238. ДАННЫЕ ДОЛЖНЫ БЫТЬ «ЖИВЫМИ»
Управленческая информация должна быть актуальной и «живой». Что это значит? Что ее нельзя хранить в форматах PDF или Word, например. Потому что тогда вы не сможете:
- быстро обновить данные;
- поменять одну из переменных — и посмотреть на то, как это изменение отразится на итоговых показателях (провести сценарный анализ);
- добавить новые показатели.
Все это возможно в таблицах, где легко обновлять и обрабатывать данные. Вы можете извлечь данные из таблицы и представить в наглядном отчете в PDF. Но помните: ни одно изменение в исходных данных в этом отчете не отобразится. А принимать решения лучше на основе актуальной информации.
239. И АБСОЛЮТНО, И ОТНОСИТЕЛЬНО
В аналитике принято сравнивать данные (отчетность, показатели) с какой-то базой: предыдущим периодом, аналогичным периодом прошлых лет, с конкурентами, со средним показателем по отрасли, по региону, с нормативами и т. д.
Сравнение может быть абсолютным (в отделе стало работать на три человека больше) и относительным (было шесть сотрудников, а стало девять: прирост на 50%!).
Ни то ни другое сравнение не показательно само по себе. Процентный прирост может быть огромным (возможно, вы слышали про эффект низкой базы: бегуны быстро прогрессируют в первые годы, рост продаж нового направления в бизнесе может быть стремительным в первые месяцы и годы, пока рынок не пресытился), но без абсолютных цифр эта информация не поможет вам делать выводы и принимать решения.
Приросты считаются так:
Абсолютный прирост = Текущий показатель – Базисный показатель (прошлый месяц, аналогичный месяц прошлого года и т. д.).
Относительный прирост = Текущий показатель / Базисный показатель – 1.
240. МОДА, МЕДИАНА И СРЕДНЕЕ
Сначала дадим определения:
- среднее арифметическое — сумма всех элементов выборки, разделенная на их количество;
- мода — значение, которое встречается чаще всего;
- медиана — такое число из выборки, что ровно половина элементов этой выборки больше него, а половина — меньше.
В качестве среднего могут указывать и среднее, и медиану, и моду. В компании с огромной зарплатой руководителя и низкими зарплатами сотрудников будет высокая средняя зарплата, не очень высокая медианная (то есть зарплата человека, которая меньше зарплаты половины сотрудников и больше зарплаты другой половины сотрудников) и совсем невысокая мода (то есть зарплата, чаще всего встречающаяся в компании).
Рассмотрим простой пример в числах.
Пусть в компании есть восемь руководителей, которые получают по 3 тысячи неких денежных единиц, 20 сотрудников, получающих по 2 тысячи единиц, и 27 сотрудников, которые получают по 200 единиц.
Средняя зарплата в компании = 69 400 / 55 = 1261 денежная единица.
Медиана = 2 тысячи единиц. Это зарплата того человека, который «богаче» одной половины коллег и «беднее» другой половины.
Мода = 200 единиц, это самая часто встречающаяся зарплата.
Когда какой показатель использовать?
На практике мода используется редко. Намного больший интерес представляют среднее и медиана.
Среднее арифметическое крайне чувствительно к выбросам (нехарактерным для изучаемой выборки слишком большим или слишком малым значениям) — одно случайное экстремальное значение может сильно сместить ваше среднее.
Медиана же к выбросам устойчива.
Выбор между медианой и средним зависит от целей исследования и от характера данных. Если экстремальные значения полагаются случайными или возникающими вследствие внешних причин или ошибок, медиана — более предпочтительный показатель.
Если имеете дело со статистикой и слышите про «среднее» — лучше поинтересоваться, как именно его рассчитывали.
241. ВЗВЕШЕННОЕ СРЕДНЕЕ
Взвешенное среднее — то, при котором значения усредняемого показателя умножаются на определенные веса (например, на объем или количество).
