10
Опрос общественного мнения
Откуда нам известно, что 64% американцев поддерживают смертную казнь (ошибка выборки ±3%)
В конце 2011 года в газете The New York Times вышла передовая статья, в которой сообщалось, что «страну охватило чувство сильной тревоги и неуверенности в будущем». Авторы публикации всесторонне исследовали психологическое состояние американцев, выяснив общественное мнение по широкому кругу вопросов, от оценки эффективности администрации Обамы до отношения населения к распределению общественного богатства страны. Ниже приведена небольшая выдержка мнений американцев, которые высказывались осенью 2011 года.
- Около 89% американцев (шокирующий показатель!) заявили, что не доверяют правительству (самый высокий уровень недоверия к власти за все время проведения подобных опросов).
- Две трети опрошенных считают, что общественное богатство страны должно распределяться среди граждан более равномерно.
- Сорок три процента жителей страны сказали, что в целом согласны со взглядами участников движения Occupy Wall Street (довольно аморфное протестное движение, стартовавшее в Нью-Йорке вблизи Уолл-стрит и впоследствии охватившее другие города страны). Чуть больше опрошенных, 46%, заявили, что взгляды участников движения Occupy Wall Street «в целом отражают взгляды большинства американцев».
- Сорок шесть процентов американцев одобрили деятельность Барака Обамы на посту президента США — и такие же 46% выразили неудовлетворенность тем, как он справляется со своими обязанностями.
- Лишь 9% жителей страны поддерживают деятельность Конгресса США.
- Несмотря на то что президентские праймериз должны были начаться только через два месяца, примерно 80% избирателей, во время праймериз обычно голосующих за республиканцев, заявляли, что «еще слишком рано говорить о том, кого именно они будут поддерживать».
Впечатляющие данные, приведенные выше, давали политическим аналитикам обильную пищу для изучения настроений американцев за год до президентских выборов. Правда, возникает резонный вопрос: откуда все это известно? Как удалось сделать столь далекоидущие выводы о настроениях сотен миллионов взрослых американцев? И почему мы должны верить, что эти выводы верны?
Ответ очевиден: это результат опросов общественного мнения. К тому же в приведенном выше примере их проводили The New York Times и CBS News. (То обстоятельство, что две конкурирующие новостные организации совместно реализовывали проект, подобный этому, является первым указанием на то, что такие исследования довольно затратны.) Я не сомневаюсь, что вы знакомы с результатами этих опросов. Возможно, не столь явно выраженным кажется тот факт, что методология их проведения представляет собой всего лишь еще одну форму статистического вывода. Опрос общественного мнения — это получение выводов о настроениях определенной совокупности людей, основанных на мнениях, высказанных некоторой выборкой, сформированной из генеральной совокупности.
Эффективность опросов обусловливается использованием того же источника, что и в предыдущих примерах с выборками, — центральной предельной теоремы. Если мы опрашиваем достаточно большую репрезентативную выборку избирателей (или любую другую группу), то у нас есть все основания полагать, что она будет очень похожа на совокупность, из которой извлечена. Если ровно половина взрослых американцев не одобряют однополые браки, то мы вполне можем рассчитывать, что в репрезентативной выборке из 1000 американцев примерно половина ее членов также выступят против однополых браков.
И наоборот (что гораздо важнее для проведения опросов общественного мнения), если в репрезентативной выборке из 1000 американцев удалось выявить определенные настроения, например 46% недовольны деятельностью Обамы на посту президента США, то это дает веский повод думать, что среди населения в целом — примерно в такой же пропорции — также присутствуют подобные настроения. Вообще говоря, мы можем рассчитать вероятность того, что результаты, полученные с помощью нашей выборки, будут значительно отклоняться от доминирующих настроений в обществе. Когда вы читаете, что статистическая погрешность составляет ±3%, в действительности речь идет о том же 95%-ном доверительном интервале, который мы вычисляли в предыдущей главе. Наш «95%-ный доверительный интервал» означает, что если бы мы провели 100 разных опросов общественного мнения в выборках, сформированных из одной и той же совокупности, то, предположительно, полученные ответы в 95 из 100 опросов отличались бы (в ту или другую сторону) от истинных настроений этой совокупности не более чем на 3%. В контексте вопроса об оценке деятельности Обамы на посту президента США, фигурировавшего в опросе, проводившемся The New York Times и CBS News, мы могли на 95% быть уверены, что истинная доля американцев, не одобряющих его деятельность, находится в диапазоне 46 ± 3%, то есть от 43% до 49%. Если вы прочитаете сопроводительный текст к опросу, набранный мелким шрифтом (между прочим, я бы настоятельно рекомендовал вам всегда это делать), то увидите, что его смысл заключается в следующем: «Теоретически в 19 случаях из 20 результаты, базирующиеся на таких выборках, будут отличаться не более чем на 3% (в ту или другую сторону) от результатов, которые были бы получены в ходе опроса всех взрослых американцев».
