Книга: Революция в аналитике. Как в эпоху Big Data улучшить ваш бизнес с помощью операционной аналитики
Назад: Глава 1 Постигаем операционную аналитику
Дальше: Глава 3 Операционная аналитика в действии
Глава 2
Больше данных… Еще больше данных… Большие данные!
В этой главе мы рассмотрим важный тренд, связанный с большими данными. Читатели должны в нем разбираться, если в их организациях планируется использовать большие данные для поддержки операционной аналитики. Разумеется, организации всегда собирали данные о своей деятельности, однако в последние годы темпы накопления возросли. И не только потому, что увеличились и источники данных. Дело в том, что зачастую данные поступают в новых форматах и содержат информацию, требующую различных аналитических технологий. Таким образом, «большие данные» – это общий термин, который применяется ко всему тренду, приведшему к проблемам в виде увеличения объемов данных, количества их источников и разнообразия форматов.
Когда организация приступает к рассмотрению больших данных и пытается понять, как они повлияют на ее аналитические процессы, она должна учесть ряд важных моментов. В этой главе мы рассмотрим несколько рекламных трюков, сопровождающих большие данные (на эти трюки иногда попадаются организации), а также разберем способы подготовки к внедрению технологий больших данных с учетом перспективы. Большие данные вовсе не так страшны, как может показаться вначале. Понимание того, как большие данные вписываются в общую картину, позволит вам успешно включить их в операционную аналитику.
Разбираемся с обманами
Нет никаких сомнений в том, что большие данные окружены столь же большой рекламной шумихой. Организации должны разобраться с обманами и сосредоточиться на действительно важном, чему может способствовать ряд методов, предложенных в этом разделе. Ни в коем случае мы не намерены преуменьшать важность или ценность больших данных. Наша цель – вернуть большие данные к реальности. Формирование реалистичных ожиданий должно стать первым шагом в процессе работы с большими данными.
Определение больших данных? Не нужно!
Один из первых вопросов, который мне часто задают клиенты: «Что такое большие данные, Билл? Вы можете дать им определение?» По-видимому, оно очень заботит людей. Чтобы убедиться в этом воочию, посетите некоторые группы на LinkedIn, посвященные большим данным. В каждой группе вы столкнетесь с вопросом определения больших данных, который задается в той или иной форме на протяжении последних нескольких лет. На одном из форумов, где я был вовлечен в дискуссию, размещались не то что десятки, а сотни ответов на вопрос: «Каково определение больших данных?» И это на форуме, где любой пост собирал в лучшем случае пару откликов. По мере развертывания дискуссии ее участники пытались превзойти друг друга, добавляя всё новые нюансы, подходящие или не подходящие к определению. Мне это занятие показалось глупым и заумным.
Люди чересчур озабочены определением больших данных. Лично я всегда предпочитал самое короткое из всех существующих определений. Пусть оно противоречит остальным, зато состоит всего из двух слов: «Не нужно!» Поначалу такой ответ может показаться вам экстремальным. С чего я это взял? Позвольте объясниться.
Если главная задача организации – решить некую бизнес-проблему путем внедрения операционной аналитики, ее не должно волновать определение больших данных. И вот почему. Схема действий, которой должна следовать организация и которой она, вероятно, следовала много лет в прошлом, очень проста. Если у вас есть проблема, требующая решения, вы должны посмотреть вокруг и задать себе вопрос: «Какие данные, если их собрать, организовать и использовать для аналитического процесса, помогут нам решить эту проблему?» Когда вы определите, что это за данные, вы должны придумать, как их собрать, организовать и включить в аналитику. Но тут возникает ключевой момент. Вопрос «Полезны ли эти данные для моего бизнеса?» не имеет абсолютно никакого отношения к определению больших данных. Полезными для бизнеса могут оказаться большие данные, малые данные или же ряд электронных таблиц.
Если же организация придет к пониманию, что ей необходимо использовать нечто похожее на большие данные, то беспокоиться насчет определения будет уже поздно: нужны будут данные как таковые. Они могут быть не очень хорошо структурированными и в переизбытке. Они могут просто соответствовать знаменитой концепции «трех V»: Volume, Variety, Velocity (объем, многообразие, скорость), выведенной исследовательской компанией Gartner. Однако знание того, что нужные вам данные соответствуют концепции «трех V», бесполезно, поскольку в момент, когда данные вам понадобятся, не останется иного выбора, кроме как придумать способ их использования, – и совершенно не важно, являются ли они большими данными. Я всегда считал, что в концепции не хватает самой важной V, которая часто упускается из виду, а именно Value, т. е. ценности больших данных. Можно добавить и прочие характеристики, если веришь, что в данных есть ценность, и считаешь, что усилия по их сбору и анализу того стоят.
