11. Масштабирование микросервисов
Когда работаешь с изящными небольшими примерами форматом с книжную страницу, все кажется простым. Но реальный мир намного сложнее. Что будет, когда наши архитектуры микросервисов станут расширяться и превращаться из простых и скромных в нечто более сложное? Что будет, когда нам придется справляться со сбоями нескольких отдельных сервисов или управлять сотнями сервисов? Какие схемы нужно будет скопировать, когда микросервисов у вас станет больше, чем людей? Давайте все это выясним.
Сбои могут происходить везде
Мы понимаем, что нештатных ситуаций не избежать. Может отказать жесткий диск. Может дать сбой наша программа. И все, кто читал об ошибках, происходящих при распределенном вычислении, могут сказать о том, что знают о ненадежности сети. Мы можем приложить максимум усилий, пытаясь ограничить число сбоев, но при определенном масштабе сбои становятся неизбежными. Жесткие диски, к примеру, сейчас надежнее, чем когда-либо прежде, но временами и они выходят из строя. Чем больше у вас жестких дисков, тем выше вероятность отказа для отдельной стойки; при расширении масштаба отказ становится статистически неизбежен.
Даже тем из нас, кто не собирается слишком сильно расширять свою систему, все же стоит учитывать возможность сбоев. Если мы, к примеру, можем изящно обрабатывать сбои сервиса, то у нас получится и обновлять службу на месте, поскольку иметь дело с запланированными отключениями намного проще, чем с незапланированными.
Мы также сможем тратить немного меньше времени на попытки остановить неизбежное и уделять немного больше времени на то, чтобы справиться с ними как можно изящнее. Меня удивляет, что немалое количество организаций тратят силы и средства в первую очередь на попытки предотвращения сбоев и значительно меньше усилий направляют на упрощение восстановления после них.
Предположение о том, что все может дать сбой и неизбежно его даст, заставит изменить представление о том, как решать проблемы.
Я видел пример такого мышления, когда много лет назад был в кампусе Google. В приемной одного из зданий в Маунтин-вью в качестве своего рода экспозиции стояла старая стойка с машинами. И там я кое-что заприметил. Эти серверы были без кожухов — голые материнские платы, вставленные в стойку. Но мне бросилось в глаза то, что жесткие диски были смонтированы на липучках. Я спросил одного из сотрудников Google о том, почему так сделано. Он ответил, что жесткие диски настолько часто выходят из строя, что им не захотелось их прикручивать. Их просто вытаскивали, бросали в мусорное ведро и крепили на липучке новый диск.
Итак, позвольте повторить: при расширении, даже если будут приобретены самый лучший комплект, самое дорогое оборудование, избежать того, что что-то может дать сбой и сделает это, просто невозможно. Поэтому нужно предполагать, что сбой может произойти. Если это обстоятельство учитывать во всем, что вы создаете, и планировать сбои, можно будет пойти на различные компромиссы. Если известно, что система сможет справиться с тем фактом, что сервер может дать сбой и даст его, то зачем беспокоиться и сильно тратиться на все это? Почему бы не воспользоваться простой материнской платой с самыми дешевыми компонентами (и какими-нибудь липучками), как это было сделано в Google, не слишком переживая за стойкость отдельного узла?
Слишком много — это сколько?
Тема межфункциональных требований уже рассматривалась в главе 7. Представление о межфункциональных требованиях формируется из рассмотрения таких аспектов, как живучесть данных, доступность сервисов, пропускная способность и приемлемое время отклика сервисов. Многие технологии, упоминаемые в этой и других главах, имеют отношение к подходам, позволяющим реализовать эти требования, но о том, какими конкретно могут быть эти требования, знаете только вы.
Обладание автоматически масштабируемой системой, способной реагировать на возросшую нагрузку или отказ отдельных узлов, может быть фантастическим результатом, но окажется избыточным для системы создания отчетов, которую нужно запускать только дважды в месяц и для которой вполне приемлемо пару дней находиться в простое. Аналогично этому отработка способов сине-зеленых развертываний для ликвидации простоев сервиса может иметь смысл для системы электронной торговли, но для корпоративной базы знаний, доступной только во внутренней сети организации (в интранете), будет, наверное, излишней.
Задать количество приемлемых отказов или допустимую скорость системы можно на основе требований, предъявляемых пользователями данной системы. Это поможет вам понять, какие технологии разумнее всего будет применить. Тем не менее пользователи не всегда смогут сформулировать конкретные требования. Следовательно, чтобы получить правильную информацию и помочь им понять, каковы будут относительные затраты на предоставление различных уровней услуг, нужно задавать вопросы.
Как уже упоминалось, межфункциональные требования от сервиса к сервису могут отличаться друг от друга, но мне хотелось бы предложить определить некоторые универсальные межфункциональные требования, а затем переопределить их для конкретных вариантов использования. Когда рассматриваются вопросы о необходимости и способах масштабирования системы, позволяющего лучше справиться с нагрузкой или сбоями, постарайтесь сначала разобраться со следующими требованиями.
• Время отклика/задержка. Сколько времени должно тратиться на ту или иную операцию? Здесь может пригодиться измерение данного показателя в ходе работы различного количества пользователей с целью определения степени влияния возрастающей нагрузки на время отклика. Из-за характерных особенностей сетей неизбежны выпадения, поэтому может пригодиться задание целей для заданной процентили отслеживаемых ответов. Цель должна также включать количество параллельных подключений (пользователей), с которым, как ожидается, сможет справиться ваша программа. Следовательно, вы можете сказать: «Мы ожидаем, что у сайта значение 90-й процентили времени отклика будет порядка 2 секунд при обслуживании 200 параллельных подключений в секунду».
• Доступность. Ожидается ли падение сервиса? Считается ли, что сервис работает в режиме 24/7? Некоторым при оценке доступности нравится смотреть на периоды допустимого вынужденного простоя, но насколько это практично для тех, кто вызывает ваш сервис? Я должен либо полагаться, либо не полагаться на доступность сервиса. Фактически оценка периодов вынужденного простоя более полезна с точки зрения исторической отчетности.
• Живучесть данных. Каков приемлемый объем потери данных? Каков обязательный срок хранения данных? Скорее всего, для разных случаев можно будет дать разные ответы на эти вопросы. Например, можно выбрать вариант годичного хранения журналов регистрации пользовательских сеансов или с целью экономии дискового пространства — менее продолжительный срок, но записи о финансовых транзакциях может потребоваться хранить в течение многих лет.
Когда требования будут определены, вам понадобится способ постоянной систематической оценки их соблюдения. Можно, к примеру, прийти к решению о проведении тестов производительности, чтобы убедиться, что в этом смысле система отвечает приемлемым целям, нужно также обеспечить отслеживание соответствующей статистики и в производственном режиме работы!
Снижение уровня функциональных возможностей
Важной частью создания отказоустойчивой системы, особенно когда функциональные возможности распределяются среди нескольких микросервисов, которые могут находиться как в рабочем, так и в нерабочем состоянии, является обеспечение ее способности безопасно снижать уровень функциональности. Представим себе стандартную веб-страницу на нашем сайте электронной торговли. Чтобы собрать вместе различные части этого сайта, требуется участие в работе нескольких микросервисов. Один микросервис может выводить на экран подробности о предлагаемом к продаже альбоме, другой — показывать цену и уровень запасов товара. И мы, наверное, будем показывать также содержимое покупательской корзины, чем может заниматься еще один микросервис. Если при отказе одного из этих сервисов станет недоступной вся страница, то мы, вероятно, создали систему менее устойчивую, чем та, которая требует доступности только одного сервиса.
Нам нужно понять, каково влияние каждого отказа, и выработать способы надлежащего снижения уровня функциональности. Если недоступен сервис покупательской корзины, это, наверное, будет весьма неприятно, но мы по-прежнему сможем показывать веб-страницу с перечнем товаров. Возможно, мы просто скроем покупательскую корзину или выведем вместо нее значок с надписью «Скоро вернусь!».
При работе с единым монолитным приложением нам не приходится принимать множество решений. Здоровье системы зависит от работы двоичного кода. Но при использовании архитектуры микросервисов нужно рассматривать намного более тонкие ситуации. Зачастую правильные действия в любой ситуации не связаны с принятием технического решения. Нам может быть известно, что технически можно сделать при отказе корзины, но пока мы не сможем осмыслить бизнес-контекст, мы не поймем, какое действие нужно предпринять. Возможно, мы закроем весь сайт, позволим людям просматривать каталог товаров или заменим ту часть пользовательского интерфейса, в которой содержатся элементы управления корзиной, номером телефона, по которому можно сделать заказ. Но для каждого показываемого клиенту интерфейса, в котором используются несколько микросервисов, или для каждого микросервиса, зависящего от нескольких нижестоящих, сотрудничающих с ним микросервисов, следует задаться вопросом: «Что произойдет при отказе?» — и знать, что нужно будет делать.
Критический взгляд на каждую из возможностей в понятиях межфункциональных требований позволит намного лучше сориентироваться в определении необходимых действий. Теперь рассмотрим, что можно сделать с технической точки зрения, чтобы при возникновении сбоя мы могли с ним успешно справиться.
Архитектурные меры безопасности
Существует несколько схем, которые я в совокупности называю архитектурными мерами безопасности и которые при возникновении нештатных ситуаций могут использоваться, чтобы предотвращать появление раздражающих, распространяющихся за пределы сервиса эффектов. Вам важно усвоить их положения и строго придерживаться стандартизации в системе, чтобы гарантировать, что ни один ее нерадивый компонент не сможет прямо у вас на глазах вызвать всеобщее обрушение. Вскоре мы посмотрим, какие основные меры безопасности заслуживают внимания, но перед этим я хочу поделиться небольшой историей, чтобы очертить круг возможных нештатных ситуаций.
Я был техническим руководителем проекта по созданию сайта классифицированной онлайн-рекламы. Сайт обслуживал довольно большие объемы информации и приносил довольно высокий доход. Наше основное приложение занималось выводом на экран классифицированных рекламных объявлений, а также служило прокси-сервером вызовов, осуществляемых по адресам других сервисов, предоставляющих различные виды продукции (рис. 11.1).
Фактически это пример приложения-душителя, где новая система перехватывает вызовы, совершаемые в адрес ранее существовавших приложений, и постепенно полностью заменяет собой эти приложения. В рамках этого проекта мы уже были на полпути к списанию прежних приложений. Мы только что перешли к использованию самых крупных объемов и самых прибыльных продуктов, но многие рекламные объявления по-прежнему обслуживались целым рядом прежних приложений. С точки зрения как количества поисковых запросов, так и дохода от этих приложений быстро избавиться от них не представлялось возможным.
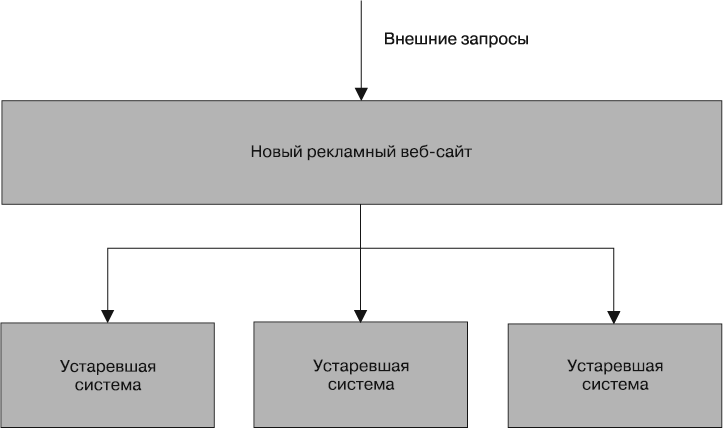
Рис. 11.1. Сайт классифицированных рекламных объявлений, на котором происходит постепенное избавление от устаревших приложений
Какое-то время наша система демонстрировала высокую живучесть и примерное поведение, справляясь с незначительными нагрузками. Со временем в пиковые моменты нам пришлось обрабатывать 6000–7000 запросов в секунду, и несмотря на то, что большинство запросов интенсивно кэшировалось реверсными прокси-серверами, находящимися перед серверами нашего приложения, поисковые запросы товаров, являющиеся наиболее важным аспектом сайта, в большинстве своем в кэше отсутствовали и требовали обслуживания по полному серверному циклу.
Однажды утром, как раз перед достижением ежедневной пиковой нагрузки, что происходило во время обеденного перерыва, система стала замедляться, а затем постепенно выходить из строя. В новом основном приложении у нас было несколько уровней мониторинга, достаточных для того, чтобы сообщить о достижении каждым узлом приложения 100%-й пиковой нагрузки на центральный процессор, превышающей нормальные уровни даже для пиковых ситуаций. Вскоре обрушилась вся система.
Нам удалось выяснить причину произошедшего и восстановить работу сайта. Оказалось, что одна из нижестоящих рекламных систем, самая старая и хуже всех поддерживаемая, начала выдавать ответы очень медленно. Подобное поведение является одним из наихудших режимов сбоя, с которым можно столкнуться. Отсутствие системы определяется довольно быстро. А когда она просто замедляется, то прежде, чем среагировать на сбой, приходится некоторое время занимать выжидательную позицию. Но какой бы ни была причина неполадок, мы создали систему, уязвимую для каскадного сбоя. Практически не контролируемый нами нижестоящий сервис способен был обрушить всю систему.
Пока одна команда изучала проблемы, возникшие с нижестоящей системой, все остальные приступили к выявлению причин возникновения нештатной ситуации в нашем приложении. Были обнаружены сразу несколько проблем. Для обслуживания нижестоящих подключений мы использовали пул HTTP-соединений. Потоки этого пула имели показатели времени ожидания, настроенные на время ожидания HTTP-вызова, направляемого в адрес нижестоящей системы, что было вполне приемлемо. Проблема заключалась в том, что всем исполнителям при замедлении нижестоящей системы приходилось ожидать истечения лимита времени. Пока они ждали, в пул приходили новые запросы, требовавшие исполнительных потоков. Из-за отсутствия доступных исполнителей эти запросы зависали. Оказалось, что у библиотеки пула соединений, которую мы использовали, была настройка лимита времени ожидания исполнителей, но по умолчанию она была отключена! Это вызвало огромное скопление заблокированных потоков. У нашего приложения в любой момент времени обычно было 40 параллельных соединений. В течение пяти минут возникшая ситуация привела к резкому возрастанию количества соединений до 800, что и обрушило систему.
