8. Управление кодом и его улучшение
В этой главе рассматриваются библиотеки, которые позволяют управлять процессами разработки, интеграцией систем, сервером и оптимизацией производительности, а также упрощать код.
Непрерывная интеграция
Никто не опишет процесс непрерывной интеграции лучше, чем Мартин Фаулер (Martin Fowler).
Непрерывная интеграция — это практика разработки ПО, согласно которой члены команды часто объединяют свои наработки. Обычно каждый человек делает это как минимум ежедневно, что приводит к выполнению множества интеграций за день. Каждая интеграция проверяется путем автоматической сборки (включая тесты), чтобы максимально быстро обнаружить ошибки интеграции. Многие команды считают, что такой подход значительно снижает количество проблем, возникающих при интеграции, а также позволяет быстрее разрабатывать целостность ПО.
Тремя наиболее популярными инструментами для непрерывной интеграции в данный момент являются Travis-CI, Jenkins и Buildbot (перечислены в следующих разделах). Они часто используются с Tox, инструментом Python для управления virtualenv и тестами из командной строки. Travis помогает работать с несколькими интерпретаторами Python на одной платформе, а Jenkins (самый популярный) и Buildbot (написан на Python) могут управлять сборками на нескольких машинах. Многие также используют Buildout (рассмотрен в подразделе «Buildout» раздела «Инструменты изоляции» главы 3) и Docker (рассмотрен в подразделе «Docker» там же) для быстрой и частой сборки сложных сред для батареи тестов.
Tox. Tox (/) — это инструмент автоматизации, предоставляющий функциональность упаковки, тестирования и развертывания ПО, написанного на Python, из консоли или сервера непрерывной интеграции. Является общим инструментом командной строки для управления и тестирования, который предоставляет следующие функции:
• проверка того, что все пакеты корректно устанавливаются для разных версий и интерпретаторов Python;
• запуск тестов в каждой среде, конфигурирование избранных инструментов тестирования;
• выступает в роли фронтенда для серверов непрерывной интеграции, снижая шаблонность и объединяя тесты для непрерывной интеграции и тесты для оболочки.
Вы можете установить Tox с помощью pip:
$ pip install tox
Системное администрирование
Инструменты, показанные в этом разделе, предназначены для наблюдения за системами и управления ими (автоматизация сервера, наблюдение за системами и управление потоком выполнения).
Travis-CI
Travis-CI (/) — распределенный сервер непрерывной интеграции, позволяющий создавать тесты для проектов с открытым исходным кодом бесплатно. Предоставляет несколько рабочих процессов, которые запускают тесты Python, и бесшовно интегрируется с GitHub. Вы даже можете указать ему оставлять комментарии для ваших запросов на включение, если этот конкретный набор изменений сломает сборку. Поэтому, если вы размещаете свой код на GitHub, Travis-CI — отличное средство, чтобы начать использовать непрерывную интеграцию. Travis-CI может собрать ваш код на виртуальной машине, на которой запущены Linux, OS X или iOS.
Для того чтобы начать работу, добавьте файл в расширением .travis.yml в ваш репозиторий. В качестве примера его содержимого приведем следующий код:
language: python
python:
- "2.6"
- "2.7"
- "3.3"
- "3.4"
script: python tests/test_all_of_the_units.py
branches:
only:
- master
Этот код указывает протестировать ваш проект для всех перечисленных версий Python путем запуска заданного сценария, сборка будет выполнена только для ветки master. Существует множество доступных параметров вроде уведомлений, предыдущих и последующих шагов и многих других (/). Для того чтобы использовать Tox вместе с Travis-CI, добавьте сценарий Tox в ваш репозиторий и измените строку с конструкцией script:; файл должен выглядеть так:
install:
- pip install tox
script:
- tox
Чтобы активизировать тестирование для вашего проекта, перейдите на сайт / и авторизуйтесь с помощью вашей учетной записи для GitHub. Далее активизируйте ваш проект в настройках профиля, и вы готовы к работе. С этого момента тесты для вашего проекта будут запускаться после каждой отправки кода в GitHub.
Jenkins
Jenkins CI (/) — это расширяемый движок непрерывной интеграции, в данный момент он считается самым популярным. Работает на Windows, Linux и OS X, его можно подключить к «каждому существующему инструменту управления исходным кодом». Jenkins является сервлетом Java (эквивалент приложений WSGI в Java), который поставляется с собственным контейнером сервлетов, что позволяет вам запускать его с помощью команды java --jar jenkins.war. Для получения более подробной информации обратитесь к инструкциям по установке Jenkins (); на странице Ubuntu содержится информация о том, как разместить Jenkins на базе обратного прокси Apache или Nginx.
Вы взаимодействуете с Jenkins с помощью информационной панели или его RESTful API, основанного на НТТР (например, по адресу ), что означает, что можно использовать HTTP для того, чтобы общаться с Jenkins с удаленных машин. Например, взгляните на Jenkins Dashboard (/) для Apache или Pylons (/).
Для взаимодействия с Jenkins API в Python наиболее часто применяется python-jenkins (), созданный командой OpenStack (/). Большинство пользователей Python конфигурируют Jenkins так, чтобы он запускал сценарий Tox как часть процесса сборки. Для получения более подробной информации обратитесь к документации по адресу , где рассказывается об использовании Tox для Jenkins, а также к руководству по настройке Jenkins для работы с несколькими машинами.
Buildbot
Buildbot (/) — это система Python, предназначенная для автоматизации цикла компиляции/тестирования, проверяющего изменения кода. Похож на Jenkins тем, что опрашивает менеджер системы контроля версий на наличие изменений, выполняет сборку и тестирование вашего кода на нескольких компьютерах в соответствии с вашими инструкциями (имеет встроенную поддержку для Tox), а затем говорит вам, что произошло. Он работает на базе веб-сервера Twisted. Если вам нужен пример того, как будет выглядеть веб-интерфейс, взгляните на общедоступную информационную панель buildbot от Chromium () (с помощью Chromium работает браузер Chrome).