Важно не определение, а результат
Даже если бы существовало общепринятое и единственное определение больших данных, это ничем бы не способствовало решению проблем бизнеса. Попытка дать определение большим данным – занятное теоретическое упражнение, но если вы узнáете, что конкретный источник данных официально относится (или нет) к категории больших данных, то в этом не будет никакого проку. Когда потребуется проанализировать источник данных, вам придется найти для этого способ вне зависимости от того, какой ярлык вы к нему прикрепите.
Поймите мои слова правильно. Если организация имеет дело с данными, подпадающими под типичные определения больших данных, это, безусловно, будет влиять на выбор тех методов и инструментов, которые она должна использовать для включения больших данных в аналитические процессы. Однако выбор методов и инструментов относится уже к области тактики, и в этом важное отличие. В первую очередь нужно ответить на стратегический вопрос: «Содержат ли эти данные важную для нас информацию?» Только получив на него положительный ответ, организация может приступить к запуску данных в работу.
Не тратьте силы на попытки понять, относятся ли нужные вам данные к категории больших данных или нет. Лучше сосредоточьтесь на включении выявленных вами значимых источников данных в аналитические процессы организации.
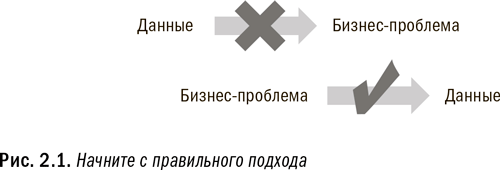
Начните с правильного подхода
Как следует из вышесказанного, важно начать с правильного подхода. Нет смысла собирать данные и хранить их в надежде на то, что однажды им будет найдено полезное применение. Как показано на рис. 2.1, организация должна для начала определить бизнес-проблему, а затем подобрать для нее необходимые данные. Сделайте усилие и примите на себя расходы по приобретению и использованию источника данных, когда это станет необходимо. В мире больших данных очень легко удариться в собирательство всех данных подряд с прицелом на то, что когда-нибудь они пригодятся. В результате организация может настолько увлечься сбором данных, что никогда ими и не воспользуется.
Хотя и кажется очевидным, что нужно начинать с бизнес-проблемы, а не со сбора данных, я знаю множество случаев, когда очень умные и расчетливые в иных отношениях организации полностью забывают про этот принцип, когда дело доходит до больших данных. Поначалу меня очень удивляла подобная склонность, но потом я понял что к чему. К началу 2014 г., когда я пишу эту книгу, вокруг больших данных поднялось столько шумихи, что никто не хочет остаться от них в стороне. Каждый совет директоров спрашивает у своего генерального директора: «А вы используете большие данные?» В свою очередь, каждый генеральный директор спрашивает у своих директоров по информационным технологиям, маркетингу и финансам: «А вы используете большие данные?» И каждый из этих директоров спрашивает у членов своей команды: «А вы используете большие данные?»
Не поддавайтесь давлению!
Не поддавайтесь давлению и не используйте большие данные только ради того, чтобы показать, что вы их используете! Ваша задача – создать системы и наладить сбор данных для поддержки только обоснованных возможностей бизнеса. Многие сильные организации поддались всеобщей лихорадке вокруг больших данных, что грозит обернуться для них весьма поучительными и дорогостоящими уроками.
Никто не хочет отвечать на этот вопрос так: «Еще нет» или так: «Мы планируем их использовать, но сначала хотим выяснить, как лучше это сделать». В обстановке всеобщей лихорадки такие ответы считаются неприемлемыми. В результате организации очертя голову набрасываются на большие данные. Некоторые запускают масштабные, дорогостоящие проекты, не имея продуманного плана насчет того, как извлечь пользу из инвестиций. Они просто собирают множество данных и покупают множество места для их хранения в надежде на то, что когда-нибудь придумают, как их использовать.
В этом и заключается главная проблема такого подхода. В текущем году вы бодро отвечаете на вопросы руководства, а оно вас гладит по головке за то, что вы идете в ногу со временем и «что-то делаете» с большими данными. Но через год-полтора то же начальство обращается к вам уже с другим вопросом: «Вы потратили столько ресурсов на этот проект и что же теперь можете продемонстрировать?» Если вы изначально не знали, для чего вам нужны большие данные, вам потребуется немало усилий, чтобы доказать, что ресурсы потрачены не зря. Я бы не хотел оказаться на месте человека, который вынужден отвечать: «Мы активно занимались большими данными, как от нас того требовали, но пока не получили никаких результатов».
Убедитесь, что ваша организация дисциплинированно подходит к внедрению больших данных. Потратьте еще немного времени на то, чтобы начать с реальной бизнес-проблемы и разработайте для ее решения план. Определите, какую конкретно аналитику можно будет выполнить на основе данных. Это займет не так уж много времени, однако существенно повысит ваши шансы на успех. Не поддавайтесь давлению рекламной шумихи и не отказывайтесь от основных принципов ведения бизнеса.
