amount", "ingredient")
>>> data.append(("2 cubes", "Arcturan Mega-gin"))
>>> data.width
2
>>> data.height
1
>>>
>>> data.height = 3
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: can't set attribute
Доступ к data.height можно получить так же, как и к любому другому атрибуту, но изменить его значение вы не можете — оно высчитывается на основе данных и всегда актуально. Такой дизайн API весьма эргономичен: конструкцию data.height проще ввести на клавиатуре, чем data.get_height(); понятно, что означает data.height. Поскольку значение этого свойства выводится на основе данных (значение свойства нельзя задать, для него определена только функция-геттер), можно не переживать, что значение свойства рассинхронизируется с реальными данными.
Декоратор свойства можно применить только к атрибутам классов и только к тем классам, которые наследуют от base object object (например, class MyClass(object), а не class MyClass() — в Python 3 всегда выполняется наследование от объекта).
Один и тот же инструмент используется при создании API для импорта и экспорта данных в Tablib для разных форматов (Tablib не хранит строку для каждого формата). Вместо этого применяются Dataset-атрибуты csv, json и yaml, они похожи на свойства Dataset.height и Dataset.width, показанные в предыдущем примере: вызывают функцию, которая генерирует результат из сохраненных данных или преобразует входной формат и затем заменяет основные данные. Но существует только один набор данных.
Когда свойство data.csv находится с левой стороны знака «равно», вызывается функция-сеттер для этого свойства, которая преобразует dataset из формата CSV. Когда свойство data.yaml находится с правой стороны знака «равно» или стоит отдельно, вызывается функция-геттер для создания строки в заданном формате на основе внутреннего набора данных. Рассмотрим пример.

 Свойство data.csv, которое стоит с левой стороны от знака «равно» (оператора присваивания), вызывает функцию formats.csv.import_set(), передавая data в качестве первого аргумента, и строку, содержащую ингредиенты Пангалактического Грызлодера, в качестве второго аргумента.
Свойство data.csv, которое стоит с левой стороны от знака «равно» (оператора присваивания), вызывает функцию formats.csv.import_set(), передавая data в качестве первого аргумента, и строку, содержащую ингредиенты Пангалактического Грызлодера, в качестве второго аргумента.
 Свойство data.yaml, стоящее отдельно, вызывает функцию formats.yaml.export_set(), передавая data в качестве аргумента, выводя строку в формате YAML для функции print().
Свойство data.yaml, стоящее отдельно, вызывает функцию formats.yaml.export_set(), передавая data в качестве аргумента, выводя строку в формате YAML для функции print().
Функции для получения, установки и удаления данных могут быть привязаны к единому атрибуту с помощью property. Его сигнатура выглядит так: property(fget=None, fset=None, fdel=None, doc=None), fget определяет функцию-геттер (formats.csv.import_set()), fset — функцию-сеттер (formats.csv.export_set()), а fdel — функцию удаления данных (оставлена пустой). Далее мы увидим код, в котором программно устанавливаются свойства форматирования.
Форматы файлов, зарегистрированные программно (не повторяйте дома)
Tablib помещает все подпрограммы для форматирования в подпакет formats. Это делает чище основной модуль core.py — и целый пакет становится модульным; добавлять новые форматы файлов будет нетрудно. Несмотря на то что можно копировать фрагменты практически идентичного кода и импортировать поведение при импорте и экспорте для каждого формата отдельно, все форматы программно загружаются в свойства, названные в честь каждого формата, в класс Dataset.
В следующем примере кода мы выводим все содержимое файла formats/__init__.py, поскольку файл не так велик и мы хотим показать, как определяется formats.available.

 В этой строке интерпретатору Python явно указывается, что файл имеет кодировку UTF-8.
В этой строке интерпретатору Python явно указывается, что файл имеет кодировку UTF-8.
 Определение formats.available находится в файле formats/__init__.py. Его также можно получить с помощью функции dir(tablib.formats), но приведенный выше список более прост для восприятия.
Определение formats.available находится в файле formats/__init__.py. Его также можно получить с помощью функции dir(tablib.formats), но приведенный выше список более прост для восприятия.
В файле core.py вместо примерно 20 (безобразных и сложных для поддержки) повторяющихся описаний функции для каждого формата код импортирует каждый формат программно, вызывая функцию self._register_formats() в конце метода __init__() класса Dataset. Рассмотрим фрагмент кода, в котором приводится метод Dataset._register_formats().


 Символ @classmethod является декоратором (они подробно описаны в подразделе «Декораторы» подраздела «Структурируем проект» главы 4). Декоратор модифицирует метод _register_formats() таким образом, что он начинает передавать в качестве первого аргумента класс объекта (Dataset), а не его экземпляр (self).
Символ @classmethod является декоратором (они подробно описаны в подразделе «Декораторы» подраздела «Структурируем проект» главы 4). Декоратор модифицирует метод _register_formats() таким образом, что он начинает передавать в качестве первого аргумента класс объекта (Dataset), а не его экземпляр (self).
 Параметр formats.available определен в файле formats/__init__.py и содержит все доступные форматы.
Параметр formats.available определен в файле formats/__init__.py и содержит все доступные форматы.
 В этой строке setattr присваивает значение атрибуту с именем fmt.title (то есть Dataset.csv или Dataset.xls). Это значение особенное: функция property(fmt.export_set, fmt.import_set) превращает Dataset.csv в свойство.
В этой строке setattr присваивает значение атрибуту с именем fmt.title (то есть Dataset.csv или Dataset.xls). Это значение особенное: функция property(fmt.export_set, fmt.import_set) превращает Dataset.csv в свойство.
 Если свойство fmt.import_set не будет определено, возникнет исключение AttributeError.
Если свойство fmt.import_set не будет определено, возникнет исключение AttributeError.
 Если функции импорта нет, попробуйте присвоить лишь поведение экспорта.
Если функции импорта нет, попробуйте присвоить лишь поведение экспорта.
 Если нет ни функции импорта, ни функции экспорта, не присваивайте ничего.
Если нет ни функции импорта, ни функции экспорта, не присваивайте ничего.
 Каждый из форматов файлов определен здесь как свойство, имеет описательную строку документации. Строка документации будет сохранена, когда функция property() будет вызвана в точке
Каждый из форматов файлов определен здесь как свойство, имеет описательную строку документации. Строка документации будет сохранена, когда функция property() будет вызвана в точке  или
или  для присвоения дополнительного поведения.
для присвоения дополнительного поведения.
 \t и \n — управляющие последовательности, которые представляют собой, соответственно, символ табуляции и новую строку. Все они перечислены в документации к строковым литералам Python ().
\t и \n — управляющие последовательности, которые представляют собой, соответственно, символ табуляции и новую строку. Все они перечислены в документации к строковым литералам Python ().
| Но мы все — ответственные пользователи Эти способы использования декоратора @property не похожи на способы применения аналогичных инструментов в Java, цель которых состоит в том, чтобы управлять доступом пользователей к данным. Это идет вразрез с философией Python, которая гласит, что мы все — ответственные пользователи. Цель применения декоратора @property — отделение данных от функций просмотра, связанных с данными (в этом случае с высотой, шириной и разными форматами хранения). В ситуации, когда геттеры и сеттеры не нужны для предобработки или постобработки, более питонским вариантом поведения будет присвоение данных обычному атрибуту и разрешение пользователю взаимодействовать с ними. |
Зависимости, полученные от третьей стороны, в пакетах (пример их использования)
Зависимости Tablib в данный момент поставляются с кодом — в каталоге packages, но могут в будущем быть перемещены в систему надстроек. Каталог packages содержит сторонние пакеты, используемые внутри Tablib, чтобы гарантировать совместимость; другой вариант — указание версий в файле setup.py, который будет загружен и установлен в момент установки Tablib. Этот прием рассматривается в разделе «Зависимости, получаемые от третьей стороны» раздела «Структурируем проект» главы 4. Для Tablib был выбран вариант поведения, позволяющий снизить количество зависимостей, который нужно загружать пользователям, и поскольку иногда для Python 2 и Python 3 требуются разные пакеты, в этом случае включаются оба пакета. (Соответствующий пакет импортируется, функции вызываются с помощью их обычного имени в файле tablib/compat.py.) Таким образом, Tablib может иметь одну базу кода вместо двух — по одной для каждой версии Python. Раз каждая из зависимостей имеет собственную лицензию, на верхний уровень каталога проекта был добавлен документ NOTICE, в котором перечисляются лицензии каждой зависимости.
Экономим память с помощью свойства __slots__ (оптимизируйте c осторожностью)
Скорости Python предпочитает читаемость. Его дизайн, афоризмы, из которых состоит его дзен, и раннее влияние, которое на него оказали языки вроде ABC (), — все это заставляет ставить дружелюбие к пользователю над производительностью (более подробно об оптимизации мы поговорим в разделе «Скорость» главы 8).
Использование свойства __slots__ в Tablib — этот тот случай, когда оптимизация имеет значение. Данная ссылка выглядит несколько странно, она доступна только для новых классов (они описаны через несколько страниц), но мы хотим показать, что при необходимости вы можете оптимизировать Python.
Подобная оптимизация полезна только в том случае, если у вас имеется много небольших объектов, поскольку она сократит отпечаток каждого объекта класса на размер одного словаря (крупные объекты сделают такую небольшую экономию нерелевантной, а для малого количества объектов такая экономия не стоит затраченных усилий).
Рассмотрим фрагмент из документации __slots__ ().
По умолчанию объекты классов имеют словарь для хранения атрибутов. Он занимает слишком много места, если объекты имеют малое количество переменных объекта. Использование места может стать особенно заметным при создании большого количества объектов.
Ситуацию можно изменить путем объявления __slots__ в описании класса. Объявление __slots__ принимает последовательность переменных объекта и резервирует достаточный объем памяти для каждой переменной. Место экономится, поскольку для каждой переменной теперь не создается __dict__.
Обычно вам не следует об этом беспокоиться: обратите внимание, что свойство __slots__ не появляется в классах Dataset или Databook — только в классе Row, но поскольку рядов данных может быть очень много, использование __slots__ выглядит хорошим решением. Класс Row не показан в tablib/__init__.py, поскольку является вспомогательным классом для класса Dataset, для каждой строки создается один объект такого класса.
Рассмотрим, как выглядит определение __slots__ в самом начале определения класса Row:
class Row(object):
"""Внутренний объект Row. Используется в основном для фильтрации."""
__slots__ = ['_row', 'tags']
def __init__(self, row=list(), tags=list()):
self._row = list(row)
self.tags = list(tags)
#
# ... и т.д. ...
#
Проблема в том, что больше не существует атрибута __dict__, в котором хранятся объекты класса Row, но функция pickle.dump() (вызывается для сериализации объектов) по умолчанию использует __dict__ для сериализации объектов, если только не определен метод __getstate__(). Аналогично во время десериализации (процесса, который читает сериализованные байты и восстанавливает объект в памяти), если метод __setstate__() не определен, метод pickle.load() загружает данные в атрибут объекта __dict__. Рассмотрим, как это обойти.
class Row(object):
#
# ... пропускаем другие определения ...
#
def __getstate__(self):
slots = dict()
for slot in self.__slots__:
attribute = getattr(self, slot)
slots[slot] = attribute
return slots
def __setstate__(self, state):
for (k, v) in list(state.items()):
setattr(self, k, v)
Для получения более подробной информации о методах __getstate__() и __setstate__() и сериализации обратитесь к документации __getstate__ ().
Примеры из стиля Tablib
Мы подготовили лишь один пример использования стиля в Tablib — перегрузка операторов (это позволяет рассмотреть детали модели данных Python). Настройка поведения ваших классов позволит разработчикам, использующим ваш API, писать хороший код.
Перегрузка операторов (красивое лучше, чем уродливое). В этом фрагменте кода приводится перегрузка операторов Python, чтобы выполнять операции для строк или столбцов набора данных. В первом фрагменте кода показывается интерактивное применение квадратных скобок [ ] как для численных индексов, так и для имен столбцов, а во втором — код, который использует это поведение.
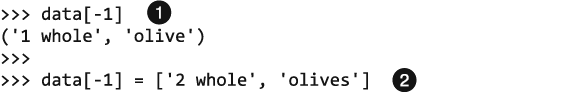