Поскольку Buildbot написан на чистом Python, его можно установить с помощью pip:
$ pip install buildbot
Версия 0.9 имеет REST API (), но она все еще находится на стадии бета-тестирования, поэтому вы не сможете ее использовать, если только явно не укажете номер версии (например, pip install buildbot==0.9.00.9.0rc1). Buildbot имеет репутацию самого мощного и самого сложного инструмента непрерывной интеграции. Для начала работы с ним обратитесь к этому отличному руководству: .
Автоматизация сервера
Salt, Ansible, Puppet, Chef и CFEngine — это инструменты для автоматизации сервера, которые предоставляют системным администраторам элегантный способ управлять их флотом физических и виртуальных машин. Все они могут управлять машинами, на которых установлены Linux, Unix-подобные системы, а также Windows.
Конечно, мы можем использовать только Salt и Ansible, поскольку они написаны на Python. Но они относительно новые, другие же варианты применяются более широко. В следующих разделах проведен их краткий обзор.

Разработчики Docker ожидают, что инструменты по автоматизации систем вроде Salt, Ansible и прочих будут дополнены Docker, а не заменены им. Взгляните на статью о том, как Docker работает с остальным ПО для DevOps.
Salt
Salt (/) называет свой главный узел мастером, а узлы-агенты — миньонами или хостами-миньонами. Его основная цель — высокая скорость; работа с сетью по умолчанию выполняется с помощью ZeroMQ, между мастером и миньонами устанавливается соединение TCP. Члены команды разработчиков Salt написали свой (необязательный) протокол передачи данных RAET (), который работает быстрее, чем TCP, и теряет не так много данных, как UDP.
Salt поддерживает версии Python 2.6 и 2.7, его можно установить с помощью команды pip:
$ pip install salt # Для Python 3 версии пока нет...
После конфигурирования сервера-мастера и любого количества хостов-миньонов мы можем запускать для миньонов произвольные команды оболочки или использовать заранее созданные модули, состоящие из сложных команд. Следующая команда перечисляет всех доступных миньонов с помощью команды ping из модуля тестирования salt:
$ salt '*' test.ping
Вы можете отфильтровать хосты-миньоны либо по их идентификатору, либо с помощью системы grains (), которая использует статическую информацию хоста вроде версии операционной системы или архитектуры ЦП, чтобы предоставить таксономию хостов для модулей Salt. Например, следующая команда применяет систему grains для перечисления только тех миньонов, на которых запущена CentOS:
$ salt -G 'os:CentOS' test.ping
Salt также предоставляет систему состояний. Состояния могут быть использованы для конфигурирования хостов-миньонов. Например, когда миньону указывается прочесть следующий файл состояний, он установит и запустит сервер Apache:
apache:
pkg:
- installed
service:
- running
- enable: True
- require:
- pkg: apache
Файлы состояний могут быть написаны с помощью YAML, дополненной системой шаблонов Jinja2, или же могут быть чистыми модулями Python. Для получения более подробной информации обратитесь к документации Salt по адресу /.
Ansible
Самое большое преимущество Ansible (/) перед другими системами автоматизации — для ее установки на клиентских машинах не требуется ничего (кроме Python). Все другие варианты поддерживают на клиентах демонов, которые опрашивают мастера. Их конфигурационные файлы имеют формат YAML. Сценарии — это документы для конфигурирования, развертывания и управления для Ansible, они написаны на YAML и используют для шаблонов язык Jinja2. Ansible поддерживает версии Python 2.6 и 2.7, ее можно установить с помощью pip:
$ pip install ansible # Для Python 3 версии пока нет...
Ansible требует наличия файла инвентаря, в котором описывается, к каким хостам он имеет доступ. В следующем фрагменте кода показывается пример хоста и сценария, который опрашивает все хосты в файле инвентаря. Рассмотрим пример файла инвентаря (hosts.yml):
[server_name]
127.0.0.1
Рассмотрим пример сценария (ping.yml):
---
- hosts: all
tasks:
- name: ping
action: ping
Для того чтобы запустить сценарий, введите следующую команду:
$ ansible-playbook ping.yml -i hosts.yml --ask-pass
Сценарий Ansible будет опрашивать все серверы, перечисленные в файле hosts.yml. С помощью Ansible вы можете выбрать группы серверов. Для получения более подробной информации об Ansible прочтите документацию к ней (/). Руководство по Ansible Servers for Hackers (/) также содержит подробную информацию.
Puppet
Puppet написан на Ruby и предоставляет собственный язык — PuppetScript — для конфигурирования. Имеет выделенный сервер Puppet Master, который отвечает за управление узлами-агентами. Модули — это небольшие разделяемые единицы кода, написанные для автоматизации или определения состояния системы. Puppet Forge (/) — это репозиторий для модулей, написанных сообществом для Open Source Puppet и Puppet Enterprise.
Узлы-агенты отправляют основную информацию о системе (например, операционную систему, ядро, архитектуру, IP-адрес и имя хоста) Puppet Master. Puppet Master компилирует на ее основе каталог данных о том, как нужно конфигурировать каждый узел, и пересылает его агенту. Агент выполняет изменения на основе того, что указано в каталоге, и отправляет Puppet Master отчет о проделанной работе.
Facter (да, его имя заканчивается на -er) — весьма интересный инструмент, который поставляется с Puppet и получает основную информацию о системе. Вы можете сослаться на эти факты как на переменные при написании модулей Puppet:
$ facter kernel
Linux
$
$ facter operatingsystem
Ubuntu
Процесс написания модулей в Puppet довольно прямолинеен: манифесты Puppet (файлы с расширением *.pp) формируют модули Puppet. Рассмотрим пример приложения Hello World для Puppet:
notify { 'Hello World, this message is getting logged into the agent node':
#As nothing is specified in the body, the resource title
#is the notification message by default.
