Книга: Революция в аналитике. Как в эпоху Big Data улучшить ваш бизнес с помощью операционной аналитики
Назад: Глава 4 Хотите бюджет? Разработайте бизнес-кейс!
Дальше: Глава 6 Управление и конфиденциальность
Глава 5
Создаем аналитическую платформу
В последние годы аналитический ландшафт все более усложняется. В сегодняшнем мире операционной аналитики совсем не так просто выбрать аналитические инструменты и базы данных. Появилось много новых инструментов и технологий, которые можно включить в современное аналитическое окружение. Эти технологии включают в себя нереляционные платформы, такие как Hadoop, платформы для обнаружения данных, поддерживающие как реляционные, так и нереляционные данные, а также их обработку, аналитика оперативной памяти, аналитика на основе графического процессора, обработка сложных событий и встроенные аналитические библиотеки. Мы поговорим о каждой технологии более подробно.
Со временем дальнейшая интеграция сделает аналитическое окружение еще более цельным и простым в использовании. Но сегодня приходится иметь дело с разнообразием компонентов в аналитической платформе. Главное здесь – надежно настроить платформу в целом так, чтобы она могла удовлетворять все ваши аналитические потребности. Причем и насущные, и те, чье появление предвидится в ближайшие несколько лет.
Для успеха операционной аналитики необходимо соединить компоненты разным образом и без изъятий, как в прошлом, чтобы создать отдельное единое аналитическое окружение, которое можно масштабировать с целью управления любым типом и объемом данных для любого вида анализа. Это может показаться невыполнимой задачей, но сегодня рынок развивается стремительно, так что задача стала уже вполне осуществимой. В этой главе мы рассмотрим, как извлечь пользу из всех вариантов и правильно разместить аналитическую платформу, которая будет выполнять все требования операционной аналитики.
Прежде чем мы начнем, обратите внимание на то, что рынок изменяется крайне быстро. Эта глава была написана в начале 2014 г., и, хотя бо́льшая часть содержания книги не слишком чувствительна к фактору времени, не исключено, что кое-какой представленный в данной главе материал получит развитие к тому моменту, когда вы будете читать книгу. Общие концепции останутся актуальными еще долгое время, но, возможно, вам придется адаптировать некоторые специфические моменты с учетом новейших разработок инструментов и технологий и с учетом предложений, появившихся на рынке.
Планирование
Планирование и внедрение аналитической платформы – непростая задача. В этом разделе мы рассмотрим несколько подходов и концепций, которые должны быть рассмотрены в ходе процесса планирования.
Операционализация аналитики – не технологическая проблема
Клиенты часто удивляются, когда я говорю им о том, что операционализация аналитики не является собственно технологической проблемой. Хотя существующие сегодня технологии позволяют обрабатывать подавляющую часть больших данных и удовлетворять потребности в операционной аналитике для подавляющей части организаций. Да, всегда встречаются нестандартные ситуации, но, пожалуй, все, что требуется вашей организации для успешного внедрения операционной аналитики в плане технологий, сегодня доступно на рынке. Если это так, почему тогда во многих организациях технологии рассматриваются как ключевая проблема?
Чтобы ответить на этот вопрос, важно понимать разницу между технологией как симптомом и технологией как причиной. В конце 2012 г. на ежегодной конференции, организованной моей компанией, у меня состоялся разговор с сотрудником крупного клиента. Этот человек входил в команду, занимавшуюся сетями и инфраструктурой, – сфера, с которой я редко сталкиваюсь по роду своей деятельности. Несмотря на то что наши миры редко пересекались, нам обоим было интересно поговорить друг с другом. Но когда разговор зашел о проблемах его компании, он не согласился с моим мнением о том, что дело вовсе не в технологиях.
Собеседник сказал, что понял меня, но при этом отметил, что в его компании использовались устаревшие сетевые протоколы. Корпоративная сеть попросту не справлялась с новыми объемами больших данных и новыми аналитическими требованиями. Сеть задыхалась, и ее поддержание в рабочем состоянии стало для него ежедневным кошмаром. Он поинтересовался, считаю ли я, что и в данном случае технология не является главной проблемой.
Симптом или причина?
Распространенным симптомом проблем, связанных с фундаментальным процессом или политикой, является влияние этих проблем на сопряженные с ними технологии. Во многих случаях проблема кроется вовсе не в технологиях. Вы должны различать, в каких случаях технология действительно является причиной проблем, а в каких – всего лишь симптомом скрытой проблемы.
Тогда я спросил у собеседника, почему бы не внедрить в его компании продвинутые сетевые продукты, способные успешно обрабатывать потоки данных и удовлетворять аналитические потребности, с которыми не справлялась существующая сеть. Он признал такую возможность, но сказал, что не может модернизировать сеть, потому что ему не выделяют необходимого финансирования. Тем самым он только подтвердил мою точку зрения. Позвольте мне объясниться.
В этой конкретной ситуации технология не была главной проблемой, ведь необходимые технологические решения доступны на рынке. Проблема же заключалась в том, что команде моего собеседника никак не удавалось убедить руководство компании в необходимости внедрения этой технологии. Команда не могла добиться одобрения своего бизнес-кейса и выделения бюджета, потому что не была отмобилизована на реализацию проекта. Таким образом, хотя технологии были источником постоянной головной боли для его команды, но не они являлись главным источником проблем.
То же самое верно и при внедрении организациями операционной аналитики. В некоторых случаях будет казаться, что именно технология создает барьеры. В таких ситуациях я рекомендую вам посмотреть на ситуацию со стороны – действительно ли технология является причиной, а не симптомом проблем?
Компоненты будут добавляться, а не заменяться
Распространено заблуждение насчет того, что новые аналитические технологии полностью заменят проверенные временем технологии. Разумеется, это не так. В действительности по мере расширения потребностей в аналитике и развития имеющихся технологий компании будут добавлять новые компоненты в аналитическое окружение, а не заменять старые на новые.
Пожалуй, наиболее широко распространено ошибочное мнение о том, что Hadoop (или более широкий класс нереляционных инструментов, к которым принадлежит Hadoop) постепенно заменяет окружение реляционных баз данных. Hadoop – это проект с открытым исходным кодом, позволяющий разбивать крупные файлы на части и обрабатывать их параллельно. (Далее в этой главе мы рассмотрим технологию Hadoop подробнее.) В действительности же Hadoop наращивает реляционное окружение, и им обоим найдется место в аналитических структурах современных организаций.
Такая путаница проистекает главным образом из того факта, что сегодня практически 100 % компаний уже используют реляционную технологию. Соответственно по рынку гуляет множество историй о том, как компании «переходят на Hadoop». Однако выражение «переходят на Hadoop» неверно. Правильнее будет говорить, что компании «добавляют Hadoop». При ближайшем рассмотрении практически во всех случаях мы видим, что Hadoop добавляется к существующему окружению, но никак не все окружение мигрирует на Hadoop.
Путаница усугубляется тем фактом, что обратный сценарий встречается крайне редко. Крайне мало организаций используют только Hadoop без реляционного окружения, и эти редкие исключения сосредоточены в основном в Кремниевой долине. Таким образом, нечасто можно услышать о том, что пользователь Hadoop «переходит на реляционную модель» или «добавляет реляционную модель» к своему окружению.
Одна из крупнейших компаний, которая традиционно использовала только Hadoop и нереляционные подходы, – это Facebook. Как известно, Facebook всегда делала ставку на разработку в своих стенах собственных технологий и проприетарных систем. Действительно, Facebook разработала Hive, один из первых и ныне популярных компонентов языка структурированных запросов, доступный пользователям Hadoop. Тем не менее на конференции, организованной Институтом хранения данных (The Data Warehousing Institute, TDWI) в мае 2013 г., Facebook объявила о том, что добавляет к окружению Hadoop реляционный компонент. Почему она это делает? Потому что команда Facebook поняла: реляционная технология исключительно хорошо решает некоторые из проблем, с которыми сталкивается компания. Facebook очень долго пыталась заставить Hadoop делать то, что платформа не предназначена делать. Комбинация технологий оказалась более разумной и позволила высвободить ресурсы для решения других задач.