 Если вы указываете в квадратных скобках числа, этот оператор вернет строку, которая находится в заданной позиции.
Если вы указываете в квадратных скобках числа, этот оператор вернет строку, которая находится в заданной позиции.
 Благодаря этому оператору присваивания с квадратными скобками…
Благодаря этому оператору присваивания с квадратными скобками…
 … вместо исходной одной оливки у вас становится две.
… вместо исходной одной оливки у вас становится две.
 Здесь выполняется удаление с помощью вырезки — 2:7 указывает на числа 2, 3, 4, 5, 6, но не 7.
Здесь выполняется удаление с помощью вырезки — 2:7 указывает на числа 2, 3, 4, 5, 6, но не 7.
 Взгляните, насколько сокращается рецепт после выполнения.
Взгляните, насколько сокращается рецепт после выполнения.
 Вы также можете получить доступ к столбцам с помощью имени.
Вы также можете получить доступ к столбцам с помощью имени.
В части кода класса Dataset, которая определяет поведение оператора «квадратные скобки», показывается, как обрабатывать доступ по имени столбца и номеру строки.


 Во-первых, проверим, что именно мы ищем — столбец (True, если key является строкой) или строку (True, если key является числом или вырезкой).
Во-первых, проверим, что именно мы ищем — столбец (True, если key является строкой) или строку (True, если key является числом или вырезкой).
 Этот код проверяет наличие ключа в self.headers и затем…
Этот код проверяет наличие ключа в self.headers и затем…
 …явно вызывает исключение KeyError, поэтому, если вы получаете доступ по имени столбца, поведение будет таким же, как и у словаря. Весь блок if/else необязателен для работы функции — если его опустить, исключение ValueError будет сгенерировано функцией self.headers.index(key) в том случае, если ключа нет в self.headers. Единственным его предназначением является предоставление пользователю библиотеки более информативной ошибки.
…явно вызывает исключение KeyError, поэтому, если вы получаете доступ по имени столбца, поведение будет таким же, как и у словаря. Весь блок if/else необязателен для работы функции — если его опустить, исключение ValueError будет сгенерировано функцией self.headers.index(key) в том случае, если ключа нет в self.headers. Единственным его предназначением является предоставление пользователю библиотеки более информативной ошибки.
 Здесь определяется, чем является ключ — числом или вырезкой (вроде 2:7). Если вырезкой, _results будет списком, а не объектом класса Row.
Здесь определяется, чем является ключ — числом или вырезкой (вроде 2:7). Если вырезкой, _results будет списком, а не объектом класса Row.
 Здесь обрабатывается вырезка. Поскольку строки возвращаются как кортежи, значения представляют собой неизменяемые копии реальных данных — и данные из набора (которые хранятся в списках) не будут случайно повреждены в результате присваивания.
Здесь обрабатывается вырезка. Поскольку строки возвращаются как кортежи, значения представляют собой неизменяемые копии реальных данных — и данные из набора (которые хранятся в списках) не будут случайно повреждены в результате присваивания.
 Метод __setitem__() может изменить одну строку, но не столбец. Это сделано намеренно, так как не существует способа изменить содержимое всего столбца; с точки зрения целостности данных такое решение не самый плохой выбор. Пользователь всегда может преобразовать столбец и внедрить его в любую позицию с помощью одного из методов insert_col(), lpush_col() или rpush_col().
Метод __setitem__() может изменить одну строку, но не столбец. Это сделано намеренно, так как не существует способа изменить содержимое всего столбца; с точки зрения целостности данных такое решение не самый плохой выбор. Пользователь всегда может преобразовать столбец и внедрить его в любую позицию с помощью одного из методов insert_col(), lpush_col() или rpush_col().
 Метод __delitem__() удалит столбец или строку, используя ту же логику, что и метод __getitem__().
Метод __delitem__() удалит столбец или строку, используя ту же логику, что и метод __getitem__().
Для получения более подробной информации о перегрузке операторов и других особых методах смотрите документацию Python о специальных именах методов ().
Requests
В День святого Валентина в 2011 году Кеннет Ритц (Kenneth Reitz) опубликовал «любовное письмо», адресованное сообществу Python, — библиотеку Requests. Она была воспринята с большим энтузиазмом благодаря интуитивно понятному дизайну API (это значит, что API настолько прост и понятен, что вам почти не нужна документация для того, чтобы им пользоваться).
Читаем более крупную библиотеку
Библиотека Requests намного крупнее библиотеки Tablib и имеет множество модулей. Однако мы подходим к вопросу ее прочтения точно так же — просмотрим документацию и будем следовать API в коде.
Загрузите Requests из GitHub:
$ git clone
$ virtualenv -p python3 venv
$ source venv/bin/activate
(venv)$ cd requests
(venv)$ pip install --editable .
(venv)$ pip install -r requirements.txt # Required for unit tests
(venv)$ py.test tests # Run the unit tests.
Некоторые тесты могут дать сбой. Например, если ваш интернет-провайдер перехватывает ошибку 404 для того, чтобы показать вам какую-нибудь рекламу, вы не сможете сгенерировать исключение ConnectionError.
Читаем документацию библиотеки Requests
Библиотека Requests находится в гораздо более крупном пакете, поэтому сначала просмотрите лишь заголовки разделов в документации к Requests (/). Requests расширяет библиотеки urrlib и , которые вы можете найти в стандартной библиотеке Python, предоставляя методы, выполняющие запросы HTTP. Библиотека предусматривает поддержку международных доменов и URL, автоматическую декомпрессию, автоматическое декодирование содержимого, проверку сертификатов SSL, поддержку прокси для HTTP(S) и другую функциональность, определенную стандартами Internet Engineering Task Force (IETF) для HTTP с помощью запросов комментария (requests for comment, RFC) 7230-7235.
Библиотека Requests стремится покрыть все спецификации HTTP от IETF, задействуя всего несколько функций, набор аргументов с ключевым словом и несколько классов.
Используем Requests
Как и в случае Tablib, в строках документации содержится достаточно информации для того, чтобы использовать Requests, не обращаясь к документации, размещенной онлайн. Рассмотрим следующий пример:
>>> import requests
>>> help(requests) # Показывает руководство по использованию
# и указывает искать 'requests.api'
>>> help(requests.api) # Показывает подробное описание API
>>>
>>> result = requests.get('')
>>> result.status_code
200
>>> result.ok
True
>>> result.text[:42]
'{\n "info": {\n "maintainer": null'
>>>
>>> result.json().keys()
dict_keys(['info', 'releases', 'urls'])
>>>
>>> result.json()['info']['summary']
'Python HTTP for Humans.'
Читаем код Requests
Рассмотрим содержимое пакета Requests.

 cacert.pem — стандартный набор сертификатов, который используется при проверке сертификатов SSL.
cacert.pem — стандартный набор сертификатов, который используется при проверке сертификатов SSL.
 Requests имеет простую структуру, за исключением каталога packages, хранящего сторонние зависимости chardet и urllib3. Они импортируются как requests.packages.chardet и requests.packages.urllib3, поэтому программисты все еще могут получить доступ к chardet и urllib3 из стандартной библиотеки.
Requests имеет простую структуру, за исключением каталога packages, хранящего сторонние зависимости chardet и urllib3. Они импортируются как requests.packages.chardet и requests.packages.urllib3, поэтому программисты все еще могут получить доступ к chardet и urllib3 из стандартной библиотеки.
Мы можем разобраться в происходящем благодаря удачно выбранным именам модулей, но если нужно больше информации, просмотрите строки документации модуля, введя head *.py в каталоге верхнего уровня. В следующем списке эти строки документации приводятся в сокращенном виде (не показывается compat.py). Исходя из его имени (он назван так же, как и аналогичный файл библиотеки Reitz’s Tablib, мы можем сделать вывод, что он отвечает за совместимость между Python 2 и Python 3).
• api.py — реализует Requests API.
• hooks.py — предоставляет возможность использовать систему функций перехвата Requests.
• models.py — содержит основные объекты, которыми пользуется Requests.
• sessions.py — предоставляет объект Session для управления настройками и их сохранения между запросами (cookies, авторизация, прокси).
• auth.py — содержит дескрипторы для аутентификации в Requests.
• status_codes.py — таблица, в которой соотносятся заголовки состояний и их коды.
• cookies.py — код для совместимости, который позволяет использовать cookielib.CookieJar с запросами.
• adapters.py — содержит транспортные адаптеры, которые Requests применяет для определения и поддержания соединений.
• exceptions.py — все исключения Requests.
• structures.py — структуры данных, которыми пользуется Requests.
• certs.py — возвращает предпочтительный набор сертификатов CA по умолчанию, в котором перечислены доверенные сертификаты SSL.
• utils.py — предоставляет вспомогательные функции, которые используются внутри Requests и могут применяться внешними пользователями.
Что мы узнали из заголовков:
• существует система функций перехвата (hooks.py) — это подразумевает, что пользователь может модифицировать способ работы библиотеки Requests. Мы не будем обсуждать этот вопрос подробно, чтобы не отвлекаться от темы;
• основным модулем является models.py, поскольку в нем содержатся «основные объекты, которыми пользуется Requests»;
• основная причина существования sessions.Session — сохранение cookies между несколькими запросами (например, это может понадобиться во время аутентификации);
• соединение HTTP создается с помощью объектов из модуля adapters.py;
• остальная часть проекта довольно очевидна: auth.py нужен для аутентификации, status_codes.py содержит коды состояний, cookies.py нужен для добавления и удаления cookies, exceptions.py — для исключений, structures.py содержит структуры данных (например, не зависящий от регистра словарь), utils.py — вспомогательные функции.
Идея поместить модуль коммуникации в отдельный файл adapters.py инновационна (во всяком случае для этого разработчика). Это означает, что models.Request, models.PreparedRequest и models.Response на самом деле ничего не делают — просто сохраняют данные, возможно несколько изменяя их в угоду представлению, сериализации или кодировке. Действия обрабатываются отдельными классами, которые существуют только для того, чтобы выполнить, например, аутентификацию или коммуникацию. Каждый класс делает что-то одно, и каждый модуль содержит классы, выполняющие похожие задачи, — в этом и проявляется питонский подход, который многие из нас используют для определений функций.
| Строки документации Requests, совместимые со Sphinx Если вы начинаете новый проект и используете Sphinx и его расширения autodoc, вам нужно отформатировать строки документации таким образом, чтобы Sphinx смог проанализировать их. В документации Sphinx не всегда получится легко найти нужные ключевые слова. Многие рекомендуют копировать строки документации в Requests, если вы хотите, чтобы формат был правильным, а не искать инструкции в документации Sphinx. Например, рассмотрим определение функции delete() в файле requests/api.py: def delete(url, **kwargs): """Отправляет запрос DELETE. :param url: URL для нового объекта :class:'Request'. :param \*\*kwargs: Необязательные аргументы, которые принимает ''request''. :return: объект класса :class:'Response <Response>' :rtype: requests.Response """ return request('delete', url, **kwargs) Представление этого определения в Sphinx autodoc находится в онлайн-документации к API (). |
Примеры из структуры Requests
Все любят API Requests — его просто запомнить, он помогает пользователям писать простой и красивый код. В этом разделе сначала рассматривается предпочтительный дизайн для более полных сообщений об ошибках и запоминающийся API, который, как мы думаем, привел к созданию модуля requests.api. Затем мы рассмотрим разницу между объектами requests.Request и urllib.request.Request и расскажем, для чего существует объект requests.Request.
Высокоуровневый API (очевидный способ решить задачу, желательно единственный)
Функции, определенные в файле api.py (за исключением request()), названы в честь методов запросов HTTP. Все методы запроса практически одинаковы, за исключением имени метода и возможных параметров с ключевыми словами, поэтому мы удалим из этого фрагмента весь код, расположенный в файле requests/api.py после функции get().