}
Перед вами еще один пример, использующий логику системы. Чтобы обратиться к другим фактам, добавьте знак $ к имени переменной, например $hostname (в нашем случае $operatingsystem):
notify{ 'Mac Warning':
message => $operatingsystem ? {
'Darwin' => 'This seems to be a Mac.',
default => 'I am a PC.',
},
}
Для Puppet существует несколько типов ресурсов, но парадигма «пакет-файл-сервис» — это все, что вам нужно для выполнения большинства задач по управлению конфигурацией. Следующий код Puppet позволяет убедиться, что пакет OpenSSH-Server устанавливается в системе. Сервису sshd (демон сервера SSH) указывается выполнять перезапуск каждый раз, когда изменяется конфигурационный файл sshd:
package { 'openssh-server':
ensure => installed,
}
file { '/etc/ssh/sshd_config':
source => 'puppet:///modules/sshd/sshd_config',
owner => 'root',
group => 'root',
mode => '640',
notify => Service['sshd'], # sshd перезапустится
# после каждого изменения этого файла
require => Package['openssh-server'],
}
service { 'sshd':
ensure => running,
enable => true,
hasstatus => true,
hasrestart=> true,
}
Для получения более подробной информации обратитесь к документации к Puppet Labs (/).
Chef
Если для управления конфигурацией вы выбираете Chef (/), то для написания кода инфраструктуры будете использовать язык Ruby. Chef похож на Puppet, но разработан с противоположной философией: Puppet предоставляет фреймворк, который упрощает работу за счет гибкости, а Chef практически не предоставляет фреймворка (его цель — быть очень гибким, поэтому его сложнее использовать).
Клиенты Chef работают на каждом узле вашей инфраструктуры и регулярно опрашивают сервер Chef, чтобы гарантировать, что ваша система всегда находится в рабочем состоянии.
Каждый отдельный клиент Chef конфигурирует себя самостоятельно. Такой подход делает Chef масштабируемой платформой по автоматизации.
Chef для работы использует пользовательские рецепты (элементы конфигурации), реализованные в cookbooks.Cookbooks, которые, по сути, являются пакетами для инфраструктурного выбора и обычно хранятся на сервере Chef. Прочтите серию руководств от DigitalOcean, посвященных Chef (), чтобы узнать, как создать просто сервер Chef.
Используйте команду knife для создания поваренной книги:
$ knife cookbook create cookbook_name
Статья Энди Гейла (Andy Gale) Getting started with Chef () — хорошая стартовая точка для тех, кто начинает работать с Chef.
Множество поваренных книг сообщества вы можете найти в Chef Supermarket — с их помощью вы легко сможете начать писать собственные поваренные книги. Для получения более подробной информации обратитесь к полной документации Chef (/).
CFEngine
CFEngine имеет крошечный отпечаток, поскольку написан на C. Основная цель ее проекта — отказоустойчивость. Она достигается с помощью автономных агентов, работающих в распределенной сети (в противоположность архитектуре мастер/клиент), которые общаются с использованием теории обещаний (). Если вам нужна архитектура без мастера, попробуйте эту систему.
Наблюдение за системами и задачами
Следующие библиотеки помогут всем системным администраторам наблюдать запущенные задачи, но их приложения значительно отличаются друг от друга: Psutil предоставляет информацию в Python, которая может быть получена вспомогательными функциями Unix, Fabric позволяет легко определить и выполнить команды для набора удаленных хостов с помощью SSH, а Luigi помогает планировать запуск и наблюдение за долгоиграющими пакетными процессами вроде цепочек команд Hadoop.
Psutil
Psutil (/) — это кросс-платформенный (включая Windows) интерфейс для разного рода системной информации (например, ЦП, памяти, дисков, сети, пользователей и процессов). Позволяет с помощью Python получить доступ к информации, которую многие из нас привыкли получать, используя команды Unix () вроде top, ps, df и netstat. Установите его с помощью pip:
$ pip install psutil
Рассмотрим пример, который наблюдает за перегрузкой сервера (если какой-то тест — сети или ЦП — даст сбой, он отправит электронное письмо):
# Функции для получения значений системы:
from psutil import cpu_percent, net_io_counters
# Функции для перерыва:
from time import sleep
# Пакет для сервисов электронной почты:
import smtplib
import string
MAX_NET_USAGE = 4 00000
MAX_ATTACKS = 4
attack = 0
counter = 0
while attack <= MAX_ATTACKS:
sleep(4)
counter = counter + 1
# Проверяем использование ЦП
if cpu_percent(interval = 1) > 70:
attack = attack + 1
# Проверяем использование сети
neti1 = net_io_counters()[1]
neto1 = net_io_counters()[0]
sleep(1)
neti2 = net_io_counters()[1]
neto2 = net_io_counters()[0]
# Рассчитываем байты в секунду
net = ((neti2+neto2) - (neti1+neto1))/2
if net > MAX_NET_USAGE:
attack = attack + 1
if counter > 25:
attack = 0
counter = 0
# Пишем очень важное электронное письмо, если значение параметра attack больше 4
TO = ""
FROM = ""
SUBJECT = "Your domain is out of system resources!"
text = "Go and fix your server!"
BODY = string.join(
("From: %s" %FROM,"To: %s" %TO,"Subject: %s" %SUBJECT, "",text), "\r\n")
server = smtplib.SMTP('127.0.0.1')
server.sendmail(FROM, [TO], BODY)
server.quit()
Хорошим примером использования Psutil является glances (/) — полностью консольное приложение, которое ведет себя как расширенная версия top (перечисляет запущенные процессы, упорядочивая их по использованию ЦП или другим способом, указанным пользователем) и имеет возможность наблюдать за клиентом и сервером.