Разные платформы – разные преимущества
На первый взгляд Hadoop кажется похожей на параллельные платформы реляционных баз данных. Несмотря на то что все они представляют собой механизм параллельной обработки, между ними существуют большие различия. Возможно, наиболее точную характеристику Hadoop дал один оборонный подрядчик из Вашингтона, округ Колумбия. (Комментарий был сделан на частном мероприятии и на условиях неразглашения, поэтому я не могу ничего конкретизировать.) На этом мероприятии группа экспертов обсуждала проблемы, с которыми сталкивались их организации, когда пытались сделать слишком много и слишком быстро при помощи таких новых платформ, как Hadoop.
Один из экспертов сообщил следующее: «Я понял, что Hadoop превосходно решает именно те задачи, для решения которых эта платформа и была создана за большие деньги такими компаниями, как Google и Yahoo! Если и у вас есть именно такие задачи, например соотнесение ключевых слов в поисковых запросах с содержанием веб-сайтов, тогда и для вас Hadoop станет феноменальной технологией. Если и другие задачи могут быть успешно решены при помощи этой парадигмы обработки, тогда Hadoop тоже окажется очень полезна. Однако существуют такие типы аналитики и обработки, для которых Hadoop совершенно неэффективна по сравнению с другими вариантами». Это вовсе не приговор Hadoop. В действительности ни одна технологическая платформа не может идеально подходить для всех видов обработки и всех ситуаций. У каждой платформы есть свои сильные и слабые стороны. Вот почему, как уже было сказано выше, организациям надо использовать разные технологические платформы и инструменты для разных типов аналитических процессов.
Если вы посмотрите, как работает Hadoop, то увидите, что она превосходно подходит для определенных типов вычислений. Например, таких, где при обработке и хранении данных изначально требуется масштабирование, о чем мы говорили во второй и четвертой главах. Но на момент написания книги Hadoop не предусматривала возможностей масштабирования до общекорпоративного уровня других параметров, таких как безопасность, параллелизм и управление рабочей нагрузкой. Hadoop также замечательно подходит для нетрадиционных типов данных, таких как аудио, видео или текст, которые не были отформатированы в пригодную для аналитики форму и все еще находятся в необработанном и неочищенном виде. Преимущество Hadoop в том, что она позволяет хранить данные без каких-либо ограничений по формату.
Задача, с которой массивно-параллельная реляционная платформа справляется лучше всего, – это работа с уже структурированными высокоценными данными, предназначенными для поддержки широкого круга пользователей и приложений, которые нуждаются в частом повторном использовании этих данных с гарантированной производительностью. Такое свойство реляционных технологий будет часто применяться при превращении традиционной аналитики в операционную.
Не сравнивайте яблоки с апельсинами
Разные аналитические платформы имеют свои сильные и слабые стороны, которые должны быть хорошо изучены и приняты во внимание при планировании аналитического окружения. Многие люди ошибочно полагают, что реляционные и нереляционные технологии, такие как Hadoop, эквивалентны, но на самом деле они не конкурируют, а дополняют друг друга. Сравнивать эти платформы – все равно что сравнивать яблоки с апельсинами.
На вебинаре под названием «Суммарная стоимость данных», состоявшемся в ноябре 2013 г., вице-президент Hortonworks (компании, которая специализируется на разработке и внедрении Hadoop, а также связанных с ней услуг) сделал очень важное заявление. Он сказал: «Мы не видим, чтобы кто-нибудь пытался использовать Hadoop для создания корпоративного хранилища данных [Enterprise Data Warehouse – EDW]. Это вопрос мощности, а не стоимости. Hadoop – это не EDW. Hadoop – это не база данных. Сравнивать эти две технологии с точки зрения рабочей нагрузки EDW – все равно что сравнивать яблоки с апельсинами. Я не знаю никого, кто бы пытался построить EDW в Hadoop». Эти слова никоим образом не принижают значение Hadoop, а просто подчеркивают ее предназначение для решения определенных задач. Точно так же можно сказать: «Я не знаю никого, кто бы пытался использовать реляционную технологию для обработки изображений».
Организации, решившие внедрить операционную аналитику, в конечном итоге придут к совместному использованию реляционных и нереляционных технологий. Когда мы далее в этой главе будем говорить об опорах аналитической архитектуры, то подробнее обсудим, как эти технологии могут совмещаться. Пока же вам надо понять: они не заменяют, а дополняют друг друга.
Делайте то, что нужно сейчас
Предположим, что во время летнего отпуска вы решили купить новый телевизор и стали изучать возможные варианты, чтобы выбрать наиболее подходящий. При этом узнаёте, что в начале весны в продаже появится новое поколение телевизоров с замечательными функциями. В результате вы решаете отложить покупку, чтобы весной приобрести новую модель. Но весной, когда эта модель появляется, узнаёте, что осенью ожидается выход еще более усовершенствованной модели. Так может продолжаться бесконечно. Пока вы откладываете покупку снова и снова, вам приходится довольствоваться устаревшим телевизором, не обладающим ни одной из новых функций. В конце концов вам придется решиться на покупку. То же самое верно и по отношению к аналитическим платформам и инструментам. Всегда будет ожидаться выход новых версий с улучшенными функциями. В определенный момент вам все же придется реализовать свой план. Иначе вы упустите все преимущества, как настоящие, так и будущие, которые могут стать доступными вашей организации.
Не застывайте в нерешительности
Не стоит откладывать модернизацию аналитического окружения в ожидании следующего пакета с функциями, который должен выйти «в ближайшее время». Новые функции всегда будут появляться в ближайшее время, поэтому выберите лучшее на данный момент и начните пожинать плоды. Время для новой модернизации наступит раньше, чем вы об этом узнаете.
Принимая во внимание постоянно меняющуюся перспективу, я настоятельно рекомендую вам не медлить с действиями, если только вы не ожидаете появления какой-либо конкретной функции, абсолютно необходимой для нужд вашего бизнеса сегодня. Если же будете постоянно откладывать решение, вашей организации придется пользоваться устаревшими платформами, не способными справиться с текущими потребностями бизнеса. Многие инструменты и технологии предусматривают возможность обновления до новых версий либо бесплатно, либо по льготной цене. Просто решите, насколько интенсивно ваша организация планирует модернизировать систему и заложите в смету соответствующие финансовые затраты и затраты труда. Также имейте в виду, что жизненный цикл инвестиций в технологии сегодня, как правило, составляет всего три – пять лет. Это значит, что не успеете вы оглянуться, как вам снова придется выбирать из разных вариантов.
Если у вас есть грамотный план, хорошие условия и утвержденный бюджет, спросите себя: «Могут ли какие-либо новые функции, появление которых ожидается в ближайшие несколько месяцев, радикально улучшить результаты?» Если могут, то измените график реализации проекта, чтобы воспользоваться преимуществами новых возможностей. Но при этом также учтите сопряженные с решением риски, поскольку в новом программном обеспечении всегда содержатся ошибки, да и выпуск его может быть отложен. Если же новые функции появятся позже, чем спустя несколько месяцев, ждать не имеет смысла. Откладывая решение из-за слухов о том, что может появиться в ближайшее время, вы никогда не выберетесь из замкнутого круга домысливания. Примите лучшее их возможных сегодня решений и обретите с ним счастье.
Построение
Итак, вы готовы к построению обновленного аналитического окружения. В этом разделе представлены некоторые новейшие подходы к процессу обновления вашего окружения. Мы рассмотрим различные технологии и способы их сочетания для того, чтобы помочь вашей организации превратить традиционную аналитику в операционную. Кроме того, как я рекомендовал в начале этой главы, обязательно изучите новейшие альтернативы, ставшие доступными на момент чтения книги.
