Книга: Канбан. Альтернативный путь в Agile
Назад: Глава 18 Экономическая модель бережливого производства
Дальше: Глава 20 Управление проблемами и правила эскалации
Глава 19
Источники вариативности
Вариативность в промышленных процессах изучается с начала 1920-х годов. Пионером в этой области был Уолтер Шухарт. Его методы заложили основу движения по управлению качеством и стали базой как для производственной системы Toyota, так и для метода «шесть сигм», обеспечивающих качество и непрерывное совершенствование. Методы Шухарта были взяты на вооружение, развиты и дополнены Эдвардсом Демингом, Джозефом Джураном и Дэвидом Чемберсом. Их работы вдохновили Уоттса Хамфри и основателей Института технологий разработки ПО Университета Карнеги – Меллон, которые считали, что изучение и систематическое снижение вариативности сулит большие преимущества для разработчиков.
Шухарт, Деминг и Джуран опубликовали множество работ по исследованию вариативности и ее использованию в качестве техники управления, а также как основания для программы усовершенствований. Кроме того, существует немало публикаций, рассказывающих о методе количественной оценки, известном как статистический контроль процессов (СКП) и ставшем основным средством изучения вариативности и борьбы с нею. Теперь СКП взят на вооружение и командами, использующими Канбан. Однако СКП и его применение считается более серьезной темой, к которой мы обратимся в одной из следующих книг. Здесь же только затронем проблему вариативности.
Шухарт разделял вариативность и вариации в производственных показателях на два типа – внутреннюю и внешнюю.
Внутренние источники вариативности – это вариации, которые находятся под контролем задействованной системы. В рамках Канбан-подхода к IT и разработке ПО мы определяем систему как процесс, который задается набором правил, управляющих ее эксплуатацией. Эти правила могут подвергнуться влиянию изменений, вносимых сотрудниками, командой или руководством. Изменения в правилах трансформируют и эксплуатацию системы, и ее производительность. Тем самым изменения в определении процесса – это изменения, которые затрагивают внутренние источники вариативности. Забавно, что такие внутренние вариации Шухарт назвал случайными. Слово «случайный» предполагает, что вариации имеют непредсказуемый характер, что является прямым следствием структуры системы. Но не предполагается, что непредсказуемость равномерно распределена или укладывается в рамки нормального распределения. Изменения в структуре процесса, вызванные изменениями внутренних правил, повлияют на медианное распределение, его распространение и форму.
Приведем пример. Отбивающий в бейсболе обладает коэффициентом ударов (известным также как средний уровень), который показывает, как часто он наносил удары, приводившие как минимум к взятию первой базы. У разных отбивающих разные коэффициенты, обычно они колеблются от 0,1 до 0,35. В любой день такой игрок может продемонстрировать показатели ниже своего среднего коэффициента ударов. Это зависит от ряда факторов: выбора питчера, коэффициента успешности ударов других игроков, а также от специфики подач.
Если изменить правила бейсбола так, чтобы соотношение шансов было в среднем в пользу отбивающего и не в пользу питчера, то средний коэффициент для отбивающих вырастет и лучшие игроки смогут достичь показателя, превышающего 0,5. Это пример модификации системы ради изменения случайных вариаций внутри нее.
Теперь приведем пример из области разработки. Пусть внутренняя, случайная вариация – это количество ошибок на строчку кода, требование, задачу или на единицу времени. Среднее количество, распространение и распределение ошибок или дефектов можно изменить, поменяв инструменты и процессы – допустим, введя модульное тестирование, непрерывную интеграцию и дружеские экспертизы программ.
Определение процесса, которое используется в вашей команде и выражено в виде правил, отражает правила совместной игры по разработке ПО. Они определяют источники и количество внутренних вариаций. Ирония состоит в том, что «случайные» вариации на самом деле находятся под полным контролем команды и руководства, которые могут изменять правила и процессы, тем самым влияя на источники внутренней вариативности.