Хуже того, нижестоящий сервис, с которым шел диалог, обеспечивал менее 5 % функциональных возможностей, используемых нашей клиентской базой, а доля доходов от него была еще меньше. Разобравшись в ситуации, мы пришли к стойкому убеждению, что с системами, просто замедляющими свою работу, справиться намного сложнее, чем с системами, которые быстро выходят из строя. Замедление в распределенных системах имеет убийственный эффект.
Даже при наличии правильно выставленных в пуле лимитов времени у нас для всех исходящих запросов был общий единственный пул HTTP-соединений. Это означало, что один медленный сервис мог в одиночку исчерпать количество доступных исполнителей, даже если все остальные продолжали работать в штатном режиме. В конце концов стало понятно, что рассматриваемый нижестоящий сервис дал сбой, но мы продолжали отправлять трафик в его направлении. В данной ситуации это означало, что мы усугубили и без того плохое состояние дел, поскольку у нижестоящего сервиса все равно не было шансов на восстановление нормального режима работы. Во избежание повторения подобных случаев мы сделали три доработки: выставили правильные значения времени ожидания, реализовали переборки, чтобы отделить друг от друга различные пулы соединений, и создали предохранитель, исключающий отправку вызовов к нездоровой системе.
Антихрупкая организация
В своей книге «Антихрупкость» (Random House) Нассим Талеб (Nassim Taleb) рассказывал о таких вещах, как получение, как бы странно это ни звучало, пользы от сбоев и нештатной работы. Ариэль Цейтлин (Ariel Tseitlin) применительно к тому, как работает Netflix, воспользовался этой концепцией для выработки понятия «антихрупкая организация».
Масштабы работы Netflix хорошо известны, как и тот факт, что Netflix целиком полагается на AWS-инфраструктуру. Эти два фактора означают, что данное понятие должно включать в себя также возможность возникновения сбоя. Компания Netflix выходит за рамки этого подхода, фактически провоцируя сбой, чтобы убедиться в том, что система к нему устойчива.
Некоторые организации были бы рады устроить испытательные дни, в которые сбой имитируется выключаемыми системами и наблюдением за реакцией различных команд. Когда я работал в Google, это весьма часто практиковалось для различных систем, и я, конечно же, думал, что многие организации могут извлечь пользу из регулярного выполнения подобных упражнений. Google выходит за рамки простых тестов для имитации сбоя сервера и как часть своих ежегодных упражнений DiRT (Disaster Recovery Test — тестирование на восстановление работоспособности после аварии) имитирует широкомасштабные бедствия наподобие землетрясений. Компания Netflix также практикует более агрессивный подход, создавая программы, вызывающие сбой, и ежедневно запуская их в производственном режиме.
Наиболее известная программа называется Chaos Monkey, она занимается тем, что в течение определенного времени выключает случайно выбранные машины. Сведения о том, что такое может произойти и реально происходит в производственном режиме, означают, что разработчики, создавшие системы, должны быть к этому по-настоящему готовы. Chaos Monkey является лишь одной из составляющих используемого в Netflix комплекса роботов имитации сбоев под названием Simian Army. Программа Chaos Gorilla используется для вывода из строя центра доступности (эквивалента дата-центра в AWS), а программа Latency Monkey имитирует медленную работу сетевого соединения между машинами. Компания Netflix сделала эти инструментальные средства доступными под лицензией открытого кода. Для многих завершающим тестом надежности системы может стать выпуск на волю собственной обезьяньей армии (то есть Simian Army) в своей производственной инфраструктуре.
Включение и провоцирование сбоев посредством программных средств и создание систем, способных справиться с ними, — это всего лишь часть того, что делает Netflix. В этой компании понимают важность извлечения уроков из происходящих сбоев и привития культуры терпимости к допускаемым ошибкам. Затем к извлечению уроков привлекают разработчиков, поскольку каждый разработчик также отвечает за сопровождение своих сервисов, работающих в производственном режиме.
Искусственно вызывая сбои и создавая условия для их появления, компания Netflix обеспечивает более успешное масштабирование своих систем и лучше реагирует на нужды своих клиентов.
Принимать экстремальные меры по примеру Google или Netflix нужно не всем, при этом важно понять, что для работы с распределенными системами нужен иной взгляд на вещи. Сбои неизбежны. То, что ваша система в данный момент разбросана по нескольким машинам (которые могут и будут сбоить) и по сети (которая обязательно проявит свою ненадежность), может как минимум повысить степень уязвимости системы. Следовательно, независимо от того, собираетесь ли вы предоставлять сервис в таких же масштабах, как Google или Netflix, готовность к сбоям, характерным для более распределенных архитектур, играет весьма важную роль. Итак, что же нам нужно сделать, чтобы справиться со сбоями в системах?
Настройки времени ожидания
Настройки времени ожидания очень легко упустить из виду, но для правильной работы с нижестоящими системами они играют весьма важную роль. Долго ли мне нужно ждать, пока я не смогу считать нижестоящую систему фактически отказавшей?
Если слишком долго ждать решения о том, что вызов не удался, можно замедлить работу всей системы. Если сделать время ожидания слишком маленьким, можно будет посчитать потенциально работоспособный вызов неудавшимся. Если полностью отказаться от времени ожидания, то обрушившаяся нижестоящая система может «подвесить» всю систему.
Настройки времени ожидания нужно иметь для всех вызовов, адресуемых за пределы процесса, и для всех таких вызовов нужно выбирать время ожидания по умолчанию. Зарегистрируйте истечение времени ожидания, найдите причину и соответствующим образом скорректируйте значение времени ожидания.
Предохранители
У вас дома предохранители существуют для защиты электрических устройств от скачков напряжения. Если произойдет такой скачок, предохранитель сработает, защищая дорогостоящие домашние устройства. Предохранитель можно выключить вручную, чтобы отключить электричество в какой-нибудь части дома, что позволит безопасно работать с электропроводкой. В книге Майкла Нигарда (Michael Nygard) Release It! (Pragmatic Programmers) показано, как та же идея может творить чудеса, когда используется в качестве защитного механизма для наших программных средств.
Рассмотрим историю, которой я только что поделился. Нижестоящее устаревшее рекламное приложение реагировало очень медленно, пока в конце концов не вернуло ошибку. Даже при правильной настройке времени ожидания до получения ошибки мы томились бы в долгом ожидании. А затем повторили бы попытку при следующем поступлении запроса и снова ждали. Плохо, конечно, что нижестоящий сервис сбоит, но ведь он при этом заставляет и нас замедлить работу.
Предохранитель же срабатывает после конкретного количества безответных запросов к нижестоящему сервису. И пока он находится в этом состоянии, все последующие запросы быстро получают отказ. По истечении определенного времени клиент отправляет несколько запросов, чтобы определить, не восстановился ли нижестоящий сервис, и при получении достаточного количества нормально обслуженных запросов восстанавливает сработавший предохранитель. Обзор подобного процесса показан на рис. 11.2.
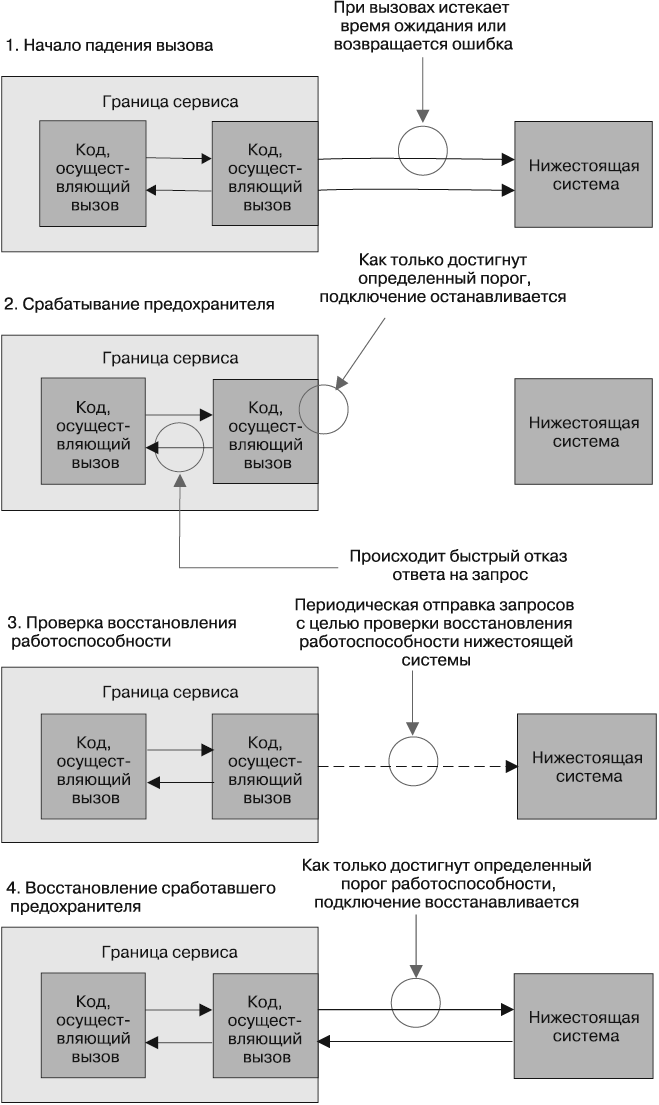
Рис. 11.2. Обзор предохранителей
Конкретная реализация предохранителя зависит от значимости получившего отказ запроса, но когда мне приходилось создавать его для HTTP-соединений, за сбой принимались либо истечение времени ожидания, либо возвращаемый код из серии 5хх HTTP. Таким образом, когда нижестоящий ресурс отказывал, или истекало время ожидания, или возвращались коды ошибок, после достижения определенного порога мы автоматически прекращали отправление трафика и быстро констатировали сбой. И в случае нормализации обстановки могли осуществлять повторный запуск в автоматическом режиме.
Установка правильных значений может вызвать затруднения. Вам ведь не хочется, чтобы предохранитель срабатывал слишком быстро, и в то же время не хочется слишком долго ждать его срабатывания. Более того, перед возобновлением отправки трафика хочется убедиться в том, что нижестоящий сервис восстановил нормальную работоспособность. Как и при выборе значений времени ожидания, я устанавливаю разумные параметры по умолчанию и использую их повсеместно, а затем изменяю для каждого конкретного случая.
При срабатывании предохранителя у вас есть выбор из нескольких вариантов. Один из них предполагает выстраивание запросов в очередь с последующей повторной попыткой их отправки. Для некоторых сценариев этот вариант вполне приемлем, особенно если вы выполняете работу, являющуюся частью асинхронного задания. Но если этот вызов был сделан как часть цепочки синхронных вызовов, то лучше будет, наверное, как можно скорее констатировать сбой. Это может означать распространение ошибки вверх по цепочке вызовов или более тонкое снижение уровня функциональности.
Располагая таким механизмом (аналогичным домашним предохранителям), мы можем воспользоваться им вручную, чтобы обезопасить свою работу. Например, если в ходе обычного обслуживания системы нужно выключить микросервис, можно вручную перевести в сработавшее положение предохранители зависимых систем, чтобы они смогли быстро констатировать сбой, пока микросервис находится в отключенном состоянии. После его возвращения в рабочее состояние мы можем восстановить сработавшие предохранители и все должно вернуться в нормальное рабочее состояние.
Переборки
В книге Release It! Нигард дает описание концепции переборок, применяемых в качестве способа изоляции от сбоев. В судостроении переборка является составной частью корабля, которую можно закрыть для защиты помещений корабля от поступления забортной воды. Если корабль дает течь, можно закрыть двери переборки. Часть корабля затопится водой, но все остальное будет не тронуто.
В понятиях архитектуры программ можно рассматривать множество различных переборок.
Возвращаясь к моему личному опыту, мы упустили шанс реализации переборки. Нам нужно было для каждого нижестоящего соединения использовать различные пулы соединений. Таким образом, при исчерпании одного пула соединений это не влияло бы на остальные соединения (рис. 11.3). Существовала бы гарантия того, что замедление работы нижестоящего сервиса повлияет только на один пул соединения, позволяя нормально обрабатывать другие вызовы.
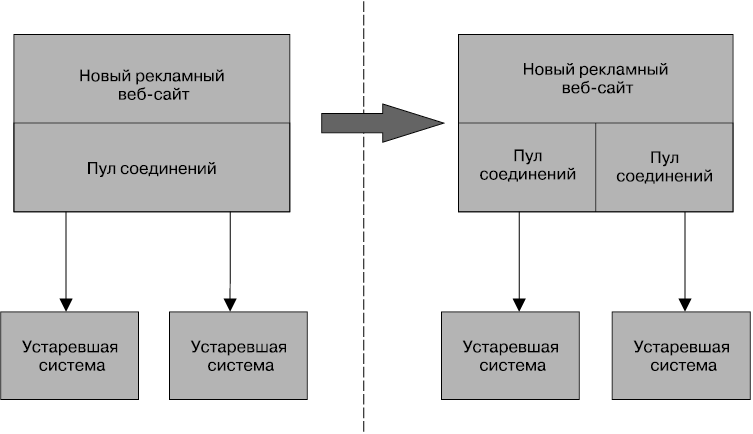
Рис. 11.3. Использование по одному пулу соединения для каждого нижестоящего сервиса с целью создания переборок
Еще одним способом реализации переборок может стать разделение проблем. Разделением функций на отдельные микросервисы можно уменьшить влияние сбоя в одной области на работу других областей.
Внимательно изучите все стороны вашей системы, от которых можно ожидать сбоя, как внутри микросервисов, так и между ними. Установлены ли между ними переборки? Советую начать с разделения пулов соединений, выделяя отдельный пул для каждого нижестоящего соединения. Но можно пойти и дальше и рассмотреть также возможность применения предохранителей.
Можно рассмотреть применение предохранителей в качестве автоматического механизма герметизации перегородки, то есть не только в качестве защиты потребителя от проблем, возникших в нижестоящей системе, но и в качестве потенциальной защиты нижестоящего сервиса от излишних вызовов, способных неблагоприятно воздействовать на него. Учитывая опасность каскадного сбоя, я бы порекомендовал обязательно применять предохранители для всех синхронных вызовов в адрес нижестоящих систем. Но вам не обязательно создавать собственные предохранители. У Netflix есть библиотека Hystrix с абстракцией предохранителя на JVM, поставляемой с эффективной системой мониторинга, есть и другие реализации для различных технологических стеков, например Polly для .NET или миксин circuit_breaker для Ruby.