Fabric
Fabric (/) — это библиотека, предназначенная для упрощения задач системного администратора. Позволяет соединяться с помощью SSH с несколькими хостами и выполнять задачи для каждого из них. Это удобно для системных администраторов, а также для тех, кто развертывает приложения. Чтобы установить Fabric, используйте pip:
$ pip install fabric
Рассмотрим полный модуль Python, определяющий две задачи Fabric: memory_usage и deploy:
# fabfile.py
from fabric.api import cd, env, prefix, run, task
env.hosts = ['my_server1', 'my_server2'] # С чем соединяться по SSH
@task
def memory_usage():
run('free -m')
@task
def deploy():
with cd('/var/'):
with prefix('. ../bin/activate'):
run('git pull')
run('touch app.wsgi')
Оператор with вкладывает команды друг в друга, поэтому в конечном счете метод deploy() для каждого хоста начинает выглядеть так:
$ ssh имя_хоста cd /var/ww/project-env/project && ../bin/activate && git pull
$ ssh имя_хоста cd /var/ww/project-env/project && ../bin/activate && \
> touch app.wsgi
Учитывая предыдущий код, сохраненный в файле fabfile.py (имя модуля по умолчанию, которое ищет fab), мы можем проверить использование памяти с помощью нашей новой задачи memory_usage:
$ fab memory_usage
[my_server1] Executing task 'memory'
[my_server1] run: free -m [my_server1] out: total used free shared buffers cached
[my_server1] out: Mem: 6964 1897 5067 0 166 222
[my_server1] out: -/+ buffers/cache: 1509 5455
[my_server1] out: Swap: 0 0 0
[my_server2] Executing task 'memory'
[my_server2] run: free -m [my_server2] out: total used free shared buffers cached
[my_server2] out: Mem: 1666 902 764 0 180 572
[my_server2] out: -/+ buffers/cache: 148 1517
[my_server2] out: Swap: 895 1 894
И мы можем выполнить развертывание:
$ fab deploy
Дополнительная функциональность включает параллельное исполнение, взаимодействие с удаленными программами и группирование хостов. В документации к Fabric (/) приведены понятные примеры.
Luigi
Luigi () — это инструмент для управления конвейером, разработанный и выпущенный компанией Spotify. Помогает разработчикам управлять целым конвейером крупных долгоиграющих пакетных задач, объединяя запросы Hive, запросы к базе данных, задачи Hadoop Java, задачи pySpark и многие другие задачи, которые вы можете написать самостоятельно. Они не должны быть приложениями, работающими с большими данными, API позволяет запланировать что угодно. Spotify позволил запускать задачи с помощью Hadoop, поэтому разработчики предоставляют все необходимые вспомогательные программы в пакете luigi.contrib (). Установите его с помощью pip:
$ pip install luigi
Включает в себя веб-интерфейс, поэтому пользователи могут фильтровать свои задачи и просматривать графики зависимостей для рабочего потока конвейера и их продвижение. В репозитории GitHub вы можете найти примеры задач Luigi, также можете просмотреть документацию к Luigi.
Скорость
В этом разделе перечислены наиболее популярные способы оптимизации скорости, используемые сообществом Python. В табл. 8.1 показаны варианты оптимизации, которые вы можете применить после того, как попробуете простые методы вроде запуска профайлера () и сравнения параметров для сниппетов кода ().
Вы, возможно, уже слышали о глобальной блокировке интерпретатора (global interpreter lock, GIL) (). Это способ, с помощью которого реализация C для Python позволяет нескольким потокам работать одновременно.
Управление памятью в Python не полностью потокобезопасно, поэтому GIL нужен для того, чтобы помешать нескольким потокам запускать одновременно один и тот же код.
GIL зачастую называют ограничением Python, но он не является такой уж большой проблемой — мешает лишь тогда, когда процессы связаны с ЦП (в этом случае, как и для NumPy или криптографических библиотек, которые мы рассмотрим далее, код переписан на C со связыванием с Python). Для всего прочего (для ввода/вывода в сетях или файлах) узким местом является код, блокирующий один поток, ожидающий завершения операции ввода/вывода. Вы можете решить проблему с блокировкой с помощью потоков или событийно-ориентированного программирования.
Отметим, что в Python 2 имеются медленная и быстрая версии библиотек — StringIO и cStringIO, ElementTree и cElementTree. Реализации на C работают быстрее, но их нужно явно импортировать. Начиная с версии Python 3.3 обычные версии импортируют быструю реализацию там, где это возможно, а библиотеки, чье имя начинается с C, считаются устаревшими.
Таблица 8.1. Способы ускорения работы
| Способ | Лицензия | Причины использовать |
| Многопоточность | PSFL | Позволяет создавать несколько потоков выполнения. Многопоточность (при использовании CPython из-за наличия GIL) не задействует собственные процессы; разные потоки переключаются, когда один из них заблокирован (это полезно, когда узким местом является какая-нибудь блокирующая задача вроде ожидания окончания операции ввода/вывода). GIL отсутствует в некоторых других реализациях Python вроде Jython и IronPython |
| Multiprocessing/subprocess | PSFL | Инструменты библиотеки multiprocessing позволяют создавать другие процессы Python, минуя GIL. Subprocess позволяет запускать несколько процессов командной строки |
| PyPy | Лицензия MIT | Этот интерпретатор Python (в данный момент для версии Python 2.7.10 или 3.2.5) предоставляет возможность динамической компиляции в код на языке С там, где это возможно. |
|
|
| Не требует усилий: вам не нужно писать код, при этом он дает значительный прирост скорости. Полноценная замена для CPython, которая обычно работает (любые библиотеки, написанные на С, должны использовать CFFI или находиться в списке совместимости PyPy ()) |
| Cython | Лицензия Apache | Предоставляет два способа статически скомпилировать код Python: использование языка аннотаций Cython (*.pxd); статистическое компилирование кода на чистом Python и применение декораторов Cython для указания типа объекта |
| Numba | Лицензия BSD | Предоставляет статический (благодаря инструменту pycc) и динамический компиляторы, компилирующие код в машинный код. Использует массивы NumPy. Требуется версия Python 2.7 или 3.4, библиотека llvmlite () и ее зависимость, инфраструктура LLVM (Low-Level Virtual Machine) |
| Weave | Лицензия BSD | Предоставляет способ «сплести» несколько строк кода на C в код на Python (применяйте его только в том случае, если вы уже используете Weave). В противном случае используйте Cython — Weave считается устаревшим |
| PyCUDA/gnumpy/ TensorFlow/ Theano/PyOpenCL | MIT/модифицированная лицензия BSD/BSD/BSD/MIT | Эти библиотеки предоставляют разные способы использования NVIDIA GPU, если он у вас установлен, и могут установить набор инструментов для CUDA (/). PyOpenCL может использовать процессоры не только от NVIDIA. Для каждого из них существует собственное приложение, например gnumpy предполагается как полноценная замена для NumPy |
| Непосредственное использование библиотек C/C++ | — | Повышение скорости стоит того, чтобы потратить дополнительное время на написание кода на C/C++ |
Джефф Напп (Jeff Knupp), автор книги Writing Idiomatic Python (), написал статью о том, как обойти GIL (), процитировав статью Дэвида Бизли (David Beazley) на эту тему.