 Функция request() содержит в своей сигнатуре **kwargs. Это означает, что дополнительные аргументы с ключевым словом не сгенерируют исключение, также это скрывает параметры от пользователя.
Функция request() содержит в своей сигнатуре **kwargs. Это означает, что дополнительные аргументы с ключевым словом не сгенерируют исключение, также это скрывает параметры от пользователя.
 В документации, опущенной в этом фрагменте для краткости, описывается каждый аргумент с ключевым словом, с которым связано действие. Использование **kwargs из сигнатуры вашей функции — единственный способ для пользователя сказать, каким должно быть содержимое **kwargs, не заглядывая в код.
В документации, опущенной в этом фрагменте для краткости, описывается каждый аргумент с ключевым словом, с которым связано действие. Использование **kwargs из сигнатуры вашей функции — единственный способ для пользователя сказать, каким должно быть содержимое **kwargs, не заглядывая в код.
 С помощью оператора with Python поддерживает контекст времени выполнения. Оно может быть использовано для любого объекта, для которого определены методы __enter__() и __exit__(). Метод __enter()__ будет вызван при входе в оператор with, а __exit__() — при выходе, независимо от того, завершился оператор нормально или сгенерировал исключение.
С помощью оператора with Python поддерживает контекст времени выполнения. Оно может быть использовано для любого объекта, для которого определены методы __enter__() и __exit__(). Метод __enter()__ будет вызван при входе в оператор with, а __exit__() — при выходе, независимо от того, завершился оператор нормально или сгенерировал исключение.
 Функция get() получает ключевое слово params=None, применяя значение по умолчанию None. Аргумент с ключевым словом params важен для get, поскольку будет использоваться в строке запроса HTTP. Предоставление отдельных аргументов с ключевым словом дает гибкость действий опытным пользователям (благодаря оставшимся **kwargs), упрощая работу для 99 % людей, которым это не нужно.
Функция get() получает ключевое слово params=None, применяя значение по умолчанию None. Аргумент с ключевым словом params важен для get, поскольку будет использоваться в строке запроса HTTP. Предоставление отдельных аргументов с ключевым словом дает гибкость действий опытным пользователям (благодаря оставшимся **kwargs), упрощая работу для 99 % людей, которым это не нужно.
 По умолчанию функция request() не разрешает перенаправление, поэтому на этом шаге устанавливается значение True, если пользователь не сделал этого заранее.
По умолчанию функция request() не разрешает перенаправление, поэтому на этом шаге устанавливается значение True, если пользователь не сделал этого заранее.
 Функция get() вызывает функцию request(), передавая в качестве первого параметра get. Создание функции get имеет два преимущества перед использованием строкового аргумента вроде request("get", ...). Во-первых, даже без документации становится очевидно, какие методы HTTP доступны в этом API. Во-вторых, если пользователь сделает опечатку в имени метода, исключение NameError будет сгенерировано быстрее, и, возможно, его будет проще отследить, чем если бы оно было сгенерировано более глубоко в коде.
Функция get() вызывает функцию request(), передавая в качестве первого параметра get. Создание функции get имеет два преимущества перед использованием строкового аргумента вроде request("get", ...). Во-первых, даже без документации становится очевидно, какие методы HTTP доступны в этом API. Во-вторых, если пользователь сделает опечатку в имени метода, исключение NameError будет сгенерировано быстрее, и, возможно, его будет проще отследить, чем если бы оно было сгенерировано более глубоко в коде.
В файле requests/api.py нет новой функциональности; она существует для того, чтобы предоставить пользователю простой API. Плюс размещение строковых методов HTTP непосредственно в API в качестве имен функций означает, что любая опечатка в имени метода будет найдена на ранних этапах, например:
>>> requests.foo('')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'module' object has no attribute 'foo'
>>>
>>> requests.request('foo', '')
<Response [403]>
Объекты класса Request и PreparedRequest (мы все — ответственные пользователи)
Файл __init__.py предоставляет классы Request, PreparedRequest и Response из файла models.py как часть основного API. Зачем вообще нужен файл models.Request? В стандартной библиотеке уже существует urllib.requests.Request, и в файле cookies.py находится объект MockRequest, который оборачивает models.Request, чтобы он работал как urllib.requests.Request для . Это означает, что любые методы, необходимые для взаимодействия объекта типа Request с библиотекой cookies, намеренно исключены из requests.Request. Для чего эти лишние усилия?
Дополнительные методы в MockRequest (нужен для эмуляции urllib.request.Request для библиотеки cookies) используются библиотекой cookies для управления cookies. За исключением функции get_type() (которая обычно возвращает или при использовании) и непроверяемого свойства (в нашем случае True), они связаны с URL или заголовками запросов.
Связанные с заголовками:
• add_unredirected_header() — добавить в заголовок новую пару ключ-значение;
• get_header() — получить определенное имя из словаря заголовков;
• get_new_headers() — получить словарь, содержащий новые заголовки (которые добавлены с помощью cookielib);
• has_header() — проверяем, существует ли имя в словаре заголовков.
Связанные с URL:
• get_full_url() — соответствует своему имени;
• host и origin_req_host — свойства, чьи значения устанавливаются путем вызова методов get_host() и get_origin_req_host() соответственно;
• get_host() — извлекает хост из URL (например, из /);
• get_origin_req_host() — вызывает get_host().
Все они являются функциями доступа, за исключением MockRequest.add_unredirected_header().
В строке документации к объекту MockRequest указывается, что «оригинальный объект запроса доступен только для чтения».
В requests.Request вместо этого непосредственно доступны атрибуты данных. Это делает все функции доступа ненужными: для получения или установки заголовков требуется лишь получить доступ к словарю request-instance.headers. Аналогично пользователь может получить или изменить строку URL: request-instance.url.
Объект PreparedRequest инициализируется пустым и заполняется при вызове метода prepared-request-instance.prepare(), что наполняет его релевантными данными (обычно получаемыми путем вызова объекта Request). В этот момент применяются исправления регистра символов, кодировки и пр. Содержимое объекта после подготовки можно будет отправить на сервер, но к каждому атрибуту все еще можно получить доступ непосредственно. Доступен даже PreparedRequest._cookies, однако нижнее подчеркивание, с которого начинается это имя, намекает на то, что атрибут не предназначен для использования за пределами класса, не запрещая при этом доступ (мы все — ответственные пользователи).
Этот выбор позволяет пользователю изменять объекты, но они становятся гораздо читабельнее, а дополнительная работа, выполняемая внутри PreparedRequest, позволяет исправить проблемы с регистром и использовать словарь вместо CookieJar (ищите оператор if isinstance()/else):
#
# ... из файла models.py ...
#
class PreparedRequest():
#
# ...пропускаем все остальное...
#
def prepare_cookies(self, cookies):
"""Подготавливает данные заданного HTTP cookie.
Эта функция в итоге генерирует заголовок ''Cookie'' на основе
предоставленных cookies с использованием cookielib. Из-за особенностей
дизайна cookielib заголовок не будет сгенерирован повторно,
если он уже существует. Это значит, что эта функция может быть
вызвана всего один раз во время жизни объекта
:class:'PreparedRequest <PreparedRequest>'. Любые последующие вызовы
''prepare_cookies'' не возымеют эффекта, если только заголовок "Cookie"
не будет удален заранее."""
if isinstance(cookies, cookielib.CookieJar):
self._cookies = cookies
else:
self._cookies = cookiejar_from_dict(cookies)
cookie_header = get_cookie_header(self._cookies, self)
if cookie_header is not None:
self.headers['Cookie'] = cookie_header
Эти детали могут показаться незначительными, но они позволяют создать интуитивно понятный API.
Примеры из стиля Requests
Примеры стиля из Requests демонстрируют использование множеств (по нашему мнению, о них незаслуженно забывают!), мы также взглянем на модуль requests.status_codes module — он задействуется для упрощения стиля остального кода и позволяет избежать применения жестко закодированных кодов состояния HTTP в остальных местах.
Множества и их арифметика (отличная питонская идиома)
Мы еще не приводили пример использования множеств в Python. Множества в Python ведут себя так же, как и множества в математике: вы можете выполнить операции вычитания, объединения (с помощью оператора ИЛИ) и пересечения (с помощью оператора И):
>>> s1 = set((7,6))
>>> s2 = set((8,7))
>>> s1
{6, 7}
>>> s2
{8, 7}
>>> s1 - s2 # разность множеств
{6}
>>> s1 | s2 # объединение множеств
{8, 6, 7}
>>> s1 & s2 # пересечение множеств
{7}
Рассмотрим пример работы с множествами, вы можете найти его в конце этой функции из файла cookies.py (рядом с пометкой  ):
):

 Спецификация **kwargs позволяет пользователю предоставить любой параметр с ключевым словом для cookie (или не предоставлять их вовсе).
Спецификация **kwargs позволяет пользователю предоставить любой параметр с ключевым словом для cookie (или не предоставлять их вовсе).
 Арифметика множеств! Питонская. Простая. Доступная в стандартной библиотеке. Для словаря функция set() формирует множество ключей.
Арифметика множеств! Питонская. Простая. Доступная в стандартной библиотеке. Для словаря функция set() формирует множество ключей.
 Это отличный пример того, что разбиение длинной строки на две короткие более разумно. Дополнительная переменная err не нанесла никакого вреда.
Это отличный пример того, что разбиение длинной строки на две короткие более разумно. Дополнительная переменная err не нанесла никакого вреда.
 Вызов result.update(kwargs) обновляет словарь result парами ключ/значение, содержащимися в словаре kwargs, заменяя существующие пары или создавая те пары, которых не было.
Вызов result.update(kwargs) обновляет словарь result парами ключ/значение, содержащимися в словаре kwargs, заменяя существующие пары или создавая те пары, которых не было.
 Здесь вызов метода bool() возвращает значение True, если объект верен (это значит, что его значение оценивается как True — в данном случае вызов bool(result['port']) оценивается как True, если значение не равно None и не является пустым контейнером).
Здесь вызов метода bool() возвращает значение True, если объект верен (это значит, что его значение оценивается как True — в данном случае вызов bool(result['port']) оценивается как True, если значение не равно None и не является пустым контейнером).
 Сигнатура для инициализации cookielib.Cookie представляет собой набор из 18 позиционных аргументов и одного аргумента с ключевым словом (rfc2109 по умолчанию считается равным False). Нам, как среднестатистическим пользователям, невозможно запомнить все значения и их позиции, поэтому Requests позволяет присваивать значения позиционным аргументам, основываясь на их имени, как в случае аргументов с ключевым словом, отправляя целый словарь.
Сигнатура для инициализации cookielib.Cookie представляет собой набор из 18 позиционных аргументов и одного аргумента с ключевым словом (rfc2109 по умолчанию считается равным False). Нам, как среднестатистическим пользователям, невозможно запомнить все значения и их позиции, поэтому Requests позволяет присваивать значения позиционным аргументам, основываясь на их имени, как в случае аргументов с ключевым словом, отправляя целый словарь.
Коды состояний (читаемость имеет значение)
Файл status_codes.py нужен только для того, чтобы создать объект, который может искать коды состояний по атрибуту. Мы сначала покажем определение словаря в файле status_codes.py, а затем — фрагмент кода файла sessions.py, в котором словарь используется.