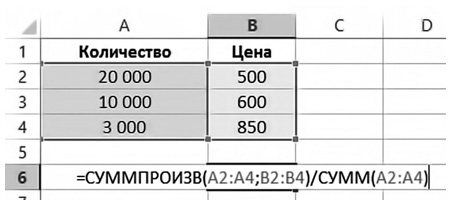
Допустим, у вас в магазине есть 20 тысяч книг по 500 рублей, 10 тысяч книг по 600 рублей и 3 тысячи книг по 850 рублей. Какова средняя цена книги из вашего ассортимента? Количество книг здесь будет весом, а цена — усредняемым показателем.
| Количество | Цена |
| 20 000 | 500 |
| 10 000 | 600 |
| 3000 | 850 |
| Средневзвешенное: | 562 |
На практике для расчета этого показателя можно применять функцию СУММПРОИЗВ (SUMPRODUCT) в Excel. Она позволяет перемножить несколько массивов. В данном примере она будет выглядеть так:
242. КВАНТИЛИ
Еще один интересный показатель в статистическом анализе — это квантили. Чаще всего встречаются 1%-, 5%-, 95%-, 99%-ный квантили. Рассмотрим на примере: пусть 95%-ный квантиль зарплат в регионе составляет 1 тысячу денежных единиц. Это значит, что 95% населения получает менее 1 тысячи единиц (или 95 человек из 100 получают менее 1 тысячи единиц). Аналогично, если 5%-ный квантиль составляет 200 единиц, то 5% населения зарабатывает менее 200 единиц.
Квантили удобны, когда необходимо получить интервал, в который с высокой вероятностью попадают все интересующие вас объекты исследования. Или когда вам необходимо отфильтровать экстремальные значения.
Для нахождения квантилей используйте функции Excel:
- в старых версиях Excel: КВАРТИЛЬ (QUARTILE);
- в Google Таблицах: QUARTILE;
- в новых версиях Excel: КВАРТИЛЬ.ВКЛ/КВАРТИЛЬ.ИСКЛ (QUARTILE.INC/ QUARTILE.EXC).
Первый аргумент функции — массив данных, а второй — значение процентиля (например, 0,05 или 0,95).
243. КАК НАЙТИ ВЫБРОСЫ?
Что такое выбросы? Это данные, нетипичные для конкретной выборки, способные исказить статистические показатели (например, среднее), рассчитанные по ней.
Откуда они появляются? Выбросы могут возникать из-за ошибок ввода информации, неправильного сбора данных, а также по причинам, не связанным с темой исследования (например, в какой-то месяц были низкие продажи из-за внешних факторов — проблем дистрибьютора, какого-то форс-мажора на рынке).
Если вернуться к примеру с заработной платой из бизнесхака , то зарплата руководителя — это не выброс.
Выбросы можно и нужно удалять, и делают это как вручную, так и автоматически.
Если у вас мало данных (например, статистика по продажам за два-три года по месяцам), то убрать их можно вручную, экспертно оценив, есть ли нетипичные данные в выборке (их может и не быть вовсе, особенно в небольшой выборке).
Если же данных много, то выбросы лучше искать автоматически. Делать это можно в Excel, Google Таблицах или в статистических пакетах.
Есть несколько базовых методов.
Правило трех сигм. Все наблюдения, которые на три среднеквадратичных отклонения (сигмы) больше или меньше среднего, — выбросы.
Формула среднеквадратичного отклонения:
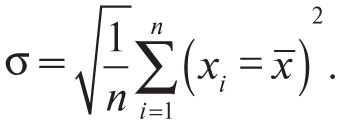
Его можно рассчитать в Excel с помощью функции СТАНДОТКЛОН.В (STDEV.S), если у вас выборка из общей совокупности, и с помощью функции СТАНДОТКЛОН.Г (STDEV.P), если вы оцениваете отклонение по всей генеральной совокупности.
В Google Таблицах используйте функции СТАНДОТКЛОН (STDEV) для выборки и СТАНДОТКЛОНП (STDEVP) для генеральной совокупности.
Примечание. Генеральная совокупность — это все объекты, которые вы собираетесь исследовать. Например, если вы проводите маркетинговое исследование своей целевой аудитории, генеральной совокупностью могут быть все мужчины от 25 до 39 лет с определенным доходом, проживающие в городе N.
Соответственно, выборка — это часть генеральной совокупности, элементы, по которым есть наблюденные данные.
Если вы сомневаетесь — используйте формулу для выборки. Данные по всей генеральной совокупности встречаются редко.
Метод Тьюки.
- Рассчитайте 25-й и 75-й персентили. В Excel и Google Таблицах — с помощью функции ПЕРСЕНТИЛЬ (PERCENTILE).