Во многих отношениях переборки являются наиболее важной из этих трех схем. Настройки времени ожидания и предохранители помогают вам высвободить ресурсы при их истощении, а переборки в первую очередь могут обеспечить невозможность их истощения. Библиотека Hystrix, к примеру, позволяет реализовать переборки, которые фактически при определенных условиях отклоняют запросы, обеспечивая тем самым дальнейшее истощение ресурсов; этот прием называется сбросом нагрузки. Иногда отклонение запроса является наилучшим способом уберечь важную систему от перегрузки и превращения в узкое место для множества вышестоящих сервисов.
Изолированность
Чем больше один сервис зависит от задействования других сервисов, тем больше благополучная работа одного сервиса влияет на выполнение задач другими сервисами. Использование технологий интеграции, позволяющих переводить нижестоящий сервер в режим автономной работы, может снизить вероятность влияния простоев, как плановых, так и внеплановых сбоев на вышестоящие сервисы.
Повышение изолированности сервисов друг от друга дает еще одно преимущество, заключающееся в существенно меньших потребностях в координации усилий между владельцами сервисов. Чем меньше эти потребности, тем большей автономностью будут обладать команды и тем больше возможность свободно распоряжаться своими сервисами и развивать их.
Идемпотентность
При проведении идемпотентных операций результат после первого применения не меняется, даже если операция последовательно выполняется еще несколько раз. Если операции обладают идемпотентностью, мы можем повторять вызов несколько раз без негативного воздействия. Это нам очень пригодится, если необходимо повторно воспроизвести сообщения, когда нет уверенности, что они обработаны. Это является весьма распространенным способом восстановления после ошибок.
Рассмотрим простой вызов с целью добавления баллов в результате размещения заказа одним из наших клиентов. Мы можем сделать вызов с полезной нагрузкой, показанной в примере 11.1.
Пример 11.1. Зачисление баллов на счет
<credit>
<amount>100</amount>
<forAccount>1234</account>
</credit>
Если этот вызов будет получен несколько раз, мы столько же раз зачислим 100 баллов. Получается, этот вызов не является идемпотентным. Но как показано в примере 11.2, при наличии дополнительной информации можно позволить банку бонусных баллов сделать этот вызов идемпотентным.
Пример 11.2. Добавление информации к зачислению баллов с целью придания идемпотентности этой операции
<credit>
<amount>100</amount>
<forAccount>1234</account>
<reason>
<forPurchase>4567</forPurchase>
</reason>
</credit>
Теперь мы знаем, что это зачисление относится к конкретному заказу под номером 4567. Учитывая, что получить бонус за конкретный заказ можно только единожды, мы можем применить зачисление еще раз без увеличения общего количества баллов.
Этот механизм работает и при организации сотрудничества на основе событий и может быть особенно полезен при наличии нескольких экземпляров одного и того же вида сервиса, подписанного на события. Даже при сохранении сведений о том, какие события были обработаны, при некоторых формах доставки асинхронных сообщений могут создаваться небольшие окна, в которых одно и то же сообщение может попадать в поле зрения двух исполнителей. Обрабатывая события идемпотентным образом, мы гарантируем, что они не станут источником ненужных проблем.
Некоторые недопонимают эту концепцию, полагая, что последующие вызовы с такими же параметрами не смогут оказывать какого-либо влияния, оставляя нас в интересном положении. Например, нам по-прежнему хотелось бы, чтобы вызов был получен нашими журналами. Нужно записать время отклика на вызов и собрать данные для мониторинга. Ключевым моментом здесь является то, что рассматриваемые бизнес-операции, которые мы считаем идемпотентными, не распространяются на полное состояние системы.
Некоторые HTTP-глаголы, например GET и PUT, определены в HTTP-спецификации в качестве идемпотентных, но, чтобы это произошло, сервис должен обрабатывать их идемпотентным образом. Если вы начнете отказывать им в идемпотентности, а вызывающая сторона будет уверена в безопасности их повторного применения, может возникнуть запутанная ситуация. Следует запомнить, что сам факт использования HTTP в качестве основного протокола еще не означает, что вы все получите, не прилагая дополнительных усилий!
Масштабирование
В основном масштабирование систем выполняется по двум причинам. Во-первых, для того, чтобы легче было справиться со сбоями: если мы переживаем за отказ какого-либо компонента, то помочь сможет наличие такого же дополнительного компонента, не так ли? Во-вторых, для повышения производительности, что позволяет либо справиться с более высокой нагрузкой, либо снизить время отклика, либо достичь обоих результатов. Рассмотрим ряд наиболее распространенных технологий масштабирования, которыми можно будет воспользоваться, и подумаем об их применении к архитектурам микросервисов.
Наращивание мощностей
От наращивания мощностей некоторые операции могут только выиграть. Более объемный корпус с более быстрым центральным процессором и более эффективной подсистемой ввода-вывода зачастую способны уменьшить задержки и повысить пропускную способность, позволяя выполнять больший объем работ за меньшее время. Но такая разновидность масштабирования, которую часто называют вертикальным масштабированием, может быть слишком затратной: иногда один большой сервер может стоить намного больше, чем два небольших сервера сопоставимой мощности, особенно когда вы начнете получать по-настоящему большие машины. Иногда само программное обеспечение не способно освоить доступные дополнительные ресурсы. Более крупные машины зачастую предоставляют в наше распоряжение больше ядер центральных процессоров, но подчас у нас нет программных средств, позволяющих использовать такое преимущество. Еще одна проблема заключается в том, что такая разновидность масштабирования не в состоянии внести весомый вклад в устойчивость сервера, если у нас только одна машина! Несмотря на это, такой подход может принести быстрый выигрыш, особенно если вы используете провайдер виртуализации, позволяющий легко и просто изменять объемы ресурсов виртуальных машин.
Разделение рабочих нагрузок
Как отмечалось в главе 6, наличие единственного микросервиса на каждом хосте, безусловно, предпочтительнее модели, предусматривающей наличие на хосте сразу нескольких микросервисов. Но изначально с целью снижения стоимости оборудования или упрощения управления хостом (хотя это спорная причина) многие принимают решение о сосуществовании нескольких микросервисов на одной физической машине. Поскольку микросервисы запускаются в независимых процессах, обменивающихся данными по сети, задача последующего их перемещения на собственные хосты с целью повышения пропускной способности и масштабирования не представляет особой сложности. Такое перемещение может повысить устойчивость системы, поскольку сбой одного хоста повлияет на ограниченное количество микросервисов.
Разумеется, мы могли бы воспользоваться необходимостью расширения масштаба для разбиения существующих микросервисов на части, чтобы успешнее справляться с нагрузкой. В качестве упрощенного примера представим, что наш сервис счетов позволяет создавать индивидуальные финансовые счета клиентов и управлять ими, а также выставляет API-интерфейс для запуска запросов с целью создания отчетов. Такая возможность запуска запросов существенно нагружает систему. Объем запросов считается некритическим и не требует сохранения поступающего за день потока запросов. Но возможность управления финансовыми записями является критической для наших пользователей, и мы не можем позволить, чтобы она функционировала со сбоями. Разделяя эти две возможности на отдельные сервисы, мы уменьшаем нагрузку на сервис важных счетов и вводим новый сервис отчета по счетам, спроектированный с учетом не только возможностей обработки запросов (возможно, с использованием технологий, рассмотренных в главе 4), но и того, что некритическую систему не обязательно развертывать в отказоустойчивом режиме, как того требует основной сервис счетов.
Распределение риска
Один из способов масштабирования с целью повышения отказоустойчивости заключается в выдаче гарантий того, что все яйца не сложены в одну корзину. Простейшим примером может послужить обеспечение того, что вы не поместили на одном хосте сразу несколько сервисов, где сбой окажет влияние на работу сразу нескольких сервисов. Но рассмотрим значение такого понятия, как хост. В большинстве возможных нынче ситуаций хост фактически является виртуальным понятием. Тогда что, если все мои сервисы находятся на разных хостах, но все эти хосты фактически являются виртуальными, запущенными на одной и той же физической машине? Если машина даст сбой, я могу потерять сразу несколько сервисов. Для уменьшения вероятности этого некоторые платформы виртуализации дают гарантии распределения хоста по нескольким физическим машинам.
Для внешних платформ виртуализации существует распространенная практика размещения корневого раздела виртуальной машины в одной сети хранения данных (SAN). Если SAN-сеть даст сбой, это может привести к сбою всех связанных с ее помощью виртуальных машин. SAN-сети отличаются масштабностью, дороговизной и проектированием в расчете на бессбойную работу. Я сталкивался со сбоями больших и дорогостоящих SAN-сетей как минимум дважды за последние десять лет, и каждый раз это имело довольно серьезные последствия.
Еще одной распространенной разновидностью сокращения вероятности сбоев является гарантия того, что не все ваши сервисы запускаются на одной и той же стойке дата-центра, или того, что сервисы распределены по более чем одному дата-центру. Если вы имеете дело с основным поставщиком услуг, то важно знать о предложении и планировании им соответствующего соглашения об уровне предоставления услуг (SLA). Если для вас допустимо не более четырех часов сбоев в квартал, а хостинг-провайдер может гарантировать всего лишь не более восьми часов, то вам придется либо пересмотреть SLA, либо придумать альтернативное решение.
AWS, к примеру, имеет региональную форму распределения, которую можно рассматривать как отдельные облака. Каждый регион, в свою очередь, разбит на две и более зоны доступности (AZ). Эти зоны в AWS являются эквивалентом дата-центра. Важно, чтобы сервисы были распределены по нескольким зонам доступности, поскольку инфраструктура AWS не дает гарантий доступности отдельно взятого узла или даже всей зоны доступности. Для своих вычислительных услуг эта инфраструктура предлагает только 99,95 % безотказной работы за заданный месячный период во всем регионе, поэтому внутри отдельно взятого региона рабочую нагрузку следует распределить по нескольким доступным зонам. Некоторых такие условия не устраивают, и вместо этого они запускают свои сервисы, также распределяя их по нескольким регионам.
Конечно же, нужно отметить, что провайдеры, давая вам SLA-гарантии, будут стремиться ограничить свою ответственность! Если несоблюдение условий с их стороны будет стоить вам клиентов и больших денежных потерь, нужно внимательно изучить контракты на предмет компенсаций. Поэтому я настоятельно рекомендую оценить влияние несоблюдения поставщиком взятых перед вами обязательств и подумать, стоит ли иметь про запас какой-нибудь план Б (или В). Мне, к примеру, приходилось работать не с одним клиентом, у которого имелась хостинг-платформа аварийного восстановления, использующая услуги другого поставщика, что снижало уязвимость от ошибок одной компании.
Балансировка нагрузки
Когда сервису нужна отказоустойчивость, вам понадобятся способы обхода критических мест сбоев. Для типичного микросервиса, выставляющего синхронную конечную HTTP-точку, наиболее простым способом решения этой задачи (рис. 11.4) будет использование нескольких хостов с запущенными на них экземплярами микросервиса, находящимися за балансировщиком нагрузки. Потребители микросервиса не знают, связаны они с одним его экземпляром или с сотней таких экземпляров.
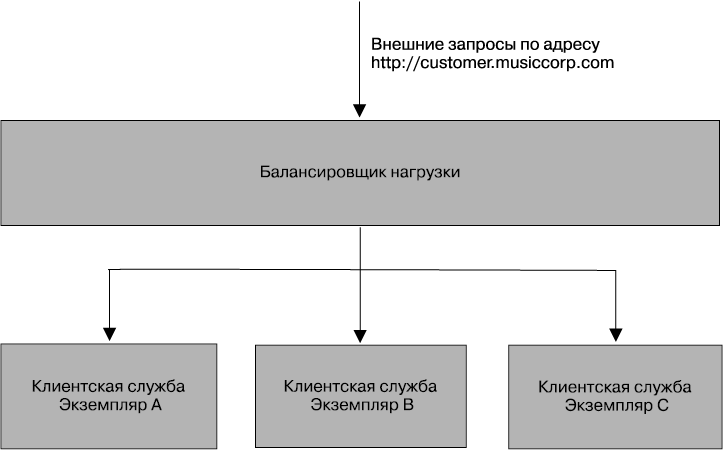
Рис. 11.4. Пример балансировки нагрузки с целью масштабирования количества экземпляров клиентского сервиса
Существуют балансировщики нагрузки всех форм и размеров, от больших и дорогих аппаратных приспособлений до балансировщиков на основе программных средств типа mod_proxy. У всех них общие основные возможности. Они распределяют поступающие к ним вызовы между несколькими экземплярами на основе определенного алгоритма, устраняя экземпляры, утратившие работоспособность, но не теряя при этом надежды на их возвращение при восстановлении нормального режима работы.
Некоторые балансировщики нагрузки предоставляют ряд полезных свойств. Одним из самых распространенных является возможность работы в качестве оконечного SSL-устройства, в котором входящие в балансировщик нагрузки HTTPS-соединения преобразуются в HTTP-соединения, в качестве которых они и попадают в сам экземпляр. Исторически издержки на управление SSL были довольно большими, и когда этот процесс берет на себя балансировщик нагрузки, он оказывает вам существенную услугу. В настоящее время это сильно упрощает настройки отдельных хостов, на которых запускаются экземпляры. Но, как говорилось в главе 9, смысл использования HTTPS заключается в обеспечении неуязвимости запросов от взлома злоумышленниками на маршруте их передачи, поэтому при использовании конечной точки SSL мы потенциально отчасти открываем свои данные. Снизить угрозу можно, поместив все экземпляры микросервисов в единую VLAN-сеть (рис. 11.5). VLAN является виртуальной локальной сетью, изолированной таким образом, что поступающие извне запросы могут пройти только через маршрутизатор, а в данном случае маршрутизатор является также балансировщиком нагрузки с возможностью выполнения роли конечной точки SSL. Единственная линия связи с микросервисами, идущая с внешней стороны VLAN-сети, использует протокол HTTPS, а внутри сети повсеместно применяется протокол HTTP.