 Все эти варианты состояния OK станут ключами словаря. За исключением счастливого человека (\\o/) и флажка (
Все эти варианты состояния OK станут ключами словаря. За исключением счастливого человека (\\o/) и флажка ( ).
).
 Устаревшие значения расположены на отдельной строке, поэтому, когда их в будущем удалят, в системе контроля версий это будет четко определено.
Устаревшие значения расположены на отдельной строке, поэтому, когда их в будущем удалят, в системе контроля версий это будет четко определено.
 LookupDict позволяет получать доступ к своим элементам через точку, как это показано в следующей строке.
LookupDict позволяет получать доступ к своим элементам через точку, как это показано в следующей строке.
 codes.ok == 200 и codes.okay == 200.
codes.ok == 200 и codes.okay == 200.
 А также codes.OK == 200 и codes.OKAY == 200.
А также codes.OK == 200 и codes.OKAY == 200.
Вся эта работа нужна для того, чтобы создать словарь с кодами состояний. Для чего? Использование словаря вместо цифр на протяжении всего кода (что чревато опечатками) позволяет повысить читаемость, а также хранить все эти числа в одном файле. Поскольку все числа, представляющие коды, записаны в словарь, каждое из них появится всего один раз. Вероятность опечаток при этом значительно снижается.
Преобразование ключей в атрибуты вместо их использования в качестве строк в словаре также снижает риск опечаток. Рассмотрим пример кода из файла sessions.py, который гораздо легче прочитать, когда в нем используются слова, а не числа.


 Здесь импортируются коды состояний.
Здесь импортируются коды состояний.
 Классы-примеси мы опишем в пункте «Примеси (еще одна отличная штука)» подраздела «Примеры структуры из Werkzeug» следующего раздела. Примесь предоставляет методы перенаправления для основного класса Session, который определен в том же файле, но не показан в приведенном фрагменте.
Классы-примеси мы опишем в пункте «Примеси (еще одна отличная штука)» подраздела «Примеры структуры из Werkzeug» следующего раздела. Примесь предоставляет методы перенаправления для основного класса Session, который определен в том же файле, но не показан в приведенном фрагменте.
 Мы входим в цикл, который следует за перенаправлениями и позволяет нам получить желаемое содержимое. Вся логика цикла удалена из этого фрагмента для краткости.
Мы входим в цикл, который следует за перенаправлениями и позволяет нам получить желаемое содержимое. Вся логика цикла удалена из этого фрагмента для краткости.
 Коды состояний, представленные в виде текста, гораздо читабельнее, нежели числа (которые трудно запомнить): codes.see_other в противном случае выглядел бы как 303.
Коды состояний, представленные в виде текста, гораздо читабельнее, нежели числа (которые трудно запомнить): codes.see_other в противном случае выглядел бы как 303.
 codes.found выглядел бы как 302, а codes.moved — как 301. Поэтому код становится самозадокументированным; мы можем узнать значение переменных из их имен. Мы избежали засорения кода опечатками, добавив точечную нотацию вместо словаря и строк (например, codes.found вместо codes["found"]).
codes.found выглядел бы как 302, а codes.moved — как 301. Поэтому код становится самозадокументированным; мы можем узнать значение переменных из их имен. Мы избежали засорения кода опечатками, добавив точечную нотацию вместо словаря и строк (например, codes.found вместо codes["found"]).
Werkzeug
Для того чтобы прочесть код Werkzeug, нам нужно узнать, как веб-серверы общаются с приложениями. В следующих абзацах мы попытались представить максимально короткий обзор по этому вопросу.
Интерфейс Python для взаимодействия серверов с веб-приложениями определен в PEP 333, который написан Филипом Джей Эби (Phillip J. Eby) в 2003 году. В нем указано, как веб-сервер (вроде Apache) общается с приложением Python или фреймворком.
1. Сервер будет вызывать приложение каждый раз при получении запроса HTTP (например, GET или POST).
2. Это приложение вернет итерабельный объект, содержащий объекты типа bytestrings, который сервер использует для ответа на запрос HTTP.
3. В спецификации также говорится, что приложение примет два параметра, например webapp(environ, start_response). Параметр environ будет содержать данные, связанные с запросом, а параметр start_response будет функцией или другим вызываемым объектом, который задействуется для отправки обратно заголовка (например, ('Content-type', 'text/plain')) и состояния (например, 200 OK) на сервер.
В этом документе есть еще полдюжины страниц дополнительной информации. В середине PEP 333 вы можете увидеть впечатляющее заявление о том, как новый стандарт сделал возможным создание веб-фреймворков.
Если промежуточное ПО может быть простым и надежным и стандарт WSGI широко доступен в серверах и фреймворках, появляется возможность создания принципиально нового фреймворка Python для веб-приложений, — фреймворка, который состоит из слабо связанных компонентов промежуточного ПО WSGI. Более того, авторы существующих фреймворков могут решить изменить свои сервисы, сделав их похожими на библиотеки, используемые вместе с WSGI, а не на монолитные фреймворки. Это позволит разработчикам приложения выбирать лучшие компоненты для требуемой функциональности, а не довольствоваться одним фреймворком, воспользовавшись всеми его преимуществами и смирившись с недостатками.
Конечно, на текущий момент этот день еще не так близок. В то же время хорошей кратковременной целью для WSGI является возможность использовать любой фреймворк с любым сервером.
Четыре года спустя, в 2007 году, Армин Ронакер (Armin Ronacher) выпустил Werkzeug, намереваясь создать библиотеку WSGI, которую можно использовать для создания приложений WSGI и компонентов промежуточного ПО.
Werkzeug — самый крупный пакет из тех, что мы рассмотрим, поэтому перечислим только несколько его проектных решений.
Читаем код инструментария
Инструментарий (тулкит) — это набор совместимых утилит. В случае Werkzeug все они связаны с приложениями WSGI. Хороший способ понять отдельные утилиты и их предназначение — взглянуть на юнит-тесты, именно так мы и поступим.
Получаем Werkzeug из GitHub:
$ git clone
$ virtualenv -p python3 venv
$ source venv/bin/activate
(venv)$ cd werkzeug
(venv)$ pip install --editable .
(venv)$ py.test tests # Запускаем юнит-тесты
Читаем документацию Werkzeug
В документации Werkzeug (/) перечислены основные возможности, предоставляемые библиотекой, — реализация спецификации WSGI 1.0 (PEP 333, /), система маршрутизации URL, возможность анализировать и сохранять заголовки HTTP, объекты, которые предоставляют запросы и ответы HTTP, сессии и поддержка cookie, загрузка файлов и другие утилиты и надстройки от сообщества. Плюс полноценный отладчик.
Эти руководства информативны, но мы используем документацию к API вместо того, чтобы изучать компоненты библиотеки. В следующем разделе рассматриваются обертки для Werkzeug (/) и документация по маршрутизации (/).
Используем Werkzeug
Werkzeug предоставляет вспомогательные программы для приложений WSGI, поэтому, чтобы узнать, что предоставляет Werkzeug, мы можем начать с приложения WSGI, а затем использовать несколько вспомогательных программ от Werkzeug. Это первое приложение несколько отличается от того, что предоставлено в PEP 333, и не использует Werkzeug. Второе приложение делает то же самое, что и первое, но при этом использует Werkzeug:
def wsgi_app(environ, start_response):
headers = [('Content-type', 'text/plain'), ('charset', 'utf-8')]
start_response('200 OK', headers)
yield 'Hello world.'
# Это приложение делает то же самое, что и указанное выше:
response_app = werkzeug.Response('Hello world!')
Werkzeug реализует класс werkzeug.Client, который ведет себя как реальный веб-сервер при выполнении подобных проверок. Ответ клиента будет иметь тип аргумента response_wrapper. В этом коде мы создаем клиентов и используем их для вызова приложений WSGI, которые создали ранее. Для начала разберем простое приложение WSGI (его ответ будет размещен в объекте werkzeug.Response):
>>> import werkzeug
>>> client = werkzeug.Client(wsgi_app, response_wrapper=werkzeug.Response)
>>> resp=client.get("?answer=42")
>>> type(resp)
<class 'werkzeug.wrappers.Response'>
>>> resp.status
'200 OK'
>>> resp.content_type
'text/plain'
>>> print(resp.data.decode())
Hello world.
Далее используйте объект werkzeug.Response:
>>> client = werkzeug.Client(response_app, response_wrapper=werkzeug.Response)
>>> resp=client.get("?answer=42")
>>> print(resp.data.decode())
Hello world!
Класс werkzeug.Request предоставляет содержимое словаря среды (аргумент environ, расположенный над wsgi_app()) в форме, удобной для пользователя, а также декоратор для преобразования функции, которая принимает объект werkzeug.Request и возвращает werkzeug.Response приложению WSGI:
>>> @werkzeug.Request.application
... def wsgi_app_using_request(request):
... msg = "A WSGI app with:\n method: {}\n path: {}\n query: {}\n"
... return werkzeug.Response(
... msg.format(request.method, request.path, request.query_string))
...
Она возвращает следующий код:
>>> client = werkzeug.Client(
... wsgi_app_using_request, response_wrapper=werkzeug.Response)
>>> resp=client.get("?answer=42")
>>> print(resp.data.decode())
A WSGI app with:
method: GET
path: /
query: b'answer=42'
Теперь мы знаем, как работать с объектами werkzeug.Request и werkzeug.Response. Помимо них, в документации указана маршрутизация. Рассмотрим фрагмент кода, где она используется; порядковые номера определяют шаблон и соответствующее ему значение.