Внешние источники вариативности – это события, происходящие вне зоны ответственности данной команды или ее руководителей. Это случайности, вносимые другими командами, поставщиками, потребителями, а также иные случаи «божественного вмешательства», как это называют в страховании: например, двухнедельный простой сервера, вызванный наводнением, в свою очередь, связанным с необычно сырой и ветреной погодой. Внешние источники вариативности требуют к себе особого подхода. Правила их не затрагивают, но можно учредить процесс, который эффективно справится с внешними вариациями. Отрасль знаний, относящаяся к этой сфере, называется управлением проблемами и рисками. Шухарт назвал внешние вариации «выявляемыми». Он имел в виду, что специалист (или группа специалистов) с легкостью укажет источник проблемы и даст его полное описание. Например: «Случилась буря, пошел сильный дождь, и наш сервер затопило». Вариации с выявляемыми причинами лежат вне сферы контроля конкретной команды или руководства, но их можно предсказать, составить план и разработать процедуры для того, чтобы с ними справиться.
Внутренние источники вариативности
Установленные процессы разработки ПО и управления проектами в сочетании со зрелостью организации и возможностями членов команды определяют количество внутренних источников вариативности и ее уровень.
Напомню, что Канбан – это не вариант жизненного цикла разработки ПО и не процесс управления проектами. Это метод управления изменениями, который требует перемен в существующем процессе – например, определения лимита незавершенных задач.
Размер единицы работы
Метод анализа, используемый для разделения требований и подготовки их к разработке, обладает собственным уровнем вариативности. Один из источников этого – размер единиц работы. В первых работах, описывающих метод экстремального программирования, пользовательские истории характеризуются как записанное на карточке повествовательное описание функции, которая должна быть внедрена и передана конечному пользователю. Единственное ограничение – размеры карточки. Считалось, что создание пользовательской истории могло длиться от полудня до пяти недель. За пару лет в лондонском сообществе выработался шаблон написания пользовательских историй.
Как <пользователь>, я хочу <функцию>, чтобы <создать некую ценность>.
Использование шаблона привело к стандартизации написания пользовательских историй. Один из авторов такого подхода, Тим Маккиннон, в 2008 году сообщил мне, что, по его данным, в среднем на создание пользовательской истории требуется 1,2 дня, а вариативность составляет от половины суток до примерно четырех дней.
Это конкретный пример сокращения случайных вариаций при методе экстремального программирования, когда команде предлагается стандартизировать написание пользовательских историй по определенному шаблону. Тем самым Тим изменил правила игры. В исходных правилах устанавливалось, что члены команды должны писать пользовательские истории на карточках в свободной форме. Теперь же карточки сохранялись, но требовалось следовать определенному шаблону изложения. Очевидно, что подобные изменения находятся в сфере влияния и контроля местных менеджеров. Для системы они являются внутренними. Размер пользовательской истории контролируется случайными вариациями.
Смешение типов единиц работы
Когда ко всем задачам относятся одинаково, к тому же приписывая их к одному типу, наблюдается большая вариативность размеров, усилий, риска или других факторов. Разбивая задачи на определенные типы, можно по-разному работать с последними, что обеспечивает большую предсказуемость.
Например, в сообществе экстремального программирования были разработаны определения типов для разных размеров историй. Они получили названия «эпик» и «песчинка». Эпик – это более крупная история, для работы с ней может понадобиться несколько человек и не одна неделя, а песчинка – небольшая история, которую могут реализовать один или два разработчика всего за несколько часов. Приняв такую номенклатуру – «эпик», «история», «песчинка», – мы получаем три разных типа. Для каждого из них разброс вариативности будет ниже, чем если бы все задания трактовались как относящиеся к одному типу.
В обычном отделе разработки ПО может решаться несколько типов задач. Например, работа по созданию новой потребительской ценности под названием «функция», «история» или «пользовательский сценарий». (Как уже говорилось, они могут быть стратифицированы по размеру, подтипу домена или профилю риска.) Или работа по устранению «производственных ошибок» и «внутренних ошибок». А может быть, и работа по обслуживанию – «рефакторинг», «переделка архитектуры» или просто «обновление».