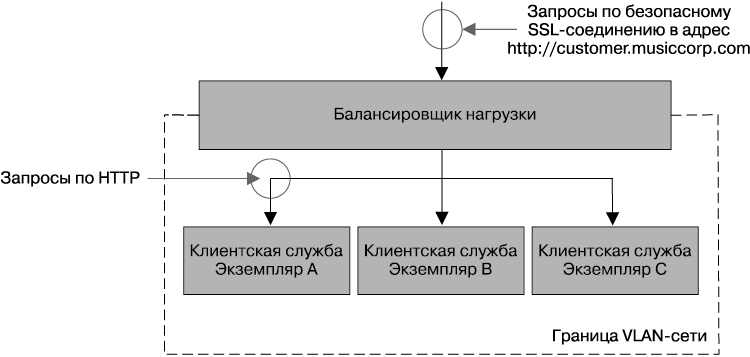
Рис. 11.5. Использование конечной точки HTTPS в балансировщике нагрузки с VLAN-сетью с целью повышения безопасности
AWS предоставляет балансировщики нагрузок с конечными точками HTTPS в форме ELB-балансировщиков (Elastic Load Balancer — гибкий балансировщик нагрузки), позволяющие для реализации VLAN-сети воспользоваться его безопасными группами или виртуальными закрытыми облаками (VPC). Такую же роль в качестве программного балансировщика нагрузки может сыграть программа вроде mod_proxy. У многих организаций имеются аппаратные балансировщики нагрузки, автоматизация которых может быть затруднена. При таких обстоятельствах я встану на защиту программных балансировщиков нагрузки, установленных за аппаратными балансировщиками, что даст командам свободу их перенастройки в соответствии с их запросами. Надо считаться с тем фактом, что аппаратные балансировщики нагрузки нередко выходят из строя, становясь единой точкой отказа! Независимо от избранного вами подхода при рассмотрении вопроса о конфигурации балансировщика нагрузки относитесь к ней так же, как относились к конфигурации вашего сервиса: обеспечьте ее сохранение в системе управления версиями и возможность автоматического применения.
Балансировщики нагрузки позволяют нам добавлять дополнительные экземпляры микросервисов незаметно для любых потребителей сервиса. Это дает нам более широкие возможности управления нагрузкой и в то же время уменьшает влияние сбоя на одном из хостов. Но у многих, если не у большинства микросервисов будут какие-нибудь постоянные хранилища данных, возможно, база данных, находящаяся на другой машине. При наличии нескольких экземпляров микросервисов на разных машинах, но только одного хоста с запущенным экземпляром базы данных мы обрекаем эту базу данных на роль единого источника сбоев. Схемы, позволяющие справиться с этой проблемой, будут рассмотрены чуть позже.
Системы на основе исполнителей
Применение балансировщиков не является единственным способом разделения нагрузки среди нескольких экземпляров сервиса и уменьшения их хрупкости. В зависимости от характера операций столь же эффективной может быть и система на основе исполнителей. Здесь вся коллекция экземпляров действует с некоторым общим отставанием в работах. Это может быть целый ряд Hadoop-процессов или, возможно, некоторое количество процессов, прослушивающих общую очередь работ. Операции такого типа хорошо подходят для формирования пакетов работ или асинхронных заданий. Подумайте в данном ключе о таких задачах, как обработка миниатюр изображений, отправка электронной почты или создание отчетов.
Эта модель также хорошо работает при пиковых нагрузках, где по мере возрастания потребностей могут запускаться дополнительные экземпляры для соответствия поступающей нагрузке. Пока сама очередь работ будет сохранять устойчивость, эта модель может использовать масштабирование для повышения как пропускной способности работ, так и отказоустойчивости, поскольку становится проще справиться с влиянием отказавшего (или отсутствующего) исполнителя. Работа займет больше времени, но ничего при этом не потеряется.
Я видел, как это вполне успешно работает в организациях, имеющих в определенные периоды времени большие объемы незадействованных вычислительных мощностей. Например, по ночам для работы системы электронной торговли все имеющиеся машины вам не нужны, поэтому временно их можно задействовать для выполнения заданий по созданию отчетов.
Хотя в системах на основе исполнителей самим исполнителям высокая надежность и не нужна, система, содержащая предназначенную для выполнения работу. должна быть надежной. Справиться с этим можно, к примеру запустив круглосуточный брокер сообщений или такую систему, как Zookeeper. Преимущества такого подхода заключаются в том, что при использовании для достижения этих целей существующих программных средств наиболее сложную задачу за нас выполняет кто-то другой. Но нам по-прежнему требуется знать, как настроить и обслуживать эти системы, добиваясь от них безотказной работы.
Начинаем все заново
Архитектура, использовавшаяся сначала, может не стать архитектурой, используемой в дальнейшем, когда вашей системе придется обрабатывать совершенно разные объемы нагрузки. Как Джеф Дин (Jeff Dean) говорил в своей презентации Challenges in Building Large-Scale Information Retrieval Systems (конференция WSDM 2009), вы должны «закладывать в конструкцию возможность десятикратного роста, но планировать ее перезапись под стократный рост». Для поддержки следующего уровня роста в определенные моменты придется делать нечто весьма радикальное.
Вспомним историю Gilt, которую мы уже затрагивали в главе 6. В течение двух лет Gilt вполне устраивало монолитное Rails-приложение. Бизнес развивался успешно, что означало увеличение количества клиентов и рост объема нагрузки. В определенный переломный момент, чтобы справиться с возросшей нагрузкой, компании пришлось переделать приложение.
Переделка может означать разбиение монолита на части, что и было сделано для Gilt. Или выбор новых хранилищ данных, которые смогли бы лучше справиться с нагрузкой, что и будет рассмотрено нами в ближайшем будущем. Это также может означать применение новых технологий, например переход с синхронных систем «запрос — ответ» к системам на основе событий, применение новых платформ развертывания, смену всех технологических стеков или применение сразу всех этих нововведений.
Есть опасение, что люди поймут необходимость изменения архитектуры в момент достижения определенного порога масштабирования и примут это за предлог для создания с нуля системы под более широкий масштаб. Это может иметь весьма пагубные последствия. Запуская новый проект, мы зачастую не знаем в точности, что именно хотим создать, и не знаем, будет ли он успешен. Нам нужно иметь возможность быстрого проведения эксперимента, чтоб понять, какие функциональные возможности следует создавать. Если изначально попытаться создать систему под широкий масштаб, мы сразу же получим большой объем работ для обеспечения готовности к нагрузке, которой может никогда и не быть. Это отвлечет силы от более важных действий, например от выяснения того, захочет ли кто-нибудь вообще воспользоваться нашим продуктом. Эрик Рис (Eric Ries) рассказывал историю о том, как шесть месяцев было потрачено на создание продукта, который никто даже не загрузил. Он размышлял, что можно было даже установить ссылку на несуществующую веб-страницу, при щелчке на которой люди получали бы сообщение об ошибке 404, чтобы посмотреть, была ли вообще потребность в продукте, а вместо работы провести шесть месяцев на пляже и при этом получить более весомый результат!
Потребность во внесении в систему изменений, позволяющих ей справиться с расширением масштаба, нельзя считать провалом. Нужно считать это признаком успеха.
Масштабирование баз данных
Масштабирование микросервисов без сохранения состояния производится довольно просто. А что делать, если мы сохраняем данные в базе данных? Нам нужно знать, как выполнять масштабирование и в таком случае. Различные типы баз данных требуют разных форм масштабирования, и понимание того, какая из этих форм подойдет наилучшим образом именно для вашего случая, гарантирует выбор нужной технологии баз данных с самого начала.
Доступность сервиса против долговечности данных
Изначально важно отделить понятие доступности сервиса от понятия долговечности самих данных. Нужно разобраться в том, что это два разных понятия и поэтому для них будут использоваться разные решения.
Например, я могу хранить копию всех данных, записанных в мою базу данных, в отказоустойчивой файловой системе. Если база данных откажет, данные не пропадут, поскольку у меня есть копия, но сама база данных станет недоступной, что может привести также к недоступности моего микросервиса. В более обобщенной модели будут задействованы резервы. Все данные, записанные в основную базу данных, будут копироваться в резервную базу данных, являющуюся точной копией основной. Если основная база данных даст сбой, мои данные окажутся в безопасности, но без механизма, который либо их вернет, либо повысит резервную базу до статуса основной, доступной базы данных у нас не будет, хотя сами данные будут в безопасности.
Масштабирование для считываний
Многие сервисы в основном занимаются считыванием данных. Вспомним сервис каталогов, который хранит информацию для выставленных на продажу товарных позиций. Мы добавляем записи для новых товарных позиций на весьма нерегулярной основе, и совсем неудивительно, что на каждую запись в каталог мы имеем по 100 считываний данных нашего каталога. К счастью, масштабирование для чтения дается значительно легче масштабирования для записи. Здесь большую роль может сыграть кэширование данных, которое вскоре будет рассмотрено более подробно. Еще одна модель предусматривает использования реплик чтения.
В системе управления реляционными базами данных (RDBMS), подобной MySQL или Postgres, данные могут копироваться из основного узла в одну или несколько реплик. Зачастую это делается с целью обеспечения безопасного хранения копий данных, но может использоваться также для распределения операций чтения. Сервис может направлять все запросы на запись к единственному основному узлу, но при этом распределять запросы на чтение между несколькими репликами, предназначенными для считывания данных (рис. 11.6). Резервное копирование из основной базы данных к репликам происходит через некоторое время после записи. Это означает, что при такой технологии считывания до завершения репликации данные могут быть устаревшими. Со временем операциям чтения станут доступны согласующиеся данные. Подобная настройка называется согласованностью, возникающей по прошествии некоторого времени, и если вы в состоянии справиться с временной несогласованностью, то ее можно признать довольно простым и весьма распространенным способом, содействующим масштабированию систем. Вскоре, когда дойдет очередь до теоремы CAP, мы рассмотрим его более подробно.
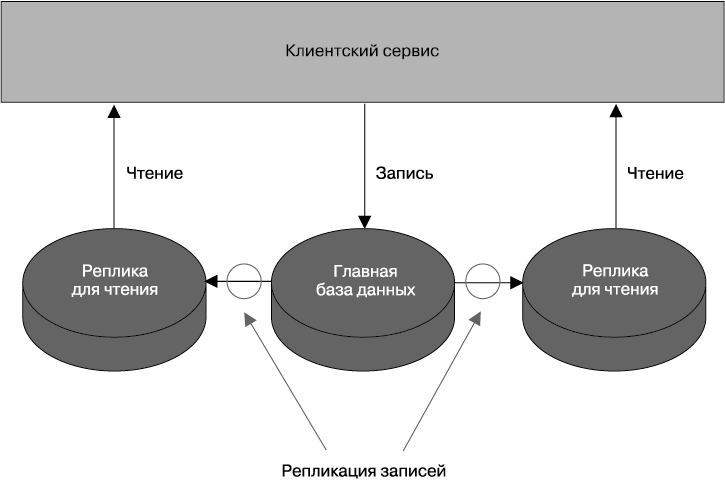
Рис. 11.6. Использование реплик для чтения с целью масштабирования операций считывания данных
Мода на использование реплик чтения в целях масштабирования появилась много лет назад, но сегодня я бы порекомендовал вам присмотреться в первую очередь к кэшированию, от которого можно получить существенно больше преимуществ с точки зрения производительности, зачастую потратив на это меньше времени и сил.
Масштабирование для производства записей
Масштабирование чтения дается сравнительно легко. А как насчет записей? Один из подходов предусматривает применение фрагментации. При этом используются несколько узлов базы данных. Берется часть данных, подлежащих записи, к ним применяется некая функция хеширования для получения ключа данных, и на основании результата работы функции определяется, куда эти данные отправлять. Рассмотрим весьма упрощенный (и совсем негодный) пример: представим, что клиентские записи диапазона A — M попадают в один экземпляр базы данных, а записи диапазона N — Z — в другой. Этим можно управлять самостоятельно в своем приложении, но некоторые базы данных, например Mongo, многое в этом плане делают за вас.
Сложность с фрагментацией операций записи данных заключается в управлении запросами. Когда смотришь на отдельно взятую запись, все представляется несложным, поскольку можно просто применить функцию хеширования, чтобы найти нужный экземпляр данных, а затем извлечь его из соответствующего фрагмента базы. А как быть с запросами, данные которых разбросаны по нескольким узлам, например предписывающими найти всех клиентов старше 18 лет? Если требуется запросить все фрагменты базы, то нужно либо запросить каждый отдельно взятый фрагмент и объединить ответы в памяти, либо иметь альтернативное хранилище для чтения, в котором доступны данные из обоих наборов. Зачастую отправкой запросов, распространяющихся на несколько фрагментов, управляет асинхронный механизм с использованием кэшируемых результатов. Например, в Mongo для выполнения таких запросов используются задания отображения и свертки (map/reduce jobs).
При использовании фрагментированных систем возникает вопрос: что случится, если понадобится добавить еще один узел базы данных? В прошлом для этого нужен был довольно длительный простой, особенно для крупных кластеров, поскольку могла потребоваться остановка работы всей базы данных и перебалансировка хранящейся в ней информации. Совсем недавно во многих системах появилась поддержка добавления фрагментов к не прекращающей работу системе, в которой перебалансировка данных осуществляется в фоновом режиме. К примеру, Cassandra справляется с этим очень хорошо. Добавление фрагментов к существующим кластерам — занятие не для слабых духом, так что все нужно тщательно проверить.
Фрагментация для операций записи может позволить увеличить масштаб, чтобы справиться с объемом записей, но при этом нисколько не улучшить отказоустойчивость. Если клиентские записи в диапазоне A — M всегда попадают в экземпляр X и экземпляр X окажется недоступен, доступ к записям A — M может быть утрачен. Здесь Cassandra предлагает дополнительные возможности, позволяющие гарантировать репликацию данных на несколько узлов кольца (так в Cassandra называется коллекция узлов).
Как можно было бы предположить на основании этого краткого обзора, масштабирование баз данных для проведения операций записи является той самой областью, где все слишком сильно усложняется и возможности различных баз данных начинают очень разниться. Мне часто встречались люди, которые меняют технологию баз данных, как только начинают сталкиваться с ограничениями, не позволяющими простым способом масштабировать имеющиеся у них объемы записи. Если такое произойдет и с вами, то зачастую самым быстрым способом решения проблемы станет приобретение более мощного оборудования, но при этом нужно все же присматриваться к таким системам, как Cassandra, Mongo или Riak, с целью поиска альтернативных моделей масштабирования, предлагающих более подходящие долговременные решения.
Совместно используемые инфраструктуры баз данных
В некоторых типах баз данных, например в традиционных RDBMS, понятия самой базы данных и схемы разделены. Это означает, что одна запущенная база данных может иметь несколько независимых схем, по одной для каждого микросервиса. Это может существенно помочь в сокращении количества машин, необходимых для запуска системы, но при этом появится весьма серьезная единая точка отказа. Если такая инфраструктура базы данных даст сбой, это может повлиять сразу на несколько микросервисов, что потенциально может привести к катастрофическому перебою в работе. Если же вы воспользуетесь подобным типом настроек, следует обязательно оценить все риски. И нужно быть абсолютно уверенными в максимально возможной отказоустойчивости самой базы данных.