 Объект werkzeug.Routing.Map предоставляет основные функции для маршрутизации. Правила соответствия применяются по порядку; первым идет выбранное правило.
Объект werkzeug.Routing.Map предоставляет основные функции для маршрутизации. Правила соответствия применяются по порядку; первым идет выбранное правило.
 Если в строке-заполнителе для правила нет условий в угловых скобках, принимается только полное совпадение, вторым результатом работы метода urls.match() является пустой словарь:
Если в строке-заполнителе для правила нет условий в угловых скобках, принимается только полное совпадение, вторым результатом работы метода urls.match() является пустой словарь:
>>> env = werkzeug.create_environ(path='/')
>>> urls = url_map.bind_to_environ(env)
>>> urls.match()
('index', {})
 В противном случае второй записью является словарь, в котором соотнесены именованные термы с соответствующими значениями, например person соотнесен с Galahad:
В противном случае второй записью является словарь, в котором соотнесены именованные термы с соответствующими значениями, например person соотнесен с Galahad:
>>> env = werkzeug.create_environ(path='/Galahad?favorite+color')
>>> urls = url_map.bind_to_environ(env)
>>> urls.match()
('ask', {'person': 'Galahad'})
 Обратите внимание, что Galahad мог соответствовать маршруту other, но вместо этого ему соответствует Lancelot, поскольку выбирается первое соответствующее правило:
Обратите внимание, что Galahad мог соответствовать маршруту other, но вместо этого ему соответствует Lancelot, поскольку выбирается первое соответствующее правило:
>>> env = werkzeug.create_environ(path='/Lancelot')
>>> urls = url_map.bind_to_environ(env)
>>> urls.match()
('other', {'other': 'Lancelot'})
 Если в списке правил соответствие не найдено, генерируется исключение:
Если в списке правил соответствие не найдено, генерируется исключение:
>>> env = werkzeug.test.create_environ(path='/shouldnt/match')
>>> urls = url_map.bind_to_environ(env)
>>> urls.match()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "[...path...]/werkzeug/werkzeug/routing.py", line 1569, in match
raise NotFound()
werkzeug.exceptions.NotFound: 404: Not Found
Вы соотнесли маршрут запроса с соответствующей конечной точкой. В следующем фрагменте кода продолжим рассматривать суть предыдущего примера:
@werkzeug.Request.application
def send_to_endpoint(request):
urls = url_map.bind_to_environ(request)
try:
endpoint, kwargs = urls.match()
if endpoint == 'index':
response = werkzeug.Response("You got the index.")
elif endpoint == 'ask':
questions = dict(
Galahad='What is your favorite color?',
Robin='What is the capital of Assyria?',
Arthur='What is the air-speed velocity
of an unladen swallow?')
response = werkzeug.Response(questions[kwargs['person']])
else:
response = werkzeug.Response("Other: {other}".format(**kwargs))
except (KeyboardInterrupt, SystemExit):
raise
except:
response = werkzeug.Response(
'You may not have gone where you intended to go,\n'
'but I think you have ended up where you needed to be.',
status=404
)
return response
Для того чтобы протестировать этот фрагмент, снова используйте класс werkzeug.Client:
>>> client = werkzeug.Client(send_to_endpoint, response_wrapper=werkzeug.Response)
>>> print(client.get("/").data.decode())
You got the index.
>>>
>>> print(client.get("Arthur").data.decode())
What is the air-speed velocity of an unladen swallow?
>>>
>>> print(client.get("42").data.decode())
Other: 42
>>>
>>> print(client.get("time/lunchtime").data.decode()) # no match
You may not have gone where you intended to go,
but I think you have ended up where you needed to be.
Читаем код Werkzeug
При хорошем тестовом покрытии вы можете узнать, что делает библиотека, взглянув на ее юнит-тесты. Проблема в том, что в этом случае вы смотрите на «отдельные деревья», а не на «лес», то есть исследуете странные варианты использования, предназначенные для того, чтобы гарантировать, что код не даст сбой (вместо того чтобы исследовать связи между модулями). Это годится для инструмента вроде Werkzeug, содержащего модульные, слабо связанные компоненты.
Поскольку мы уже знаем, как работают маршрутизация и обертки для запроса и ответа, то теперь можем прочесть файлы werkzeug/test_routing.py и werkzeug/test_wrappers.py.
Когда мы в первый раз откроем файл werkzeug/test_routing.py, можем быстро взглянуть на связи между модулями, поискав импортированные объекты во всем файле.
Рассмотрим все операторы импорта.
 Конечно, pytest используется для тестирования.
Конечно, pytest используется для тестирования.
 Модуль uuid применяется всего в одной функции test_uuid_converter(), чтобы подтвердить, что работает преобразование между объектами типа string и uuid.UUID (строка Universal Unique Identifier (универсальный уникальный идентификатор) позволяет уникально идентифицировать объекты в Интернете).
Модуль uuid применяется всего в одной функции test_uuid_converter(), чтобы подтвердить, что работает преобразование между объектами типа string и uuid.UUID (строка Universal Unique Identifier (универсальный уникальный идентификатор) позволяет уникально идентифицировать объекты в Интернете).
 Функция strict_eq() используется довольно часто и определена в файле werkzeug/tests/__init__.py. Предназначена для тестирования и нужна только потому, что в Python 2 существовало явное преобразование между строками в формате Unicode и byte, но на это нельзя полагаться в Python 3.
Функция strict_eq() используется довольно часто и определена в файле werkzeug/tests/__init__.py. Предназначена для тестирования и нужна только потому, что в Python 2 существовало явное преобразование между строками в формате Unicode и byte, но на это нельзя полагаться в Python 3.
 werkzeug.routing — это тестируемый модуль.
werkzeug.routing — это тестируемый модуль.
 Объект Response применяется всего в одной функции test_dispatch() для подтверждения, что werkzeug.routing.MapAdapter.dispatch() передает правильную информацию, отправленную приложению WSGI.
Объект Response применяется всего в одной функции test_dispatch() для подтверждения, что werkzeug.routing.MapAdapter.dispatch() передает правильную информацию, отправленную приложению WSGI.
 Эти объекты словаря используются по одному разу. ImmutableDict нужен для того, чтобы подтвердить, что неизменяемый каталог, указанный в werkzeug.routing.Map, действительно неизменяем, а MultiDict — чтобы предоставить несколько значений с ключами строителю URL и подтвердить, что был собран правильный URL.
Эти объекты словаря используются по одному разу. ImmutableDict нужен для того, чтобы подтвердить, что неизменяемый каталог, указанный в werkzeug.routing.Map, действительно неизменяем, а MultiDict — чтобы предоставить несколько значений с ключами строителю URL и подтвердить, что был собран правильный URL.
 Функция create_environ() предназначена для тестирования: создает среду WSGI без реального запроса HTTP.
Функция create_environ() предназначена для тестирования: создает среду WSGI без реального запроса HTTP.
Цель этого анализа — исследование связей между модулями. Мы обнаружили, что werkzeug.routing лишь импортирует некоторые специальные структуры данных. Остальная часть юнит-тестов показывает область действия модуля маршрутизации. Например, вы можете использовать символы, не входящие в ASCII:
def test_environ_nonascii_pathinfo():
environ = create_environ(u'/лошадь')
m = r.Map([
r.Rule(u'/', endpoint='index'),
r.Rule(u'/лошадь', endpoint='horse')
])
a = m.bind_to_environ(environ)
strict_eq(a.match(u'/'), ('index', {}))
strict_eq(a.match(u'/лошадь'), ('horse', {}))
pytest.raises(r.NotFound, a.match, u'/барсук')
Существуют тесты для сборки и анализа URL и даже утилиты для поиска ближайшего совпадения, которое не является полным. Вы можете выполнить пользовательскую обработку в процессе преобразования типов путей и строк URL:
def test_converter_with_tuples():
'''
Регрессионные тесты для
'''
class TwoValueConverter(r.BaseConverter):
def __init__(self, *args, **kwargs):
super(TwoValueConverter, self).__init__(*args, **kwargs)
self.regex = r'(\w\w+)/(\w\w+)'
def to_python(self, two_values):
one, two = two_values.split('/')
return one, two
def to_url(self, values):
return "%s/%s" % (values[0], values[1])
map = r.Map([
r.Rule('/<two:foo>/', endpoint='handler')
], converters={'two': TwoValueConverter})
a = map.bind('example.org', '/')
route, kwargs = a.match('/qwert/yuiop/')
assert kwargs['foo'] == ('qwert', 'yuiop')
Аналогично немногое импортируется в файле werkzeug/test_wrappers.py. В тесте показывается функциональность, доступная объекту Request, — cookies, кодировки, аутентификация, безопасность, таймауты кэша и даже мультиязычные кодировки:
def test_modified_url_encoding():
class ModifiedRequest(wrappers.Request):
url_charset = 'euc-kr'
req = ModifiedRequest.from_values(u'/?foo= '.encode('euc-kr'))
'.encode('euc-kr'))
strict_eq(req.args['foo'], u' ')
')
Как правило, чтение тестов позволяет более подробно ознакомиться с возможностями библиотеки. Теперь понятно, для чего нужна библиотека Werkzeug, поэтому можно двигаться дальше.
| Tox в Werkzeug Tox (/) — инструмент командной строки, который использует виртуальные среды для запуска тестов. Вы можете запускать их на своем компьютере (tox в командной строке), если установлены интерпретаторы Python. Интегрирован с GitHub, поэтому, если у вас есть файл tox.ini на высшем уровне репозитория, как у Werkzeug, он автоматически будет запускать тесты при каждом коммите. Рассмотрим конфигурационный файл Werkzeug tox.ini целиком: [tox] envlist = py{26,27,py,33,34,35}-normal, py{26,27,33,34,35}-uwsgi
[testenv] passenv = LANG deps= # General pyopenssl greenlet pytest pytest-xprocess redis requests watchdog uwsgi: uwsgi
# Python 2 py26: python-memcached py27: python-memcached pypy: python-memcached
# Python 3 py33: python3-memcached py34: python3-memcached py35: python3-memcached
whitelist_externals= redis-server memcached uwsgi |
| commands= normal: py.test [] uwsgi: uwsgi --pyrun {envbindir}/py.test --pyargv -kUWSGI --cache2=name=werkzeugtest,items=20 --master |
Примеры стиля из Werkzeug
В главе 4 мы уже рассмотрели большую часть принятых соглашений по стилю. Первый пример стиля в этом разделе демонстрирует элегантный способ угадать типы на основе строки, второй показывает, что вы можете использовать параметр VERBOSE при определении длинных регулярных выражений, поэтому другие пользователи смогут понять, что делает выражение, не затратив на это много времени.
Элегантный способ угадать тип (если реализацию легко объяснить — идея, возможно, хороша)
Вам, скорее всего, приходилось анализировать текстовые файлы и преобразовывать содержимое к разным типам. Это решение выглядит особенно питонским, поэтому мы включили его в книгу.