Одно из фундаментальных отличий опросов общественного мнения от других форм использования метода выборки состоит в том, что интересующим нас статистическим показателем выборки будет не среднее значение (например, 187 фунтов веса), а некий процент или доля (например, 47% избирателей, или 0,47). В остальном же процессы идентичны. При наличии крупной репрезентативной выборки (опрос общественного мнения) можно ожидать, что доля респондентов, охваченных определенными настроениями (например, 9% респондентов в этой выборке одобряют деятельность Конгресса США), примерно равна доле американских избирателей в целом, испытывающих аналогичные настроения. Это в принципе ничем не отличается от предположения о том, что средний вес выборки из 1000 мужчин-американцев должен примерно равняться среднему весу всех мужчин-американцев. Тем не менее мы допускаем вероятность какого-то разброса от выборки к выборке доли тех, кто одобряет деятельность Конгресса США, точно так же как у нас есть все основания ожидать какого-то разброса в средних значениях веса при использовании разных произвольных выборок из 1000 мужчин-американцев. Если бы The New York Times и CBS News провели еще один опрос — задавая те же вопросы другой выборке из 1000 взрослых американцев, — то очень маловероятно, что его результаты полностью бы совпали с результатами первого опроса. С другой стороны, можно ожидать, что ответы, полученные в ходе первого и второго опросов, будут незначительно отличаться между собой. (Воспользуюсь метафорой, к которой уже прибегал в этой книге: если вы попробуете ложку супа из кастрюли, затем хорошенько перемешаете суп и попробуете ложку супа еще раз, то его вкус, скорее всего, покажется вам примерно таким же.) Стандартная ошибка — вот что указывает на то, какого разброса результатов от выборки к выборке (в данном случае от опроса к опросу) мы можем ожидать.
Формула расчета стандартной ошибки в случае, когда речь идет о процентной величине или доле, несколько отличается от формулы, с которой вы уже познакомились; впрочем, интуитивные соображения остаются такими же. Для любой произвольной выборки, сформированной надлежащим образом, стандартная ошибка равняется 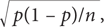 где p — доля респондентов, выражающих определенную точку зрения, (1 – p) — доля респондентов, имеющих противоположную точку зрения, а n — общее количество респондентов в выборке. Обратите внимание, что стандартная ошибка будет уменьшаться с увеличением размера выборки, поскольку n находится в знаменателе. Стандартная ошибка также будет уменьшаться с увеличением разности между p и (1 – p). Например, стандартная ошибка будет меньше в случае опроса, в ходе которого 95% респондентов выражают определенную точку зрения, чем в случае опроса, в котором мнения респондентов разделяются примерно 50 на 50. Это чисто математический результат, поскольку 0,05×0,95 = 0,047, тогда как 0,5×0,5 = 0,25; меньшая величина в числителе формулы ведет к уменьшению стандартной ошибки.
где p — доля респондентов, выражающих определенную точку зрения, (1 – p) — доля респондентов, имеющих противоположную точку зрения, а n — общее количество респондентов в выборке. Обратите внимание, что стандартная ошибка будет уменьшаться с увеличением размера выборки, поскольку n находится в знаменателе. Стандартная ошибка также будет уменьшаться с увеличением разности между p и (1 – p). Например, стандартная ошибка будет меньше в случае опроса, в ходе которого 95% респондентов выражают определенную точку зрения, чем в случае опроса, в котором мнения респондентов разделяются примерно 50 на 50. Это чисто математический результат, поскольку 0,05×0,95 = 0,047, тогда как 0,5×0,5 = 0,25; меньшая величина в числителе формулы ведет к уменьшению стандартной ошибки.
Допустим, что в результате проведения простого экзитпола репрезентативной выборки из 500 избирателей выяснилось, что 53% проголосовали за кандидата от республиканцев, 45% — за кандидата от демократов и 2% поддержали независимого кандидата. Если использовать кандидата от республиканцев как интересующую нас долю, то стандартная ошибка для этого экзитпола составит:
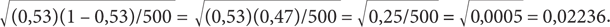
Для упрощения округлим стандартную ошибку для этого экзитпола до 0,02. Пока это всего лишь некое число. Подумаем, почему оно так важно для нас. Предположим, избирательные участки только что закрылись, и вашему работодателю (коим является некая телекомпания) не терпится объявить победителя выборов еще до того, как станут известны официальные результаты. Вам как человеку, уже прочитавшему две трети этой книги, поручено заниматься обработкой данных, полученных в ходе экзитпола. Ваш начальник желает знать, можно ли на их основании назвать победителя выборов.