Операционные системы, базы данных, платформы, языки, API и сервисные архитектуры со временем меняются. Для работы с этими изменениями нужно обновлять и код.
Используя методы определения разных типов единиц работы, мы можем изменить медиану и разброс вариативности, увеличив предсказуемость в системе для конкретного типа работы.
Еще одна стратегия по увеличению предсказуемости – назначение общей WIP-мощности для отдельных типов. Например, в моей команде обслуживания в Corbis были разрешены только две единицы IT-обслуживания одновременно. Это ограничивало мощность, потраченную на API и обновления базы данных. Такая стратегия особенно полезна, когда типы разделяются по размеру или требуемым усилиям – как, например, эпик, история или песчинка. Назначив конкретную мощность для каждого типа, вы сможете поддержать чуткость системы и увеличить предсказуемость.
Представьте себе команду, использующую канбан-доску, на которой отражен лимит в два эпика, восемь обычных историй и четыре песчинки. В работе два эпика. В очереди освобождается место для обычной истории, но в бэклоге ни одна из них не готова к началу работы. Команда должна решить, начать ли работу с эпиком (или песчинкой) либо придерживаться ранее заявленных типов, что вызовет простой.
Если начать эпик, а через несколько дней в бэклоге окажется обычная история, то они не смогут сразу же приступить к работе над ней. Это увеличит разброс времени выполнения для обычных историй.
Лучше начать работу над песчинкой, которая будет окончена еще до того, как появится следующая обычная история. В данном случае отрицательное влияние отсутствует, а пропускная способность увеличивается. Однако если сотрудникам не повезет и они не смогут закончить более мелкий элемент до того, как на подходе окажется следующая история, то время выполнения для обычных историй увеличится, хотя и не так значительно, как в случае с эпиком. Возможности повысить пропускную способность стоит предпочесть предсказуемость и управление рисками, поскольку владельцы бизнеса и высшее руководство особенно ценят предсказуемость. Она порождает и сохраняет доверие, которое в agile считается высшей ценностью. Этого не произойдет, если делать больше работы с меньшей степенью надежности.
Смешение классов обслуживания
Рассмотрим классы обслуживания, описанные в . Можно предположить, как скажется на вариативности смешение элементов. Если организация страдает от излишков ускоренных запросов, то они внесут существенную долю случайности во все остальные задания, увеличив среднее время выполнения и разброс вариативности, что снизит предсказуемость для всей системы.
Ускоренные запросы – это внешние вариации, поэтому они будут описаны в следующем разделе.
Если спрос на остальные классы обслуживания сравнительно устойчив, то время выполнения для каждого класса нужно строго соблюдать. Медиана и разброс вариаций должны быть измеримы и оставаться примерно постоянными, что обеспечивает предсказуемость. Этого можно достичь, если бэклог велик и в нем есть ассортимент задач каждого класса. Задайте WIP-лимит для каждого класса обслуживания. Это обеспечит сохранение медианы и разброса вариативности для каждого класса, так что система будет предсказуемой.
Если спрос переменен – например, существует лишь несколько элементов с фиксированной датой поставки, которые носят сезонный характер, – то нужно принять меры либо по формированию спроса, либо по контролю над ним. Например, можно объявить о сезонных изменениях в WIP-лимитах для каждого типа в соответствии с ожидаемым изменением спроса или об изменениях правил вытягивания задач, связанных с поступающими в работу классами обслуживания. Это необходимо, чтобы нейтрализовать значительные изменения спроса.
Рассмотрим пример команды с WIP-лимитом в 20 единиц, из которых 4 приходятся на единицы с фиксированной датой поставки, 10 – на элементы стандартного класса и 6 – на единицы нематериального класса. Можно либо установить правило, что этих более мелких лимитов нужно строго придерживаться, либо ослабить жесткость, чтобы стандартный или нематериальный элемент мог занимать место элемента с фиксированной датой поставки, когда сезонный спрос на такие элементы недостаточен. В разное время года эти правила могут меняться ради общего экономического выигрыша и обеспечения большей предсказуемости системы.