 Поиск в словарях с помощью ключей в Python использует соотнесение хэшей, как и поиск в множестве. Python не имеет операторов switch case. (Их отклонили как непопулярные в PEP 3103 (/).) Вместо этого пользователи Python используют инструкцию if/elif/else или (как показано здесь) питонское решение — поиск в словаре.
Поиск в словарях с помощью ключей в Python использует соотнесение хэшей, как и поиск в множестве. Python не имеет операторов switch case. (Их отклонили как непопулярные в PEP 3103 (/).) Вместо этого пользователи Python используют инструкцию if/elif/else или (как показано здесь) питонское решение — поиск в словаре.
 Обратите внимание, что в первый раз попытка преобразования выполняется к более ограниченному типу int, перед тем как попытаться выполнить преобразование к типу float.
Обратите внимание, что в первый раз попытка преобразования выполняется к более ограниченному типу int, перед тем как попытаться выполнить преобразование к типу float.
 Питонским решением также является использование оператора try/except для infer type.
Питонским решением также является использование оператора try/except для infer type.
 Эта часть необходима, поскольку код находится в файле werkzeug/routing.py, а анализируемая строка является частью URL. Здесь проверяется наличие кавычек, при обнаружении они удаляются.
Эта часть необходима, поскольку код находится в файле werkzeug/routing.py, а анализируемая строка является частью URL. Здесь проверяется наличие кавычек, при обнаружении они удаляются.
 text_type преобразовывает строки в формат Unicode таким образом, что они остаются совместимыми и с Python 2, и с Python 3. Этот код практически аналогичен функции u(), показанной в разделе «HowDoI» в начале главы 5.
text_type преобразовывает строки в формат Unicode таким образом, что они остаются совместимыми и с Python 2, и с Python 3. Этот код практически аналогичен функции u(), показанной в разделе «HowDoI» в начале главы 5.
Регулярные выражения (читаемость имеет значение)
Если вы используете в своем коде длинные регулярные выражения, не забывайте про параметр re.VERBOSE — сделайте их более понятными для других людей. Пример регулярных выражений показан во фрагменте файла werkzeug/routing.py:
import re
_rule_re = re.compile(r'''
(?P<static>[^<]*) # static rule data
<
(?:
(?P<converter>[a-zA-Z_][a-zA-Z0-9_]*) # имя преобразователя
(?:\((?P<args>.*?)\))? # аргументы преобразователя
\: # разделитель переменных
)?
(?P<variable>[a-zA-Z_][a-zA-Z0-9_]*) # имя переменной
>
''', re.VERBOSE)
Примеры структуры из Werkzeug
В первых двух примерах, связанных со структурой, демонстрируются питонские способы использования динамической типизации. Мы предупреждали, что присваивание переменной разных значений может приводить к появлению проблем (см. подраздел «Динамическая типизация» раздела «Структурируем проект» главы 4), но не упомянули преимущества такого присваивания. Одно из них заключается в том, что вы можете использовать любой тип объекта, который ведет себя предсказуемо. Это называется утиной типизацией. Утиная типизация исповедует следующую философию: «Если что-то выглядит, как утка, крякает, как утка, то это и есть утка».
В обоих примерах используется возможность вызвать объекты, которые не являются функциями: вызов cached_property.__init__() позволяет проинициализировать экземпляры класса, чтобы их можно быть применять как обычные функции, а вызов Response.__call__() позволяет объекту класса Response вызвать как функцию самого себя.
В последнем фрагменте используется реализация некоторых классов-примесей (каждый из них определяет какую-либо функциональность в объекте класса Request), характерная для Werkzeug, чтобы продемонстрировать, что такие классы — это тоже отличная штука.
Декораторы, основанные на классах (питонский способ использовать динамическую типизацию)
Werkzeug применяет утиную типизацию для того, чтобы создать декоратор @cached_property. Когда мы говорили о свойстве, описывая проект Tablib, то упоминали, что оно похоже на функцию. Обычно декораторы являются функциями, но поскольку тип ничем не навязывается, они могут быть любым вызываемым объектом: свойство на самом деле является классом. (Вы можете сказать, что оно задумывалось как функция, поскольку его имя не начинается с прописной буквы, а в PEP 8 говорится, что имена классов должны начинаться c прописной буквы.) При использовании нотации, похожей на вызов функции (property()), будет вызван метод property.__init__() для инициализации и возврата экземпляра свойства — класс, для которого соответствующим образом определен метод __init__(), работает как вызываемая функция. Кря.
В следующем фрагменте кода содержится полное определение свойства cached_property, которое является подклассом класса property. Документация класса cached_property говорит сама за себя. Когда это свойство будет использоваться для декорирования BaseRequest.form в коде, который мы только что видели, instance.form будет иметь тип cached_property и с точки зрения пользователя будет вести себя как словарь, поскольку для него определены методы __get__() и __set__(). При получении доступа к BaseRequest.form в первый раз он считает данные формы (если она существует), а затем запишет их в instance.form.__dict__, чтобы к ним можно было получить доступ в дальнейшем:
class cached_property(property):
"""Декоратор, который преобразует функцию в ленивое свойство.
Обернутая функция в первый раз вызывается для получения результата,
затем полученный результат используется при следующем обращении к value::
class Foo(object):
@cached_property
def foo(self):
# выполняем какие-нибудь важные расчеты
return 42
Класс должен иметь '__dict__' для того, чтобы это свойство работало.
"""
# деталь реализации: для подкласса, встроенного
# в Python свойства-декоратора
# мы переопределяем метод __get__ так, чтобы получать кэшированное
# значение.
# Если пользователь хочет вызвать метод __get__ вручную, свойство будет
# работать как обычно, поскольку логика поиска реплицируется
# в методе __get__ при вызове вручную.
def __init__(self, func, name=None, doc=None):
self.__name__ = name or func.__name__
self.__module__ = func.__module__
self.__doc__ = doc or func.__doc__
self.func = func
def __set__(self, obj, value):
obj.__dict__[self.__name__] = value
def __get__(self, obj, type=None):
if obj is None:
return self
value = obj.__dict__.get(self.__name__, _missing)
if value is _missing:
value = self.func(obj)
obj.__dict__[self.__name__] = value
return value
Взглянем на этот код в действии:
>>> from werkzeug.utils import cached_property
>>>
>>> class Foo(object):
... @cached_property
... def foo(self):
... print("You have just called Foo.foo()!")
... return 42
...
>>> bar = Foo()
>>>
>>> bar.foo
You have just called Foo.foo()!
42
>>> bar.foo
42
>>> bar.foo # Обратите внимание, сообщение не выводится снова...
42
Response.__call__
Класс Response собран с помощью функциональности класса BaseResponse, как и Request. Мы изучим его интерфейс и не будем смотреть на сам код. Взглянем лишь на строку документации для класса BaseResponse, чтобы узнать, как его использовать.

 В примере, показанном в строках документации, функция index() вызывается в ответ на запрос HTTP. Ответом будет строка Index page.
В примере, показанном в строках документации, функция index() вызывается в ответ на запрос HTTP. Ответом будет строка Index page.
 Эта сигнатура нужна в приложениях WSGI, как указано в PEP 333/PEP 3333.
Эта сигнатура нужна в приложениях WSGI, как указано в PEP 333/PEP 3333.
 Класс Response является подклассом BaseResponse, поэтому ответ представляет собой объект класса BaseResponse.
Класс Response является подклассом BaseResponse, поэтому ответ представляет собой объект класса BaseResponse.
 Для ответа 404 требуется лишь установить значение ключевого слова status.
Для ответа 404 требуется лишь установить значение ключевого слова status.
 И вуаля — объект response является вызываемой функцией сам по себе, все сопутствующие заголовки и детали имеют разумные значения по умолчанию (либо переопределены, если путь отличается от /).
И вуаля — объект response является вызываемой функцией сам по себе, все сопутствующие заголовки и детали имеют разумные значения по умолчанию (либо переопределены, если путь отличается от /).
Как объект класса может быть вызываемой функцией? Дело в том, что для него был определен метод BaseRequest.__call__. В следующем примере кода мы покажем лишь этот метод.

 Эта сигнатура позволяет сделать объекты класса BaseResponse вызываемыми функциями.
Эта сигнатура позволяет сделать объекты класса BaseResponse вызываемыми функциями.
 Здесь учтены требования к вызову приложений WSGI для функции start_response.
Здесь учтены требования к вызову приложений WSGI для функции start_response.
 А здесь возвращается итерабельный объект типа bytes.
А здесь возвращается итерабельный объект типа bytes.
Пора извлечь следующий урок: если язык позволяет что-то сделать, почему бы не сделать это? После того как мы поняли, что можно добавить метод __call__() к любому объекту и сделать его вызываемой функцией, мы можем вернуться к оригинальной документации и еще раз перечитать раздел о модели данных в Python ().
Примеси (еще одна отличная штука)
Примеси в Python — это классы, которые предназначены для того, чтобы добавлять определенную функциональность — набор связанных атрибутов. В Python, в отличие от Java, вы можете реализовать множественное наследование. Это означает, что парадигма, при которой создаются подклассы для полдюжины разных классов одновременно, — это один из способов разбить функциональность на отдельные классы. Это похоже на пространства имен.
Подобное разбиение может быть полезно во вспомогательной библиотеке вроде Werkzeug, поскольку она говорит пользователю, какие функции связаны друг с другом, а какие — нет. Разработчик может быть уверен, что атрибуты в одном классе-примеси не будут изменены функциями другого класса-примеси.

В Python для того, чтобы идентифицировать класс-примесь, не нужно ничего, кроме как следовать соглашению, в рамках которого к имени класса добавляется слово «Mixin». Это означает, что, если вы не хотите обращать внимания на порядок разрешения методов, все методы класса-примеси должны иметь разные имена.
В Werkzeug методы класса-примеси иногда могут требовать наличия определенных атрибутов. Эти требования зачастую приводятся в строке документации класса-примеси.