Добро пожаловать в компьютинг на основе текстуры
На протяжении многих лет крупные организации стремились объединять наиболее ценные данные и аналитические процессы на единственной централизованной платформе, называемой корпоративным хранилищем данных (EDW). Эта большая реляционная база данных обычно использует параллельную платформу баз данных для достижения максимальной масштабируемости и производительности. Параллельные системы состоят из множества машин, которые соединены между собой таким образом, что данные предоставляются пользователю, как если бы система была одной большой машиной. На самом же деле данные в EDW хранятся не в одном месте, а распределены между множеством машин с одинаковой конфигурацией и соединенных друг с другом в высокопроизводительную сеть.
Создание традиционной системы EDW, функционирующей с точки зрения пользователя как единая машина, требует молниеносных соединений между входящими в нее машинами, а также сложного программного обеспечения для выполнения обработки. Такие соединения позволяют осуществлять масштабное перемещение данных, когда это необходимо (например, при объединении двух больших таблиц), и обеспечивают невероятно высокую скорость операций, когда перемещение данных не требуется. В отличие от этой концепции, которая объединяет машины с одинаковой конфигурацией, система на основе текстуры соединяет между собой различные типы платформ. Компьютинг на основе текстуры соединяет множество разных систем в одну большую логическую систему посредством высокоскоростных сетей, что позволяет любому компоненту взаимодействовать и обмениваться данными с любым другим компонентом текстуры. Многие люди приравнивают текстурный компьютинг к технологии Infiniband, действующей гораздо быстрее, чем соединения в традиционных сетях. Однако эта сеть является всего лишь основой для аналитических процессов и соответствующего программного обеспечения по управлению процессами. На рис. 5.1 проиллюстрирована концепция построения компьютинга на основе текстуры.
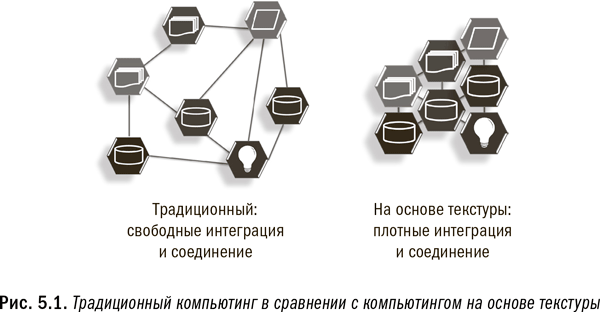
В современных системах на основе текстуры машины с разными конфигурациями и разными базовыми платформами могут взаимодействовать между собой с молниеносной скоростью. Произвольное и частое перемещение массивных объемов данных по текстуре по-прежнему нежелательно, но очевидное преимущество состоит в том, что сейчас стало возможным достаточно быстро перемещать данные для удовлетворения важных потребностей без серьезного ухудшения производительности. С учетом строгих требований к производительности перемещение больших объемов данных в производственном или операционном окружении по-прежнему должно быть сведено к минимуму. Тем не менее в процессе обнаружения данных, когда производительность не так важна, применение текстуры обеспечивает безграничную эффективность и гибкость.
Единое аналитическое окружение уже на подходе
Компьютинг на основе текстуры развивается с целью удовлетворения сегодняшних потребностей в анализе больших объемов данных различного типа с использованием широкого разнообразия аналитических техник. Конечная цель – создать единое аналитическое окружение, где пользователи смогут всецело сосредоточиться на анализе данных, не думая о том, где эти данные находятся.
Превращение традиционной аналитики в операционную, особенно в эпоху больших данных, требует выбора концепции компьютинга на основе текстуры и создания единого аналитического окружения. Сегодня существует слишком много разных типов данных и различных аналитических потребностей для того, чтобы позволить единственной платформе управляться со всем, что касается скорости и масштаба. В едином аналитическом окружении пользователям будет не важно, какие конкретно технологии оно включает и где в текстуре физически находятся данные. Вместо этого они могут сосредоточиться на построении логики аналитического процесса. Давайте же посмотрим, как создать фундамент для будущего, которое начинается уже сегодня.
Три столпа единого аналитического окружения
Единое аналитическое окружение, способное выполнять операционную аналитику для организации, стоит на трех опорах:
1. Реляционная база данных: используется для развертывания операционной аналитики в масштабах всей организации с учетом широкого круга пользователей и приложений. Это рабочая лошадка, которая внедряет операционную аналитику в бизнес-процессы.
2. Технология обнаружения данных: используется с целью облегчить исследование данных любого типа и тестирования аналитических процессов любого типа. Позволяет организации быстро и эффективно находить в данных новые инсайты.
3. Нереляционная технология (обычно Hadoop): используется для сосредоточения и первичной обработки данных любого типа, поскольку не делает предположений относительно их структуры. Также используется для текущего хранения малоценных и/или редко используемых данных.
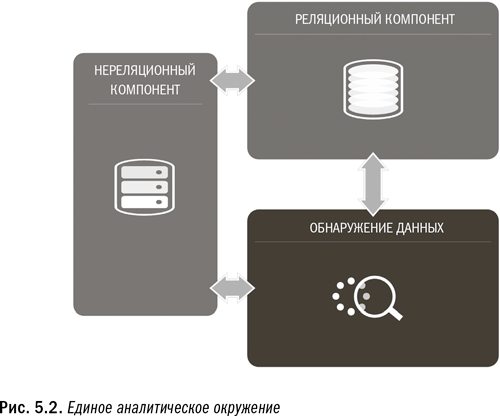
Чтобы понять, как эти опоры сочетаются друг с другом в едином аналитическом окружении (рис. 5.2), вы можете представить каждую технологию в виде специализированного мозга. В прошлом все три мозга были автономными и не соединенными между собой. Поэтому каждый мог воспользоваться преимуществами только своей узкой специализации. Компьютинг на основе текстуры объединяет их с целью создать один мозг со множеством специализированных компонентов, которые могут напрямую взаимодействовать между собой и поддерживать друг друга. Это очень похоже на то, как работает человеческий головной мозг. Разные отделы нашего мозга отвечают за разные действия, но все они интегрированы в единую систему, которая гораздо мощнее суммы отдельных ее компонентов. Аналогичным образом единое аналитическое окружение как целое обладает гораздо большим потенциалом, чем сумма его отдельных частей.
Далее мы обсудим каждый компонент более подробно. В добавление к трем несущим опорам можно использовать для специфических нужд по выбору некоторые вспомогательные технологии. К ним относятся обработка в памяти, инструменты на основе графического процессора, технологии для обработки сложных событий и встроенные аналитические библиотеки. Каждая из них будет рассмотрена ниже.
Реляционная опора
Практически все организации сегодня используют механизмы реляционной базы данных для управления данными, предназначенными для поддержки корпоративных приложений. Большинство крупных организаций внедрило массивно-параллельный механизм базы данных, чтобы гарантировать предельную масштабируемость, которую такой механизм может придать аналитическим процессам. Компании, предлагающие предприятиям параллельное пространство для баз данных, включают в том числе Teradata, IBM и Oracle. На протяжении ряда лет реляционная технология была стандартным способом хранения данных и выполнения отчетов и аналитики на основе этих данных. Поскольку из трех опор реляционная технология является наиболее распространенной и понятной, мы рассмотрим ее вкратце.
Очень распространено заблуждение, будто загружать в реляционную базу можно только данные в сложноструктурированном формате, полностью и формально определенные. Несмотря на то что во многих организациях действуют правила, требующие приведения данных к формальной модели и структуре перед загрузкой, на самом деле реляционная технология этого не требует. Изображения или аудио плохо подходят для реляционной системы, а вот сенсорные данные и блоги вполне можно использовать, пусть и с небольшими дополнительными усилиями. Многие поставщики реляционных баз данных сегодня обеспечивают прямую поддержку расширяемого языка разметки Extensible Markup Language (XML), а некоторые недавно начали поддерживать и текстовый формат обмена данными JavaScript Object Notation (JSON). Поддержка этих форматов позволяет, в частности, загружать исходные сенсорные данные и делать запросы к ним напрямую, не прибегая к дополнительным манипуляциям.