Существует ли пузырь больших данных?
На фоне сегодняшнего ажиотажа вокруг больших данных часто возникает вопрос о том, а не превращаются ли большие данные в очередной пузырь? В январе 2013 г. исследовательская компания Gartner высказала официальное мнение, что большие данные прошли пик цикла ажиотажа и вступили в этап избавления от иллюзий. После публикации этой статьи мне позвонил журналист и спросил, что я думаю по поводу заката больших данных и пузыря, который вот-вот лопнет. Мой ответ сначала может показаться противоречивым, но после моего объяснения вы поймете, в чем дело. Я ответил, что в некоторых отношениях угроза пузыря больших данных действительно существует. Но с других более важных, точек зрения, такого пузыря нет. Мой ответ кратко изложен в тексте и в таблице 2.1.

Я считаю, что в определенном смысле пузырь больших данных действительно скоро лопнет. Породили же проблему нереалистичные ожидания рынка. Похоже, многие люди считают, что большие данные – это легкий и дешевый способ добыть своего рода «волшебную кнопку», нажав на которую, можно получить ответы на любые вопросы. Это всегда было смешным предположением для любого аналитического начинания. И остается смешным в мире больших данных.
Никакой волшебной кнопки не существует! Для того чтобы успешно разработать и внедрить аналитические процессы для больших данных, требуется ничуть не меньше времени и сил, чем для любых других видов данных. А поначалу может потребовать даже больше времени, поскольку большие данные являются новшеством. Следствием ошибочных предположений, безусловно, станут крайне показательные неудачи с большими данными на рынке. Я уже вижу первые признаки таких провалов. Но, поскольку эти первоначальные неудачи поспособствуют взрыву раздутого пузыря нереалистичных ожиданий, они пойдут всем нам на благо. Ведь добиться успеха при помощи больших данных и сделать их операционными вполне возможно. Но для этого организации необходимо отнестись к большим данным с реалистичными ожиданиями по части затрат, сроков и усилий.
Для больших данных нет «волшебной кнопки»
Совершенно очевидно, что сегодня на преуспевание с большими данными возлагаются необоснованные надежды. В этом смысле пузырь существует. Тем не менее воздействие больших данных и их анализа со временем намного превзойдет сегодняшние раздутые ожидания. Как пузырь доткомов не уничтожил потенциал Интернета, так и пузырь больших данных не уничтожит их потенциала.
Теперь давайте рассмотрим, почему пузырь больших данных не лопнет. Люди часто считают, что взрыв пузыря свидетельствует о том, что его основа была фальшивой. Но вы можете быть уверены в том, что большие данные строятся не на ложной посылке. Большие данные будут оказывать очень сильное влияние на наше будущее. Я воспользуюсь аналогией, чтобы объяснить, почему так произойдет.
Вспомните интернет-пузырь конца 1990-х гг. Из-за этого гигантского пузыря, раздутого интернет-компаниями, многие люди потеряли много денег. Но вот что важно понять. Если вернуться в 1999 или 2000 г., на самый пик ажиотажа вокруг Интернета, и почитать тогдашние статьи о том, как Сеть изменит наши личные жизни и способы ведения бизнеса, то, уверен, вы подметите, что Интернет уже превзошел самые смелые мечты той эпохи.
Видите ли, интернет-пузырь был обусловлен отнюдь не мошеннической природой Сети или ее неспособностью воплотить в жизнь все раздутые обещания того времени. На деле же пузырь возник из-за того, что люди посчитали, что реализовать преимущества Интернета будет очень дешево, быстро и легко. Тогда, для того чтобы привлечь финансирование, компании было достаточно вставить в начале своего названия букву «i» или «e». Это сильно напоминает мне сегодняшнюю ситуацию с большими данными. Если бы в 2013 г. я заявил, что создал компанию в облаке и она будет заниматься большими данными, машинным обучением и предоставлять аналитические услуги, то, вероятно, достаточно быстро собрал бы наличные.
В ближайшие несколько лет произойдут как банкротства, так и консолидация рынка в пространстве больших данных. Неизбежны и разочарования, по мере того как компании, без достаточных на то оснований поспешившие ринуться в большие данные, начнут осознавать свою ошибку. Тем не менее через пять – десять лет большие данные с лихвой воплотят в жизнь все ожидания, с ними связанные. Влияние операционной аналитики на основе больших данных намного превзойдет все сегодняшние предположения. Несмотря на все предостережения, высказанные мной в начале этого раздела, ваша организация не должна оставаться на обочине и буквально обязана войти в мир больших данных. Просто это нужно делать грамотно и рационально.