Вы объясняете, что ответ на этот вопрос зависит от того, насколько уверенной хочет быть телекомпания в правильности своего заявления — или, точнее говоря, какой риск она готова принять на себя, если оно окажется ошибочным. Вспомните: стандартная ошибка дает нам представление о том, как часто можно ожидать, что доля в выборке (экзитпол) окажется достаточно близкой к истинной доле в совокупности (результат голосования). Нам известно, что примерно в 68% случаев мы можем ожидать, что доля в выборке — в данном случае 53% избирателей, которые утверждают, что проголосовали за кандидата от республиканцев, — отстоит от истинного окончательного результата голосования не более чем на одну стандартную ошибку. Таким образом, вы говорите начальнику «с 68%-ной уверенностью», что ваша выборка, которая показывает, что кандидат от республиканцев получил голоса 53% избирателей ± 2%, то есть между 51 и 55%, соответствует истинному достигнутому им результату. Между тем, согласно тому же экзитполу, за кандидата от демократов отдали голоса 45% избирателей. Если предположить, что итог голосования за кандидата от демократов имеет ту же стандартную ошибку (упрощение, суть которого я объясню ниже), то с 68%-ной уверенностью можно утверждать, что наша выборка (экзитпол), которая показывает, что за кандидата от демократов проголосовали 45% избирателей ± 2%, то есть между 43 и 47%, заключает в себе истинный результат этого кандидата. Согласно этому подсчету, победителем становится кандидат от республиканцев.
Группа графического дизайна бросается строить красочную трехмерную диаграмму, чтобы вы могли отобразить ее на экранах ваших телезрителей:
Представитель Республиканской партии 53%
Представитель Демократической партии 45%
Независимый кандидат 2%
(Предел погрешности 2%)
Поначалу ваш босс приходит в восторг — главным образом потому, что диаграмма представлена в трехмерном виде, насыщена яркими красками и даже может вращаться на экране вокруг вертикальной оси. Однако когда вы объясняете, что примерно в 68 случаях из 100 результаты экзитпола будут отличаться от действительных результатов выборов не более чем на одну стандартную ошибку, ваш начальник, которому уже не раз приходилось посещать курсы аутотренинга и управления негативными эмоциями, указывает на совершенно очевидную вещь: в 32 случаях из 100 результаты экзитпола будут отличаться от действительных результатов выборов более чем на одну стандартную ошибку. И что тогда?
Вы объясняете, что есть два варианта: 1) кандидат от республиканцев мог получить даже больше голосов, чем предсказывал экзитпол, тогда все равно вы назвали бы победителя правильно; 2) но существует достаточно высокая вероятность того, что кандидат от демократов набрал гораздо больше голосов, чем предсказывал экзитпол; в этом случае ваша восхитительная красочная вращающаяся трехмерная диаграмма объявит победителя неправильно.
Босс запускает чашкой с кофе в стену, из чего вы делаете вывод, что посещение курсов аутотренинга и управления негативными эмоциями не пошло ему на пользу. Между тем, начальник продолжает бушевать: «Как, черт бы вас побрал, мы можем быть уверены в правильности результата, показанного на вашей …ной диаграмме?»
Понимая кое-что в статистике, вы указываете ему, что не можете быть уверены в каком-либо результате до тех пор, пока не будут подсчитаны все голоса. И предлагаете в качестве критерия уверенности воспользоваться 95-процентным доверительным интервалом. В данном случае ваша восхитительная красочная вращающаяся 3D-диаграмма предскажет победителя неправильно в среднем лишь в 5 случаях из 100.
Начальник закуривает сигарету и пытается успокоиться. Вы решаете не напоминать ему о запрете курения на рабочем месте, несмотря на участившиеся в последнее время случаи пожаров в офисах, однако все же отваживаетесь поделиться кое-какими плохими новостями: единственный способ, позволяющий вашей телекомпании повысить уверенность в результатах экзитпола, — расширить предел погрешности, но тогда однозначно назвать победителя выборов будет невозможно. После этого вы показываете начальнику новую 3D-диаграмму:
Представитель Республиканской партии 53%
Представитель Демократической партии 45%
Независимый кандидат 2%
(Предел погрешности 4%)
Из центральной предельной теоремы вам известно, что приблизительно 95% пропорций выборки будут отстоять от истинной пропорции доли голосов совокупности на расстоянии, не превышающем двух стандартных ошибок (в данном случае 4%). Таким образом, если мы хотим обеспечить большую уверенность в результатах экзитпола, то нам придется умерить свои амбиции в том, что касается точности прогноза. Как следует из приведенной выше пропорции доли голосов (к сожалению, мы не можем показать здесь соответствующую красочную вращающуюся 3D-диаграмму), ваша телекомпания может, при 95%-ном доверительном уровне, объявить о том, что кандидат от республиканцев получил 53% голосов избирателей ± 4%, то есть между 49 и 57% голосов избирателей, а кандидат от демократов — 45% ± 4%, то есть между 41 и 49% голосов избирателей.