Нерегулярный поток
Нерегулярный поток работы может быть вызван как внешними, так и внутренними источниками вариативности. Каждый отдельный элемент, входящий в канбан-систему, будет отличаться от других как по природе, так и по размеру, сложности, профилю риска и требуемым усилиям. Такая естественная разница приведет к тому, что у вашего потока появятся приливы и отливы. Канбан-система справляется с ними естественным образом, как только вводятся WIP-лимиты. Однако еще большая вариативность, вызванная иными причинами, например разными размерами единиц работы, шаблонами спроса, смешением типов и классов обслуживания и внешними источниками, требует буферизации, которая могла бы нейтрализовать приливы и отливы задач в системе. При повышенной вариативности системы могут потребоваться дополнительные буферы, а WIP-лимиты, возможно, придется увеличить. Рост WIP-лимитов приведет к увеличению времени выполнения, но сглаживание потока должно снизить вариативность. Таким образом, увеличение WIP-лимита для придания потоку равномерности удлинит среднее время выполнения, но снизит разброс этого времени. Это предпочтительнее, поскольку менеджеры, владельцы и даже клиенты ценят предсказуемость больше, чем случайно удавшееся сокращение времени выполнения или повышение пропускной способности.
Переработка
Переработка, связанная как с внутренними ошибками, замеченными и исправленными до релиза, так и с производственными ошибками, внесенными в новую работу по созданию потребительской ценности, влияет на вариативность. Если доля ошибок известна, регулярно подсчитывается и остается почти на одном уровне, то можно так отладить систему, чтобы она успешно с этим справлялась. Подобная система будет экономически неэффективной, зато надежной. Недостаток предсказуемости получается, когда доля ошибок оказывается неожиданной. Незапланированная переработка ввиду ошибок увеличивает время выполнения, обычно повышает разброс вариаций и существенно снижает пропускную способность. Судя по всему, очень сложно даже планировать определенную долю ошибок (например, восемь ошибок на пользовательскую историю), не говоря уж о том, чтобы уметь точно предсказать их размер и сложность. Лучшая стратегия по снижению вариативности из-за ошибок – неустанно стремиться к высокому качеству и выдавать результат, содержащий очень мало оплошностей.
Внесение изменений в жизненный цикл разработки ПО может серьезно повлиять на долю ошибок. Использование дружеской экспертизы, парного программирования, модульных тестов, автоматизированных платформ тестирования, непрерывной (или очень частой) интеграции, небольших размеров пакетов, четко определенной архитектуры и хорошо продуманного, слабо связанного дизайна кода существенно уменьшит число ошибок. Изменения, непосредственно влияющие на долю ошибок и опосредованно повышающие предсказуемость системы, находятся под контролем как местного руководства, так и самой команды.
Внешние источники вариативности
Внешние источники вариативности лежат вне сферы прямого контроля процесса разработки ПО или метода управления проектами. Некоторые из них поступают из других областей бизнеса или цепочки создания ценности: их причиной, например, могут быть поставщики или клиенты. Среди других внешних источников есть элементы физического мира, которые не так-то легко предугадать, предсказать или контролировать, – например, отказ техники или неблагоприятные погодные условия.
Двойственность требований
Плохо прописанные требования и бизнес-планы и отсутствие стратегического планирования, предвидения или другой задающей контекст информации способны привести к тому, что член команды не сможет принять решение, а следовательно, и закончить свой кусок работы. Единица работы из-за невозможности принять решение оказывается блокированной. Для прояснения ситуации требуется новая информация, которая поможет члену команды принять правильное решение, так что незавершенные задания направятся дальше, к своему завершению.
Чтобы сократить негативное влияние подобной блокировки, команде и непосредственному руководству нужно внедрить эффективные процедуры управления проблемами и их разрешения, что описано в .
