Путешествие в будущее
Каждое решение учитывает прошлый опыт (хранящийся в состояниях нашего тела), а также текущую ситуацию («Хватит ли у меня денег, чтобы купить X вместо Y?», «Доступен ли вариант Z?»). Однако в истории о принятии решений есть еще одна часть: предсказание будущего.
Любое существо, принадлежащее к животному миру, запрограммировано на поиск вознаграждения. Что такое вознаграждение? В общем случае – нечто такое, что приблизит организм к идеальной цели. Вода служит вознаграждением, когда ваш организм обезвожен, а пища – когда заканчиваются запасы энергии. Вода и пища называются первичным подкреплением, которое непосредственно связано с биологическими потребностями. Однако гораздо чаще поведением человека управляют вторичные подкрепления, то есть такие, которые предсказывают первичные. Например, металлический прямоугольник сам по себе ничего не значит для мозга, но, поскольку вы научились распознавать его как фонтанчик для питья, его вид становится вознаграждением, когда вы испытываете жажду. У людей можно выявить еще более абстрактные концепции подкрепления, например ощущение, что нас ценят окружающие. В отличие от животных мы нередко ставим эти подкрепления выше биологических потребностей. По меткому выражению Рида Монтегю, «акулы не устраивают голодовки»: остальные представители животного мира стремятся лишь к удовлетворению базовых потребностей, и только человек постоянно жертвует этими потребностями в угоду абстрактным идеям. Таким образом, когда мы оказываемся перед выбором из нескольких возможностей, то объединяем внутренние и внешние данные, чтобы максимизировать вознаграждение, каким бы индивидуальным оно ни было.
Трудность с любым подкреплением, базовым или абстрактным, состоит в том, что его плоды обычно не бывают мгновенными. Мы почти всегда принимаем решения, при которых выбранный образ действия приносит вознаграждение не сразу, а через какое-то время. Люди много лет ходят в школу, потому что ценят будущий аттестат, не бросают нелюбимую работу, поскольку надеются на повышение; они мучают себя физическими нагрузками, надеясь добиться хорошей физической формы.
Для сравнения разных вариантов необходимо присвоить каждому из них ценность в общей валюте, то есть ожидаемого вознаграждения, а затем выбрать тот, при котором вознаграждение выше. Рассмотрим следующий сценарий: у меня есть немного свободного времени, и я пытаюсь решить, чем заняться. Мне нужно купить кое-что из бакалеи, а кроме того, зайти в кафе и составить заявку на грант для лаборатории, поскольку осталось уже мало времени. И еще мне хочется погулять с сыном в парке. Как мне расставить приоритеты в этом списке вариантов?
Конечно, все было бы просто, будь у меня возможность пережить эти варианты, каждый раз возвращаясь назад во времени, а потом выбрать тот, который приводит к наилучшему результату. Увы, я не умею путешествовать во времени.
Или умею?
Мозг человека постоянно путешествует во времени. Когда нам нужно принять решение, мозг симулирует различные результаты действий, чтобы нарисовать возможную картину будущего. Мысленно мы способны отключаться от настоящего и перемещаться в несуществующий мир.

Люди ежедневно возвращаются в прошлое, как в фильме «Назад в будущее».
Как бы то ни было, мысленная симуляция того или иного варианта – это всего лишь первый шаг. Чтобы сделать выбор между воображаемыми сценариями, я пытаюсь оценить, какое вознаграждение получу в каждом случае. Представляя, как заполняю кладовку бакалейными товарами, я чувствую облегчение оттого, что проявил организованность и избавился от неопределенности. Получение гранта дает подкрепление иного рода: не только деньги для лаборатории, но также уважение декана и чувство удовлетворения от профессиональных успехов. Представив себя в парке с сыном, я испытываю радость и получаю вознаграждение в виде крепких семейных связей. Окончательное решение определится тем, как каждый вариант будущего оценивается в общей валюте моей подкрепляющей системы. Сделать выбор нелегко, поскольку в каждом из вариантов имеются нюансы: симуляция покупки бакалеи сопровождается ощущением скуки, заявке на грант сопутствует чувство неудовлетворенности, а прогулке по парку – ощущение вины из-за несделанной работы. Обычно сознание по очереди симулирует все варианты и получает ответ от интуиции. Именно так я делаю выбор.
Насколько точна моя симуляция будущего? Могу ли я предсказать, что произойдет на самом деле при выборе каждого из этих вариантов? Ответ прост: не могу. Точность моих предсказаний проверить невозможно. Все симуляции основаны только на прошлом опыте, а также на моих теперешних моделях устройства мира. Как и все представители животного мира, мы не можем бездействовать, надеясь случайным образом выяснить, что принесет вознаграждение в будущем, а что нет. Главная задача мозга – предсказывать, и, чтобы достаточно хорошо справляться с этой задачей, мы должны постоянно изучать окружающий мир на собственном опыте. Таким образом, в данном случае я даю оценку каждому варианту на основе прошлого опыта. Строя в своей голове голливудскую студию, мы путешествуем во времени в воображаемое будущее, чтобы определить его ценность. Именно так я и делаю выбор – сравнивая друг с другом варианты возможного будущего. Именно так я перевожу соперничающие варианты в общую валюту вознаграждения.