Готовимся к внедрению больших данных
После того как организация сформирует реалистичные ожидания в отношении больших данных, как ей подготовиться к их внедрению? Какие ключевые моменты необходимо учесть при разработке стратегии? В этом разделе мы сосредоточимся на темах, которые помогут организации подготовиться к внедрению больших данных, после того как она избавится от ажиотажа вокруг них.
Приливная волна больших данных уже нахлынула
Нет никаких сомнений в том, что сегодня на нас обрушивается приливная волна больших данных и что любая организация должна ее укротить, дабы добиться успеха. Этой теме и посвящена моя книга «Укрощение больших данных» (Taming the Big Data Tidal Wave). Я выбрал такое название, поскольку считаю, что океан является очень хорошей аналогией для пространства данных. Представьте себе накатывающие на берег волны. Если вы сидите на резиновой камере в том месте, где волны разбиваются, то узнаете, что волна даже чуть выше талии вполне способна опрокинуть вас на спину. Когда же волны наберут силу, они могут причинить вам осязаемый вред, если вы позволите им обрушиться на вас. Точно так же происходит и с данными. Вырастая в объемах, данные могут вас подавить, и справиться с ними будет нелегко. Если вы позволите волне данных ударить вас, она отправит вас в нокаут и не позволит довести дело до конца.
Вы должны придумать, как оседлать волну. В океане можно использовать доски для серфинга. Те, кто ничего не знает о серфинге, могут подумать, что все доски для него одинаковы. Но это не так. Зайдите в спортивный магазин и увидите, что существуют доски длинные и короткие, разной формы, с плавниками и без них. Серфер выбирает доску в зависимости от того, на каком виде волны он собирается кататься, и в зависимости от своих опыта и целей – гонки на скорость или выполнения трюков.
Аналогичным образом, когда речь идет о данных и аналитике, неосведомленные люди часто предполагают – только и нужно, что нагрести данные, складировать их, а потом проанализировать каким-нибудь инструментом. Но любой специалист знает, что существует огромное разнообразие платформ и инструментов, которые дают доступ к данным и обеспечивают их анализ. Большие данные, несомненно, могут потребовать добавления новых инструментов в уже имеющийся набор, подобно тому как серферу со временем могут понадобиться новые доски. И подобно тому как между использованием различных досок для серфинга существует больше сходства, чем различий, то же верно для применения различных аналитических платформ и инструментов к различным типам данных и аналитики.
Вы готовы оседлать волну больших данных
Если в штате организации имеются опытные специалисты, которые обеспечивали эффективное использование данных в прошлом, они же вполне способны справиться и с большими данными, приложив некоторые усилия. Подобно тому как профессиональный серфер может кататься где угодно и на любой доске, так и профессиональные аналитики могут проанализировать любые данные при помощи любых платформ и инструментов.
Когда организация встает перед необходимостью внедрения новых инструментов для больших данных, ей потребуются и люди, способные пользоваться этими инструментами. Если вы дадите мне лучшую доску для серфинга и отправите меня по самым пологим волнам, я не прокачусь и метра, потому что не умею этого делать. В то же время опытные серферы проявят свое умение, даже если дать им новую доску и отправить на новый пляж, где катят другие по размеру и типу волны, отличающиеся от привычных для них. Поначалу они могут держаться на доске чуть неуклюже, но спустя пару часов будут серфинговать, как обычно, уверенно. Каждая новая доска, каждый новый пляж и каждая непривычная волна представляют собой не квантовый скачок, который невозможно одолеть, а пошаговое изменение. Точно так же опытные аналитики уже имеют базовые навыки, чтобы работать с большими данными, и им просто нужно немного времени, чтобы подстроиться к требованиям других типов данных и анализа. Подобно тому как опытные серферы могут приспособиться к любой доске на любом пляже, так и опытные аналитики могут адаптироваться к любому типу данных и любому типу анализа, поскольку для них это будет пошаговым изменением, а не непреодолимым квантовым скачком.
Именно новая информация придает силу большим данным
Что же делает большие данные настолько мощными и захватывающими? Почему я прогнозирую, что они будут оказывать огромное воздействие на наше будущее? Причина – в той новой информации, которую они могут предоставить. Большие данные часто снабжают организации информацией, которая является оригинальной в одном или сразу в двух аспектах. Во-первых, с небывалым уровнем детализации. Во-вторых, зачастую недоступной ранее.
Давайте рассмотрим, как производители автомобилей в настоящее время используют большие данные для целей предупредительного техобслуживания. На протяжении многих лет в прошлом, когда происходила поломка автомобиля, производитель прилагал усилия, стараясь выяснить, почему она случилась, а затем проследить путь вплоть до коренного изъяна, вызвавшего проблему. Сегодня встроенные датчики обеспечивают интенсивные потоки данных в процессе разработки и испытания двигателей, а также двигателей уже проданных автомобилей. Благодаря этому автопроизводители часто могут выявлять опасные шаблоны до того, как те приведут к поломке. Это и называется предупредительным техобслуживанием.