По мере того как команда и организация взрослеют, можно заняться анализом первопричин и их устранением. Блокирующие проблемы, вызванные двусмысленными требованиями, решаются непосредственным воздействием на аналитические процессы, которые используются в разработке требований, и совершенствованием способностей и навыков тех, кто эти требования создает. Подобные меры нуждаются в привлечении других подразделений и менеджеров, а также в желании бизнеса совершенствоваться.
В 2007 году в Corbis это достигалось постепенно. Сначала внедрили канбан-систему – визуальную доску и электронное средство отслеживания. Вместе с этим пришла прозрачность. Бизнес оказался сильнее вовлечен в процесс разработки ПО и в наблюдение за производительностью этого подразделения. Создавались отчеты, демонстрирующие количество нерешенных проблем и заблокированных единиц работы, а также среднее время разрешения этих задач. ( Отчет о проблемах и заблокированных единицах работы)
Когда требование проделало путь до приемочного тестирования, но было отвергнуто, поскольку оказалось ненужным бизнесу, команда ответила на это, выделив на доске мусорную корзину и прикрепив к ней талон, как показано на рис. 19.1. После этого руководство попросило создать несколько электронных отчетов о работе, которая поступила в систему, но не смогла проделать весь путь по ней (рис. 19.2).

Рис. 19.1. Доска с мусорной корзиной
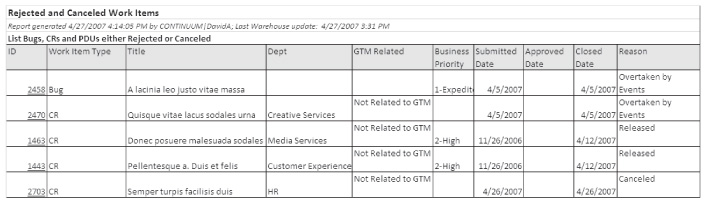
Рис. 19.2. Отчет о непринятой и отмененной работе, демонстрирующий незавершенные рабочие единицы за прошлый месяц
Сочетание прозрачности, отчетности и сознания ответственности за отрицательное влияние (в том числе экономическое) неудачных требований привело к тому, что бизнес сознательно изменил поведение. Изначально отчет о потерях, который демонстрировал эффект от неудачных требований, содержал от пяти до десяти единиц в месяц. К пятому месяцу он опустел. Бизнес понял: если относиться к созданию требований внимательнее, то можно будет не разбрасываться мощностью. Они добровольно согласились сотрудничать, чтобы добиться лучших системных результатов. В итоге удалось исключить первопричины выявляемых вариаций из-за плохо написанных требований или неудачно определенной контекстуальной информации.
Хотя команда разработки ПО приняла меры по достижению большей прозрачности и ответственности, они не затронули процесс разработки требований. Просто процесс управления проблемами и их решения нейтрализовал негативное влияние блокирующих вопросов: команда стала ответственнее и сократила время разрешения проблем. В результате снизилось отрицательное влияние на среднее время выполнения и разброс вариативности. Прозрачность и отчетность привели к внешним изменениям процесса, что устранило первопричину проблемы.
Это один из примеров того, как локально предпринятые меры косвенно влияют на вариации с выявляемой причиной.
Ускоренные запросы
Ускоренные запросы – результат внешних событий, таких как неожиданный заказ клиента, или неполадок во внутренних процессах компании, например коммуникативной ошибки, которая приводит к слишком позднему обнаружению какого-то важного требования. Ускоренные запросы – это вариации с выявляемыми причинами, поскольку причина запроса всегда известна, а следовательно, «выявляема».
В промышленном производстве ускорение считается отрицательным фактором. Оно влияет на предсказуемость других запросов, увеличивает среднее время выполнения и разброс вариативности, а также сокращает пропускную способность. Данные, полученные за 2007 год в Corbis, показали, что это верно и для процессов разработки ПО: ускорение нежелательно, даже если проводится с целью создания ценности.
Необходимость в ускорении можно сократить. Увеличение резервной мощности благодаря усовершенствованию пропускной способности, автоматизации или увеличению ресурсов повысит способность к реагированию. Более короткое время выполнения, высокая прозрачность и организационная зрелость – все это снизит необходимость в ускорении. Хорошие команды, усвоившие Канбан-подход, обычно не злоупотребляют ускоренными запросами. Например, в Corbis за весь 2007 год их было всего пять.