CQRS
Схема разделения ответственности на команды и запросы (CQRS) относится к альтернативной модели хранения и запроса информации. При использовании обычных баз данных одна и та же система применяется как для внесения изменений в данные, так и для запроса этих данных. А при использовании CQRS часть системы имеет дело с командами, которые отлавливают запросы на изменение состояния, в то время как другая часть системы работает с запросами на извлечение данных.
Команды бывают с запросами на внесение изменений в состояние. Эти команды проходят проверку, и если они работают, их применяют к модели. В командах должна содержаться информация об их намерениях. Они могут обрабатываться в синхронном или асинхронном режиме, позволяя различным моделям управлять масштабированием. К примеру, входящие запросы можно просто выстроить в очередь и обработать их чуть позже.
Ключевым выводом для нас является то, что внутренние модели, используемые для обработки команд и запросов, сами являются полностью разделенными. Например, я могу выбрать обработку и выполнение команд как событий, возможно, просто сохраняя команды в хранилище данных (этот процесс известен как подбор источников событий). Моя модель запроса может запрашивать источник событий и создавать прогнозы на основе сохраненных событий для сбора сведений о состоянии объектов домена или же просто забрать нужное из командной части системы для обновления различных типов хранилищ данных. Во многих отношениях мы получаем те же преимущества, что и от рассмотренных ранее реплик чтения, но при этом не требуется, чтобы резервное хранилище для реплик было таким же, как и хранилище данных, используемое для обработки изменений данных.
Такая форма разделения позволяет иметь различные типы масштабирования. Части нашей системы, занимающиеся командами и запросами, могут находиться в разных сервисах или на разном оборудовании и пользоваться совершенно разными типами хранилищ данных. Это может открыть для нас массу способов масштабирования. Можно даже поддерживать различные типы форматов чтения, имея несколько реализаций той части, которая занимается запросами, с возможной поддержкой графического представления данных или формы данных на основе пар «ключ — значение».
Но при этом следует иметь в виду, что схема такого рода весьма сильно отходит от модели, в которой все CRUD-операции обрабатываются в едином хранилище данных. Мне приходилось наблюдать, как несколько весьма опытных команд разработчиков бились над получением приемлемых результатов от использования данной схемы!
Кэширование данных
Кэширование довольно часто используется для оптимизации производительности посредством сохранения предыдущего результата какой-нибудь операции с тем, чтобы последующие запросы могли использовать это сохраненное значение, не затрачивая времени и ресурсов на повторное вычисление значения. В большинстве случаев кэширование проводится с целью исключения необходимости выполнения полного цикла обращения к базе данных или другим сервисам для ускорения обслуживания результата. При правильном использовании из кэширования можно извлечь огромные преимущества, выражающиеся в повышении производительности. Причина хорошего масштабирования технологии HTTP под обработку большого количества запросов кроется во встроенной концепции кэширования.
Даже при использовании единого монолитного веб-приложения вариантов того, где и как проводить кэширование, совсем немного. При использовании архитектуры микросервисов, где каждый сервис имеет собственные источник данных и поведение, мы располагаем намного большим количеством вариантов того, где и как проводить кэширование. При использовании распределенных систем кэширование задумывается либо на стороне клиента, либо на стороне сервера. Но какое лучше?
Кэширование на стороне клиента, прокси-сервере и стороне сервера
При кэшировании на стороне клиента результат кэширования сохраняется клиентом. Именно клиент решает, когда обращаться за свежей копией и нужно ли это делать. В идеале нижестоящий сервис будет давать подсказки, помогающие клиенту понять, что делать с ответом, чтобы он знал, когда выполнять новый запрос и надо ли это вообще. При прокси-кэшировании прокси-сервер помещается между клиентом и сервером. Хорошим примером может послужить использование обратного прокси-сервера или сети доставки контента (CDN). При кэшировании на стороне сервера ответственность за кэширование возлагается на сервер, возможно, с использованием таких систем, как Redis, или Memcache, или даже простой организацией кэша в памяти.
Какой из вариантов является наиболее подходящим, зависит от того, что вы пытаетесь оптимизировать. Кэширование на стороне клиента может помочь существенно сократить количество сетевых вызовов и стать одним из самых быстрых способов уменьшения нагрузки на нижестоящий сервис. При этом ответственность за порядок проведения кэширования возлагается на клиента, и если необходимо изменить этот порядок, развертывание изменений для нескольких потребителей может вызвать затруднения. Могут возникнуть трудности и с аннулированием просроченных данных, хотя вскоре мы рассмотрим некоторые применяемые для этого механизмы копирования.
При кэшировании с использованием прокси-сервера процесс непрозрачен как для клиента, так и для сервера. Зачастую это является весьма простым способом добавления кэширования к уже существующей системе. Если прокси-сервер создан для кэширования общего трафика, он может также заниматься кэшированием для нескольких сервисов. Наиболее распространенным примером может послужить обратный прокси-сервер наподобие Squid или Varnish, который может кэшировать любой HTTP-трафик. Наличие прокси-сервера между клиентом и сервером становится причиной дополнительных сетевых скачков трафика, хотя в моей практике проблемы из-за этого возникали крайне редко, поскольку оптимизация производительности, осуществляемая благодаря кэшированию, перевешивала любые дополнительные сетевые издержки.
При кэшировании на стороне сервера процесс непрозрачен для клиентов, и им не о чем волноваться. Когда кэширование проводится близко к границе сервиса или внутри нее, это может упростить такие действия, как аннулирование данных или отслеживание и оптимизация кэш-попаданий. Когда имеется несколько типов клиентов, кэширование на стороне сервера может стать самым быстрым способом повышения производительности.
Для каждого общедоступного сайта, над которым мне приходилось работать, в итоге мы использовали сочетание всех трех подходов. Но бывали и такие распределенные системы, в которых удавалось обойтись вообще без кэширования. Но все это сводилось к знанию того, с какой нагрузкой следует справиться, насколько свежими должны быть ваши данные и что именно сейчас может сделать ваша система. Поначалу нужно просто понять, что в вашем распоряжении имеется целый ряд различных инструментальных средств.
Кэширование при использовании технологии HTTP
HTTP предоставляет ряд весьма полезных средств управления, помогающих нам проводить кэширование либо на стороне клиента, либо на стороне сервера, в которых было бы полезно разобраться, даже если сами вы не пользуетесь HTTP.
Во-первых, при применении HTTP в ответах клиентам мы можем воспользоваться инструкциями по управлению кэшированием — cache-control. В них клиентам говорится о том, должны ли они вообще использовать кэширование ресурсов, и если должны, то как следует проводить кэширование в секундах. У нас также есть возможность настройки заголовка Expires (истечения срока годности), где вместо указания длины кэшируемого содержимого указываются время и дата, при наступлении которых ресурс должен считаться несвежим и подлежащим повторному извлечению. Какая из настроек вам больше подойдет, зависит от характера совместно используемых ресурсов. Для стандартного статичного содержимого сайта, например для CSS или изображении зачастую хорошо подходит простая инструкция cache-control с указанием времени жизни информации (TTL). Однако, если заранее известно, когда поступит новая версия ресурса, разумнее будет воспользоваться Expires-заголовком. В первую очередь все это может принести большую пользу и избавить клиента от необходимости отправки запроса на сервер.
Кроме инструкций cache-control и использования Expires-заголовков, в нашем арсенале полезных свойств HTTP есть еще один вариант — метки объектов (Entity Tags, или ETags). ETag используется для определения того, изменилось значение ресурса или нет. Если я обновляю запись клиента, URI ресурса остается прежним, но значение становится другим, поэтому я буду ожидать изменения ETag. Эффективность этого приема проявляется при использовании условных GET-запросов. При отправке GET-запроса можно указать дополнительные заголовки, сообщая сервису о необходимости отправки нам ресурса только в том случае, если он отвечает ряду критериев.
Представим, к примеру, что мы извлекаем клиентскую запись и ее ETag возвращается в виде o5t6fkd2sa. Чуть позже, возможно, из-за того, что инструкция по управления кэшированием данных предписывает нам, что ресурс должен рассматриваться как несвежий, мы хотим убедиться в том, что получаем самую свежую версию. При выдаче последующего GET-запроса мы можем передать условие об извлечении данных в случае несовпадения ETag — If-None-Match: o5t6fkd2sa. Тем самым серверу сообщается, что нам нужен ресурс по указанному URI, если у него уже имеется ETag, значение которого не соответствует указанному. Если уже есть новейшая версия, сервис отправляет нам ответ 304 Not Modified, обозначающий, что мы уже располагаем самой последней версией. Если доступна более свежая версия, мы получаем ответ 200 OK с изменившимся ресурсом и новой меткой ETag для него.
Тот факт, что эти средства управления встроены в столь широко применяемую спецификацию, означает, что мы можем воспользоваться преимуществом целого арсенала уже существующих программных средств, управляющих кэшированием. Такие обратные прокси-серверы, как Squid или Varnish, могут незаметно размещаться в сети между клиентом и сервером и сохраняя кэшируемое содержимое, и устанавливая для него срок истечения годности. Эти системы предназначены для очень быстрого обслуживания огромного количества параллельных запросов и являются стандартным средством масштабирования общедоступных сайтов. Такие сети доставки контента (CDN), как имеющаяся в AWS сеть CloudFront или Akamai, могут обеспечить маршрутизацию запросов к средствам кэширования, расположенным ближе к осуществившему вызов клиенту, гарантируя тем самым, что трафик, когда он понадобится, не проделает половину кругосветного путешествия. И что еще прозаичнее, справиться за нас с этой работой смогут клиентские библиотеки и клиентские средства кэширования, относящиеся к технологии HTTP.
ETags, Expires-заголовки и cache-control могут перекрывать функции друг друга, и если не проявить осторожность и принять решение о применении всех этих средств, то можно столкнуться с получением весьма противоречивой информации! Получить более глубокое представление о достоинствах тех или иных средств можно, прочитав книгу REST In Practice (O’Reilly) или изучив раздел 13 спецификации HTTP 1.1, где описывается, как эти различные управляющие средства реализуются как на клиентской, так и на серверной стороне.
Если принято решение воспользоваться HTTP в качестве межсервисного протокола, то наиболее подходящим вариантом будет кэширование на стороне клиента и сокращение потребностей клиента в полном цикле выполнения запроса. Если будет принято решение о выборе другого протокола, то нужно понять, когда и как можно предоставить подсказки клиенту, чтобы помочь ему разобраться в том, насколько долго он может пользоваться кэшированными данными.
Кэширование, проводимое для операций записи
Кэширование чаще всего выполняется для операций чтения, однако существует ряд обстоятельств, когда имеет смысл проводить кэширование и для операций записи. Например, если используется кэширование с отложенной записью (write-behind cache), запись можно вести в локальное устройство кэширования, а чуть позже данные будут сброшены в нижестоящий источник — возможно, в канонический источник данных. Это может пригодиться при резком возрастании количества операций записи или высокой вероятности многократной записи одних и тех же данных. При использовании буфера и потенциально пакетных записей кэширование с отложенной записью может поспособствовать дальнейшей оптимизации производительности.
Если используется кэширование с отложенной записью и записи практически постоянно попадают в буфер, то при недоступности нижестоящего сервиса можно будет выстроить очередь из записей и после восстановления доступности отправить их к нему.
Кэширование в целях повышения отказоустойчивости
Кэшированием можно воспользоваться для реализации отказоустойчивости в случае сбоев. Если при использовании кэширования на стороне клиента нижестоящий сервис становится недоступным, клиент может принять решение об использовании кэшированных, но потенциально несвежих данных. Для предоставления ранее использовавшихся данных можно также воспользоваться чем-нибудь вроде обратного прокси-сервера. Для некоторых систем лучше, чтобы они были доступны даже при использовании не совсем свежих данных, чем не возвращали вообще никаких результатов, но это вы будете делать на собственный страх и риск. Разумеется, если запрашиваемых данных в кэше не окажется, то мы уже ничем не сможем помочь, но есть способы смягчения подобной ситуации.
Технология, которую мне приходилось видеть в Guardian, а потом и в других местах, заключалась в периодическом медленном перемещении существующего живого сайта в создаваемую статическую версию сайта, которую можно задействовать в случае сбоя. Хотя эта перетянутая версия не такая свежая, как кэшированное содержимое, обслуживаемое на стороне живой системы, в крайних случаях оно может гарантировать, что версия сайта все же будет выведена на экран.
Скрытие источника
Если при использовании обычного кэша запрос не станет попаданием в кэш, он отправляется к источнику для извлечения свежих данных, а вызывающий данные блокируется в ожидании результата. Обычно такой исход вполне ожидаем. Но если происходит массовое непопадание в кэш, возможно, из-за сбоя машины (или группы машин), предоставляющей кэш, к источнику будет направлено большое количество запросов.
Для сервисов, обслуживающих широко кэшируемые данные, сам источник зачастую должен масштабироваться таким образом, чтобы справиться лишь с долей общего трафика, поскольку большинство запросов обслуживается из памяти средствами кэширования, находящимися перед источником. Если вдруг возникнет критическая ситуация из-за аннулирования целой области кэша, наш источник будет истерзан до смерти.
Один из способов защиты источника в подобной ситуации заключается в первую очередь в категорическом запрете запросам направляться к источнику. Вместо этого (риc. 11.7) сам источник по мере необходимости осуществляет заполнение кэша в асинхронном режиме. Если случается непопадание в кэш, выдается событие, которое может быть подхвачено источником и которое оповещает его о необходимости перезаполнения кэша. Следовательно, если аннулирован целый кусок, мы можем воссоздать кэш в фоновом режиме. Мы можем принять решение о блокировке исходного запроса в ожидании перезаполнения области, но это может вызвать претензии к самому кэшу и возникновение неблагоприятных последствий. Скорее всего, мы отдадим предпочтение сохранению стабильности системы, отклонив исходный запрос и сделав это без промедления.