- Вычтите 25-й персентиль из 75-го, чтобы получить межквартильный размах (МР).
- Рассчитайте внутренние и внешние границы по следующим формулам:
Нижняя внешняя граница = 25-й персентиль – 3 МР;
Верхняя внешняя граница = 75-й персентиль + 3 МР;
Нижняя внутренняя граница = 25-й персентиль – 1,5 МР;
Верхняя внутренняя граница = 75-й персентиль + 1,5 МР.
- Значения, лежащие за пределами внешних границ, — выбросы (если данные распределены нормально, то за пределами этих границ будет лежать лишь 0,000002 данных). Значения за пределами внутренних границ тоже можно считать выбросами, но не такими экстремальными. За их пределами будет лежать 0,01 данных.
244. ЗАБУДЬТЕ ОБ АБСОЛЮТНОЙ ТОЧНОСТИ
Не стоит в аналитических и финансовых расчетах (речь, конечно, об управленческой отчетности и внутренних расчетах, а не о бухгалтерии) стремиться к абсолютной точности, к трем-четырем знакам после запятой.
Окажется ли решение более взвешенным, если вы будете знать о росте показателя на 1,247% вместо того, чтобы знать о его росте на 1,2%? Стоит ли более точный расчет того времени и внимания, которое на него потратите вы / аналитик / маркетер / кто-либо другой из ваших коллег?
245. ЧТО НА ЧТО ВЛИЯЕТ. НАХОДИМ И ИНТЕРПРЕТИРУЕМ КОРРЕЛЯЦИЮ
Корреляция — это статистический показатель, характеризующий силу статистической связи между двумя случайными величинами (наборами наблюдаемых данных).
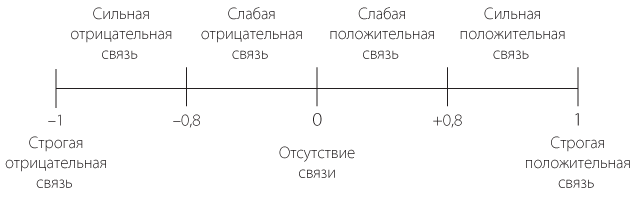
Коэффициент корреляции любых величин всегда лежит в диапазоне от –1 до 1. На данном промежутке можно выделить следующие точки и интервалы:
–1: детерминированная (неслучайная) отрицательная связь. Одна величина растет — другая падает, и наоборот. Связь строгая, то есть величины связаны напрямую.
от –1 до –0,8: сильная отрицательная связь. Вообще чем больше коэффициент корреляции (по модулю) — тем сильнее связь.
от –0,8 до 0: слабая отрицательная связь (значения ближе к нулю, скорее всего, означают полное отсутствие связи — такая корреляция может возникать случайно).
0: полное отсутствие связи.
от 0 до 0,8: слабая положительная связь (значения ближе к нулю, скорее всего, означают полное отсутствие связи — такая корреляция может возникать случайно).
от 0,8 до 1: сильная положительная связь.
1: детерминированная (неслучайная, строгая) положительная связь показателей.
Коэффициент корреляции полезен для определения причинно-следственных связей. При этом связь может быть двусторонней (например, привлекательность соцсети и количество зарегистрировавшихся пользователей — так называемый сетевой эффект). Чем привлекательнее социальная сеть, тем больше в ней регистрируется людей. Верно и в обратную сторону: чем больше зарегистрировавшихся пользователей, тем привлекательнее соцсеть.
Часто встречается односторонняя связь, например сложность пожара и количество пожарных, участвовавших в его тушении. Из наблюдаемой положительной корреляции вряд ли стоит делать вывод, что сложность пожара зависит от количества пожарных, или пытаться снизить сложность пожара, уменьшая количество пожарных в команде. Тем не менее обратная взаимосвязь выглядит разумной. При этом помните, что наличие статистической взаимосвязи не обязательно говорит о причинно-следственной связи. Корреляция бывает ложной. Блогер Дмитрий Чернышев в своем Живом Журнале приводит курьезные примеры, в которых присутствует статистическая связь, но явно отсутствует причинно-следственная. Так, есть сильная корреляция между:
- потреблением моцареллы и количеством докторских степеней (один из самых известных примеров);
- потреблением сметаны и количеством мотоциклистов, погибших в ДТП;
- средним возрастом «Мисс Америка» и количеством людей, погибших от горячего пара, и т. д.