 В классе UserAgentMixin нет ничего особенного; он создает подкласс объекта, что выполняется по умолчанию в Python 3 и настоятельно рекомендуется для совместимости с Python 2. Все это нужно делать явно, поскольку «явное лучше, чем неявное».
В классе UserAgentMixin нет ничего особенного; он создает подкласс объекта, что выполняется по умолчанию в Python 3 и настоятельно рекомендуется для совместимости с Python 2. Все это нужно делать явно, поскольку «явное лучше, чем неявное».
 UserAgentMixin.user_agent предполагает, что существует атрибут self.environ.
UserAgentMixin.user_agent предполагает, что существует атрибут self.environ.
 При включении в список базовых классов для Request предоставляемый им атрибут становится доступным с помощью вызова Request(environ).user_agent.
При включении в список базовых классов для Request предоставляемый им атрибут становится доступным с помощью вызова Request(environ).user_agent.
 Больше ничего нет — мы полностью рассмотрели определение класса Request. Вся функциональность предоставляется базовым классом или классами-примесями. Модульными, подключаемыми и такими же великолепными, как Форд Префект.
Больше ничего нет — мы полностью рассмотрели определение класса Request. Вся функциональность предоставляется базовым классом или классами-примесями. Модульными, подключаемыми и такими же великолепными, как Форд Префект.
| Новые классы и object Базовый класс object добавляет атрибуты по умолчанию, на которые полагаются другие встроенные параметры. Классы, которые не наследуют от класса object, называются старыми или классическими классами. В Python 3 таких классов нет, наследование от класса object выполняется по умолчанию. Это означает, что все классы Python 3 являются новыми. Новые классы доступны в Python 2.7 (их поведение не изменялось с версии Python 2.3), но наследование должно быть прописано явно, и мы считаем, что так нужно делать всегда. Более подробная информация содержится в документации к Python для новых классов (/), в руководстве по адресу , а история их создания — в статье по адресу . Рассмотрим некоторые различия между старыми и новыми классами (в Python 2.7; все классы Python 3 являются новыми): >>> class A(object): ... """Новый класс, он является подклассом object.""" ... >>> class B: ... """Старый класс.""" ... >>> dir(A) ['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__'] >>> >>> dir(B) ['__doc__', '__module__'] >>> >>> type(A) <type 'type'> >>> type(B) <type 'classobj'> >>> >>> import sys >>> sys.getsizeof(A()) # размер в байтах. 64 >>> sys.getsizeof(B()) 72 |
Flask
Flask — это веб-микрофреймворк, который объединяет Werkzeug и Jinja2, оба они написаны Армином Роначером (Armin Ronacher). Создавался шутки ради и был выпущен 1 апреля 2010 года, но быстро стал одним из самых популярных фреймворков Python. Армин несколькими годами ранее (в 2007 году) выпустил Werkzeug, преподнеся его как «швейцарский нож для веб-разработки на Python», и (как мы предполагаем) был немного расстроен тем, что он приживался слишком медленно. Идея Werkzeug заключалась в том, чтобы отвязать WSGI от всего остального, дабы разработчики могли подключать вспомогательные программы по своему выбору. Армин еще не догадывался, насколько нам нужны дополнительные «рельсы».
Читаем код фреймворка
Программный фреймворк похож на физический фреймворк — предлагает структуру для создания приложения WSGI: пользователь библиотеки предоставляет компоненты, которые основное приложение Flask запускает. Наша цель при чтении кода — понять структуру фреймворка и его возможности.
Получаем Flask с GitHub:
$ git clone
$ virtualenv venv # вы можете использовать Python 3, но это не рекомендуется
$ source venv/bin/activate
(venv)$ cd flask
(venv)$ pip install --editable .
(venv)$ pip install -r test-requirements.txt # Required for unit tests
(venv)$ py.test tests # Запускаем юнит-тесты
Читаем документацию Flask
Онлайн-документация к Flask (/) начинается с реализации веб-приложения длиной семь строк, затем приводится общее описание Flask: это основанный на Unicode и совместимый с WSGI фреймворк, который использует Jinja2 для создания шаблонов HTML и Werkzeug — для работы со вспомогательными программами WSGI, например маршрутизации URL. Имеет встроенные инструменты для разработки и тестирования.
Вам также доступны полезные руководства, поэтому следующий шаг сделать нетрудно.
Использование Flask
Мы можем запустить пример flaskr, который загрузили с репозитория GitHub. В документах говорится, что это небольшой сайт для ведения блога. Находясь в верхнем каталоге Flask, запустите следующие команды:
(venv)$ cd examples/flaskr/
(venv)$ py.test test_flaskr.py # Тесты должны проходить
(venv)$ export FLASK_APP=flaskr
(venv)$ flask initdb
(venv)$ flask run
Читаем код Flask
Итоговой целью Flask является создание веб-приложения, поэтому он не особо отличается от приложений командной строки Diamond и HowDoI. Вместо того чтобы привести еще одну схему, иллюстрирующую прохождение потока выполнения по функциям, мы пройдемся с помощью отладчика по приложению-примеру flaskr. Для этого нам нужен pdb — отладчик Python (находится в стандартной библиотеке).
Для начала добавьте точку останова в файле Flaskr.py, которая будет активизирована, когда поток выполнения ее достигнет, что заставит интерактивную сессию войти в отладчик:
@app.route('/')
def show_entries():
import pdb; pdb.set_trace() ## Здесь поставьте точку останова.
db = get_db()
cur = db.execute('select title, text from entries order by id desc')
entries = cur.fetchall()
return render_template('show_entries.html', entries=entries)
Закройте файл и введите python в командной строке, дабы войти в интерактивную сессию. Чтобы не запускать сервер, используйте внутренние вспомогательные программы для тестирования Flask — для симуляции запроса HTTP GET к каталогу /, куда мы только что поместили отладчик:
>>> import flaskr
>>> client = flaskr.app.test_client()
>>> client.get('/')
> /[... truncated path ...]/flask/examples/flaskr/flaskr.py(74)show_entries()
-> db = get_db()
(Pdb)
Последние три строки мы получили от pdb: мы видим путь (к Flaskr.py), номер строки (74) и имя метода (show_entries()), где мы остановились. Строка (-> db = get_db()) показывает выражение, которое будет выполнено следующим, если сделаем в еще один шаг в отладчике. Приглашение (Pdb) указывает на то, что мы используем отладчик pdb.
Мы можем подняться или опуститься по стеку, введя в командной строке u или d соответственно. Просмотрите документацию к pdb () под заголовком «Команды отладчика», чтобы получить полный список команд, с которыми можно работать. Мы также можем ввести имена переменных, чтобы увидеть их значения, и любую другую команду Python; мы даже можем указать переменным другие значения до того, как продолжим выполнение кода.
Если мы поднимемся по стеку на один шаг, то увидим, что вызвало функцию show_entries() (с помощью точки останова, которую мы только что установили): это объект flask.app.Flask, имеющий словарь с именем view_functions, который соотносит строковые имена (вроде 'show_entries') с функциями. Мы также увидим, что функция show_entries() была вызвана с **req.view_args.
Мы можем узнать, чем является req.view_args, в интерактивной командной строке отладчика, просто введя нужное имя (это пустой словарь — {}, то есть аргументов нет):
(Pdb) u
> /[ ... truncated path ...]/flask/flask/app.py(1610)dispatch_request()
-> return self.view_functions[rule.endpoint](**req.view_args)
(Pdb) type(self)
<class 'flask.app.Flask'>
(Pdb) type(self.view_functions)
<type 'dict'>
(Pdb) self.view_functions
{'add_entry': <function add_entry at 0x1081 98230>,
'show_entries': <function show_entries at 0x1081981b8>, [... truncated ...]
'login': <function login at 0x1081982a8>}
(Pdb) rule.endpoint
'show_entries'
(Pdb) req.view_args
{}
Одновременно с отладкой мы можем открыть файл исходного кода и следовать по нему. Если мы продолжим подниматься по стеку, то увидим, где вызвано приложение WSGI:
(Pdb) u
> /[ ... truncated path ...]/flask/flask/app.py(1624)full_dispatch_request()
-> rv = self.dispatch_request()
(Pdb) u
> /[ ... truncated path ...]/flask/flask/app.py(1973)wsgi_app()
-> response = self.full_dispatch_request()
(Pdb) u
> /[ ... truncated path ...]/flask/flask/app.py(1985)__call__()
-> return self.wsgi_app(environ, start_response)
Если мы продолжим вводить u, то окажемся в модуле тестирования, который был использован для создания фальшивого клиента без запуска сервера, — мы достигли конца стека. Мы узнали, что приложение flaskr отправляется изнутри объекта класса flask.app.Flask, строка 1985 файла Flask/Flask/app.py. Перед вами эта функция:

 Это строка 1973, определенная в отладчике.
Это строка 1973, определенная в отладчике.
 Это строка 1985, также определенная в отладчике. Сервер WSGI получит объект Flask как приложение и будет вызывать его всякий раз, когда приходит соответствующий запрос (с помощью отладчика мы нашли точку входа в код).
Это строка 1985, также определенная в отладчике. Сервер WSGI получит объект Flask как приложение и будет вызывать его всякий раз, когда приходит соответствующий запрос (с помощью отладчика мы нашли точку входа в код).
Мы используем отладчик точно так же, как граф вызовов для HowDoI: следуем вызовам функций (это в принципе не отличается от чтения самого кода). Ценность отладчика заключается в том, что мы не видим лишнего кода, который может отвлечь нас или запутать. Используйте тот подход, который наиболее эффективен для вас.
После того как мы поднялись по стеку с помощью команды u, можем вернуться вниз с помощью команды d — и снова окажемся у точки останова, помеченной *** Newest frame:
> /[ ... truncated path ...]/flask/examples/flaskr/flaskr.py(74)show_entries()
-> db = get_db()
(Pdb) d *** Newest frame
Далее можем перейти через вызов функции с помощью команды n (next — «далее») или же сделать минимально возможный шаг с помощью команды s (step — «шаг»):

Тема на этом не заканчивается, но демонстрировать весь материал довольно утомительно. Вот что мы узнали.
 Существует объект Flask.g, который при более детальном рассмотрении оказывается глобальным контекстом (при этом он является локальным для объекта Flask). Он предназначен для хранения соединений с базой данных и других устойчивых объектов вроде cookie, которые должны «жить» дольше, чем методы класса Flask. Использование словаря подобным образом позволяет хранить переменные за пределами пространства имен приложения Flask, избегая «столкновений» имен.
Существует объект Flask.g, который при более детальном рассмотрении оказывается глобальным контекстом (при этом он является локальным для объекта Flask). Он предназначен для хранения соединений с базой данных и других устойчивых объектов вроде cookie, которые должны «жить» дольше, чем методы класса Flask. Использование словаря подобным образом позволяет хранить переменные за пределами пространства имен приложения Flask, избегая «столкновений» имен.
 Функция render_template() находится в конце определения функции в модуле flaskr.py. Это означает, что мы, по сути, закончили работу — возвращаемое значение отправляется вызывающей функции из объекта Flask, который мы видели при подъеме по стеку. Поэтому мы пропустим остальную часть.
Функция render_template() находится в конце определения функции в модуле flaskr.py. Это означает, что мы, по сути, закончили работу — возвращаемое значение отправляется вызывающей функции из объекта Flask, который мы видели при подъеме по стеку. Поэтому мы пропустим остальную часть.
Отладчик полезно использовать локально в том месте, которое вы проверяете, чтобы точно понять, что происходит в коде до и после выбранной пользователем точки. Одной из основных функций является возможность изменять переменные на ходу (любой код Python работает в отладчике), после чего вы можете продолжить выполнение кода.
| Журналирование во Flask Diamond содержит пример журналирования в приложении, а Flask предоставляет такой пример в библиотеке. Если вы хотите лишь избежать предупреждений «обработчик не обнаружен», выполните поиск строки logging в библиотеке Requests (requests/requests/__init__.py). Но если вам необходимо предоставить поддержку журналирования в вашей библиотеке или фреймворке, следует воспользоваться примером, предоставляемым Flask. Журналирование во Flask реализовано в файле Flask/Flask/logging.py. В нем определяется формат строк журнала для производства (уровень журналирования ERROR) и отладки (уровень журналирования DEBUG), также автор кода следует советам из Twelve-Factor App (/) по записи журналов в потоки (которые направляются в потоки wsgi.errors или sys.stderr в зависимости от контекста). Средство журналирования добавляется в основное приложение Flask в Flask/Flask/app.py (в следующем фрагменте кода опущена вся нерелевантная информация).
|
|
|







Примеры стиля из Flask
Большая часть примеров стиля из главы 4 уже была рассмотрена, поэтому для Flask мы продемонстрируем всего один — реализацию элегантных и простых декораторов маршрутизации.
Декораторы для маршрутизации во Flask (красивое лучше, чем уродливое). Декораторы для маршрутизации во Flask добавляют маршрутизацию URL к целевым функциям, например так:
@app.route('/')
def index():
pass
При отправке запроса приложение Flask будет использовать маршрутизацию URL для определения корректной функции, которая нужна для генерации ответа. Синтаксис декоратора позволяет хранить логику маршрутизации за пределами целевой функции, поддерживает функции flat, а его использование интуитивно.
Делать это вовсе необязательно — он существует только для того, чтобы предоставить пользователю данную функциональность API. Рассмотрим исходный код метода основного класса Flask, определенного в файле Flask/Flask/app.py.