Многопоточность и другие способы оптимизации, показанные в табл. 8.1, более подробно рассматриваются в следующих разделах.
Многопоточность
Библиотека для работы с потоками в Python позволяет создать несколько потоков. Из-за GIL (во всяком случае в CPython) только один процесс Python может быть запущен для каждого интерпретатора; это означает, что прирост производительности появится только в том случае, если хотя бы один поток заблокирован (например, для ввода/вывода). Еще один вариант для ввода/вывода — обработка событий. Чтобы узнать подробнее, прочтите абзацы, связанные с asyncio, в подразделе «Производительность сетевых инструментов из стандартной библиотеки Python» раздела «Распределенные системы» главы 9.
Когда у вас есть несколько потоков Python, ядро замечает, что один из потоков заблокирован для ввода-вывода, и оно переключается, чтобы позволить следующему потоку использовать процессор до тех пор, пока он не будет заблокирован или не завершится. Все это происходит автоматически, когда вы запускаете ваши потоки. Есть хороший пример применения многопоточности на сайте Stack Overflow (), для серии Python Module of the Week написана отличная статья на тему многопоточности (/). Вы также можете просмотреть документацию стандартной библиотеки, посвященную работе с потоками ().
Модуль multiprocessing
Модуль multiprocessing () стандартной библиотеки Python предоставляет способ обойти GIL путем запуска дополнительных интерпретаторов Python. Отдельные процессы могут общаться друг с другом с помощью запросов multiprocessing.Pipe или multiprocessing.Queue; также они могут делиться памятью с помощью запросов multiprocessing.Array или multiprocessing.Value, что автоматически реализует блокировки. Осторожно делитесь данными; эти объекты реализуют блокировку для того, чтобы предотвратить одновременный доступ разных процессов.
Рассмотрим пример, иллюстрирующий прирост скорости, который появляется в результате использования пула работников. Существует компромисс между сэкономленным временем и временем, затрачиваемым на переключение между интерпретаторами. В примере используется метод Монте-Карло для оценки значения числа пи:
>>> import multiprocessing

 Использование multiprocessing.Pool внутри менеджера контекста указывает, что пул должен применяться только тем процессом, который его создал.
Использование multiprocessing.Pool внутри менеджера контекста указывает, что пул должен применяться только тем процессом, который его создал.
 Общее количество итераций останется неизменным, оно лишь будет поделено на разное количество процессов.
Общее количество итераций останется неизменным, оно лишь будет поделено на разное количество процессов.
 Метод pool.map() создает несколько процессов — по одному на каждый элемент списка итераций; максимальное количество равно числу, указанному при инициализации пула (в вызове multiprocessing.Pool(processes)).
Метод pool.map() создает несколько процессов — по одному на каждый элемент списка итераций; максимальное количество равно числу, указанному при инициализации пула (в вызове multiprocessing.Pool(processes)).
 Существует только один процесс для первого испытания timeit.
Существует только один процесс для первого испытания timeit.
 10 повторений одного процесса с 10 миллионами итераций заняли 134 секунды.
10 повторений одного процесса с 10 миллионами итераций заняли 134 секунды.
 Для второго испытания timeit создано 10 процессов.
Для второго испытания timeit создано 10 процессов.
 10 повторений десяти процессов, каждый из которых имеет один миллион итераций, заняли 74 секунды.
10 повторений десяти процессов, каждый из которых имеет один миллион итераций, заняли 74 секунды.
Идея заключается в том, что существуют накладные расходы при создании нескольких процессов, но инструменты, позволяющие запустить с помощью Python несколько процессов, довольно надежны. Для получения более подробной информации просмотрите документацию о библиотеке multiprocessing в стандартной библиотеке (), а также прочитайте статью Джеффа Наппа (Jeff Knupp) о том, как обойти GIL (пара абзацев посвящены этой библиотеке) ().
Subprocess
Библиотека subprocess () была представлена в версии стандартной библиотеки для Python 2.4, определена в PEP 324 (). Выполняет системный вызов (вроде unzip или curl), как если бы она была вызвана из командной строки (по умолчанию, не вызывая системную оболочку ()), а разработчик выбирает, что нужно сделать с входным и выходным конвейерами subprocess. Мы рекомендуем пользователям Python 2 получить обновленную версию пакета subprocess32, в которой исправляются некоторые ошибки. Установите его с помощью pip:
$ pip install subprocess32
В блоге Python Module of the Week вы можете найти отличное руководство по subprocess (/).
PyPy
PyPy — это реализация Python на чистом Python. Она быстра; и когда она работает, вам не нужно больше ничего делать со своим кодом — он будет работать без дополнительных усилий. Вам следует воспользоваться этим вариантом в первую очередь.
Вы не можете получить ее с помощью команды pip, поскольку, по сути, это еще одна реализация Python. На странице загрузок PyPy вы можете найти корректную версию реализации для вашей версии Python и операционной системы.
Существует модифицированная версия тестового кода, ограниченная по процессору, от Дэвида Бизли (David Beazley) (), в которую добавлен цикл для выполнения нескольких тестов. Вы можете увидеть разницу между PyPy и CPython.
Сначала запустим ее с помощью CPython:
$ # CPython
$ ./python -V Python 2.7.1
$
$ ./python measure2.py
1.0 67744 01665 1.4 54123 97385 1.5 14852 04697 1.5 46938 89618 1.6 01091 14647
А теперь запустим тот же сценарий, но изменим интерпретатор Python — выберем PyPy:
$ # PyPy
$ ./pypy -V Python 2.7.1 (7773f8fc4223, Nov 18 2011, 18:47:10)
[PyPy 1.7.0 with GCC 4.4.3]
$
$ ./pypy measure2.py
0.068 39990 61584 0.048 32100 86823 0.038 85889 05334 0.044 06905 17426 0.069 53001 02234
Получается, что благодаря простой загрузке PyPy мы сократили время работы сценария с 1,4 секунды до 0,05 — практически в 20 раз. Порой ваш код будет ускорен менее чем в два раза, но иногда вы сможете значительно его ускорить. И для этого не нужно прикладывать никаких усилий, за исключением загрузки интерпретатора PyPy. Если хотите, чтобы ваша библиотека, написанная на C, была совместима с PyPy, следуйте советам PyPy () и используйте CFFI вместо ctypes из стандартной библиотеки.