Как и в случае с плохо написанными требованиями, можно надеяться, что прозрачность процесса и полная информация о пропускной способности, времени выполнения и доле выполнения в срок повлияет на поведение партнеров выше по цепочке. Есть вероятность, что спрос будет сформирован так, чтобы с самого начала было понятно: требование лучше выполнить в рамках обычного класса обслуживания, а не в виде ускоренного запроса.
Один из способов вызвать такие изменения – договориться об ограничении числа ускоренных запросов, которые могут быть обработаны в любой момент. В Corbis этот лимит равнялся одному. Отказывая бизнесу в возможности ускорить все подряд, вы заставляете партнеров выше по цепочке (из отдела продаж или маркетинга) искать возможности и эффективно их оценивать. Если продажники получают комиссию, которая рассчитывается на основе получаемой прибыли, то невозможность ускорить запрос сильно ударит по ним.
Если это происходит из-за превышения WIP-лимита на ускоренные запросы, то в будущем они постараются собрать больше информации и вовремя разместить запрос, чтобы он мог попасть в обычный класс обслуживания. Это еще один пример внутренних мер, которые можно предпринять для косвенного влияния на выявляемые причины вариации. Изменение в системном дизайне, которое призвано сократить внутренние случайные вариации, оказывает влияние и на внешние вариации с выявляемыми причинами.
Нерегулярный поток
Уже упоминалось, что нерегулярный поток работы бывает вызван вариациями и со случайными, и с выявляемыми причинами. Вариации с выявляемыми причинами, воздействующие на поток, приводят к заблокированным заданиям.
Часто причинами заблокированных по выявляемым причинам задач становятся двусмысленные требования, а также очередь на доступ к общей среде или общему специалисту.
Блокированные рабочие единицы требуют строгой дисциплины и опыта в управлении проблемами и их разрешении, о чем говорится в . Есть два способа решения проблемы заблокированных рабочих единиц.
Первый восстанавливает поток за счет времени выполнения и даже качества. Вы можете восстановить поток, увеличив общий WIP-лимит – либо установив буфер напрямую, либо задав менее жесткие правила ограничения незавершенных задач: например, 3, а не 1,2 элемента в среднем на человека. Больший WIP-лимит подразумевает, что, пока одна задача блокирована, члены команды могут работать над остальными. Такой подход рекомендуется недостаточно зрелым организациям. Эффект от него прост и лишен драматизма. Время выполнения будет больше, но во многих отраслях это не составляет проблемы. Сильнее может оказаться и разброс вариативности, так что время выполнения окажется менее предсказуемым. Однако благодаря использованию канбан-системы оно все равно будет более предсказуемым, чем раньше. Главный недостаток использования больших WIP-лимитов в том, что так почти (или совсем) не создается внутренней напряженности, которая вызвала бы обсуждения и внедрение улучшений. Нет стимула к совершенствованию, эффект канбана как катализатора утрачивается.
Второй подход связан с неукоснительным проведением политики управления проблемами и их разрешения и, по достижении зрелости команды, с переходом к анализу и устранению первопричин, а также внесению улучшений, направленных на предотвращение вариаций с выявляемыми причинами в будущем. При таком подходе WIP-лимиты, размеры буфера и действующие правила остаются достаточно жесткими, и если задача блокируется, то это останавливает всю работу. Простой сотрудников, назначенных на блокированную задачу, повышает ответственность за блокирующую проблему. После этого может начаться массовая атака на проблему, что, как было установлено, стимулирует простаивающих членов команды думать о первопричинах и возможных изменениях в процессе, которые смогут сократить или исключить возможность новой подобной проблемы. Как показывает практика, сохранение жестких WIP-лимитов и проведение мероприятий по управлению проблемами и их разрешению позволяет создать культуру непрерывного совершенствования. Впервые я столкнулся с этим в Corbis в 2007 году, но есть и другие данные, полученные в 2009 году в таких компаниях, как Software Engineering Professionals (Индианаполис), IPC Media и BBC Worldwide (обе из Лондона). Сейчас уже достаточно информации, позволяющей предположить, что Канбан действительно способствует появлению культуры, сосредоточенной на непрерывном совершенствовании. Среди постоянно появляющихся элементов процесса, которые можно привести в пример, – готовность устанавливать жесткие правила WIP, маркировать работу как заблокированную, позволять потоку останавливаться, вызывая простой, и заниматься управлением проблемами и их решением в качестве устоявшейся организационной практики. Результат – сосредоточение на анализе и устранении первопричин и постепенное внедрение усовершенствований, которые снижают вариации с выявляемыми причинами и помогают распространению культуры непрерывного совершенствования.