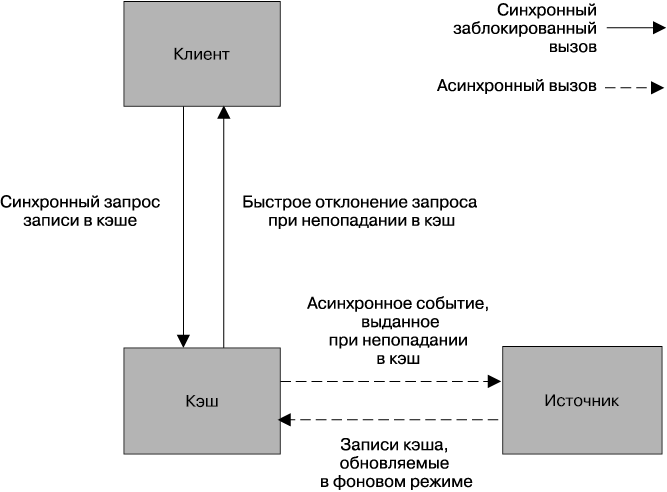
Рис. 11.7. Скрытие источника от клиента и заполнение кэша в асинхронном режиме
В некоторых ситуациях такой подход, возможно, не имеет смысла, но он может стать способом сохранения работоспособности всей системы в случае отказа ее частей. Быстро отклоняя запросы, не занимая ресурсы или не увеличивая время задержки, мы избегаем превращения сбоя в кэше в распространяющийся каскадный сбой и получаем шанс восстановить нормальный режим работы.
Не нужно ничего усложнять
Остерегайтесь излишне широкого применения кэширования! Чем больше средств кэширования между вашей системой и источником свежих данных, тем большим может оказаться объем устаревших данных и тем труднее может стать определение степени свежести тех данных, которые в итоге увидит клиент. С применением архитектуры микросервисов, где в цепочку вызовов вовлечены сразу несколько микросервисов, эта проблема может только усугубиться. Повторю еще раз: чем больше объем применения кэширования, тем труднее будет получить доступ к сведениям о свежести любой части данных. Поэтому, если вы считаете кэширование неплохой затеей, не нужно ничего усложнять, остановитесь на чем-нибудь одном и хорошенько подумайте, прежде чем что-нибудь к этому добавлять!
Отравление кэша: предостережение
При кэшировании мы думаем, что при его неправильном применении самое худшее, что может быть, заключается в кратковременном использовании устаревших данных. А что, если вам в итоге придется всегда пользоваться только устаревшими данными? Ранее я уже упоминал о проекте, над которым работал, где мы использовали приложение со strangler-шаблоном, чтобы легче было перехватывать вызовы к нескольким устаревшим системам с прицелом на постепенный отказ от их применения. Наше приложение вполне эффективно работало в качестве прокси-сервера. Трафик направлялся через приложение к устаревшим приложениям. На обратном пути выполнялись несколько служебных действий. Например, мы убеждались в том, что к результатам, полученным от устаревших приложений, применялись надлежащие HTTP-кэш-заголовки.
Однажды, почти сразу после обычного планового выпуска, начали происходить весьма странные вещи. Была допущена ошибка, при которой к небольшому поднабору страниц в коде вставки кэш-заголовка применялось логическое условие, в результате чего заголовок вообще не изменялся. К сожалению, незадолго до этого изменили и само нижестоящее приложение и в него был вставлен HTTP-заголовок постоянной свежести Expires: Never. Ранее это не производило никакого эффекта, поскольку заголовок переписывался. А теперь никакой перезаписи не происходило.
Для кэширования HTTP-трафика в приложении активно использовалось средство Squid, и мы заметили появившуюся проблему довольно быстро, поскольку видели, что средство Squid стало обходить больше запросов, направляющихся к серверам приложения. Мы внесли исправление в код кэш-заголовков и выдали новый выпуск, а также вручную вычистили соответствующую область Squid-кэша. Но этого оказалось недостаточно.
Как уже упоминалось, кэширование может проводиться в нескольких местах. Когда дело касается обслуживания контента для пользователей общедоступного веб-приложения, между вами и клиентом может быть несколько средств кэширования. Перед сайтом может быть не только что-нибудь вроде CDN-сети — кэширование может использоваться также некоторыми поставщиками интернет-услуг. Можете ли вы контролировать такие средства кэширования? И даже если можете, остается еще одно средство кэширования, над которым у вас нет практически никакого контроля, — это кэш в браузере пользователя.
Страницы со свойством постоянной свежести Expires: Never застревают в средствах кэширования многих ваших пользователей и никогда не будут аннулированы, пока кэш не будет заполнен или пользователь не очистит его вручную. Понятно, что мы не можем инициировать ни то, ни другое событие; единственное, что можно сделать, — изменить URL-адреса таких страниц, чтобы инициировать их повторное извлечение.
Конечно же, кэширование может быть весьма эффективным, но при этом нужно представлять себе весь путь подвергаемых кэшированию данных от источника до пункта назначения, чтобы по-настоящему оценить все сложности и все места, где что-то может пойти не так.
Автоматическое масштабирование
Если вам посчастливилось получить полностью автоматизированное выделение виртуальных хостов и вы можете полностью автоматизировать развертывание экземпляров микросервисов, значит, у вас есть строительные блоки, позволяющие автоматически масштабировать микросервисы.
Например, у вас также может применяться масштабирование, запускаемое при известных тенденциях. Вам может быть известно, что пиковая нагрузка на систему наблюдается между 9:00 и 17:00, поэтому вы подключаете дополнительные экземпляры в 8:45 и выключаете их в 17:15. Если вы пользуетесь такими средствами, как AWS, в котором имеется очень хорошая встроенная поддержка автоматического масштабирования, выключение ненужных экземпляров поможет сэкономить деньги. Чтобы узнать, как изменяется нагрузка в течение дня и недели, понадобятся соответствующие данные. У некоторых разновидностей бизнеса имеются также вполне очевидные сезонные циклы, поэтому, для того чтобы сделать правильные выводы относительно объема вызовов, вам нужны ретроспективные данные.
В то же время можно быстро реагировать, подключая дополнительные экземпляры при обнаружении повышения нагрузки или сбоя экземпляра и удаляя экземпляры, когда надобность в них отпадет. Основным фактором здесь является знание того, насколько быстро вы сможете выполнить масштабирование, заметив восходящую тенденцию. Если вы знаете, что для обнаружения тенденции понадобится всего лишь пара минут, а масштабирование может занять минимум десять минут, значит, для преодоления этого разрыва нужно обзавестись дополнительными мощностями. В таком случае возникает необходимость в применении хорошего набора нагрузочных тестов. Ими можно воспользоваться для тестирования правил автоматического масштабирования. Если тесты, способные воспроизвести различные нагрузки для запуска масштабирования, отсутствуют, то действенность выбранных правил останется проверять только в производственном режиме. И негативные последствия неправильного выбора не будут слишком велики!
Хорошим примером бизнеса, для которого может потребоваться сочетание масштабирования на основе прогноза и на основе реагирования на изменение нагрузки, может послужить сайт. Наблюдая за последним новостным сайтом, над которым мне пришлось работать, мы заметили четкие дневные тенденции с ростом нагрузки с утра до обеда и последующим ее спадом. Эта схема повторялась изо дня в день, а в выходные дни трафик был менее выраженным. Это позволяет выявить весьма четкую тенденцию, которая может управлять упреждающим масштабированием ресурсов путем их добавления (и высвобождения). В то же время какое-нибудь интересное событие может вызвать неожиданный всплеск нагрузки, требующий кратковременного более объемного выделения ресурсов.
Я считаю, что автоматическое масштабирование используется главным образом для того, чтобы справиться со сбоями экземпляров, а не для того, чтобы оперативно реагировать на условия нагрузки. В AWS вы можете определять правила вроде «в этой группе должно быть не менее пяти экземпляров», чтобы при сбое одного из них автоматически запускался новый экземпляр. Я видел, как такой подход приводил к веселой игре в «ладушки», когда кто-то забывал выключить правило, а затем пытался уменьшить количество экземпляров с целью проведения обслуживания и наблюдал за тем, как они все продолжали запускаться!
Полезны оба вида масштабирования, как на основе прогноза, так и на основе реагирования на изменение нагрузки, и оба они могут существенно повысить экономическую эффективность при использовании платформы, позволяющей платить только за использованные вычислительные ресурсы. Но они также требуют тщательного наблюдения за доступными вам данными. Я бы посоветовал использовать автоматическое масштабирование в первую очередь при возникновении сбоев в ходе сбора данных. Если потребуется приступать к масштабированию при изменении нагрузки, нужно проявить особую осторожность и не допустить слишком быстрого возврата мощностей. В большинстве случаев лучше иметь больше вычислительных мощностей, чем нужно, вместо того чтобы испытывать их острый дефицит!
Теорема CAP
Хотелось бы получить абсолютно все, но, к сожалению, мы знаем, что это невозможно. А что касается распределенных систем, подобных тем, что создаются с использованием архитектур микросервисов, есть даже математические доказательства того, что это невозможно. Может, вы уже слышали про теорему CAP, особенно при обсуждении достоинств различных типов хранилищ данных. Ее суть заключается в том, что в распределенных системах есть три компромиссных по отношению друг к другу свойства: согласованность, доступность и терпимость к разделению. В частности, в теореме говорится, что при отказе удается сохранить только два из них.
Согласованность является характеристикой системы, означающей, что при обращении к нескольким узлам будет получен один и тот же ответ. Доступность означает, что на каждый запрос будет получен ответ. Терпимость к разделению является способностью системы справляться с тем фактом, что установить связь между ее частями порой становится невозможно.
После того как Эрик Брюер (Eric Brewer) опубликовал исходную гипотезу, идея получила математическое доказательство. Я не собираюсь в него углубляться не только потому, что это не относится к теме книги, но и потому, что не могу гарантировать, что сделаю это правильно. Воспользуемся лучше несколькими практическими примерами, которые помогут разобраться в том, что за всем этим стоит, и в том, что теорема CAP является выжимкой из весьма логичного набора рассуждений.
Мы уже говорили о некоторых простых технологиях масштабирования баз данных. Возьмем одну из них, чтобы исследовать идеи, положенные в основу теоремы CAP. Представим, что сервис инвентаризации развернут на базе двух отдельных дата-центров (рис. 11.8). В каждом дата-центре экземпляры сервиса поддерживает база данных, и эти две базы данных обмениваются данными, стараясь синхронизировать их между собой. Операции чтения и записи осуществляются через локальный узел базы данных, а для синхронизации данных между узлами применяется репликация.
Теперь подумаем о том, что случится, когда что-нибудь откажет. Представим, что прекратило работу что-либо настолько простое, как сетевая связь между двумя дата-центрами. С этого момента синхронизация даст сбой. Записи, осуществляемые в основную базу данных в дата-центре DC1, не будут дублироваться на дата-центр DC2, и наоборот. Большинство баз данных, поддерживающих такие настройки, поддерживают также какую-либо разновидность технологии выстраивания очередей, чтобы впоследствии обеспечить возможность восстановления из этой ситуации. Но что произойдет до такого восстановления?
Рис. 11.8. Использование репликации двух основных баз для распределения данных между двумя узлами баз данных
Принесение в жертву согласованности
Предположим, что сервис инвентаризации нами полностью не отключен. Теперь при внесении изменений в данные в DC1 база данных в DC2 их не видит. Это означает, что любой запрос, обращенный к узлу инвентаризации в DC2, увидит потенциально устаревшие данные. Иными словами, система все еще доступна на обоих узлах, способных обслуживать запросы, и мы сохранили работоспособность системы, несмотря на разделение, но утратили согласованность. Зачастую это называется AP-системой. Мы не можем сохранить все три свойства.
Если в период данного разделения будет продолжено получение записей, значит, мы смирились с тем фактом, что через некоторое время записи будут рассинхронизированы. Чем дольше продлится разделение, тем труднее будет восстанавливать синхронизацию.
Реальность такова, что даже при отсутствии сетевого сбоя между узлами баз данных репликация данных не проводится мгновенно. Как уже говорилось, системы, которые готовы поступиться согласованностью для сохранения терпимости к разделению и доступности, называются согласованными по прошествии некоторого времени. Иначе говоря, ожидается, что в некоторый момент в будущем обновленные данные станут видны всем узлам, но это не произойдет немедленно, поэтому придется смириться с вероятностью того, что пользователи увидят устаревшие данные.
Принесение в жертву доступности
А что, если потребуется сохранить согласованность и отказаться вместо нее от чего-то другого? Итак, для сохранения согласованности каждый узел базы данных должен знать, что у него имеется такая же копия данных, как и у других узлов баз данных. Теперь при разделении, если узлы баз данных не могут связываться друг с другом, они не могут выполнять координацию для обеспечения согласованности. Мы не в состоянии гарантировать согласованность, поэтому единственным вариантом остается отказ от ответа на запрос. Иными словами, мы приносим в жертву доступность. Система согласована и терпима к разделению, или же можно сказать, что она приняла форму CP. В этом режиме сервису придется выработать меры снижения уровня функциональности до тех пор, пока не будет преодолено разделение и узлы баз данных не восстановят синхронизированность.
Обеспечить согласованность нескольких узлов довольно трудно. В распределенных системах сложно найти задачу труднее этой (если таковая вообще сможет найтись). Давайте немного порассуждаем на эту тему. Представим, что нужно прочитать запись из локального узла базы данных. Как узнать, что эта запись не устарела? Нужно обратиться с вопросом к другому узлу. Но мне также нужно попросить узел базы данных не разрешать обновление этой записи до тех пор, пока чтение не будет завершено, иными словами, для обеспечения согласованности нужно инициировать транзакционное чтение между несколькими узлами баз данных. Но люди, как правило, не связываются с транзакционным чтением, не так ли? Оно слишком медленное. Они запрашивают блокировки. Чтение может заблокировать всю систему. Для выполнения этой задачи всем согласованным системам требуется определенный уровень блокировки.
Как уже говорилось, для распределенных систем сбои не должны быть неожиданностью. Рассмотрим транзакционное чтение в наборе согласованных узлов. Я прошу удаленный узел заблокировать заданную запись, как только чтение будет инициировано. Завершаю чтение и прошу удаленный узел снять его блокировку. Но теперь я не могу с ним общаться. Что же произошло? Правильное применение блокировок вызывает серьезные затруднения даже в системе с единственным процессом, а правильно реализовать их в распределенных системах еще сложнее.
Помните, в главе 5 мы говорили о распределенных транзакциях? Основная причина затруднений при их реализации заключалась в проблеме обеспечения согласованности между несколькими узлами.
Обеспечить согласованность между несколькими узлами настолько трудно, что я буду весьма настоятельно рекомендовать при возникновении насущной потребности в этом не пытаться заниматься изобретательством. Лучше подобрать такое хранилище данных или такую службу блокировки, которые предлагают нужные характеристики. К примеру, такое средство, как Consul, которое вскоре будет рассмотрено подробнее, реализует совершенно согласованное хранилище пар «ключ — значение», разработанное для совместного использования конфигурации несколькими узлами. За лозунгом «Друзья не должны позволять своим друзьям писать собственные системы криптографии» должен следовать лозунг «Друзья не должны позволять своим друзьям создавать собственные распределенные согласованные хранилища данных». Если вы полагаете, что вам нужно написать собственное хранилище данных, обладающее свойствами CP, прочитайте сначала все статьи по данной теме, затем получите степень кандидата наук и потом подумайте, стоит ли тратить несколько лет на получение неработающего хранилища. А в это время я воспользуюсь чем-нибудь уже готовым или, что более вероятно, очень постараюсь создать вместо этого системы, обладающие свойствами AP и согласованностью, возникающей по прошествии некоторого времени.