Cython
К сожалению, PyPy работает не со всеми библиотеками, использующими расширения, написанные на C. Для этих случаев Cython (произносится «сайтон» — это не то же самое, что CPython, стандартная реализация Python, созданная с помощью C) (/) реализует superset языка Python (можно писать модули Python на C и C++). Cython дает возможность вызывать функции из скомпилированных библиотек на C и предоставляет контекст nogil, позволяющий обойти GIL для раздела кода (он не манипулирует объектами Python) (). Применяя Cython, вы можете воспользоваться преимуществами строгого типизирования в Python переменных и операций.
Рассмотрим пример строгой типизации с помощью Cython:
def primes(int kmax):
"""Расчет простых чисел с помощью дополнительных ключевых слов Cython """
cdef int n, k, i
cdef int p[1000]
result = []
if kmax > 1000:
kmax = 1000
k = 0
n = 2
while k < kmax:
i = 0
while i < k and n % p[i] != 0:
i = i + 1
if i == k:
p[k] = n
k = k + 1
result.append(n)
n = n + 1
return result
Эта реализация алгоритма поиска простых чисел содержит дополнительные ключевые слова. Следующий пример написан на чистом Python:
def primes(kmax):
""" Расчет простых чисел с помощью стандартного синтаксиса Python """
p= range(1000)
result = []
if kmax > 1000:
kmax = 1000
k = 0
n = 2
while k < kmax:
i = 0
while i < k and n % p[i] != 0:
i = i + 1
if i == k:
p[k] = n
k = k + 1
result.append(n)
n = n + 1
return result
Обратите внимание: в версии Cython вы объявляете, что целые числа и массивы целых чисел будут скомпилированы в типы C, в то же время будет создан список Python:


 Тип объявляется как целое число.
Тип объявляется как целое число.
 Переменные n, k и i объявляются как целые числа.
Переменные n, k и i объявляются как целые числа.
 Мы заранее выделяем память для массива целых чисел p размером в 1000 элементов.
Мы заранее выделяем память для массива целых чисел p размером в 1000 элементов.
В чем же разница? В версии Cython вы можете увидеть объявление типов переменных и массива целых чисел, которые выглядят так же, как и в обычном С. Например, дополнительное объявление типа (целочисленного) в выражении cdef int n,k,i позволяет компилятору Cython генерировать более эффективный код С. Поскольку синтаксис несовместим со стандартным Python, он сохраняется в файлах с расширением *.pyx, а не с расширением *.py.
Каковы различия в скорости? Давайте проверим!

 Модуль pyximport позволяет импортировать файлы с расширением *.pyx (например, primesCy.pyx) с помощью скомпилированной в Cython версии функции primes.
Модуль pyximport позволяет импортировать файлы с расширением *.pyx (например, primesCy.pyx) с помощью скомпилированной в Cython версии функции primes.
 Команда pyximport.install() позволяет интерпретатору Python непосредственно запустить компилятор Cython для генерации кода C, который автоматически компилируется в библиотеку с расширением *.so. Далее Cython может легко и эффективно импортировать эту библиотеку в ваш код Python.
Команда pyximport.install() позволяет интерпретатору Python непосредственно запустить компилятор Cython для генерации кода C, который автоматически компилируется в библиотеку с расширением *.so. Далее Cython может легко и эффективно импортировать эту библиотеку в ваш код Python.
 С помощью функции time.time() вы можете сравнить время выполнения этих двух вызовов, которые определяют 500 простых чисел. На стандартном ноутбуке (dual-core AMD E-450 1.6 GHz) мы получили следующие значения:
С помощью функции time.time() вы можете сравнить время выполнения этих двух вызовов, которые определяют 500 простых чисел. На стандартном ноутбуке (dual-core AMD E-450 1.6 GHz) мы получили следующие значения:
Cython time: 0.0054 seconds
Python time: 0.0566 seconds
А здесь результат работы встроенной машины ARM BeagleBone ():
Cython time: 0.0196 seconds
Python time: 0.3302 seconds
Numba
Numba (/) — это компилятор для Python, поддерживающий NumPy (он является динамическим — just-in-time (JIT)). Компилирует аннотированный код Python (и NumPy) для LLVM (Low-Level Virtual Machine) (/) с помощью особых декораторов. Вкратце, Numba использует LLVM для компилирования кода Python в машинный код, который может быть нативно выполнен во время работы программы.
Если вы используете Anaconda, установите Numba с помощью команды conda install numba. Если нет, установите его вручную. Вы должны заранее установить NumPy и LLVM (перед Numba).
Проверьте, какая версия LLVM вам нужна (на странице PyPI для llvmlite по адресу ), и загрузите ее для вашей ОС:
• сборки LLVM для Windows (/);
• сборки LLVM для Debian/Ubuntu (/);
• сборки LLVM для Fedora ();
• вы можете найти информацию о том, как устанавливать LLVM на основе исходного кода для других систем Unix, в разделе «Сборка компиляторов Clang + LLVM» (/);
• для OS X используйте команду brew install homebrew/versions/llvm37 (или выберите текущую версию).
Как только вы установите LLVM и NumPy, инсталлируйте Numba с помощью pip. Вам может понадобиться помочь установщику найти файл llvm-config, предоставив переменной среды LLVM_CONFIG соответствующий путь, например:
$ LLVM_CONFIG=/path/to/llvm-config-3.7 pip install numba
Чтобы использовать его в своем коде, декорируйте свои функции:
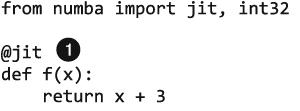
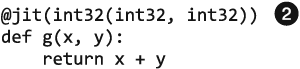
 Без аргументов декоратор @jit выполняет ленивую компиляцию — сам решает, оптимизировать ли функцию и как это сделать.
Без аргументов декоратор @jit выполняет ленивую компиляцию — сам решает, оптимизировать ли функцию и как это сделать.
 Для ранней компиляции укажите типы. Функция будет скомпилирована с указанной специализацией, ни одну другую специализацию использовать не получится, возвращаемое значение и два аргумента будут иметь тип numba.int32.