Доступ к среде
Доступ к среде – типичный вид проблемы с выявляемой причиной, которая может оказать существенное влияние на поток, пропускную способность и предсказуемость. Отказ среды часто останавливает весь рабочий поток. С помощью канбан-системы эта проблема и ее воздействие становятся нагляднее. Простой, вызванный заданием WIP-лимита, стимулирует совместные действия по ее решению. Когда коллеги выше по цепочке, например разработчики и тестировщики, помогают операторам системы восстановить среду, такое поведение часто называется роением. Роение – это ситуация, когда вся команда собирается вместе и работает над единственной проблемой до полного ее разрешения. Природа Канбана позволяет командам сосредоточиться на времени выполнения, пропускной способности и потоке на протяжении всей цепочки создания ценности. Соединив усилия всех групп на разных отрезках цепочки создания ценности для достижения общей цели, мы порождаем стимул, чтобы наброситься на проблему со всех сторон, целым «роем». Все выигрывают от того, что простаивающие сотрудники добровольно помогают решить проблему, которая воздействует на них, даже если это выходит за рамки их должностных обязанностей.
Другие рыночные факторы
В октябре 2008 года вслед за крахом Lehman Brothers и ряда других драматических событий в финансовом секторе банки и инвестиционные компании таких ведущих финансовых центров, как Лондон и Нью-Йорк, стали отменять или видоизменять IT-проекты, находившиеся в разработке. Причина была в том, что их мир рушился и они боролись за выживание как могли. Внезапно выяснилось, что нужно лучше понять собственную – и общерыночную – ликвидность. Оказалось, что предлагать новейшие или экзотичные товары и услуги неактуально. Рынок больше не интересовался инвестициями. Осенью 2008 года финансовые предприятия беспокоились исключительно о собственной платежеспособности или ее отсутствии.
Это конкретный пример того, насколько серьезно могут измениться проектные портфели и требования к проекту в процессе работы. Необходимость реагировать на подобные изменения обычно отвлекает команды, что приводит к существенным потерям в пропускной способности, значительному увеличению времени выполнения, а нередко и к потере качества, отсутствию предсказуемости, поскольку команде нужно справиться с хаосом, который рыночные колебания вносят в проект.
Разумеется, эти события относятся к вариациям с выявляемыми причинами. Их требуется нейтрализовать при помощи стратегии и тактики управления рисками. Существуют достаточно серьезные наработки по вариациям с выявляемыми причинами, или событийному риску. Наличие опыта в управлении рисками как часть общей цели повышения зрелости организации улучшит предсказуемость разработки как при использовании Канбана, так и без него. Однако канбан-системы демонстрируют большую предсказуемость при хорошем управлении рисками. Это порождает внутрисистемное доверие.
В канбан-системах есть и другие элементы, которые помогают при управлении рисками. Так, WIP-лимит снижает риск, поскольку в любое время в работе находится лишь небольшое число задач. Назначение WIP-лимитов для отдельных типов рабочих единиц и классов обслуживания позволяет управлять рисками и нейтрализовать вариации с выявляемыми причинами. Появляются и другие стратегии. Судя по всему, выйдут в свет и новые книги, где будут подробно описаны передовые методы внедрения Канбана и современные тактики управления рисками.