Величину вознаграждения для каждого варианта можно рассматривать как внутреннюю похвалу, отражающую полезность чего-либо. Поскольку покупка бакалеи обеспечит меня пищей, присвоим ей десять единиц. Заявка на грант – нелегкое, но необходимое для моей карьеры дело, и поэтому она весит двадцать пять единиц вознаграждения. Я люблю проводить время с сыном, и прогулка по парку стоит пятьдесят единиц.
Однако тут есть один интересный поворот: мир сложен, и наша внутренняя похвала не является чем-то постоянным. Оценка окружающего мира непрерывно меняется, поскольку предсказания довольно часто не совпадают с тем, что происходит на самом деле. Ключ к эффективному обучению состоит в отслеживании этой ошибки предсказания: разницы между ожидаемым результатом выбора и результатом, полученным в действительности.
В данном случае у моего мозга есть предсказание о том, какое вознаграждение может ждать меня в парке. Если мы встретим там друзей и все обернется лучше, чем я ожидал, в следующий раз это повысит оценку данного варианта. С другой стороны, если нам не повезет и пойдет дождь, в следующий раз моя оценка прогулки в парк будет ниже.
Как же это устроено? В мозгу имеется крошечная древняя система, предназначенная для того, чтобы обновлять оценку окружающего мира. Эта система состоит из маленьких групп клеток в среднем мозге, которые общаются на языке нейротрансмиттера под названием «дофамин».
В случае несоответствия между ожиданиями и реальностью дофаминовая система в среднем мозге передает сигнал, который пересматривает оценку. Сигнал сообщает остальной системе, какой оказалась реальность: лучше ожиданий (усиленный выброс дофамина) или хуже ожиданий (уменьшение выработки дофамина). Сигнал об ошибке предсказания позволяет мозгу скорректировать свои ожидания, чтобы в следующий раз они оказались ближе к реальности. Дофамин действует как корректор ошибок: химический оценщик, который поддерживает оценки максимально актуальными. Таким образом мы получаем возможность расставлять приоритеты на основе оптимизированных догадок о будущем.
Мозг запрограммирован на поиск неожиданных результатов, и эта чувствительность лежит в основе способности животных адаптироваться и обучаться. Поэтому неудивительно, что архитектура мозга, участвующая в обучении на собственном опыте, одинакова у всех видов от пчелы до человека. Это означает, что мозг уже давно открыл основные принципы обучения путем вознаграждения.
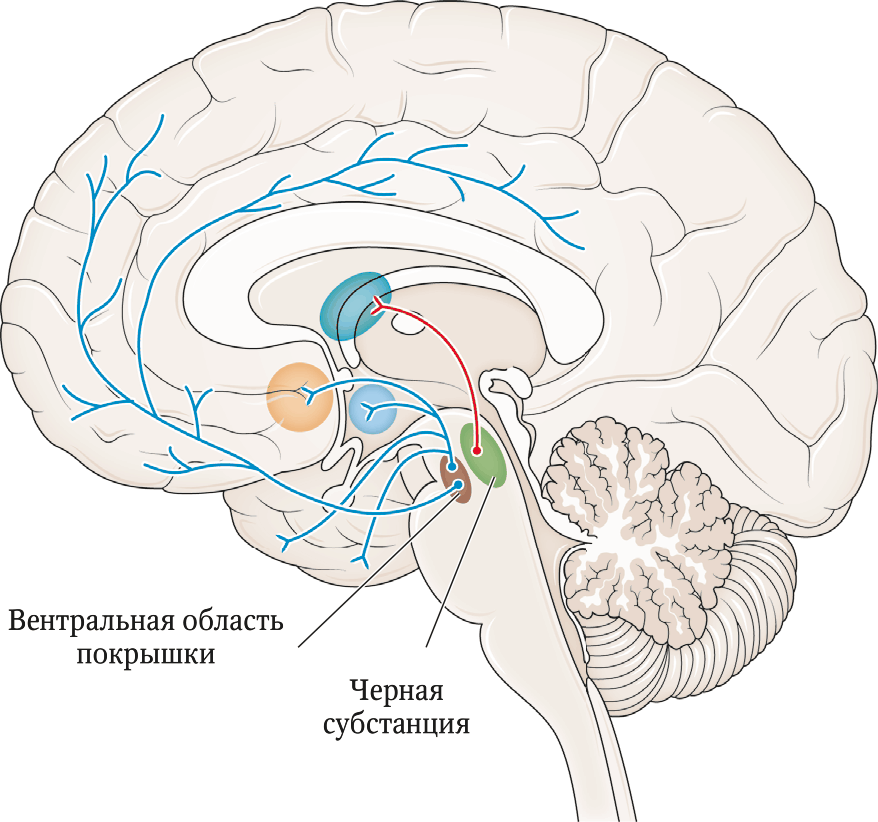
Вырабатывающие дофамин нейроны, участвующие в принятии решений, сосредоточены в крошечных областях мозга, которые носят название вентральной области покрышки и черной субстанции. Несмотря на маленький размер, они имеют огромное влияние, обеспечивая корректировку, когда предсказанная ценность выбора оказывается слишком высокой или слишком низкой.