Другой пример ложной корреляции — та, что возникает по причине наличия общего тренда. Например, положительная корреляция между числом выехавших на отдых за рубеж и количеством произведенных турбин. Очевидно, что причинно-следственной связи между показателями нет. Но можно предположить, что оба показателя могут зависеть от экономического роста в стране. Значения коэффициента корреляции, близкие к нулю, необязательно говорят об отсутствии причинно-следственной связи — только об отсутствии линейной зависимости, взаимосвязь между величинами может быть более сложной.
Таким образом, при анализе статистической взаимосвязи в первую очередь нужно опираться на логическую объяснимость направления (положительная или отрицательная) и силы взаимосвязи. Если эмпирический опыт подтверждается корреляцией, можно смело ее использовать. Если статистика не соответствует практике, необходимо использовать ее с осторожностью.
Кстати, и наличие корреляции не означает наличия причинно-следственной связи. Возможно, обе величины связаны с какой-то третьей и поэтому коррелируют, но между ними может не быть причинно-следственной связи.
Для расчета коэффициента корреляции в Google Таблицах и Excel (пример демонстрируется в Google Таблицах) есть функция КОРРЕЛ (CORREL). Ее аргументы — это диапазоны с наблюденными значениями показателей.
В примере в столбцах A и B находятся случайные числа (сгенерированные с помощью функции СЛУЧМЕЖДУ (RANDBETWEEN)). Коэффициент корреляции практически нулевой — что вполне естественно. Между двумя массивами случайных чисел связи нет.
Связь можно анализировать и на диаграммах — хорошо подходит точечная:
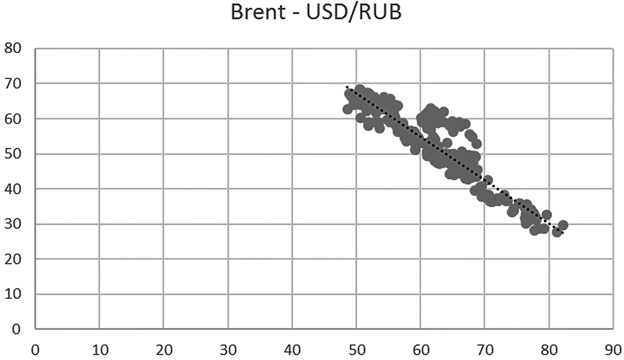
В следующем примере мы рассчитываем корреляцию между ценой нефти марки Brent и курсом USD/RUB. Связь весьма сильная: –0,82.
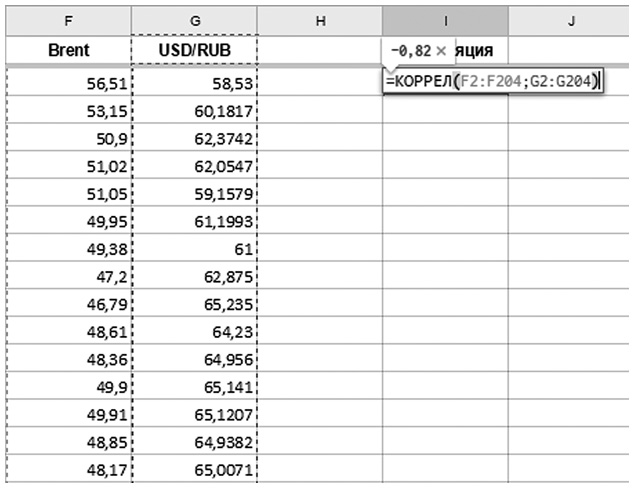
Диаграмма для этих данных:
Функция КОРРЕЛ аналогично работает и в Excel.
246. МАСШТАБ ОСИ НА ГРАФИКЕ МЕНЯЕТ ВСЕ
Мы склонны верить точным цифрам и графикам (возможно, вы слышали о том, что в XIX веке высоту Джомолунгмы преувеличили — вместо 29 тысяч футов указали 29 002, чтобы людям не казалось, что расчеты были примерными). Но и статистика, и графики представляют собой поле для манипуляций.
Так, если на графике немного подкорректировать значения вертикальной оси и отобразить неполный период, то совсем небольшие колебания могут выглядеть как тренд или гигантский скачок.