Для ранней компиляции укажите типы. Функция будет скомпилирована с указанной специализацией, ни одну другую специализацию использовать не получится, возвращаемое значение и два аргумента будут иметь тип numba.int32.
Флаг nogil позволит коду игнорировать глобальную блокировку интерпретатора, а модуль numba.pycc можно использовать для компилирования кода заранее. Для получения более подробной информации обратитесь к руководству пользователя для Numba ().
Библиотеки для работы с GPU
Numba опционально может быть создан с той производительностью, которая позволит ему работать на графическом процессоре (graphics processing unit, GPU), оптимизированном для выполнения быстрых параллельных вычислений в современных видеоиграх. Вам понадобится NVIDIA GPU, также нужно установить тулкит CUDA Toolkit от NVIDIA (). Далее следуйте инструкциям документации по использованию Numba’s CUDA JIT для GPU ().
Помимо Numba, еще одной популярной библиотекой, которая может работать с GPU, является TensorFlow (/). Выпущена компанией Google под лицензией Apache v2.0. Предоставляет возможность использовать тензоры (многомерные матрицы), а также способ объединить в цепочку операции над ними для более быстрого выполнения операций над матрицами.
На данный момент она может использовать GPU только в операционных системах Linux. Для получения более подробных инструкций обратитесь к следующим страницам:
• установка TensorFlow с поддержкой GPU — ;
• установка TensorFlow без поддержки GPU — .
Среди тех, кто не пользуется Linux, до того как компания Google опубликовала TensorFlow (/), привычным вариантом работы с матричной математикой с помощью GPU была библиотека Theano, активно разрабатываемая в Монреальском университете. Для нее создана страница, посвященная использованию GPU (). Theano поддерживает операционные системы Windows, OS X и Linux. Доступна по команде pip:
$ pip install Theano
Для низкоуровневого взаимодействия с GPU вы можете использовать PyCUDA ().
Наконец, те, у кого нет NVIDIA GPU, могут использовать PyOpenCL (), обертку для библиотеки OpenCL от Intel (), которая совместима с несколькими разными аппаратными наборами ().
Взаимодействие с библиотеками, написанными на C/C++/FORTRAN
Все библиотеки, описанные в следующих разделах, отличаются друг от друга. CFFI и ctypes написаны на Python, F2PY нужна для FORTRAN, SWIG позволяет использовать объекты языка C во многих языках (не только Python), а Boost.Python (библиотека C++) — объекты языка C++ в коде Python и наоборот. В табл. 8.2 приводится более подробная информация.
Таблица 8.2. Интерфейсы С и С++
| Библиотека | Лицензия | Причины использовать |
| CFFI | Лицензия MIT | Лучшая совместимость с PyPy. Позволяет писать код С изнутри Python, который может быть скомпилирован для сборки общей библиотеки С со связыванием Python |
| ctypes | Лицензия Python Software Foundation | Находится в стандартной библиотеке Python. Позволяет оборачивать существующие DLL или общие объекты, которые писали не вы. Вторая по качеству совместимость с PyPy |
| F2PY | Лицензия BSD | Позволяет использовать библиотеку FORTRAN. F2PY является частью библиотеки NumPy, поэтому вам следует применять NumPy |
| SWIG | GPL (output не ограничен) | Позволяет автоматически генерировать библиотеки на многих языках, используя специальный формат файла, который не похож ни на C, ни на Python |
| Boost.Python | Лицензия Boost Software | Этот инструмент не относится к командной строке. Это библиотека С++, которая может быть включена в код С++ и использована для определения того, какие объекты должны быть доступны Python |
C Foreign Function Interface
Пакет CFFI (/) предоставляет простой механизм для взаимодействия с кодом, написанным на C, из Python и PyPy. CFFI рекомендуется использовать с PyPy () для наилучшей совместимости между CPython и PyPy. Он поддерживает два режима: встроенный режим совместимости для бинарных интерфейсов приложения (application binary interface, ABI) (смотрите следующий пример кода) позволяет динамически загружать и запускать функции из исполняемых модулей (по сути, предоставляет такую же функциональность, как LoadLibrary или dlopen), а также режим API, который позволяет выполнять сборку модулей расширения C.
Установите его с помощью pip:
$ pip install cffi
Рассмотрим пример взаимодействия ABI:

 Строка может быть получена из объявления функции, расположенного в заголовочном файле С.
Строка может быть получена из объявления функции, расположенного в заголовочном файле С.
 Открываем общую библиотеку (*.DLL или *.so).
Открываем общую библиотеку (*.DLL или *.so).
 Теперь мы можем относиться к clib как к модулю Python и просто вызываем функции, которые определили с помощью точечной нотации.
Теперь мы можем относиться к clib как к модулю Python и просто вызываем функции, которые определили с помощью точечной нотации.
ctypes
ctypes () — это выбор де-факто для взаимодействия с кодом на C/C++ и CPython; находится в стандартной библиотеке. Предоставляет полный доступ к нативному интерфейсу на С для большей части операционных систем (например, kernel32 для Windows, или libc для *nix), а также поддерживает загрузку и взаимодействие с динамическими библиотеками — разделяемыми объектами (*.so) или DLL — во время выполнения программы. Вместе с ctypes поставляется множество типов для взаимодействия с API системы, что позволяет вам легко определить собственные сложные типы вроде структур и объединений, а также модифицировать элементы вроде внутренних полей и выравнивания, если это нужно. Она может быть несколько неудобна в использовании (поскольку вам нужно вводить много дополнительных символов), но вместе с модулем стандартной библиотеки struct () у вас, по сути, будет полный контроль над тем, как ваши типы данных преобразуются в типы, которые могут применять методы, написанные на чистом C/C++.