Правда, теперь вы сталкиваетесь с новой проблемой. При 95%-ном доверительном уровне вы не можете отвергнуть вероятность того, что каждый из кандидатов мог набрать по 49% голосов избирателей. Это неизбежный компромисс; единственная возможность обрести большую уверенность в том, что результаты вашего экзитпола будут соответствовать истинным результатам выборов без использования новых данных, — обуздать свои амбиции относительно точности прогнозов. Подумайте об этом вне статистического контекста. Допустим, вы говорите приятелю, что «почти не сомневаетесь» в том, что Томас Джефферсон был третьим или четвертым президентом США. Каким образом вы можете обрести большую уверенность в своих исторических познаниях? Снизив категоричность утверждений. Можно, например, сказать, что вы «абсолютно уверены» в том, что Томас Джефферсон был одним из первых пяти президентов США.
Ваш начальник предлагает вам заказать пиццу и быть готовым к тому, что придется поработать вечером (или даже всю ночь). На этот раз статистические боги оказываются к вам милостивы. Вам на стол кладут данные второго экзитпола, для проведения которого использовалась выборка из 2000 избирателей. Его результаты таковы: кандидат-республиканец — 52% голосов, кандидат-демократ — 45% голосов, независимый кандидат — 3% голосов. На этот раз ваш босс совершенно взбешен, поскольку эти данные показывают, что разрыв между кандидатами сократился, а это еще больше затрудняет своевременное предсказание итогов голосования. Но не нужно спешить с выводами! Вы указываете (стараясь сохранять присутствие духа), что размер второй выборки (2000) в четыре раза больше первой, которая использовалась при проведении первого экзитпола. Таким образом, стандартная ошибка существенно уменьшилась. Новая стандартная ошибка для кандидата от республиканцев равняется 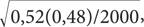 что составляет 0,01.
что составляет 0,01.
Если вашего начальника по-прежнему устраивает 95%-ный доверительный интервал, то вы можете объявить победителем кандидата от республиканцев. С учетом вашей новой стандартной ошибки 0,01 95%-ные доверительные интервалы для кандидатов таковы: кандидат-республиканец: 52 ± 2, или между 50 и 54% голосов избирателей; кандидат-демократ 45 ± 2, или между 43 и 47% голосов избирателей. Теперь между этими двумя доверительными интервалами нет никакого взаимного перекрытия. Вы можете в прямом эфире сообщить, что на выборах победил кандидат от республиканцев; такой прогноз окажется правильным более чем в 95 случаях из 100.
Но это даже лучше. Из центральной предельной теоремы вам известно, что в 99,7% случаев пропорция долей выборки будет отстоять от истинной пропорции долей совокупности на расстоянии, не превышающем трех стандартных ошибок. В нашем примере с выборами 99,7%-ные доверительные интервалы для двух кандидатов таковы: кандидат от республиканцев: 52 ± 3%, или между 49 и 55% голосов избирателей; кандидат от демократов 45 ± 3%, или между 42 и 48% голосов избирателей. То есть после того как вы объявите победителем выборов кандидата-республиканца, благодаря новой выборке из 2000 избирателей останется лишь ничтожная вероятность того, что вы вместе со своим начальником будете уволены.
Вы, наверное, обратили внимание, что использование большей по объему выборки снижает стандартную ошибку. Именно за счет этого крупные общенациональные опросы позволяют получить необычайно точные результаты. В то же время выборки меньшего размера увеличивают величины стандартных ошибок и, следовательно, доверительный интервал (или «предел ошибки выборочного исследования», как принято говорить среди специалистов по проведению опросов общественного мнения). Текст, набранный мелким шрифтом в опросе The New York Times / CBS News, гласит, что предел погрешности для вопросов по поводу праймериз республиканцев составляет 5 процентных пунктов в сравнении с 3 процентными пунктами для других вопросов, включенных в опрос общественного мнения. Эти вопросы задавались лишь тем, кто сам назвал себя сторонником Республиканской партии, и тем, кто участвовал в голосованиях на закрытых собраниях ее членов, поэтому размер выборки для данной подгруппы вопросов снизился до 455 (общее количество избирателей, участвовавших в опросе, составило 1650).