А как насчет принесения в жертву терпимости к разделению?
Нам ведь нужно понять, какие два свойства из трех выбрать, не так ли? Мы уже получили приобретающую согласованность по прошествии некоторого времени AP-систему. У нас есть согласованная, но трудная в создании и масштабировании CP-система. Почему не создать еще и CA-систему? Итак, как же нам пожертвовать терпимостью к разделению? Если у системы отсутствует терпимость к разделению, она не сможет запускаться по сети. Иными словами, ей нужно быть единым процессом, выполняемым локально. CA-систем среди распределенных систем просто не бывает.
AP или CP?
Каков должен быть правильный выбор: AP или CP? В реальности нужно решать, что от чего зависит. При создании какой-нибудь системы всегда приходится идти на компромиссы. Нам известно, что AP-системы проще поддаются масштабированию и их легче создавать, и мы знаем, что CP-система потребует больших трудозатрат из-за сложностей при поддержке распределенной согласованности. Но мы можем не понимать влияния этих компромиссов на бизнес. Подойдет ли для системы инвентаризации пятиминутная задержка с обновлением записи? Если ответ положительный, то выбор будет за AP-системой. А как насчет сведений о балансе клиента банка? Могут ли они быть устаревшими? Без знания контекста, в котором используется операция, мы не можем решить, как правильно поступить. Осведомленность о существовании теоремы CAP просто помогает понять, что такие компромиссы существуют, и разобраться в том, какие вопросы следует задавать.
Это не все или ничего
Не обязательно, чтобы вся наша система была либо AP, либо CP. Каталог может быть AP, поскольку в случае с ним нас не особо волнует устаревшая запись. А вот насчет сервиса инвентаризации может быть принято решение о его принадлежности к CP, поскольку мы не собираемся продавать клиенту отсутствующий товар, а затем приносить ему извинения.
Но даже отдельные сервисы не обязательно должны быть либо CP, либо AP.
Подумаем о сервисе остатка бонусных баллов, в котором сохраняются записи о количестве полученных клиентами бонусных баллов. Можно решить, что устаревание сведений об остатке этих баллов, демонстрируемых клиенту, нас особо не волнует, но что делать, когда речь пойдет об обновлении остатка и обязательном поддержании согласованности, чтобы убедиться в том, что клиенты не воспользовались большим количеством баллов, чем им было доступно? К какому из типов отнести этот микросервис: CP, AP или же сразу к обоим? Вообще-то мы сделали следующее: применили компромиссы теоремы CAP к отдельным возможностям сервиса.
Еще одна сложность заключается в том, что ни согласованность, ни доступность не должны рассматриваться как либо все, либо ничего. Многие системы допускают куда более тонкие компромиссы. Например, применяя такое средство, как Cassandra, я могу идти на различные компромиссы для отдельных вызовов. Поэтому, если мне требуется строгое соблюдение согласованности, я могу выполнить чтение, ставящее блокировку до тех пор, пока не ответят все реплики, или пока не ответит определенный кворум реплик, или даже пока не ответит отдельный узел. Понятно, что, если в ожидании обратного отчета от всех реплик одна из них окажется недоступна, блокировка будет сохраняться довольно долго. Но если меня устроит простой кворум узлов, приславших отчет, для меня может быть приемлемо частичное отсутствие согласованности, которое поможет стать менее уязвимым к недоступности отдельной реплики.
Вам будут часто попадаться сообщения о людях, которым удалось обойти теорему CAP. Это неправда. Все, что им удается сделать, заключается в создании системы, где некоторые возможности относятся к категории CP, а некоторые — к AP. Математическое доказательство, подкрепляющее теорему CAP, остается незыблемым. Несмотря на неоднократные мои попытки обойти математику в школе, я понял, что сделать это невозможно.
И реальный мир
Многое, о чем мы говорим, относится к миру электроники — битам и байтам, сохраненным в памяти. Мы говорим о согласованности в какой-то манере, похожей на детские рассуждения. Мы представляем себе, что в пределах видимости созданной нами системы мы можем остановить мир и считаем, что во всем этом есть смысл. И еще многое из того, что мы создаем, — это просто отражение реального мира, и мы не в состоянии этим управлять, не так ли?
Вернемся к системе инвентаризации. Она отображается на физические товарные позиции реального мира. Мы в своей системе подсчитываем количество имеющихся альбомов. На начало дня было 100 копий альбома Give Blood группы The Brakes. Одну мы продали. Теперь у нас 99 копий. Все просто, не правда ли? Но что получится, если при отправке заказа кто-нибудь уронит копию на пол и случайно ее раздавит? Что произойдет? Наша система говорит «99», но на полке 98 копий.
А что, если мы создали нашу систему инвентаризации с прицелом на AP-свойства и впоследствии время от времени вынуждены выходить на контакт с пользователем и сообщать ему, что один из его товаров отсутствует на складе? Станет ли это самым худшим, что может случиться в этом мире? Несомненно, гораздо проще будет создать систему, выполнить ее масштабирование и убедиться в том, что все сделано правильно.
Мы должны признать, что независимо от степени возможной согласованности наших систем и от них самих разобраться абсолютно во всем, что может произойти, невозможно, особенно если мы ведем учет происходящего в реальном мире. Это одна из основных причин, по которой во многих ситуациях AP-системы в конечном счете берут верх. Кроме того что CP-системы сложны для построения, они все равно не в состоянии решить все наши проблемы.
Обнаружение сервисов
Когда количество микросервисов, находящихся в вашем распоряжении, станет солидным, вы непременно захотите получить сведения о том, где располагается каждый из них. Возможно, вам потребуется узнать, какой из них работает в той или иной среде, чтобы понять, что нужно отслеживать. Может, просто захочется узнать, где находится сервис счетов, чтобы использующие его микросервисы знали, где его найти. Или, может быть, вам просто потребуется упростить оповещение разработчиков — сотрудников организации, чтобы они знали, какие API-интерфейсы доступны, и не изобретали колесо заново. В широком смысле все эти сценарии можно назвать обнаружением сервисов. И как всегда бывает с микросервисами, в нашем распоряжении немало вариантов, которые можно взять на вооружение.
Все решения, которые будут рассматриваться, действуют в двух аспектах. Во-первых, они предоставляют экземпляру некий механизм для регистрации и заявления «Я здесь!». Во-вторых, они дают способ, позволяющий найти сервис после того, как он зарегистрируется. Но обнаружение сервисов дается труднее, когда рассматривается среда, в которой постоянно ведутся ликвидация и развертывание новых экземпляров сервисов. В идеале хотелось бы, чтобы с этой задачей справлялось любое выбранное нами решение.
Рассмотрим некоторые наиболее распространенные средства поставки сервиса и оценим доступные варианты.
DNS
Лучше начать с простого. DNS позволяет нам связать имя с IP-адресом одной или нескольких машин. Мы можем, к примеру, решить, что сервис счетов всегда можно будет найти по адресу accounts.musiccorp.com. Затем у нас может быть запись, указывающая на IP-адрес хоста, на котором работает этот сервис, или, возможно, этот адрес при его разрешении будет указывать на балансировщик нагрузки, распределяющий нагрузку между несколькими экземплярами. Это означает, что нам в рамках развертывания сервиса придется заниматься обновлением этих входов.
При работе с экземплярами сервиса в других средах мне приходилось наблюдать эффективную работу шаблона домена на основе соглашений. Например, у нас может быть шаблон, определяемый как <имя_сервиса>-<среда>.musiccorp.com, дающий входы типа accounts-uat.musiccorp.com или accounts-dev.musiccorp.com.
Более совершенным способом управления различными средами является использование для разных сред серверов с разными доменными именами. Это позволяет предположить, что accounts.musiccorp.com — это место, где я всегда смогу найти сервис счетов, но данный адрес может разрешаться указаниями на различные хосты в зависимости от того, где я выполняю поиск. Если у вас уже есть свои среды, размещенные в разных сегментах сети, и вам удобно управлять собственными DNS-серверами и записями, это может стать отличным решением, но если вы не извлекаете из такого подхода никаких других преимуществ, можно счесть его слишком трудоемким.
У DNS множество преимуществ, и одно из основных заключается в том, что этот стандарт настолько хорошо продуман и имеет настолько богатый положительный опыт применения, что его поддерживают практически все технологические стеки. К сожалению, когда внутри организации существует несколько сервисов для управления DNS, для среды, в которой мы работаем с высокодоступными хостами, предназначены только некоторые из них, что существенно затрудняет обновление DNS-записей. В компании Amazon неплохо справляется с этой работой сервис Route53, но мне еще не попадался достаточно хороший, самостоятельно занимающий хост вариант, хотя (в чем мы вскоре убедимся) в этом вопросе нам сможет помочь такое средство, как Consul. Кроме трудностей с обновлением DNS-записей, ряд проблем может создать и сама спецификация DNS.
DNS-записи для доменных имен имеют указание времени жизни информации (TTL). Это время означает, как долго клиент может считать запись свежей. Когда мы хотим изменить хост, на который ссылается доменное имя, мы обновляем запись, но нужно учесть то обстоятельство, что у клиента будет храниться старый IP-адрес, по крайней мере пока не истечет TTL. DNS-записи могут кэшироваться во многих местах (даже JVM-машина будет кэшировать DNS-записи, пока вы не заставите ее не делать этого), и чем больше мест, в которых запись кэширована, тем более устаревшей она может быть.
Одним из способов обхода этой проблемы является содержание записи доменного имени для вашего сервиса, указывающего на балансировщик нагрузки, который (рис. 11.9), в свою очередь, указывает на экземпляры сервиса. При развертывании нового сервиса можно удалить старый из записи балансировщика нагрузки и вместо него добавить новый. Некоторые специалисты используют DNS в режиме круговой конкуренции, где сами DNS-записи ссылаются на группу машин. Эта технология считается крайне проблематичной, поскольку клиент скрыт от используемого хоста и потому не может справиться с остановкой маршрутизации трафика на один из хостов в случае его отказа.
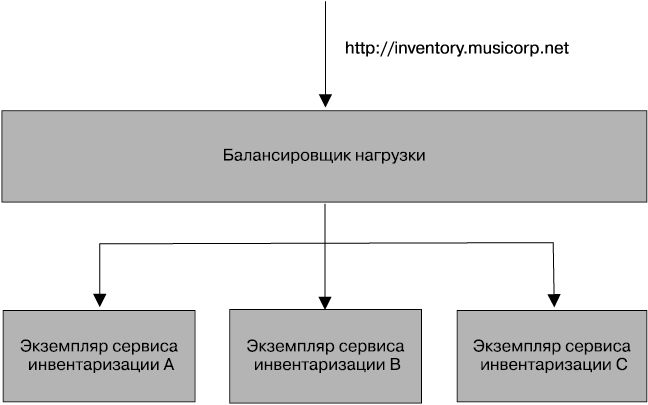
Рис. 11.9. Решение проблемы устаревших DNS-записей путем использования DNS для направления на балансировщик нагрузки
Как уже упоминалось, технология DNS хорошо продумана и пользуется весьма широкой поддержкой. Но у нее все же имеется один или два недостатка. Прежде чем выбрать что-нибудь более сложное, я все же посоветовал бы вам разобраться в том, насколько эта технология сможет подойти для решения именно ваших проблем. Когда у вас имеются только отдельные узлы, использования DNS, ссылающейся непосредственно на хосты, может оказаться вполне достаточно. Но в тех ситуациях, где нужно иметь более одного экземпляра на хост, лучше подойдет использование DNS-записей, разрешенных направлением трафика к балансировщику нагрузок, который может справиться с вводом в строй и с выводом из строя отдельных хостов.
Динамическая регистрация сервисов
Недостатки DNS как способа нахождения узлов в высокодинамичной среде привели к появлению множества альтернативных систем, в большинстве из которых используется самостоятельная регистрация сервисов с применением центрального реестра, который, в свою очередь, предлагает возможность впоследствии выполнять поиск этих сервисов. Зачастую такие системы способны на большее, чем простое предоставление возможности регистрации сервиса и его обнаружения, что можно рассматривать и как полезные свойства, и как излишества. Эта область перенасыщена различными возможностями, поэтому, чтобы дать представление о том, что вам доступно, мы просто рассмотрим несколько вариантов.
Zookeeper
Средство Zookeeper изначально разрабатывалось как часть проекта Hadoop. Оно используется в невероятно большом количестве случаев, в том числе в качестве средства управления конфигурациями, синхронизации данных между сервисами, выбора лидера, выстраивания очереди сообщений и (что полезно для нас) в качестве службы имен.
Подобно многим похожим типам систем, для предоставления различных гарантий Zookeeper полагается на работу сразу на нескольких узлах кластера. Это означает, что вам следует ожидать запуска как минимум трех узлов Zookeeper. Основная доля интеллекта, заложенного в Zookeeper, приходится на обеспечение того, чтобы данные были безопасно реплицированы между этими узлами и чтобы при сбоях узлов сохранялась согласованность.
В своей основе Zookeeper для сохранения информации предоставляет иерархическое пространство имен. Клиенты могут вставлять в эту иерархию новые узлы, вносить в них изменения или запрашивать их. Более того, они могут добавлять к узлам наблюдателей, чтобы получать оповещение о внесении в них изменений. Это означает, что в этой структуре мы можем сохранять информацию о том, где находятся наши сервисы, и клиент будет оповещен о внесении изменений. Zookeeper зачастую используется в качестве главного хранилища конфигурации, поэтому вы также можете сохранять в нем конфигурацию, характерную для сервиса, что позволит вам выполнять такие задачи, как динамическое изменение уровней журнальной регистрации или выключение свойств работающей системы. Лично я стараюсь избегать использования таких систем, как Zookeeper, в качестве источника конфигурации, поскольку считаю, что они могут усложнить поиск причин конкретного поведения того или иного сервиса.
Само средство Zookeeper может делать универсальные предложения, и именно поэтому столь широк спектр его применения. Его можно считать просто реплицированным деревом информации с возможностью оповещения о вносимых изменениях. Это означает, что обычно для подстраивания под конкретный случай применения приходится создавать различные надстройки. К счастью, для этого существуют клиентские библиотеки для большинства языков программирования.