 _PackageBoundObject настраивает файловую структуру для импорта шаблонов HTML, статических файлов и другого содержимого, основываясь на значениях конфигурации, указывающих их местоположение относительно местоположения модуля приложения (например, app.py).
_PackageBoundObject настраивает файловую структуру для импорта шаблонов HTML, статических файлов и другого содержимого, основываясь на значениях конфигурации, указывающих их местоположение относительно местоположения модуля приложения (например, app.py).
 Почему бы не назвать его декоратором? Он выполняет те же функции.
Почему бы не назвать его декоратором? Он выполняет те же функции.
 Это функция, которая добавляет URL в сопоставление, содержащее все правила. Единственное предназначение Flask.route — предоставить удобный декоратор для пользователей библиотеки.
Это функция, которая добавляет URL в сопоставление, содержащее все правила. Единственное предназначение Flask.route — предоставить удобный декоратор для пользователей библиотеки.
Примеры структуры из Flask
Основной посыл для обоих примеров структуры для Flask — модульность. Flask целенаправленно структурирован так, чтобы вы могли расширять и модифицировать практически все что угодно — от способа кодирования/декодирования строк JSON (Flask дополняет функциональность стандартной библиотеки для работы с JSON возможностью задавать кодировки для объектов datetime и UUID) до классов, использованных для маршрутизации URL.
Стандарты, характерные для приложения (простое лучше, чем сложное)
Flask и Werkzeug имеют модуль wrappers.py. Он нужен, чтобы добавить соответствующие значения по умолчанию во Flask, фреймворк для веб-приложений, которые будут дополнять общую библиотеку вспомогательных программ для приложений WSGI от Werkzeug. Во Flask создаются подклассы для Request и Response Werkzeug для того, чтобы добавлять функциональность, характерную для веб-приложений. Например, объект Response из файла Flask/Flask/wrappers.py выглядит так:

 Класс Response от Werkzeug импортируется как ResponseBase, эта деталь стиля делает предназначение класса очевидным и позволяет новому подклассу Response получить его имя.
Класс Response от Werkzeug импортируется как ResponseBase, эта деталь стиля делает предназначение класса очевидным и позволяет новому подклассу Response получить его имя.
 Возможность создать подкласс flask.wrappers.Response, а также способ выполнения этой задачи подробно описаны в строках документации. Когда вы реализуете подобную функциональность, важно помнить о документации, в противном случае пользователи не будут знать о том, что такая возможность существует.
Возможность создать подкласс flask.wrappers.Response, а также способ выполнения этой задачи подробно описаны в строках документации. Когда вы реализуете подобную функциональность, важно помнить о документации, в противном случае пользователи не будут знать о том, что такая возможность существует.
 На этом изменения в классе Response заканчиваются. Класс Request изменился больше, но мы не будем показывать его в этой главе, чтобы не раздувать ее размер.
На этом изменения в классе Response заканчиваются. Класс Request изменился больше, но мы не будем показывать его в этой главе, чтобы не раздувать ее размер.
В этой небольшой интерактивной сессии показывается, что изменилось в классе Response:
>>> import werkzeug
>>> import flask
>>>
>>> werkzeug.wrappers.Response.default_mimetype
'text/plain'
>>> flask.wrappers.Response.default_mimetype
'text/html'
>>> r1 = werkzeug.wrappers.Response('hello', mimetype='text/html')
>>> r1.mimetype
u'text/html'
>>> r1.default_mimetype
'text/plain'
>>> r1 = werkzeug.wrappers.Response('hello')
>>> r1.mimetype
'text/plain'
Идея изменения mime-типа по умолчанию заключается в том, чтобы позволить пользователям Flask писать меньше кода при сборке объектов ответа, которые содержат HTML (ожидаемые вариант использования Flask). Разумные значения по умолчанию делают ваш код гораздо более понятным для среднестатистического пользователя.
| Разумные значения по умолчанию могут быть важны Иногда значения по умолчанию нужны не только для простоты использования. Например, Flask устанавливает ключи, необходимые для определения числа посетителей и безопасной коммуникации, по умолчанию равными Null. Если ключ имеет значение null, то приложение при попытке запуска безопасной сессии сгенерирует ошибку. Форсирование появления таких ошибок означает, что пользователи будут создавать собственные тайные ключи — другими (плохими) вариантами будет либо молчаливое разрешение использования ключа сессии, равного null, а также небезопасных способов подсчета посетителей, либо предоставление ключа по умолчанию вроде mysecretkey, который не будет обновляться (и соответственно, не будет использоваться при развертывании). |
Модульность (еще одна отличная штука). Строки документации для flask.wrappers.Response сообщают пользователям, что они могут создать подкласс объекта Response и использовать его в основном объекте Flask.
В следующем фрагменте кода Flask/Flask/app.py мы приведем другие примеры модульности Flask.


 Здесь можно заменить пользовательский класс Request.
Здесь можно заменить пользовательский класс Request.
 А здесь вы можете определить пользовательский класс Response. Эти атрибуты относятся к классу Flask (а не к объекту), имеют понятные имена, благодаря которым можно узнать их назначение.
А здесь вы можете определить пользовательский класс Response. Эти атрибуты относятся к классу Flask (а не к объекту), имеют понятные имена, благодаря которым можно узнать их назначение.
 Класс Environment является подклассом класса Environment из Jinja2, который может понимать Flask Blueprints («Эскизы Flask»), что позволяет создавать более крупные приложения, состоящие из множества файлов.
Класс Environment является подклассом класса Environment из Jinja2, который может понимать Flask Blueprints («Эскизы Flask»), что позволяет создавать более крупные приложения, состоящие из множества файлов.
 Существуют и другие проявления модульности, которые здесь не показаны, поскольку мы не хотим повторяться.
Существуют и другие проявления модульности, которые здесь не показаны, поскольку мы не хотим повторяться.
Если вы взглянете на определение класса Flask, то увидите, где создаются и используются объекты этих классов. Мы показали их для того, чтобы вы поняли, что эти определения классов не должны быть доступны пользователю, — этот выбор был явно сделан при выборе структуры, чтобы дать пользователю больше возможностей контролировать поведение Flask. Когда пользователи говорят о модульности Flask, они имеют в виду не только применение любого бэкенда для базы данных. Подразумевается, что вы можете подключать и применять разные классы.
Вы увидели примеры качественно написанного кода, который следует принципам дзен. Мы рекомендуем взглянуть на полный код перечисленных здесь программ: лучший способ стать хорошим программистом — читать отличный код. И помните: когда писать код становится трудно, используй исходники, Люк!
Если вам нужна книга, материал которой основан на десятилетнем опыте чтения и рефакторинга кода, рекомендуем вам Object-Oriented Reengineering Patterns (издательство Square Bracket Associates) () за авторством Сержа Демейера (Serge Demeyer), Стефана Дюкасса (Stеphane Ducasse) и Оскара Нирстраса (Oscar Nierstrasz).
Демон — это компьютерная программа, которая работает как фоновый процесс.
Если вы столкнетесь с проблемой, когда lxml потребует более свежую версию библиотеки libxml2, установите более раннюю версию lxml, введя команду pip uninstall lxml; pip install lxml==3.5.0. Все сработает как надо.
Демонизируя процесс, вы создаете его копию, открепляете идентификатор сессии и копируете его снова, поэтому процесс будет полностью отключен от терминала, из которого вы его запускаете. Недемонизированные программы завершают работу при закрытии терминала — возможно, вы видели предупреждающее сообщение «Вы действительно хотите закрыть терминал? Это приведет к завершению запущенных процессов», за которым идет список запущенных в данный момент процессов. Демонизированный процесс продолжит работу после закрытия окна терминала. Он называется демоном в честь демона Максвелла () (умного демона, а не гнусного).
В PyCharm вы можете сделать это, выбрав пункты меню PyCharm—>Preferences—>Project:Diamond—>Project Interpreter, а затем указав пути к интерпретатору Python в текущей виртуальной среде.
В Python абстрактным считается класс, для которого отдельные методы не определены. Ожидается, что разработчик определит их в подклассе. В абстрактном базовом классе вызов этой функции сгенерирует исключение NotImplementedError. Более современная альтернатива — использовать модуль Python для абстрактных базовых классов (abc) () (впервые реализован в Python 2.6), который сгенерирует ошибку при создании объекта незавершенного класса. Полная спецификация приведена в PEP 3119 ().
Мы перефразировали отличную статью The Difference Between Complicated and Complex Matters () Ларри Кубана (Larry Cuban), заслуженного профессора Стэнфорда.
В Python предусмотрен лимит для рекурсии (максимальное количество раз, которое функция может вызвать сама себя) — он по умолчанию значительно ограничивает ваши возможности (существует для того, чтобы предупредить избыточное использование рекурсии). Вы можете узнать значение этого ограничения, введя import sys; sys.getrecursionlimit().
Язык программирования имеет функции первого класса, если он рассматривает функции как объекты первого класса. В частности, это означает, что язык поддерживает передачу функций в качестве аргументов другим функциям, возврат их как результат других функций, присваивание их переменным или сохранение в структурах данных.
PID расшифровывается как process identifier (идентификатор процесса). Каждый процесс имеет уникальный идентификатор, который доступен в Python благодаря модулю os в стандартной библиотеке: os.getpid().
В Python 2 по умолчанию применяется ASCII, в Python 3 — UTF-8. Существует несколько разрешенных способов взаимодействия между кодировками, все они перечислены в PEP 263 (/). Вы можете использовать тот, который лучше работает в вашем любимом текстовом редакторе.
Если вам нужно обновить свои знания о словаре, воспользуйтесь RFC 7231 — документом, содержащим семантику HTTP (). Если вы просмотрите его содержимое и прочтете введение, то сможете понять, упоминается ли нужное вам определение, и найти его.
Они определены в разделе 4.3 текущего рабочего предложения для HTTP ().
Модуль ранее назывался cookielib в Python 2, urllib.requests.Request ранее назывался urllib2.Request в Python 2.
Этот метод позволяет обрабатывать запросы из разных источников (вроде получения библиотеки JavaScript, размещенной на стороннем сайте). Он должен возвращать изначальный хост запроса, определенный в IETF RFC 2965.
С тех пор PEP 333 был заменен спецификацией, в которую были добавлены детали, характерные для Python 3, PEP 3333. Для получения вводной информации рекомендуем прочесть руководство по WSGI () Иэна Бикинга (Ian Bicking).
re.VERBOSE позволяет писать более читаемые регулярные выражения путем изменения обработки пробелов и добавления комментариев. Подробную информацию вы можете получить из документации к re ().
То есть, если объект можно вызвать, его можно проитерировать или же для него определен правильный метод…
Отсылка к Ruby on Rails, популяризовавшему веб-фреймворки, следущие стилю Django «все включено», а не стилю Flask «почти ничего не включено (пока вы не добавите надстройки)». Django — отличный выбор в том случае, если вам нужно именно та функциональность, которую предоставляет Django. Он был создан для поддержки онлайн-газеты (и отлично с этим справляется).
WSGI — это стандарт Python, определенный в PEP 333 и PEP 3333, в котором описывается, как приложение может связываться с веб-сервером.
В Python стек вызовов содержит исполняемые инструкции, запущенные интерпретатором Python. Поэтому если функция f() вызовет функцию g(), то f() пойдет на стек первой, а g() при вызове будет помещена выше f(). Когда функция g() возвращает значение, она удаляется из стека, и функция f() продолжает работу с того места, где прервалась. Стек называется так потому, что он работает точно так же, как посудомойка, которой требуется вымыть стопку тарелок: новые тарелки помещаются наверх, и вам всегда нужно начинать работу с верхних.
Игра слов use force — use source. — Примеч. пер.