Некоторые материалы по управлению рисками в канбан-системах, появившиеся в результате использования Канбана, я представлял на конференциях в 2009 году. Они доступны в интернете.
Трудности с координацией
Еще один распространенный источник вариаций с выявляемой причиной, который блокирует работу и лишает поток равномерности, – это координация с внешними командами, заинтересованными лицами и ресурсами. Обычная реакция на проблемы координации – планирование совещаний с регулярной каденцией. В определенных случаях это очень эффективное решение, но оно не всегда возможно.
Поток может быть прерван ограничениями, которые установлены правительственными органами или нормативными документами, требующими проведения аудита или утверждения документа. Люди, которые должны выполнять эту функцию, часто недоступны или не располагают свободным временем.
Сначала вариации с выявляемыми причинами такого рода нужно нейтрализовать, повысив осведомленность сотрудников и обратив общее внимание на этот фактор при помощи наглядности и прозрачности. Маркировав элементы как заблокированные и наглядно продемонстрировав источник блокировки, руководство, команда и другие участники цепочки создания ценности осознают воздействие этих координационных проблем.
Такое осознание должно привести к поведенческим изменениям, улучшающим ситуацию.
Одна из возможных тактик – изучение правительственных и регуляторных норм с целью определить, что именно должно подвергнуться оценке, одобрению, аудиту и изучению. Если предположить, что существуют разные профили риска, которые дают возможность распределить задания на две категории – «необходимо согласовать» и «необязательно согласовывать», – то для разбивки задач можно использовать типы рабочих единиц либо классы обслуживания. После этого стоит задать отдельные WIP-лимиты как для типов, так и для классов для обеспечения равномерности потока.
Выводы
• Изучение вариативности в промышленных процессах началось в 1920-е годы с Уолтера Шухарта. В середине и конце XX века его дело продолжили и развили Эдвардс Деминг, Джозеф Джуран и Дэвид Чемберс.
• Изучение вариативности и связанный с ним метод статистического анализа лежит в основе производственной системы Toyota (а следовательно, и бережливого управления) и метода «шести сигм» для совершенствования процесса.
• Работы Эдвардса Деминга и Джозефа Джурана – главный источник вдохновения для Института технологий разработки ПО Университета Карнеги – Меллон и модели зрелости возможностей (современное название – «интегрированная модель зрелости», или CMMI).
• Шухарт разделил источники вариативности на две категории: внутренние для процесса или системы и внешние для процесса или системы.
• Внутренние вариации называются вариациями со случайными причинами.
• Внешние вариации называются вариациями с выявляемыми причинами.
• В цепочке создания ценности жизненного цикла разработки ПО может быть много источников вариаций со случайными причинами. Типичные примеры – размер рабочей единицы, тип, класс обслуживания, нерегулярный поток и переработка.
• Список источников вариаций с выявляемыми причинами, возможно, бесконечен. Типичные примеры – двусмысленные требования, ускоренные запросы, доступность среды, нерегулярный поток, рыночные факторы, факторы персонала и проблемы с координационной деятельностью.
• Вариации со случайными причинами можно контролировать, задав правила, определяющие жизненный цикл разработки ПО и используемые процессы управления проектами.
• Вариациями с выявляемыми причинами можно управлять, развив способности к управлению проблемами и их разрешению, а также способности к управлению рисками. Такие вариации можно сократить или ликвидировать благодаря анализу и устранению первопричин.
• Канбан-системы приводят к более благоприятным экономическим результатам, если с ними сочетается умелое управление событийными рисками.
• Канбан также предлагает дополнительные способы управления рисками – например, назначение WIP-лимитов для классов обслуживания и типов рабочих единиц, использование профилей риска для разбивки задач на типы или классы и действия в соответствии с ними.
• Предстоит еще много работать над передовыми стратегиями и тактиками управления рисками в Канбане – это станет темой следующей книги.
Назад: Глава 18 Экономическая модель бережливого производства
Дальше: Глава 20 Управление проблемами и правила эскалации