Единый мозг со специализированными подсистемами
Единое аналитическое окружение на основе текстуры будет функционировать как единый мозг с несколькими специализированными подсистемами. При таком способе интеграции различных технологий единое целое будет обладать гораздо большим потенциалом, чем его отдельные компоненты, – точно так же, как это происходит в случае человеческого головного мозга.
Оба формата XML и JSON имеют структуру, но она далеко не такая чистая, четко определенная и неизменная, как в традиционных форматах, таких как файлы фиксированной ширины или файлы с разделителями. Форматы XML и JSON часто называют слабоструктурированными. Извлечение информации из данных, представленных в таких форматах, требует некоторых дополнительных усилий, но зато придает необходимую гибкость. На рис. 5.3 приведен пример файла JSON. При взгляде на него легко понять, что означает каждый элемент данных, однако этот формат не очень удобен, когда дело доходит до написания кода для анализа данных и извлечения отдельных полей.

Большое преимущество реляционных технологий корпоративного класса состоит в том, что они позволяют не только масштабировать объем данных и мощность обработки, но и надежно управлять ресурсами, чтобы справиться с широким разнообразием требований, предъявляемых к данным в крупной организации. Это важно, поскольку наряду с операционной аналитикой в режиме реального времени нужно будет осуществлять масштабную пакетную обработку, выполнять запросы для создания отчетности и многое другое. Без управления ресурсами такая смешанная рабочая нагрузка создаст серьезную проблему.
Концепцию смешанной рабочей нагрузки можно представить в виде транспортного затора, когда грузовики, легковые автомобили, мотоциклы, спецмашины, фургоны и т. д. соперничают между собой за полосы движения. В базах данных вместо разных типов транспортных средств поступают запросы разных типов, разных размеров и с разными приоритетами. Если не регулировать потоки этих запросов, система перестанет с ними справляться и возникнет «пробка». В то же время надежная подсистема управления ресурсами организует все запросы по их приоритетности и объему ресурсов: выделяются полосы для спецтранспорта, платные полосы для тех, кто нуждается в привилегиях, и т. п. В результате каждому предоставляются наилучшие условия. Хорошая подсистема управления ресурсами позволяет многим пользователям и процессам эффективно использовать систему совместно.
Главная опора операционной аналитики
Реляционная опора обычно является лучшим местом для развертывания операционной аналитики. С учетом ее масштабируемости по всем необходимым параметрам, а также ее способности легко интегрироваться почти со всеми корпоративными приложениями реляционная технология играет важную роль в превращении традиционной аналитики в операционную.
Реляционные технологии корпоративного класса поддерживают массовый параллелизм и обладают возможностями по обеспечению строгой безопасности. Другими словами, системы могут жестко контролировать, кто и к каким данным имеет доступ, а также позволяют многим пользователям одновременно получать доступ к одним и тем же данным. Другие преимущества реляционных систем: доступность, надежность, восстанавливаемость и управляемость. Эти свойства приобретают важнейшее значение, когда, скажем, сотни сотрудников колл-центра плюс тысячи сотрудников на местах, плюс тысячи сотрудников в штаб-квартире нуждаются в доступе к одной и той же информации. Большинство приложений, которые сегодня используются крупными организациями, предназначены для работы с реляционным сервером баз данных, что еще повышает привлекательность реляционных технологий и легкость их интеграции.
Подведем итог: именно на реляционной опоре организации обычно стремятся развернуть операционно-аналитические процессы. Именно на реляционную технологию, благодаря ее возможностям масштабирования, опирается организация, когда наступает время превратить традиционную аналитику в операционную.
Опора для обнаружения данных
В последнее время немало внимания на рынке привлекает идея добавления к единому аналитическому окружению платформы для обнаружения данных. Обнаружение данных не является новой концепцией как таковой, и большинство организаций уже имеют для этого то или иное окружение. Классическое автономное окружение, в котором специалисты-аналитики годами разрабатывали новые виды аналитики, также является формой для обнаружения данных. Отличие состоит в том, что классическое аналитическое окружение редко когда интегрируется с другими корпоративными системами и, как правило, не масштабируется. Настало время оставить эти устаревшие архитектуры в прошлом. Сегодня для процессов обнаружения данных часто используются такие инструменты, как SAS, IBM SPSS и R. Каждый из них может быть использован в рамках интегрированной платформы для обнаружения данных, а не только в рамках автономного окружения.
Следует заметить, что не так давно изменился способ применения аналитических инструментов. Они гораздо плотнее интегрируются с масштабируемыми платформами, которые являются частью корпоративного аналитического окружения. И реляционные технологии, и Hadoop позволяют перейти от автономного изолированного обнаружения данных к платформам для обнаружения данных. Эти платформы являются частью единого корпоративного аналитического окружения.
Платформы для обнаружения данных выходят за пределы аналитической «песочницы» – изолированной программной среды, которая давно уже встраивалась в другие платформы. Аналитическая «песочница» производит логическое разделение большой операционной системы, что дает специалистам-аналитикам возможность не только запрашивать, но и загружать и создавать данные. Она позволяет осуществлять быстрое исследование и моделирование аналитических процессов в нужном масштабе благодаря использованию самых масштабируемых платформ, которые только есть у организации. Недавно такие «песочницы» стали очень популярны в окружении хранилищ реляционных данных. Хотя окружение для обнаружения данных также может содержать аналитические «песочницы», но оно представляет собой нечто большее.
Сегодня платформы для обнаружения данных, которые являются второй опорой единого аналитического окружения, позволяют смешивание и сопоставление всех типов данных, как структурированных, так и нет. Такая платформа должна поддерживать и реляционную, и нереляционную обработку. Она также должна поддерживать практически любой вид аналитической методологии или подхода. Это означает, что она должна поддерживать не только традиционные методы статистики и прогнозирования, но и текстовый анализ (имейлов, документов и т. д.), анализ объектных графов (взаимных связей между людьми, местностями или объектами), геопространственный анализ (пространственных отношений) и многое другое. На рис. 5.4 проиллюстрировано, как платформа для обнаружения данных комбинирует и упрощает обработку аналитики.
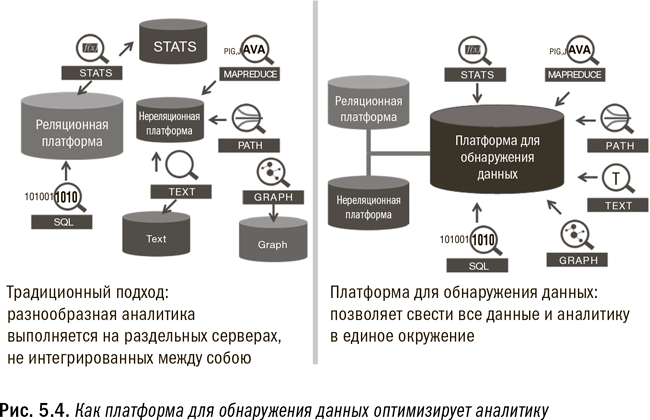
Важная особенность окружения для поиска данных – здесь действуют крайне слабые правила и ограничения. Такие платформы для обнаружения данных, как Teradata Aster и Pivotal Greenplum, не только предоставляют собственные аналитические алгоритмы, но и поддерживают использование общих аналитических инструментов, таких как SAS, SPSS или R. Они также идеально подходят для применения в инновационных центрах. Поисковая платформа может быть встроена или нет в окончательный операционно-аналитический процесс. Разумеется, она используется для обнаружения и определения аналитического процесса, который стоит внедрения. Но как только детализированная аналитическая логика, необходимая для выполнения поиска, определена, ее можно встраивать в процесс обработки напрямую, без использования поисковой платформы. Это происходит благодаря тому, что зачастую можно существенно упростить и оптимизировать аналитический процесс при переходе от фазы обнаружения к фазе обработки. Подробнее об этом мы поговорим в шестой главе.