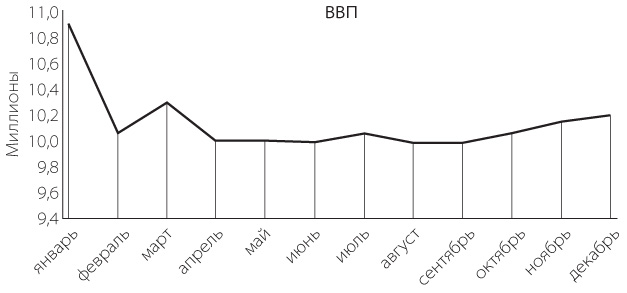
Представьте, что на графике ниже — ВВП некой страны. Неплохой рывок в конце года, не так ли?
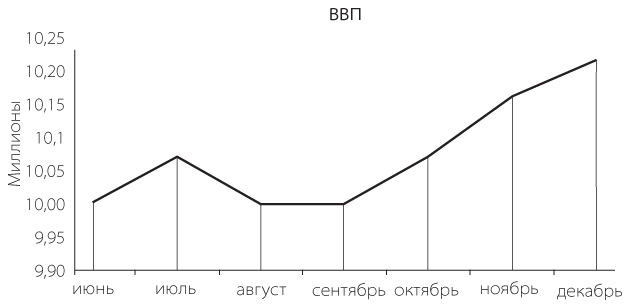
Но на самом деле это не рывок, а незначительный рост. И только в рамках полугодия – относительно первого полугодия же не все так радужно. Все дело в том, что диапазон значений оси на первом графике меньше и на нем нет первого полугодия.
Если вы хотите подробнее ознакомиться со статистическими манипуляциями, прочитайте небольшую книгу Дарелла Хаффа «Как лгать при помощи статистики», где анализируются и объясняются все способы манипулирования данными.
247. СООТНОШЕНИЕ DATA INK
Не используйте объем, затенение и другие визуальные эффекты, которые лишь мешают восприятию графиков и диаграмм.
Существует формула, разработанная Эдвардом Тафти — главным специалистом по информационному дизайну:

Или, если перевести на русский язык:
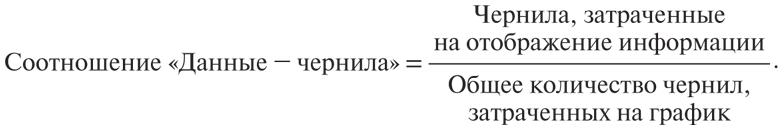
В идеале это соотношение должно быть равно единице. Но часто оно гораздо ниже, потому что на графике много дополнительных неинформативных элементов. Сравните, например, следующие две круговые диаграммы, отображающие структуру продаж овощной лавки:
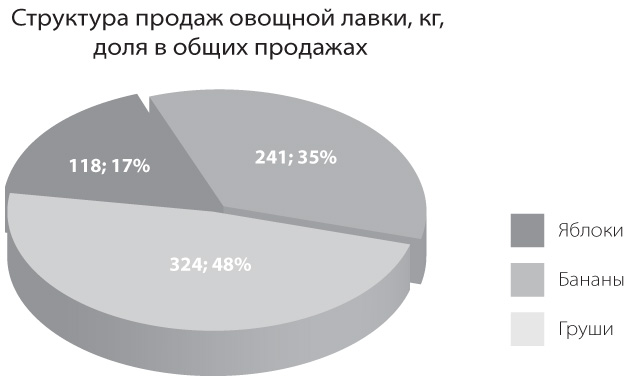
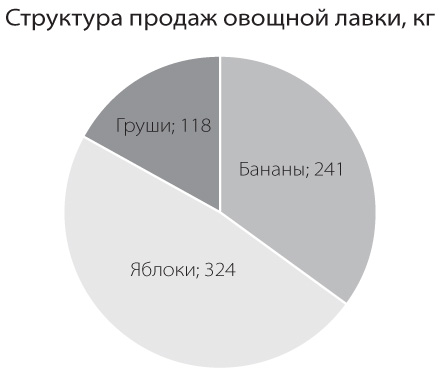
Кстати, круговые диаграммы, даже с хорошим коэффициентом Data-Ink, часто проигрывают линейчатым в простоте восприятия сообщения:
Больше о типах диаграмм можно прочитать в книге Джина Желязны «Говори на языке диаграмм».