С получением информации от датчиков двигателей теперь стало возможным идентифицировать первые признаки надвигающихся проблем. Ведет ли перегрев детали к ее отказу? Предшествует ли небольшое падение напряжения в аккумуляторе распространенной проблеме с электричеством? Ломаются ли некие детали обычно в паре, в наборе или по отдельности? Ответы на эти вопросы невозможно было получить ранее, до появления доступных ныне данных.
Сильной стороной сенсорных данных в этом случае является не увеличение информации, а предоставление совершенно новой информации, не доступной ранее. Возможность прогнозировать и устранять проблемы до того, как произойдет поломка, позволяет значительно повысить удовлетворенность потребителей и снизить расходы на гарантийное обслуживание, поскольку автомобили меньше времени находятся в автомастерской и, как правило, гораздо дешевле принять профилактические меры и устранить проблему, чем ремонтировать уже сломавшийся автомобиль.
Традиционно профессиональные аналитики тратили много времени на совершенствование аналитических моделей, использующих существующие наборы источников данных. Они старались внедрять новейшие методики моделирования и добавлять новые метрики, извлеченные из данных. Эти усилия оправдывали себя, поскольку позволяли понемногу повышать эффективность моделей.
Новая информация почти всегда побеждает новые алгоритмы
Причина, обязывающая организацию активно использовать большие данные, заключается в той совершенно новой информации, которую они часто предоставляют. Да, необходимо корректировать существующие аналитические процессы, использующие имеющиеся данные. Но добавление новой информации может привести к настоящим прорывам. Всегда отдавайте приоритет тестированию новой информации перед тестированием новых методологий или новых метрик, основанных на имеющейся информации.
Между тем существует простой способ значительно повысить мощность аналитического процесса. Организации следует отказаться от традиционного подхода в виде подстройки имеющихся моделей, как только обнаруживается новая информация, относящаяся к проблеме. Эта новая информация может оказаться настолько значимой, что профессиональным аналитикам придется заняться не улучшением существующих моделей, а немедленно приступить к включению в них и тестированию новых данных.
Даже упрощенное использование новой информации может оказать воздействие на качество аналитического процесса, причем намного сильнее, чем при подстройке процесса, использующего имеющуюся информацию. Включайте новую информацию в процесс как можно быстрее, пусть даже поначалу в черновом варианте. Как только это будет сделано, возвращайтесь к пошаговым отладке и улучшению аналитики. И почти всякий раз новая информация будет побеждать новые алгоритмы и новые метрики, основанные на старой информации.
Ищите и задавайте новые вопросы
По мере того как организация расширяет ассортимент используемых данных и инструментов, она также должна сосредоточиться на поиске новых вопросов, которые следует задать, и новых способов задавать старые вопросы. Часто, найдя новый источник данных, люди сразу же задумываются о том, как бы его использовать в уже готовых решениях старых проблем. Однако в каждом случае наряду с этим подходом нужно рассматривать и два других, как показано на рис. 2.2.

Во-первых, необходимо посмотреть, какие совершенно новые и различные проблемы могут быть решены при помощи новой информации. Это кажется очевидным, однако люди с легкостью попадают в привычную колею и просто используют данные для решения обычных проблем. Организация должна сделать акцент на поиске новых возможностей для применения данных. Во-вторых, нужно попробовать найти новые, лучшие способы решения старых проблем. Для этого необходимо изучить проблемы, уже считающиеся преодоленными, и подумать, можно ли подойти к ним совсем с другой стороны за счет внедрения новых данных. Это позволит глубже вникнуть в проблему.
Одной из полезных концепций для осуществления подобной деятельности в контексте клиентских данных является стратегия динамического управления отношениями с клиентами, описанная Джеффом Тэннером в книге «Стратегия динамического управления отношениями с клиентами: Большая прибыль от больших данных» (Dynamic Customer Strategy: Big Profits from Big Data). Она может послужить хорошим подспорьем для читателей, интересующихся заявленной темой.
С тем, как искать новые проблемы, должно быть все понятно, поэтому давайте рассмотрим пример того, как можно использовать большие данные для поиска новых способов решения старых проблем. В сфере здравоохранения клинические испытания служат золотым стандартом, а в их составе заключительный тест и управляющая конструкция выполняются посредством так называемого двойного слепого метода, когда ни пациенты, ни врачи не знают, кто какое лечение получает. Это исследование проводится в строго контролируемых условиях и позволяет с высокой точностью определить положительные и отрицательные эффекты тестируемых процедуры или препарата. Однако, после того как на их разработку были потрачены сотни миллионов долларов и многие годы исследований, клинические испытания в лучшем случае охватывают от 2000 до 3000 человек. Такой размер выборки недостаточен. И это означает, что хотя клинические испытания позволяют очень точно измерить показатели согласно пожеланиям исследователей, но попросту не хватит данных для того, чтобы выявить весь спектр непредвиденных последствий.