Ищите инсайты быстрее, чем производите обработку
Поисковая платформа должна быть гибкой и дружественной к пользователям, чтобы ускорить процесс поиска новых инсайтов. Ее необходимо оценивать по другим критериям, чем операционные платформы, например по времени инсайта. Скорость обработки и масштабируемость не так важны для процесса обнаружения данных, как гибкость и простота использования.
В некоторых случаях для поиска данных можно использовать реляционные и нереляционные платформы без добавления отдельной платформы. При этом важно располагать окружением, предназначенным для обнаружения данных. Независимо от того, как она применяется, поисковая платформа должна быть конфигурирована иначе, чем операционные системы. Попытка вести поиск в рамках типичной операционной системы с ее ограничениями – заведомо проигрышный подход. Процесс поиска нуждается в гибкости, чтобы пересчитывать данные, изменять по желанию их расположение, тасовать их и проводить с ними многочисленные эксперименты. В условиях, когда необходимо соблюдать правила операционных процессов, такая свобода попросту невозможна. Ее обеспечивает окружение для поиска данных.
Другой важный момент состоит в том, что поисковая платформа позволяет как можно быстрее найти новые инсайты. Такую платформу не нацеливают на обеспечение максимальной производительности или масштабируемости, хотя это будет не лишним. Производительность и масштабируемость важны для операционного процесса, но далеко не так важны для поискового процесса. Важнее всего при создании моделей и исследовании новой аналитики как можно быстрее провести эксперимент полного цикла. Это возвращает нас к концепции времени инсайта, о которой мы говорили в четвертой главе. Время на программирование и тестирование нового процесса может намного превысить время обработки, необходимое для выполнения программы, вот почему так важно располагать поисковым окружением, позволяющим легко комбинировать данные, управлять алгоритмами и подтверждать новый инсайт. А об операционной производительности и масштабируемости следует беспокоиться уже после того, как вы обнаружили нечто и доказали, что работа с ним стоит усилий. Более подробно об этом мы поговорим в шестой главе.
Нереляционная опора
Сегодня на рынке доступно широкое разнообразие нереляционных платформ. Hadoop быстро стала среди них самой популярной, а в аналитическом окружении – постоянным его компонентом. Нереляционные платформы не требуют, чтобы данные хранились в каком-либо конкретном формате, и наряду с базовым языком SQL используют различные языки программирования для взаимодействия с данными. Hadoop приобрела популярность благодаря своей способности работать с неструктурированными или слабоструктурированными данными, настолько распространившимися в мире больших данных. В действительности все данные имеют какую-либо структуру. Неструктурированными обычно называют данные, находящиеся в сложных форматах, которые не так легко конвертировать в пригодную для аналитики форму. Например, это текстовые, видео– и аудиофайлы. Другой распространенный тип – это слабоструктурированные данные, находящиеся посредине между структурированными и неструктурированными данными. Примеры включают многие журнальные файлы, такие как блоги, сенсорные данные или данные в формате JSON, о чем мы говорили выше в этой главе. Слабоструктурированные данные имеют определенные величины, но необязательно в установленном порядке или простом формате.
Hadoop особенно хорошо справляется с такими типами данных. Имея открытый исходный код и потому будучи бесплатной, Hadoop также позволяет свободно экспериментировать при небольших затратах. Кроме того, такие поставщики, как Cloudera, Hortonworks и MapR, предлагают коммерческие версии Hadoop, а Teradata, IBM и Oracle – приложения к Hadoop. Все эти предложения добавляют ценные свойства к открытому исходному коду.
Между Hadoop и реляционной технологией существует ряд важных отличий, связанных с тем, что для загрузки файлов с данными на эту платформу требуется только разместить их в файловой системе. Причем для загрузки не требуются никакие специфические форматы или структуры данных. Поскольку Hadoop не имеет никаких установок касательно хранимых файлов с данными, то она не предусматривает и никаких особых способов обращения с тем или иным типом данных.
Отсутствие требований к формату означает, что на эту платформу можно загружать тексты, фото, изображения, данные журнала событий, сенсорные данные или данные любого другого типа по мере их поступления, а затем обрабатывать их в параллельном режиме. В этом и состоит отличие от реляционной технологии, для которой данные по умолчанию должны быть представлены в виде таблиц. Несмотря на то что данные с такой реляционной структурой могут быть помещены в Hadoop, работа с ними – не самая сильная сторона этой платформы. На деле же, когда необходимы стандартные реляционные операции, работать с Hadoop будет гораздо сложнее и медленнее, чем с реляционной технологией корпоративного класса. Причина в том, что стандартные базы данных имеют все необходимые инструменты и функции, предназначенные для работы с реляционными данными, а Hadoop – нет. Hadoop предлагает бóльшую гибкость в отношении формата данных, но за счет утраты специализированных функций для обращения с конкретным форматом.
Одна из причин использовать Hadoop заключается в том, что данные неравноценны по своей природе. Например, данные об операциях по текущим банковским счетам отражают реальный факт перемещения денег, тогда как пост на Twitter – всего лишь чье-то мнение. Твиты далеко не так ценны, как сведения о финансовых транзакциях, поэтому нет смысла хранить их в дорогостоящей системе, где они скорее всего редко будут использоваться. Hadoop же позволяет организациям хранить малоценные данные на тот случай, если вдруг они пригодятся. Также в ней можно хранить необработанные лог-файлы, из которых извлечены фрагменты с важной информацией. Благодаря архивированию необработанных файлов в Hadoop всегда можно вернуться к ним позже и извлечь из них дополнительную информацию, если в ней возникнет необходимость. Использование Hadoop для целей архивирования похоже на непрерывное резервное копирование файлов с последующим легким к ним доступом – вместо неудобной заправки ленты. Наконец, архивирование необработанных данных может очень пригодиться в случае аудиторских проверок или возникновения юридических вопросов.
Hadoop можно сравнить с аффинажным заводом по переработке железорудного сырья. Здесь скальную породу, содержащую руду, загружают в плавильную печь, где породу перемалывают, нагревают и переплавляют в железные слитки, отделяя отходы. Hadoop работает точно так же: собирает большие объемы твитов, перерабатывает их при помощи инструментов текстового анализа и выплавляет из терабайтов мнений гораздо меньшие по размеру (и гораздо более ценные!) подборки информации, скажем, о покупательских предпочтениях или трендах. Затем эти железные слитки (аналитические результаты) передаются в производственную систему (реляционное окружение), где им придается еще большая ценность в виде металлопроката, балок и другой готовой продукции. Сегодня, благодаря низкой стоимости хранения малоценных данных, можно хранить гораздо бо́льшие объемы, чем в прошлом.
Hadoop становится первоначальным хранилищем для многих источников данных. Кроме того, она может быть использована для очистки и обработки данных, как было описано выше, чтобы сделать их пригодными для дальнейшего применения в аналитических целях. Например, текстовые данные из имейлов, отзывов клиентов или постов в социальных сетях не очень полезны в необработанном формате. Чтобы извлечь из таких текстовых данных полезную информацию, к ним необходимо применить алгоритмы текстового анализа. Скажем, ценная информация включает знание того, кто разместил пост в социальных сетях, является ли его тональность положительной, о каких продуктах идет речь и т. д. Hadoop идеально подходит для процессов, предназначенных извлекать такую информацию из текста, поскольку она позволяет осуществлять параллельный анализ текста. Затем уже структурированные данные, извлеченные из текста, можно включать в аналитический процесс.