Например, структура C, определенная следующим образом в файле my_struct.h:
struct my_struct {
int a;
int b;
};
может быть реализована так, как показано в файле с именем my_struct.py:
import ctypes
class my_struct(ctypes.Structure):
_fields_ = [("a", c_int),
("b", c_int)]
F2PY
Генератор интерфейса Fortran-к-Python (F2PY) (/) является частью NumPy. Чтобы его получить, установите NumPy с помощью команды pip:
$ pip install numpy
Предоставляет гибкую функцию командной строки, f2py, которая может быть использована тремя разными способами (все они задокументированы в руководстве к F2PY по адресу ). Если вы имеете доступ к управлению исходным кодом, то можете добавить особые комментарии с инструкциями для F2PY, которые показывают предназначение каждого аргумента (какие элементы являются входными, а какие — возвращаемыми), а затем запустить F2PY:
$ f2py -c fortran_code.f -m python_module_name
В противном случае F2PY способен сгенерировать промежуточный файл с расширением *.pyf, который вы можете модифицировать, чтобы получить такой же результат. Для этого потребуются три шага:

 Автоматически сгенерируйте промежуточный файл, который определяет интерфейс между сигнатурами функций языков FORTRAN и Python.
Автоматически сгенерируйте промежуточный файл, который определяет интерфейс между сигнатурами функций языков FORTRAN и Python.
 Отредактируйте файл, чтобы входные и выходные переменные были корректно размечены.
Отредактируйте файл, чтобы входные и выходные переменные были корректно размечены.
 Теперь скомпилируйте код и постройте модули расширения.
Теперь скомпилируйте код и постройте модули расширения.
SWIG
Упрощенный упаковщик и генератор интерфейсов (Simplified Wrapper Interface Generator, SWIG) (/) поддерживает большое количество языков сценария, включая Python. Этот широко распространенный инструмент командной строки генерирует привязки для интерпретируемых языков из аннотированных файлов заголовков C/C++.
Для начала используйте SWIG для того, чтобы автоматически сгенерировать промежуточный файл из заголовка — он будет иметь суффикс *.i. Далее модифицируйте этот файл так, чтобы он отражал именно тот интерфейс, который вам нужен, а затем запустите инструмент сборки, чтобы скомпилировать код в разделяемую библиотеку. Все это описывается шаг за шагом в руководстве по SWIG ().
Несмотря на то что есть некоторые ограничения (в данный момент могут иметься проблемы с небольшим объемом новой функциональности С++, а заставить работать код, содержащий большое количество шаблонов, может быть затруднительно), SWIG предоставляет много функций Python при малых усилиях. В дополнение вы легко можете расширить привязки, создаваемые SWIG (в файле интерфейса), чтобы перегрузить операторы и встроенные методы и, по сути, преобразовать исключения C++ таким образом, дабы вы могли отловить их в Python.
Рассмотрим пример, иллюстрирующий, как переопределить __repr__. Этот фрагмент кода получен из файла с именем MyClass.h:
#include <string>
class MyClass {
private:
std::string name;
public:
std::string getName();
};
А это myclass.i:
%include "string.i"
%module myclass
%{
#include <string>
#include "MyClass.h"
%}
%extend MyClass {
std::string __repr__()
{
return $self->getName();
}
}
%include "MyClass.h"
В репозитории SWIG на GitHub вы можете найти еще больше примеров использования Python (). Установите SWIG с помощью вашего менеджера пакетов, если он там есть (apt-get install swig, yum install swig.i386 или brew install swig), или воспользуйтесь ссылкой , чтобы загрузить SWIG, а затем следуйте инструкциям по установке для вашей операционной системы (). Если у вас нет библиотеки Perl Compatible Regular Expressions (PCRE) в OS X, для ее установки задействуйте Homebrew:
$ brew install pcre
Boost.Python
Boost.Python (/) требует выполнения несколько большего объема ручной работы для того, чтобы воспользоваться функциональностью объектов C++, но он может предложить ту же функциональность, что и SWIG, и даже больше, например обертку, позволяющую получать доступ к объектам Python как к объектам PyObjects в C++, а также инструменты для предоставления доступа к объектам С++ для кода Python. В отличие от SWIG, Boost.Python является библиотекой, а не инструментом командной строки, поэтому вам не нужно создавать промежуточный файл с другим форматированием — все пишется на языке С++. Для Boost.Python написано подробное руководство (), если он вам интересен.
Фаулер выступает за использование правил хорошего тона при проектировании ПО. Он один из главных сторонников непрерывной интеграции (). Эта цитата взята из его статьи о непрерывной интеграции. Он провел серию семинаров, посвященных разработке через тестирование и отношению к экстремальной разработке (/), вместе с Дэвидом Хайнемайером Хэнссоном (David Heinemeier Hansson, создатель Ruby on Rails) и Кентом Бэком (Kent Beck, инициатор движения экстремального программирования (XP), одним из основных принципов которого является непрерывная разработка) ().
На GitHub другие пользователи оправляют запросы на включения, чтобы оповестить владельцев другого репозитория о том, что у них имеются изменения, которые они хотели бы внести в их проект.
REST расшифровывается как representational state transfer — передача состояния представления. Это не стандарт и не протокол, а набор принципов проектирования, разработанных во время создания стандарта HTTP 1.1. Список релевантных архитектурных ограничений для REST доступен в «Википедии»: .
OpenStack предоставляет бесплатное ПО для облачных сетей, хранения и вычислений, поэтому организации могут размещать собственные приватные облака или публичные облака, за доступ к которым нужно платить.
За исключением Salt-SSH, который является альтернативной архитектурой Salt (возможно, она была создана как ответ пользователям, желавшим получить версию Salt, более похожую на Ansible).
Дэвид Бизли написал отличное руководство (), которое описывает способ работы GIL. Он также рассматривает новую версию GIL (), появившуюся в Python 3.2. Результаты показывают, что максимизация производительности в приложении Python требует глубокого понимания GIL, его влияния на приложение, а также знания количества ядер и понимания узких мест приложения.
По адресу приводится полная реализация метода. По сути, вы бросаете дротики в квадрат размером 2 × 2, а круг имеет радиус = 1. Если дротик может попасть в любое место доски с одинаковой вероятностью, то процент дротиков, попавших в круг, будет равен π / 4. Это означает, что если вы умножите шанс попадания в круг на 4, то получите число π.
Язык может быть одновременно строго типизированным и динамически типизированным, это описывается по адресу 28920/.
Необходимо особенно тщательно писать расширения на C, чтобы убедиться, что вы регистрируете свои потоки для интерпретатора ().