К чему ведет такая ограниченность выборки? К ситуациям наподобие тех, что случились несколько лет назад, когда применение многих препаратов-анальгетиков из класса ингибиторов ЦОГ-2, в том числе Vioxx и Celebrex, обернулось неприятностями. Исследователи обнаружили, что эти препараты в два – четыре раза повышают вероятность развития сердечных заболеваний по сравнению с нормой. А ведь проблема не была выявлена в ходе первоначальных клинических испытаний, и прошло несколько лет после выведения препаратов на рынок, прежде чем ее определили.
Взгляните по-новому на проблемы, которые считаете уже решенными
Когда вы находите новые данные, содержащие новую информацию, обязательно вернитесь к былым проблемам. Довольно часто оказывается, что проблему, уже считающуюся решенной, можно решить гораздо эффективнее, если использовать новую информацию и подойти к проблеме с другой стороны.
Теперь давайте перенесемся немного вперед. Можем ли мы повысить точность клинических испытаний при помощи больших данных, даже если они собираются за пределами контролируемой среды? В ближайшем будущем детальная электронная медицинская документация станет нормой. Благодаря этому после выпуска препарата на рынок можно будет отслеживать его действие на тысячах, сотнях тысяч или миллионах людей, которые начнут его использовать. А также проанализировать действие препарата при любых комбинациях болезней, которыми страдают использующие его пациенты, и в комбинациях с любыми другими препаратами и методами лечения, применяемыми одновременно с ним. Люди же, использующие препарат не по назначению и наряду с противопоказанными лекарствами, останутся за рамками клинических испытаний.
Использование электронных историй болезней позволит выявлять непредвиденные положительные и отрицательные эффекты препарата (разумеется, при сохранении конфиденциальности сведений о пациентах). Несмотря на то что эти данные будут поступать не из строго контролируемой среды, как при клинических испытаниях, они позволят намного раньше обнаруживать скрытые проблемы наподобие сердечных осложнений при использовании Vioxx. Чтобы подтвердить эти аналитические результаты, могут потребоваться контролируемые исследования, зато можно будет гораздо быстрее обнаружить источник проблем. Речь идет не о том, чтобы заменить клинические испытания анализом неконтролируемых медицинских данных, а о том, что использование этих данных способно помочь исследователям выявлять непредвиденные положительные и отрицательные эффекты препаратов и намного улучшать методы лечения. Всего-то и требуется задуматься о том, как по-иному подойти к решению проблем… Даже если сегодня они считаются уже решенными.
Хранение данных больше не требует двоичного выбора
Внедрение больших данных требует от организации изменения подходов к тому, как она собирает данные, хранит их и настолько долго. До недавнего времени было слишком дорого тратиться на что-то иное, кроме хранения самых важных данных. Если данные были достаточно важными для того, чтобы их собирать, значит, они были достаточно важными и для того, чтобы хранить их очень долго, если не бессрочно. Учитывая сегодняшнее изобилие источников больших данных, организации должны отказаться и от двоичного выбора «собирать или не собирать», и от бессрочного хранения собранного. Теперь необходимы многовекторные решения.
Во-первых, необходимо ли выбирать все части из источника данных или только отдельные части? Во-вторых, какие данные и на протяжении какого времени должны храниться? Возможно, потребуется лишь малая доля и хранить ее надо будет недолго, а потом удалить. Определение правильного подхода требует сначала определения ценности данных на сегодняшний день и в перспективе.
Чтобы наглядно проиллюстрировать, какие данные не нужно собирать, приведу вам следующий пример. Представьте себе современный умный дом, оснащенный массой всевозможных датчиков. В каждой комнате имеется свой термостат, который постоянно посылает данные о текущей температуре в центральную систему для того, чтобы поддерживать в комнатах постоянную температуру. В процессе взаимодействия термостатов с центральной системой генерируется непрерывный поток данных, но имеют ли они ценность? Эти данные необходимы для выполнения конкретной тактической задачи, но трудно представить, для чего бы они могли потребоваться спустя долгое время. Показания с разрывом в миллисекунду нужны только для выполнения главной задачи – обновления сведений в системе. Если же энергетическая компания будет скрупулезно собирать и хранить такие данные, поступающие из всех обслуживаемых ею домов и зданий, она переполнит свои хранилища данных и не создаст ничего ценного.
Для сокращения данных можно прибегнуть к аналитике. Сокращение данных – это процесс идентификации тех их областей, которые можно проигнорировать или же скомбинировать, чтобы уменьшить количество используемых метрик при небольшой потере информации. Например, если установлено, что температура в смежных комнатах вашего дома всегда отличается не более чем на полградуса, то можно собирать данные не для каждой комнаты, а только для одной и экстраполировать их на соответствующую зону внутри дома. Это позволит значительно сократить хранимые объемы данных без снижения качества информации, доступной для аналитики.