Среди недостатков Hadoop – потребность тщательно следить за тем, чтобы при программировании в параллельном окружении создавался правильный ответ. Многие выкладки, которые просты для выполнения в однопотоковом окружении, требуют совершенно другого подхода в параллельных системах. Существуют два типа параллелизма: на уровне узлов или исполняемых модулей и на уровне системы. Параллелизм на уровне узлов заключается в простом выполнении одной и той же программы на каждом узле. Узлы не взаимодействуют между собой и не обмениваются информацией. Гораздо сложнее параллелизм на уровне системы, поскольку он предполагает координацию работы всех узлов и обмен информацией между ними для получения правильного результата. Таким образом, программисты должны быть внимательны при написании программы, с тем чтобы она соответствовала уровню параллелизма, который требуется для выполнения данной задачи.
Любые данные, в любом формате, любого объема
Способность Hadoop работать с любыми объемами данных в любом формате делает ее важной опорой единого аналитического окружения.
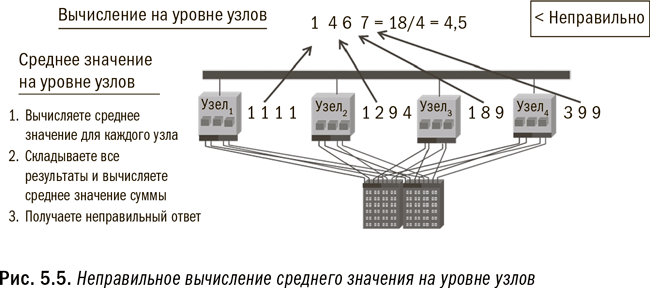
Например, вы не можете получить среднее значение, применяя процесс на уровне узлов или исполняемого модуля, поскольку каждый модуль сначала вычислит среднее значение на основе имеющихся у него данных, а затем сообщит вам свое среднее значение. Но, как вы помните из курса введения в статистику, вычисление среднего значения из средних значений не даст вам искомого правильного ответа. Вам нужно подсчитать общую сумму, чтобы затем вычислить общее среднее значение. (В качестве иллюстрации см. рис. 5.5 и 5.6.) Для обеспечения точности вычислений в Hadoop программисты должны заложить в программу надлежащий уровень параллелизма. В противоположность этому параллельное реляционное окружение построено таким образом, что параллелизм на уровне системы является в ней стандартом.
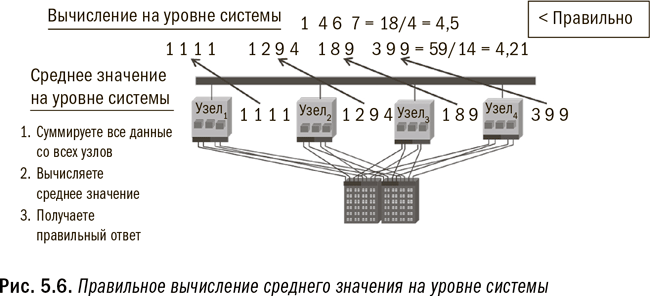
Сегодня на рынок приходят пакеты, дополняющие Hadoop синтаксисом наподобие SQL или даже методологией извлечения данных. Однако эти варианты все еще не являются настолько надежными, чтобы удовлетворять требованиям крупных организаций. Это возвращает нас к необходимости использовать каждую платформу в соответствии с ее назначением. Как указывалось в четвертой главе, с некоторыми задачами Hadoop справляется лучше других опций, но есть и задачи, где она проявляет себя неважно.
Как узнать, какой тип обработки подходит для Hadoop? Простейший тест должен определить: могут или нет ваши вычисления осуществляться параллельно и независимо друг от друга на отдельных узлах? Если независимая обработка подмножества данных каждого исполняемого модуля даст вам такой же ответ, как и обработка всего массива данных в одной большой системе, то Hadoop подойдет для таких вычислений. На рис. 5.5 и 5.6 проиллюстрированы примеры неправильного и правильного ее применения. Если же вы хотите узнать средний объем продаж по каждому отдельному потребителю, ответ будет правильным при условии, что все данные по каждому потребителю хранятся в одном модуле. Но если для получения ответа требуется передача данных между модулями, то, чтобы получить такой же ответ, как если бы все данные обрабатывались разом, Hadoop придется очень постараться. Разумеется, я чрезмерно упрощаю ситуацию, из которой имеются свои исключения, но эта рекомендация во многих случаях поможет вам выбрать правильное направление.
Еще один способ определить, насколько Hadoop подходит для управления алгоритмом, – это узнать, какого типа обработки, последовательной или непоследовательной, требует алгоритм. В реляционных системах SQL получает отвечающий комплект и шаги для прохождения каждой колонки цифр по маршруту, применяя к каждой записи заданные функции. SQL плохо справляется с задачами, когда для обработки необходимо перепрыгивать от колонки к колонке и от итерации к итерации (часто на основе результатов предыдущей итерации). Hadoop же использует такие языки программирования, как Java, Python или C++, которые лучше подходят для сложного управления данными, поскольку в этом случае не требуется последовательной построчной обработки.
Одна из интересных особенностей, связанных с использованием в Hadoop языков C++, Java и Python, состоит в том, что Hadoop не столько создает новые функции, сколько расширяет возможности масштабирования существующей функциональности. Любая программа, написанная сегодня на Java для Hadoop, могла быть написана несколько лет назад и реализована в традиционной однопоточной системе. Пусть используемый язык и не нов, зато ново окружение, где он применяется, что в огромной степени масштабирует применение Java.
Подведем итог: Hadoop в ее нынешнем виде лучше всего подходит для начального хранения данных из крупных источников и для начальных уточнения и обработки этих данных. Также Hadoop стоит использовать для хранения малоценных или нечасто используемых данных. Наконец, Hadoop замечательно подходит для архивирования. Однако в ближайшем будущем большинство организаций редко когда смогут использовать Hadoop для поддержки операционно-аналитических процессов в режиме реального времени.
Вспомогательные технологии
Вспомогательные технологии могут быть добавлены к единому аналитическому окружению с целью поддержки его опор. Эти вспомогательные технологии предназначены для специфических типов обработки или аналитики, являются гораздо более специализированными и применимы только в определенных случаях. Технологии, которые мы рассмотрим в этом разделе, будут продолжать развиваться, и со временем их список может расшириться. Также вполне возможно, что предлагаемая этими технологиями функциональность в конечном итоге будет встроена в одну или несколько опор и добавления вспомогательных компонентов не потребуется. Давайте рассмотрим некоторые из наиболее распространенных вспомогательных технологий по состоянию на начало 2014 г.
Технологии аналитики в памяти
Технологии аналитики в памяти загружают данные непосредственно в большой пул памяти, а затем приводят в действие сложные алгоритмы. Такие технологии стоят дорого ввиду необходимости иметь большой объем памяти, зато их производительность невероятно высока. Подход «вычисления в памяти» особенно эффективен в тех случаях, когда необходимо продолжать выстраивать и перестраивать большое количество сложных моделей. SAS предлагает устройство для аналитики в памяти вместе с несколькими различными платформами.
Сегодня распространено применение аналитики в памяти к моделям оценки риска в крупных финансовых учреждениях – им может требоваться обновление моделей риска для тысяч разных сценариев и ценных бумаг по крайней мере на ежедневной основе при принятии решений об инвестициях и хеджировании рисков.
Устройства на основе графических процессоров
Устройства на основе графических процессоров (Graphics Processing Units, GPU) предназначены для решения другого типа задач, нежели устройства для аналитики в памяти. Индивидуальный GPU поддерживает масштабную вычислительную обработку, но не обязательно работу с большими массивами данных. При применении GPU к аналитическим процессам заимствуется технология, изначально разработанная для создания сложной компьютерной графики на персональных компьютерах. GPU управляют монитором ПК путем применения сотен и даже тысяч слабых процессоров к массиву данных. Обработка миллионов пикселей для видеоигры требует огромной параллельной обработки. Хотя GPU уступают в скорости и надежности серийным микропроцессорам, они могут быть использованы для сжатия математических данных. Устройства на основе GPU предлагает, например, компания Fuzzy Logix.