Как обычно, примеры, приведенные в этой главе, «грешат» многими упрощениями. Вы, наверное, обратили внимание, что в примере с выборами у кандидатов от Республиканской и Демократической партий должна была быть своя собственная стандартная ошибка. Вернемся еще раз к приведенной выше формуле: 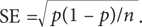 Размер выборки n один и тот же для обоих кандидатов, однако p и (1 – p) будут несколько разниться. Во втором экзитполе (когда размер выборки был увеличен до 2000 избирателей) стандартная ошибка для кандидата от Республиканской партии составила
Размер выборки n один и тот же для обоих кандидатов, однако p и (1 – p) будут несколько разниться. Во втором экзитполе (когда размер выборки был увеличен до 2000 избирателей) стандартная ошибка для кандидата от Республиканской партии составила 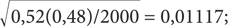 для кандидата от Демократической партии —
для кандидата от Демократической партии — 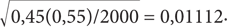 Разумеется, какими бы ни были наши намерения и цели, эти два числа должны быть одинаковы. Именно поэтому я остановил свой выбор на общепринятом соглашении: из двух значений стандартной ошибки использовать большее значение для всех кандидатов. В любом случае такой подход вносит в доверительные интервалы небольшую дополнительную меру предосторожности.
Разумеется, какими бы ни были наши намерения и цели, эти два числа должны быть одинаковы. Именно поэтому я остановил свой выбор на общепринятом соглашении: из двух значений стандартной ошибки использовать большее значение для всех кандидатов. В любом случае такой подход вносит в доверительные интервалы небольшую дополнительную меру предосторожности.
При проведении многих общенациональных опросов общественного мнения, включающих в себя большое число вопросов, идут еще дальше. В случае опроса The New York Times / CBS News для каждого вопроса должна быть, строго говоря, своя стандартная ошибка (в зависимости от ответа). Например, стандартная ошибка, относящаяся к ситуации, когда 9% участников опроса одобряют деятельность Конгресса США, должна быть меньше стандартной ошибки, относящейся к ситуации, когда 46% участников опроса одобряют деятельность Обамы на посту президента США, поскольку 0,09 × 0,91 меньше, чем 0,46 × 0,54: 0,0819 против 0,2484. (Интуитивные соображения, на которых основывается эта формула, объясняются в к настоящей главе.)
Поскольку использование собственной стандартной ошибки для каждого вопроса было бы неудобным и вносило бы излишнюю путаницу, при проведении подобных опросов общественного мнения обычно предполагается, что доля выборки для каждого вопроса равняется 0,5 (или 50%) — что порождает максимально возможную стандартную ошибку для любого размера выборки, — и именно такая стандартная ошибка используется при вычислении предела ошибки выборки для опроса в целом.
При соответствующей организации опросы общественного мнения становятся поистине замечательными инструментами. Согласно Фрэнку Ньюпору, главному редактору Gallup Organization, опрос 1000 человек позволяет с высокой степенью точности оценить настроения в обществе в целом. С точки зрения статистики Фрэнк Ньюпор, несомненно, прав. Но чтобы получить столь значимые и точные данные, мы должны надлежащим образом провести опрос, а затем правильно интерпретировать его результаты, что порой намного легче сказать, чем сделать. Неправильные результаты опросов обычно обусловлены не ошибкой в математических расчетах при вычислении стандартных ошибок, а являются следствием некорректно сформированной выборки, или неправильно сформулированных вопросов, или того и другого. Выражение «мусор на входе — мусор на выходе» полностью применимо к проведению социологических опросов. Ниже перечислены ключевые методологические вопросы, которые необходимо задать при проведении любого опроса общественного мнения или оценивании чьей-то работы.
Действительно ли данная выборка является репрезентативной (представительной) из совокупности, настроения которой мы пытаемся выяснить? Многие типичные проблемы, связанные с данными, уже обсуждались в главе 7. Тем не менее мне придется еще раз указать на опасность систематической ошибки выбора, особенно систематической ошибки самоотбора. Любой опрос, результаты которого зависят от людей, попадающих в выборку по собственной инициативе, например в ходе ток-шоу на радио или при проведении добровольных интернет-опросов, будет отражать мнения лишь тех, кто сам пожелал его высказать. В подобных случаях мы узнаем лишь мнения людей, которые проявляют повышенный интерес к рассматриваемому вопросу или располагают избытком свободного времени. Очевидно, что ни та ни другая группа не может отражать общие настроения общества. Однажды я сам участвовал в ток-шоу на радио в качестве гостя. Один из слушателей программы, ехавший в это время в автомобиле по каким-то своим делам, позвонил на радиостанцию и выразил категорическое несогласие с моим мнением. Мои взгляды возмутили его до такой степени, что он не поленился свернуть с автомагистрали к телефонной будке, которую заметил возле обочины, чтобы позвонить в радиостудию. Хотелось бы верить, что те слушатели, которые во время этого ток-шоу не свернули с автомагистрали, разделяли мои взгляды.