Установите сроки хранения данных
Сейчас происходит масштабное изменение точки зрения на хранение данных. Утверждается правило их удаления по истечении определенного периода времени. Организация должна определить временну́ю ценность данных. Некоторые пригодны только для немедленного применения, другие будут терять свою ценность постепенно. Только небольшую долю данных стоит хранить долго, в отличие от стандартной сегодняшней практики.
Давайте рассмотрим сценарий, когда данные остаются крайне важными только на протяжении определенного периода времени. Железнодорожники устанавливают на рельсах датчики для измерения скорости проходящих поездов. Недавно я узнал, что они также измеряют температуру вагонных колес. Если груз в вагоне несбалансирован и смещается в одну сторону, то вагон начинает перекашиваться. С этой стороны давление груза возрастает, что увеличивает трение, которое, в свою очередь, ведет к большему нагреванию колес. Когда они нагреваются выше определенной температуры, индикатор указывает на серьезный дисбаланс и возможный сход вагона с рельсов. Железнодорожники отслеживают температуру колес в режиме реального времени, когда поезд движется. При нагревании колесной пары выше установленного уровня поезд останавливается и к нему направляется бригада рабочих, чтобы проинспектировать состояние вагона и зафиксировать груз. Это экономит железнодорожным компаниям в перспективе массу денег, поскольку сход состава с рельсов обернется дорогостоящей, а подчас и смертоносной катастрофой.
Теперь обратимся к данным о температуре колес и подумаем, на протяжении какого времени они сохраняют свою ценность. Предположим, что состав должен проехать более 3000 километров за несколько дней. Датчики измеряют температуру колес, скажем, с регулярностью в 30 секунд. Крайне важно собирать и анализировать эти данные в режиме реального времени, чтобы немедленно выявлять возможные проблемы.
Далее перенесемся на пару недель вперед. Поезд благополучно прибыл к месту назначения. Все показатели температуры колес находились в пределах полуградуса от нормы. Дальше хранить эти данные не имеет смысла. Возможно, имеет смысл сохранить выборку данных по нескольким благополучным рейсам, чтобы использовать ее для сравнения с отклонениями от нормы. В то же время данные по рейсам, когда возникали проблемы с температурой колес, могут храниться практически бессрочно наряду с небольшой выборкой по благополучным рейсам. Прочие данные никакой ценности не представляют.
Разумеется, существуют данные, которые имеет смысл хранить очень долго. Банки и брокерские дома могут поддерживать отношения с клиентами на протяжении нескольких последних лет и даже десятилетий. Для них важно хранить информацию о каждом вкладе, сделанном каждым клиентом, и о каждом обмене имейлами опять-таки с каждым клиентом. Это позволяет им улучшить качество обслуживания с течением времени, а также обеспечить себе правовую защиту. В этом случае собираемые данные также хранятся практически вечно, как и было заведено при традиционном подходе.
Итак, ключевое положение этого раздела состоит в том, что организации должны изменить свои подходы к сбору, накоплению и хранению данных. Поначалу вам может быть некомфортно от мысли о том, что некие данные вы упускаете и сознательно удаляете уже собранные. Но в эпоху больших данных делать это необходимо.
Интернет вещей грядет
Концепция Интернета вещей неуклонно привлекала все больше внимания в 2013-м и начале 2014 г. Речь идет обо всех «вещах», работающих онлайн и взаимодействующих друг с другом и с нами. По мере того как датчики и коммуникационные технологии дешевеют, всё больше вещей становятся «умными», приобретая способность оценивать обстановку и передавать информацию. Уже обыденными стали подключенные к Интернету холодильники и часы, которые регулярно отправляют и получают информацию.
Интернет вещей способен порождать огромные массивы данных. В этом он даже может опередить все остальные источники больших данных. Примечательно, что значительная часть генерируемых им данных нередко носит чисто функциональный характер. Любая коммуникация длится очень недолго и может содержать только упрощенную информацию. Например, часы могут получать информацию об обновлении времени из надежного внешнего источника, а затем передавать ее другим часам в домашней сети. В совокупности это создает обширный объем данных, но в большинстве своем у них крайне низкая ценность и крайне короткий срок пригодности.
Многие примеры, описанные в этой книге, можно отнести к сфере Интернета вещей, скажем показания датчиков. Такие умные устройства, «разговаривающие» друг с другом, принесут благо и компаниям, и потребителям. По мере того как все больше вещей вокруг нас приобретают способность сообщаться между собой, перед нами открываются новые возможности:
• Ваш дом изучит ваши предпочтения касательно освещения, отопления и т. п., а затем будет автоматически подстраивать эти функции для вас.
• Такие приборы, как лампочки и освежители воздуха, будут предупреждать вас о необходимости их скорой замены.