Среди областей применения обработки с помощью GPU – моделирование методом Монте-Карло, когда исследуются миллионы и даже миллиарды возможных сценариев. Люди часто прибегают к моделированию методом Монте-Карло (хотя и не в масштабе, требующем применения GPU) при планировании выхода на пенсию. При оценке пенсионных накоплений различные показатели, такие как ставки доходности и темпы инфляции, пропускаются через широкий спектр возможных ставок, чтобы определить, сколько денег будет накоплено к указанной дате выхода на пенсию. По завершении моделирования подводится итог: сколько сценариев приведут к успеху и сколько к провалу.
Поскольку каждый из различных факторов варьируется в широком спектре возможных ставок, то для этого требуется большое количество вычислений. GPU хорошо справляются с такого рода сценариями в производственном масштабе. Вместо простого применения метода Монте-Карло к пенсионным накоплениям финансовые учреждения используют его для очень сложного моделирования рисков в текущем режиме. Так что в ближайшие годы можно ожидать более частого применения GPU в аналитике.
Дополнительная поддержка доступна
Вспомогательные технологии, предназначенные для решения конкретных задач, помогают организации при превращении традиционной аналитики в операционную. Со временем функционал этих технологий может быть включен в основные опоры аналитического окружения. Но пока этого не произошло, пробел может быть заполнен специализированными устройствами или продуктами на основе программного обеспечения.
Технологии для обработки сложных событий
Обработка сложных событий (Complex Event Processing, CEP) используется для анализа потоковых данных в режиме реального времени. CEP следует подходу, отличающемуся от используемых в традиционных аналитических процессах. При обработке потока данных по технологии CEP цель состоит не в соотнесении их с другими данными организации, а в определении того, что происходит прямо сейчас в потоке данных, с целью выявить сигналы, которые требуют немедленного реагирования. Требуемые для CEP обработка данных и управление ими отличаются от типичных аналитических процессов и нуждаются в несколько иных технологиях.
Одно из ключевых отличий между CEP и другими видами аналитики состоит в том, что CEP буквально рассматривает данные еще даже до того, как они помещаются в хранилище. Другими словами, процессы CEP применяется к данным во время их перемещения из источника к месту хранения. Это позволяет максимально быстро реагировать на сигналы, как только они появляются в данных. Среди поставщиков в этой области можно назвать компании TIBCO и Informatica.
CEP может быть использована, например, для выявления мошеннических действий на веб-сайте во время их развертывания, не дожидаясь выполнения других процессов, идентифицирующих мошенничество. Также она может быть использована для мониторинга данных, поступающих с датчиков двигателя, чтобы максимально быстро выявлять ранние признаки проблем. CEP не заменяет, а дополняет типичные аналитические процессы. С учетом природы CEP ее обычно применяют в высокодинамичном окружении.
Встроенные аналитические библиотеки
Набирает популярность тренд встраивать в реляционные или нереляционные платформы аналитические алгоритмы с тем, чтобы их можно было легко добавлять в аналитические процессы. В отличие от ситуации всего несколько лет назад, сегодня появилась возможность встраивать непосредственно в процессы и приложения даже алгоритмы статистического моделирования, прогнозирования и машинного обучения.
Встроенные аналитические библиотеки помогают реализовать потенциал операционной аналитики благодаря тому, что обеспечивают доступ к аналитическим функциям независимо от пользовательского интерфейса или конкретного приложения. Другими словами, не нужно использовать аналитический инструмент в качестве части процесса, поскольку платформа может непосредственно выполнять аналитику. Недостатком таких встроенных функций является то, что они не снабжаются пользовательским интерфейсом. Это просто функции, что означает: выходные данные будут представляться в виде таблиц или файлов, а не красиво отформатированных отчетов. Выходные данные, создаваемые таким образом, хорошо подходят для использования в других приложениях и процессах, но работать с ними нелегко. Программный продукт, доступный для использования на разных платформах, предлагает компания Fuzzy Logix.
Аналитический инструмент или платформа?
По мере того как аналитические функции все глубже интегрируются в аналитические платформы, границы между инструментами и платформами размываются. Когда алгоритмы выполняются полностью в рамках платформы посредством встроенной функции, это позволяет обеспечить максимальное масштабирование.
Я думаю, что в будущем специалисты-аналитики будут использовать традиционные аналитические инструменты с графическими пользовательскими интерфейсами для обнаружения данных, разработки и тестирования аналитических процессов. Определив, какие процессы должны быть переведены в разряд операционных, они затем переключатся на использование встроенных алгоритмических функций для операционализации этих процессов. Со встроенными функциями не так легко работать, как с пользовательскими интерфейсами, но когда пользователи точно знают, что должно быть включено в окончательный аналитический процесс, функции не потребуют много дополнительной работы. Такой подход позволяет использовать гибкий и дружественный к пользователям набор инструментов для обнаружения данных и развития процессов, а также использовать преимущества встроенных родных функций для применения в производственном масштабе.
Использование
Теперь, когда мы определили основные компоненты единого аналитического окружения предприятия, давайте рассмотрим несколько важных тем, связанных с максимизацией выгод, которые обеспечивает окружение.
Любой анализ любых данных в любое время
Вашей целью должно быть создание единого аналитического окружения, которое позволит осуществлять анализ данных любого типа и объема посредством любого аналитического метода в любое время. Именно так. Крайне важна способность анализировать текстовые данные, генерировать социальные графы, прогнозировать реакцию, а затем объединять эти результаты с историей клиента и другой информацией. Однако добавление многочисленных опор имеет смысл только в том случае, если организация планирует использовать эти опоры. Некоторые организации с минимальными потребностями в аналитике какое-то время могут обойтись одной опорой. В то же время большинство крупных организаций найдут необходимым использовать многочисленные опоры вкупе со вспомогательными технологиями.
Решение о добавлении компонентов в аналитическое окружение должно быть основано на анализе затрат и доходов, который принимает во внимание, сколько данных потребуется дублировать на новую платформу, сколько будет стоить синхронизация данных и обучение пользователей новым навыкам, обладает ли новая платформа необходимыми характеристиками для операционного масштабирования и многое другое. Бежать покупать новейшую сверкающую игрушку только потому, что она появилась в продаже, – пустая затея.
После того как опоры будут установлены на место, уже не составит труда оптимизировать их использование и распространить данные и аналитические процессы в масштабах всего аналитического окружения организации. Самая большая проблема состоит в том, чтобы обосновать необходимость добавления новый опоры или вспомогательной технологии в аналитическое окружение (подробнее об этом в четвертой главе). Причина очевидна: гораздо дешевле использовать нечто, уже занявшее свое место, чем ставить на это место нечто новое.
Таким образом, для того чтобы организация смогла осуществлять любой необходимый ей анализ данных любого типа и в любое время, она должна сначала установить на свое место опоры. Стоит проводить периодический (возможно, ежегодный) обзор базовых опор или вспомогательных технологий, которые организация еще не внедрила. Возможно, в ходе очередного обзора вы придете к выводу о необходимости разработки бизнес-кейса с целью добавления недостающего компонента в окружение. Если потребности организации в операционной аналитике понуждают к установке новой опоры, организации следует ее добавить, поскольку это увеличит гибкость и функциональность при построении аналитических процессов.
Конечных пользователей не должно волновать, где хранятся данные
Суть в том, что конечных пользователей, будь то профессиональные аналитики или пользователи традиционной бизнес-аналитики, менее всего волнует, где хранятся данные, потребные им для анализа. Пользователям нужен свободный доступ к данным и возможность создавать и реализовывать любые необходимые им аналитические процессы с максимальной легкостью и с достаточной производительностью. Например, подборки сведений о клиентах, таких как демографические данные, представлены в виде таблиц в реляционном окружении или в виде файлов в нереляционном окружении? Пользователям это безразлично, были бы обеспечены доступ, свободное использование и производительность, желаемые пользователями.