По большому счету, на сегодняшний день Zookeeper может считаться устаревшим и не предоставляет нам такого количества готовых функциональных возможностей для обнаружения сервисов, как более новые альтернативные средства. Тем не менее это давно испытанное и широко используемое средство. Правильно применить основные алгоритмы, реализуемые средством Zookeeper, весьма непросто. К примеру, я знаю одного поставщика баз данных, который использовал Zookeeper только для выбора лидера с целью обеспечения правильного повышения статуса до основного узла при возникновении сбоя. Клиент чувствовал, что Zookeeper был слишком «тяжелым» средством, и потратил много времени на сглаживание шероховатостей в собственной реализации PAXOS-алгоритма, чтобы найти замену тому, что делало средство Zookeeper. Приходится довольно часто слышать, что не нужно создавать собственные криптографические библиотеки. Я расширю это утверждение, сказав, что не следует также создавать собственные распределенные системы координирования. Ведь сколько раз уже говорилось, что нужно использовать то, что уже есть и нормально работает.
Consul
Как и Zookeeper, средство Consul поддерживает и управление конфигурациями, и обнаружение сервисов. Но оно пошло дальше Zookeeper в части предоставления более широкой поддержки ключевых сценариев использования. Например, для обнаружения сервисов в нем показывается HTTP-интерфейс, и одной из убийственных особенностей Consul является фактическое предоставление готового DNS-сервера, а именно это средство может обслуживать SRV-записи, которые дают вам для заданного имени как IP-адрес, так и порт. Следовательно, если часть вашей системы уже использует DNS и может поддерживать SRV-записи, можете просто присоединиться к Consul и приступить к его использованию, не внося никаких изменений в уже существующую систему.
В Consul имеются и другие встроенные возможности, которые могут вам пригодиться, например проверка степени работоспособности узлов. Следовательно, Consul вполне может перекрыть возможности, которые предоставляют другие, специально предназначенные для этого инструменты мониторинга, хотя вы, скорее всего, воспользуетесь Consul в качестве источника этой информации, а затем разместите ее на более сложной инструментальной панели или в системе выдачи предупреждений. Но если в некоторых сценариях применения присущие Consul отказоустойчивость и сконцентрированность на обслуживании систем, интенсивно применяющие узлы краткосрочного пользования, приведут к тому, что этим средством в итоге будут заменены такие средства, как Nagios и Sensu, это меня не удивит.
В Consul для всего, от регистрации сервиса и отправки запросов в хранилище пар «ключ — значение» до вставки проверок степени работоспособности, используется RESTful HTTP-интерфейс. Это существенно упрощает интеграцию с различными технологическими стеками. Одной из особенностей, которая мне нравится в Consul, является то, что поддерживающая это средство команда выделила основную часть управления кластером. Serf, надстройкой для которого является Consul, занимается обнаружением узлов в кластере, управляет восстановлением после сбоев и выполняет оповещение. Затем Consul добавляет к этому обнаружение сервисов и управление конфигурациями. Такое разделение ответственности мне очень импонирует, что не должно стать для вас сюрпризом, учитывая темы, рассматриваемые на страницах этой книги!
Consul является совершенно новым средством, и из-за сложности используемых в нем алгоритмов я, как всегда, испытываю некоторые сомнения, рекомендуя его для столь важного задания. Тем не менее Hashicorp — команда, занимающаяся его поддержкой, несомненно, имеет солидный послужной список в создании весьма полезных технологий с открытым кодом (в виде как Packer, так и Vagrant). И я разговаривал с некоторыми специалистами, успешно использующими данное средство в производственном режиме. Исходя из этого, думаю, к нему стоит присмотреться.
Eureka
Разработанная компанией Netflix система с открытым кодом под названием Eureka не следует тенденциям, наблюдающимся в таких системах, как Consul и Zookeeper, и не пытается быть универсальным хранилищем конфигураций. Она имеет весьма узкую специализацию.
Eureka предоставляет основные возможности обеспечения сбалансированности нагрузки тем, что может поддерживать круговой поиск экземпляров сервисов. Эта система предоставляет конечную точку на REST-основе, поэтому вы можете создавать своих клиентов или использовать ее собственных Java-клиентов. Java-клиент предоставляет такие дополнительные возможности, как проверка состояния работоспособности экземпляров. Разумеется, при отказе от собственного клиента Eureka и переходе непосредственно к конечной точке на REST-основе вам придется заниматься всем этим самостоятельно.
За счет того что клиенты имеют дело с обнаружением сервисов напрямую, нам удается избежать использования отдельного процесса. Но это требует, чтобы сервис обнаружения был реализован каждым клиентом. В Netflix, занимающейся стандартизацией на JVM-машинах, это достигается тем, что Eureka используется всеми клиентами. Если вы являетесь более крупным полиглотом в области вычислительных сред, то для вас это может оказаться гораздо более сложной задачей.
Прокатка собственной системы
Один из подходов, которым я пользовался сам и использование которого видел в других местах, заключался в прокатке собственной системы. В одном из проектов мы интенсивно использовали инфраструктуру AWS, в которой предлагалось воспользоваться возможностью добавления к экземплярам меток. При запуске экземпляров сервиса я хотел применить метки, чтобы помочь определить, каким был этот экземпляр и для чего он использовался. Это позволило бы связать расширенные метаданные с заданным хостом, например:
• service = accounts (сервис = accounts, то есть счета);
• environment = production (среда = производство);
• version = 154 (версия = 154).
Я мог использовать API-интерфейсы инфраструктуры AWS для запроса всех экземпляров, связанных с заданной учетной записью AWS, чтобы найти машины, которые меня интересовали. В данном случае сохранением метаданных, связанных с каждым экземпляром, и предоставлением нам возможности их запроса занималась сама инфраструктура AWS. Затем для взаимодействия с этими экземплярами я создал инструментальные средства командной строки, чем существенно облегчил создание инструментальных панелей для отслеживания состояния, особенно при использовании идеи, заключавшейся в том, чтобы заставить каждый экземпляр сервиса показывать подробности проверки степени работоспособности.
Когда я делал это в последний раз, мы не заходили так далеко, чтобы заставлять сервисы использовать API-интерфейсы AWS для поиска их зависимостей, но не вижу причин, по которым вы не смогли бы это сделать. Разумеется, если вам нужно оповестить вышестоящие сервисы об изменения местонахождения нижестоящих сервисов, то придется делать это самостоятельно.
Не забывайте про людей!
Системы, которые рассматривались до сих пор, облегчали экземплярам сервисов проведение саморегистрации и выискивание других сервисов, с которыми нужно общаться. Но людям также иногда нужна эта информация. Какую бы систему вы ни выбирали, убедитесь в том, что у вас есть доступные инструментальные средства, позволяющие создавать отчеты и информационные панели в верхней части реестров, чтобы создать экспозицию для людей, а не только для компьютеров.
Документирующие сервисы
Разбиением систем на узкоспециализированные микросервисы мы надеемся показать множество стыков в виде API-интерфейсов, которые люди могут использовать для создания многих, надеюсь, замечательных вещей. Если обнаружение проведено правильно, мы знаем, где что есть. Но как узнать, чем все это занимается или как всем этим пользоваться? Один из очевидных вариантов заключается в применении документации, описывающей API-интерфейсы. Разумеется, документация может часто устаревать. В идеале хотелось бы обеспечить постоянное соответствие документации состоянию API-интерфейса микросервиса и облегчить просмотр этой документации, когда мы знаем, где находится конечная точка сервиса. Воплотить это в реальность пытаются две различные технологии, Swagger и HAL, и обе они заслуживают рассмотрения.
Swagger
Swagger позволяет описать API-интерфейс, чтобы можно было создать весьма функциональный пользовательский веб-интерфейс, позволяющий просматривать документацию и взаимодействовать с API-интерфейсом посредством браузера. Особенно подкупает возможность выполнения запросов: вы можете, к примеру, определить POST-шаблоны, разъясняя, какого сорта контент ожидается сервером.
Чтобы справиться со всем этим, Swagger нуждается в сервисе для выставления сопутствующего файла, соответствующего Swagger-формату. У Swagger имеется ряд библиотек для различных языков программирования, которые делают все это за вас. Например, для Java можно комментировать методы, соответствующие API-вызовам, а для вас будет создан соответствующий файл.
Мне нравится то впечатление, которое оставляет Swagger у конечного пользователя, но оно мало что дает для концепции дополнительных исследований на основе гиперсреды. И все же это очень хорошее средство показа документации, дающей представление о ваших сервисах.
HAL и HAL-браузер
Сам по себе язык гипертекстовых приложений (HAL) является стандартом, в котором описываются положения, касающиеся выставляемых нами элементов управления гиперсредой. Как уже говорилось в главе 4, элементы управления гиперсредой являются средствами, с помощью которых мы позволяем клиентам постепенно исследовать API-интерфейсы, чтобы применять возможности наших сервисов без задействования такой же сильной связанности, которая используется другими технологиями интеграции. Если вы решите применять стандарты гиперсреды, заложенные в HAL, то это позволит вам воспользоваться не только большим количеством клиентских библиотек для применения API-интерфейса (на момент написания данной книги в статье «Википедии», посвященной HAL, перечислялись 50 поддерживающих его библиотек для множества различных языков), но и HAL-браузером, предоставляющим способ исследования API с помощью браузера.
Как и Swagger, этот пользовательский интерфейс может применяться не только как живая документация, но и как средство, выполняющее вызовы самого сервиса. Хотя выполнение вызовов происходит не так же гладко. Если при использовании Swagger можно определять шаблоны для выполнения таких операций, как выдача POST-запросов, с HAL вы больше полагаетесь на собственные силы. В то же время присущая элементам управления гиперсредой эффективность позволяет намного продуктивнее исследовать API-интерфейс, демонстрируемый сервисом, поскольку дает возможность легко и просто следовать по ссылкам. Оказывается, браузеры великолепно справляются и с этими задачами!
В отличие от Swagger, все информация, необходимая для управления данной документацией и «песочницей», встроена в элементы управления гиперсредой. Но это обоюдоострый меч. Если вам уже приходилось использовать элементы управления гиперсредой, то больших усилий для показа HAL-браузера и предоставления клиентам возможности исследования вашего API-интерфейса не понадобится. Но если вам не приходилось пользоваться гиперсредой, то либо вы не сможете применять HAL, либо вам придется подгонять свой API-интерфейс под использование гиперсреды, что, скорее всего, станет занятием, нарушающим нормальную работу текущих потребителей.
Тот факт, что в HAL также дается описание стандартов гиперсреды с поддержкой клиентских библиотек, является дополнительным бонусом, и я полагаю, что именно в этом кроется весомая причина, по которой среди тех, кто уже имеет опыт применения элементов управления гиперсредой, наблюдается больше сторонников использования HAL, чем сторонников применения Swagger в качестве способа документирования API-интерфейсов. Если вы используете гиперсреду, то я советую отдать предпочтение HAL, а не Swagger. Однако если вы используете гиперсреду, но не видите оснований для перехода на HAL, я настоятельно рекомендую пустить в дело Swagger.
Самостоятельно описываемая система
В ходе раннего развития сервис-ориентированной архитектуры появились такие стандарты, как Universal Description, Discovery и объединенный стандарт Integration (UDDI), помогающие людям разобраться в том, какие сервисы были запущены. Эти подходы были весьма тяжеловесными, что приводило к появлению альтернативных технологий, с помощью которых осуществлялись попытки разобраться в наших системах. Мартин Фаулер рассмотрел концепцию понятного человеку реестра, в рамках которой использовались намного более легкие подходы, предназначенные просто для того, чтобы люди могли записывать информацию о сервисах в организациях в чем-то таком же простом, как вики.
Получение описания нашей системы и характера ее поведения играет важную роль, особенно когда дело касается вопросов масштабирования. Мы уже рассмотрели несколько различных технологий, которые помогут нам обрести понимание непосредственно из нашей системы. Отслеживая состояние работоспособности нижестоящих сервисов наряду с отслеживанием идентификаторов взаимосвязанности, что помогает нам проследить цепочки вызовов, мы можем получить реальные данные в условиях взаимосвязанности сервисов. Используя такие системы обнаружения сервисов, как Consul, мы можем увидеть, где работают микросервисы. HAL позволяет нам увидеть, какие возможности размещены в данный момент в каждой отдельно взятой конечной точке, а страница проверки работоспособности и системы мониторинга позволяют узнать, каково состояние работоспособности как системы в целом, так и отдельных сервисов.
Всю эту информацию можно получить программным способом. Совокупность этих данных позволяет нам сделать понятный человеку реестр эффективнее простой вики-страницы, которая, несомненно, будет устаревать. Вместо этого мы будем применять его для задействования и отображения всей информации, выдаваемой системой. Создавая настраиваемые информационные панели, мы можем обобщить огромный массив информации, доступной для оказания помощи в осмыслении нашей экосистемы.
Во всех смыслах начинать следует с чего-нибудь настолько же простого, как статическая веб-странница или вики, на которой по крупицам собираются данные о живой системе. Но со временем нужно присматриваться к размещению все больших объемов информации. То, что к этой информации можно быстро получить доступ, является ключевым инструментом, позволяющим справиться с трудностями, возникающими из-за эксплуатации этих систем в режиме масштабирования.
Резюме
Микросервисы как подход к проектированию все еще довольно молоды, поэтому, хотя у нас уже есть вполне определенный опыт, от которого можно отталкиваться, я уверен, что в следующие несколько лет появятся более удачные схемы, позволяющие успешно справляться с их масштабированием. И тем не менее я надеюсь, что в этой главе был намечен ряд шагов, которыми можно будет воспользоваться в вашем путешествии по масштабированию микросервисов и которые станут для вас хорошим подспорьем.
Вдобавок к тому, что здесь было рассмотрено, я рекомендую прочитать замечательную книгу Майкла Нигарда (Michael Nygard) Release It!. В ней он делится с нами подборкой историй о сбоях системы и некоторыми схемами, помогающими успешно справиться со сбоями. Книгу действительно стоит прочитать (более того, я хотел бы заострить внимание на том, что она должна рассматриваться в качестве весьма важного пособия для тех, кто создает масштабируемые системы).
Мы уже усвоили довольно много основ и близки к завершению нашего разговора. В следующей, последней главе мы уделим внимание объединению всего изученного в единое целое и подытожим все, что нам удалось узнать при прочтении книги.
CAP — по первым буквам англоязычных названий этих свойств. — Примеч. пер.