Любой метод выяснения мнений, который систематически исключает какой-либо сегмент совокупности, также приводит к ошибке выбора. Например, широкое распространение мобильной связи породило множество новых методологических сложностей. Организации, специализирующиеся на проведении социологических опросов, делают все от них зависящее, чтобы опросить репрезентативную выборку соответствующей совокупности. Опрос The New York Times / CBS News базировался на телефонных интервью, проводившихся на протяжении шести дней с 1650 взрослыми американцами, 1475 из которых сообщили, что зарегистрированы для участия в голосовании.
Относительно остальной части методологии, применявшейся при проведении этого опроса, я могу лишь догадываться, но большинство опросов, которые проводятся социологическими организациями, используют тот или иной вариант описанных ниже методов. Чтобы гарантировать, что люди, поднявшие трубку, отражают мнение совокупности в целом, данный процесс начинается с использования теории вероятностей — нечто наподобие вытаскивания шариков из урны. Компьютер случайным образом выбирает некую совокупность номеров коммутационных станций стационарной телефонной связи. (Номер коммутационной станции стационарной телефонной связи представляет собой код региона плюс первые три цифры телефонного номера.) За счет случайного выбора 69 000 номеров коммутационных станций стационарной телефонной связи в Соединенных Штатах, каждый в пропорции к своей доле во всей совокупности телефонных номеров, данный опрос в целом, по-видимому, отразит географическое распределение соответствующей совокупности. Как поясняется в тексте, набранном мелким шрифтом, «номера коммутационных станций стационарной телефонной связи были выбраны таким образом, чтобы каждый регион страны был представлен в пропорции к его доле во всей совокупности телефонных номеров». К каждому выбранному номеру компьютер добавил четыре случайные цифры. Таким образом, в окончательном списке домохозяйств, которые предстояло обзвонить в ходе опроса, оказались как фактически используемые, так и неиспользуемые телефонные номера. Кроме того, этот опрос предусматривал «случайный набор номеров мобильных телефонов».
Для каждого набираемого телефонного номера один взрослый член семьи назначался респондентом посредством некой «произвольной процедуры» (например, телефонную трубку предлагалось взять самому молодому из взрослых членов семьи). Этот процесс был усовершенствован, чтобы получить выборку респондентов, отражающую возрастной и половой состав взрослого населения страны. Самое главное — интервьюер будет пытаться сделать несколько звонков в разное время суток, чтобы дозвониться на каждый из выбранных телефонных номеров. Эти неоднократные попытки — до десяти или двенадцати звонков на один и тот же телефонный номер — являются важным условием получения правильной выборки. Очевидно, было бы дешевле и проще звонить на разные телефонные номера до тех пор, пока достаточно большая выборка взрослых не подойдет к телефонам и не ответит на соответствующие вопросы. Однако такая выборка допустила бы сильный крен в пользу тех, кто большую часть времени проводит дома, а в это число входят главным образом безработные, пенсионеры, инвалиды и т. д. Такой вариант опроса был бы вполне уместен, если бы вы намеревались квалифицировать его результаты следующим образом: деятельность Обамы на посту президента США одобряют 46% безработных, пенсионеров и прочих слоев населения, с готовностью отвечающих на телефонные опросы общественного мнения.
Одним из показателей достоверности опроса является так называемый процент ответивших, то есть доля респондентов, выбранных для проведения опроса и в конечном счете ответивших на его вопросы. Низкий процент ответивших может указывать на неправильное формирование выборки. Чем больше респондентов отказались отвечать на поставленные вопросы (или до них просто не удалось дозвониться), тем выше вероятность, что эта значительная группа людей в чем-то весьма существенно отличается от тех, кто согласился участвовать в опросе. Организаторы опроса могут выполнить тест на «систематическую ошибку отсутствия ответа», проанализировав имеющиеся в их распоряжении данные о респондентах, с которыми им не удалось установить контакт. Возможно, они проживают в каком-то специфическом регионе, или не желают отвечать на вопросы в силу какой-то особой причины, или принадлежат к какой-то расовой или этнической группе, или имеют какой-то определенный уровень дохода. Анализ такого рода зачастую помогает выяснить, повлияет ли низкий процент ответивших на результаты опроса в целом.