Сосредоточьтесь на том, чего желают пользователи
Пользователям безразлично, где хранятся данные или на каких опорах выполняется аналитика. Им просто нужен доступ к любым данным для любого вида анализа в любое время. Чем меньше пользователи вынуждены думать о физических местах хранения и анализа данных, тем эффективнее они могут действовать.
Поставщики сейчас усиленно работают над тем, чтобы сделать несоизмеримые опоры единого аналитического окружения тесно интегрированными, если не практически прозрачными для пользователей. Они встраивают в них коннекторы, которые позволяют пользователям, работающим на одной платформе, получать свободный доступ к данным на другой платформе. Благодаря этому пользователи могут сосредоточиться на логике аналитического процесса, не беспокоясь о том, где физически находятся данные. На практике это означает, что работающий в реляционной среде пользователь может видеть данные в виде таблицы, тогда как на самом деле они хранятся в виде файла в нереляционной среде. Когда поступает запрос на эти данные, они извлекаются из нереляционного хранилища и передаются на реляционную платформу для обработки запроса. Пользователи не знают о происходящем, да им оно и не важно, пока поддерживается производительность. Если же производительность страдает, системные администраторы могут перенести данные из файла, хранящегося в нереляционном окружении, в реляционную таблицу, чтобы не требовалось осуществлять преобразование данных. И, наоборот, данные из реляционной таблицы могут быть перемещены в нереляционный файл, если общие требования к обработке обусловливают это место как лучшее для хранения данных. В общем, любую часть данных можно разместить на хранение туда, где они будут наиболее пригодны для использования.
При выборе решений для корпоративной аналитической среды важно оценивать как текущие возможности, так и долгосрочные планы поставщиков по добавлению продуктов к единому аналитическому окружению. С одной стороны, не нужно откладывать решение в ожидании следующего поколения продуктов с незначительной дополнительной функциональностью. С другой стороны, не стоит игнорировать долгосрочные дорожные карты продуктов, которые вы планируете приобрести. Технологии меняются быстро, и разные поставщики могут идти разными путями. Вы можете найти двух поставщиков с эквивалентными предложениями для удовлетворения ваших сегодняшних потребностей, но их дорожные карты могут существенно разниться, так что в перспективе один из них способен значительно превзойти другого.
Как насчет облака?
Читатели, безусловно, знакомы с концепцией облака и облачных архитектур, поэтому я не стану давать здесь базовых определений, а остановлюсь на нескольких ключевых моментах, важных в контексте нашего разговора об операционной аналитике. Меня часто спрашивают по поводу использования облака для аналитических процессов, как операционных, так и неоперационных. Чтобы ответить на этот вопрос, важно провести различие между облачными архитектурами и облачными услугами.
Организации могут внедрить облачную архитектуру на собственном оборудовании под защитой своих брандмауэров. Это частное облако позволит обеспечить эффективное совместное использование ресурсов без какого-либо внешнего вмешательства и потери контроля над данными. Другой вариант – аренда пространства на общедоступном облаке у внешнего поставщика облачных услуг. В этом случае организация платит поставщику только за используемые ею оборудование и ресурсы (включая маржу прибыли для поставщика).
Для малого бизнеса или исследователей, которые обычно используют лишь небольшую часть ресурсов сервера, общедоступное облако может быть очень выгодным вариантом, даже несмотря на надбавку к цене со стороны поставщика. У крупных же организаций, использующих большие данные и операционную аналитику, обычно так много пользователей, использующих так много данных, что общедоступное облако в конечном счете может обойтись им гораздо дороже, чем частное. Например, если организация использует вычислительную мощность 20 серверов практически беспрерывно, то аренда ресурсов обойдется ей намного дороже, чем владение собственными. Кроме того, использование общедоступного облака для уязвимых данных поднимает вопросы, связанные с безопасностью и соблюдением конфиденциальности. Эти вопросы могут носить правовой характер или же касаться восприятия: так, многие потребители могут чувствовать себя некомфортно, если компания будет хранить их персональные данные на общедоступном облаке.
Использовать облако или нет?
Частное облачное окружение – это чрезвычайно мощная и экономически эффективная архитектура, к которой прибегнут многие организации. Общедоступные облака могут оказаться дорогостоящими для крупных организаций, поэтому вряд ли будут широко использоваться для целей операционной аналитики, как это сегодня рекламируется на рынке. Все опоры и вспомогательные технологии, рассмотренные нами в этой главе, могут работать в облачной архитектуре.
Сегодня многие поставщики предлагают аналитику в виде сервисных пакетов на базе общедоступного облака. Эти приложения позволяют пользователям создавать и осуществлять аналитические процессы с помощью инструментов, которые предлагаются по подписке или на основе платы по мере пользования. Многие, но не все, аналитические сервисные продукты могут быть юридически закреплены за организацией и присоединены к частному облаку. Прежде чем тратить время на оценку конкретного аналитического метода в качестве сервисного продукта, убедитесь в том, что он подходит для вашего запланированного окружения. Например, если вашей организации не разрешено использовать общедоступные облака, вряд ли имеет смысл рассматривать продукты, доступные только там.
Частное и безопасное облачное окружение способно обеспечить гибкость, необходимую для превращения аналитики в операционную, а также хорошую рентабельность. Вместо того чтобы иметь на 15 отделов один сервер, который к тому же часто простаивает или недостаточно используется, можно иметь пять серверов, которые с лихвой удовлетворят потребности всех отделов. Это позволит снизить затраты на обслуживание и административные накладные расходы. В ближайшие несколько лет внутренние частные облачные архитектуры получат широкое распространение повсеместно и будут применяться для поддержки многих операционно-аналитических процессов.
Что же касается общедоступных облаков и аналитики в качестве предложений сервиса, то они в основном будут привлекать малый и средний бизнес, а также крупные организации для исследований на начальных этапах.
Подведем итоги
Наиболее важные положения этой главы:
• Превращение традиционной аналитики в операционную – это не технологическая проблема для большинства организаций. Проблемы с технологиями являются симптомами фундаментальных проблем с корпоративной политикой или культурой.
• Новые технологии, например Hadoop, не заменяют ранее существовавшие технологии, такие как реляционные базы данных, а дополняют их.
• Аналитическое окружение развивается, объединяя много платформ разной мощности, каждая их которых предназначена для решения разных задач.
• Не откладывайте решение об инвестициях в ожидании выхода новых продуктов с новыми функциями, если только эти функции не имеют для вас крайне важного значения.
• Компьютинг на основе текстуры ведет к созданию единого аналитического окружения, которое включает множество взаимосвязанных, масштабируемых и интегрированных компонентов.
• Современное единое аналитическое окружение покоится на трех основных опорах и ряде вспомогательных технологий. Цель его – позволить осуществлять любой тип анализа с использованием любых данных любого типа и объема в любое время.
• Реляционная опора является основой для развертывания операционной аналитики и обеспечивает масштабируемость по всем ключевым для организации параметрам.
• Опора для обнаружения данных предназначена для исследования всех видов данных при помощи любых аналитических методов и призвана быстро обеспечивать нахождение новых инсайтов, а не максимальную скорость обработки.
• Нереляционная опора (как правило, Hadoop) превосходно подходит для работы с нетрадиционными форматами данных, для хранения малоценных и редко используемых данных, а также для целей архивирования.
• Вспомогательные технологии, позволяющие применять специфические типы обработки, включают технологии аналитики в памяти, технологии на основе графических процессоров, встроенные аналитические библиотеки и технологии обработки сложных событий.
• Пользователи не желают знать, где физически находятся данные или что именно их обрабатывает. Единое аналитическое окружение развивается, так что пользователям не придется больше беспокоиться насчет этих вопросов.
• Облачные архитектуры могут быть использованы в едином аналитическом окружении. Для большинства крупных организаций частные облака будут предпочтительнее публичных.
Назад: Глава 4 Хотите бюджет? Разработайте бизнес-кейс!
Дальше: Глава 6 Управление и конфиденциальность