Позволяет ли формулировка вопросов получить точную информацию по интересующим нас темам? Чтобы выяснить настроения в обществе, необходимо учитывать гораздо больше нюансов, чем при оценивании экзамена или измерении веса респондентов. Результаты социологического опроса во многом зависят от правильности формулировки задаваемых вопросов. Рассмотрим пример, который на первый взгляд кажется довольно простым: какой процент американцев поддерживает смертную казнь? Как следует из названия этой главы, это заведомое большинство американцев. Согласно опросу, проведенному Институтом Гэллапа, начиная с 2002 года свыше 60% американцев ежегодно заявляют, что поддерживают применение смертной казни в отношении лиц, осужденных за убийство. Процент американцев, выступающих за смертную казнь, колеблется в относительно узком диапазоне, от высоких 70% в 2003 году до более низких 64% в отдельные годы. Эти данные позволяют сделать однозначный вывод: заведомое большинство американцев выступают за смертную казнь.
Или такой вывод слишком поспешен? Поддержка американцами смертной казни падает, когда в качестве альтернативы предлагается пожизненное тюремное заключение без права условно-досрочного освобождения. Опрос, проведенный Институтом Гэллапа в 2006 году, показал, что лишь 47% американцев считают смертную казнь справедливой карой за убийство, тогда как 48% высказываются за пожизненное тюремное заключение. Это не просто некий статистический парадокс, которым можно удивить гостей, пришедших к вам на вечеринку; фактически это уже означает отсутствие в стране большинства, поддерживающего применение смертной казни при наличии альтернативы в виде пожизненного тюремного заключения. Когда мы пытаемся выяснить отношение общества к той или иной проблеме, важнейшую роль играют формулировка вопроса и выбор языка.
Политики зачастую стараются сыграть на этом обстоятельстве, используя опросы общественного мнения и фокус-группы для тестирования «слов, которые приносят нужный результат». Например, избиратели в большей степени склонны поддерживать формулировку «снижение налогового бремени», чем «урезание налогов», несмотря на то что обе формулировки, по сути, описывают одно и то же действие. Аналогично, избирателей меньше волнует «изменение климата», чем «глобальное потепление», несмотря на то что глобальное потепление — лишь одна из форм изменения климата. Очевидно, политики пытаются манипулировать ответами избирателей путем использования «не нейтральных» слов. Если социологичекая организация стремится создать себе репутацию «честной», то есть выдающей результаты, заслуживающие доверия, она должна отказаться от употребления языка, способного повлиять на точность собираемой информации. Точно так же если по истечении какого-то времени предполагается сравнивать результаты опросов (например, как потребители оценивают нынешнее состояние экономики в сравнении с тем, как они оценивали его год назад), то вопросы, позволяющие получить требуемую информацию, в том и другом случае должны быть одинаковыми — или по крайней мере очень похожими.
Организации по исследованию общественного мнения (например Gallup Organization) зачастую проводят так называемое тестирование расщепленной выборки, когда разные варианты одного и того же вопроса тестируются на разных выборках, чтобы оценить, как незначительные изменения в формулировке вопроса влияют на ответы респондентов. Для таких экспертов, как Фрэнк Ньюпор из Gallup Organization, ответы буквально на каждый вопрос несут в себе значимую информацию, даже когда они кажутся несовместимыми. Тот факт, что отношение американцев к смертной казни резко меняется, когда в качестве альтернативы предлагается пожизненное тюремное заключение без права условно-досрочного освобождения, свидетельствует о чем-то важном. По мнению Ньюпора, результаты любого опроса общественного мнения необходимо рассматривать в общем контексте. Никакой отдельно взятый вопрос или опрос не в состоянии охватить всей глубины настроений общества, когда речь идет о какой-либо сложной проблеме.
Говорят ли респонденты правду? Опрос общественного мнения, как и знакомство в интернете, предполагает некоторое «пространство для маневра». Нам известно, что люди не всегда говорят правду, особенно когда им приходится отвечать на разного рода затруднительные и щекотливые вопросы. Респонденты могут завышать свой доход или преувеличивать свои возможности, когда у них спрашивают, например, о том, сколько раз в месяц они занимаются сексом. Они могут сообщить, что пойдут голосовать, хотя на самом деле предпочтут какой-то другой вид досуга. Они могут бояться выражать непопулярную или социально неприемлемую точку зрения. Именно по этим причинам даже идеально продуманный и организованный опрос зависит от того, насколько правдивы ответы респондентов.
При проведении опросов, касающихся выборов, очень важно заранее отсортировать тех, кто не придет на избирательные участки, от тех, кто намерен голосовать. (Если наша цель — определить вероятного победителя выборов, то какое нам дело до мнения тех, кто не собирается его избирать?) Люди часто говорят, что примут участие в голосовании, только потому, что им кажется, будто именно такого ответа от них ждут. Результаты исследований, в ходе которых сравнивалось количество избирателей, фактически пришедших на избирательные участки, с количеством тех, кто обещал прийти, показали, что от одной четверти до трети респондентов, утверждавших, что будут участвовать в выборах, не голосовали. Один из способов минимизировать искажения, вносимые неправдивыми ответами, — выяснить, участвовал ли данный респондент в голосовании на прошлых или нескольких предыдущих выборах. Респонденты, регулярно игнорирующие выборы, скорее всего, не станут участвовать в них и в дальнейшем. Аналогично, если есть опасения, что респонденты не решатся дать социально неприемлемый ответ на поставленный вопрос (например выразить отрицательное отношение к какой-либо расовой или этнической группе), то можно попытаться его более тонко сформулировать (например спросить, «придерживаются ли такого мнения знакомые вам люди»).
Одним из самых щекотливых за все время стало исследование, проведенное Национальным центром исследования общественного мнения (National Opinion Research Center — NORC) при Чикагском университете. Полное название исследования было таким: «Социальная организация сексуальности: половая жизнь в Соединенных Штатах»; впрочем, довольно быстро за ним закрепилось более краткое название: «Исследование секса». Формальное описание исследования включало такие фразы: «организация моделей поведения, на которых строятся половые контакты» и «выбор сексуальных партнеров и сексуальное поведение на протяжении жизни». Я слишком упрощаю, говоря, что исследователи пытались задокументировать «кто, как, с кем и как часто». Целью данного исследования, результаты которого были опубликованы в 1995 году, было не просто просветить нас относительно сексуального поведения соседей (хотя об этом тоже шла речь), но и оценить, как сексуальное поведение американцев влияет на распространение ВИЧ/СПИД.
Если уж американцы не решаются признаться, что не будут голосовать, то можно только представить, насколько они горят желанием описывать свое сексуальное поведение, если под ним могут, в частности, подразумеваться какие-либо предосудительные действия (например супружеская неверность) или даже склонность к половым извращениям. В данном исследовании использовалась впечатляющая методология. Оно основывалось на собеседованиях с репрезентативной выборкой взрослого населения США, включающей 3342 человека. Каждое собеседование занимало примерно 90 минут. Почти 80% респондентов заполнили соответствующую анкету, что позволило авторам исследования сделать вывод о том, что его результаты достаточно точно отражают сексуальное поведение американцев в целом (по крайней мере, в 1995 году).
Поскольку вы уже одолели большую часть книги и, в частности, главу, посвященную методологии проведения опросов общественного мнения, вы имеете право вкратце ознакомиться с выводами авторов «Исследования секса» (должен заранее вас разочаровать: ничего особенно шокирующего в них нет). Как заметил один из обозревателей, «секс занимает в жизни американцев гораздо меньше места, чем можно было бы предположить».
- Люди, как правило, занимаются сексом с теми, кто им близок по тем или иным признакам. Девяносто процентов пар относятся к одной и той же расе, религии, социальному классу и возрастной группе.
- Типичный респондент занимался сексом «пару-тройку раз в месяц» (правда, разброс по этому показателю весьма значителен). Количество сексуальных партнеров после достижения восемнадцатилетнего возраста колеблется от нуля до 1000 (и более).
- Примерно 5% мужчин и 4% женщин сообщили о том или ином числе сексуальных контактов с партнерами своего пола.
- У 80% респондентов в предыдущем году был либо один, либо ни одного сексуального партнера.
- Респонденты, имеющие одного сексуального партнера, оказались более счастливы по сравнению с теми, у кого вообще не было сексуального партнера или у кого их было много.
- Четверть женатых мужчин и 10% замужних женщин сообщали о наличии у них внебрачных половых связей.
- Большинство людей занимаются «этим» по старинке: вагинальный половой акт оказался самым привлекательным способом половых контактов для мужчин и женщин.
В одном из обзоров «Исследования секса» было высказано простое, но важное критическое замечание, что точность этого опроса отражает действительные сексуальные практики взрослого населения Соединенных Штатов и «предполагает, что респонденты являются частью населения, от которого эти ответы были получены, и что эти люди честно отвечали на поставленные вопросы». Данное высказывание также может служить выводом для всей этой главы. На первый взгляд, самым подозрительным в любом опросе может показаться то, что мнения столь небольшого числа людей способны отражать мнения населения всей страны. Но в этом-то как раз ничего удивительного или подозрительного нет. Один из самых фундаментальных статистических принципов заключается в том, что надлежащим образом сформированная выборка способна точно отражать совокупность, из которой она извлечена. Реальных проблем проведения опросов общественного мнения две: 1) определение правильной выборки и выход на нее и 2) получение информации от этой репрезентативной группы таким образом, чтобы она точно отражала мнения ее членов.