• Холодильники будут автоматически выдавать вам списки покупок, учитывая ваше потребление и сроки годности хранящихся продуктов.
• Видео– и аудиоконтент будет плавно следовать за вами из комнаты в комнату, избавляя вас от необходимости что-либо включать и выключать.
• Датчики на вашем теле или рядом с ним будут отслеживать ваш режим сна, потребление калорий, температуру тела и сообщать эти и массу других всевозможных показателей.
Наши вещи могут стать крупнейшим источником персональных данных
Интернет вещей надвигается с быстрой скоростью. Недолго осталось ждать того времени, когда многие из наших личных вещей, больших и малых, будут обладать датчиками и способностью к сообщению. Объемы данных, генерируемых нашими вещами, превзойдут все персональные данные, что мы собираем сегодня. Личные фотографии и видео будут составлять лишь малую долю в общем объеме всех сообщений, отправляемых нашими вещами.
В то время как Интернет вещей будет производить, возможно, один из самых больших объемов данных, последние, вероятно, будут фильтроваться гораздо жестче по сравнению с другими данными. В результате объем, который мы решим оставить, может быть вполне управляемым. Мы позволим всем нашим вещам свободно сообщаться на постоянной основе, а отлавливать будем только самые важные части этого взаимодействия. Более подробно рассмотрим эту концепцию в шестой главе.
Вскоре Интернет вещей станет очень горячей и популярной темой. Я не могу уделить ей того должного внимания, которого она заслуживает. Но, как это произошло и с феноменом больших данных, вскоре в изобилии появятся книги и статьи, посвященные Интернету вещей. Заинтересованные читатели должны внимательно следить за развитием этого тренда. Как свидетельствуют многие из примеров, использованных в книге, операционная аналитика во множестве будет опираться на данные, поставляемые из окружающих нас вещей. Тогда Интернет вещей станет компонентом аналитической стратегии практически каждой организации.
Помещаем большие данные в правильный контекст
Как большие данные вписываются в общую картину? В чем их специфика? Что будет с ними дальше? Эти типичные вопросы возникают у большинства организаций. Как и в любой другой относительно новой области, возникает немало путаницы и разногласий по поводу того, чем являются большие данные на самом деле. В этом разделе мы рассмотрим ряд тем и концепций, которые следует усвоить, чтобы поместить большие данные в правильный контекст. Это позволит гораздо эффективнее включить их в процессы операционной аналитики и добиться успеха.
Данные не столько большие, сколько разнообразные
Как мы уже отмечали ранее в этой главе, именно новая информация, которую содержат большие данные, делает их такими захватывающими. И также отмечали, что многие люди считают, будто сложность в управлении большими данными проистекает из их объема. Но отнюдь не объемом выделяются многие источники больших данных. Часто главная сложность связана с тем, что новая информация обнаруживается в данных разного типа или формата и может потребовать различных аналитических методологий.
Большинство данных, собиравшихся ранее для анализа в мире бизнеса, носили деловой или описательный характер и были хорошо структурированы. Это значит, что информация в них была представлена в четко установленной и легко читаемой форме. Например, колонка под названием «Продажи» в электронной таблице содержала только суммы в долларах. Менее структурированные данные, такие как письменные документы или изображения, считались непригодными для целей анализа. Сейчас, в эпоху больших данных, организации сталкиваются с новыми типами и форматами данных, многие из которых структурированы не так, как традиционные источники. Датчики выдают информацию в специальных форматах. Данные GPS устанавливают местонахождение людей и вещей в пространстве. Часто возникает необходимость определить, насколько крепки взаимоотношения между людьми или организациями. Все это принципиально разные типы данных в плане как формата, так и способов их анализа. О различных типах анализа мы поговорим в седьмой главе.
Главная сложность не в объеме, а в разнообразии
Несмотря на то что основное внимание привлекает «громадность» больших данных, зачастую реальную сложность представляет их разнообразие. Существует множество новых источников данных во множестве новых форматов, содержащих новые типы информации. Определить, как извлечь из этого разнообразия нужную информацию, может потребовать больше усилий, чем определить, как масштабировать аналитические процессы.
Анализ социальной сети с определением количества и крепости связей между ее подписчиками требует совершенно других методологий, чем, скажем, прогнозирование продаж. Подобное разнообразие больших данных представляет собой куда больший вызов, чем их «громадность». В чем заключается сложность? Давайте посмотрим на примере.
Предположим, что организация впервые решает запустить текстовый анализ сообщений по электронной почте. Даже для того чтобы проанализировать всего несколько тысяч имейлов, потребуется приобрести специальное программное обеспечение, установить его и настроить, а также определить желательную для организации логику анализа. Создание процесса текстового анализа для 10 000 писем потребует столько же времени и усилий, как и для 10 млн или 100 млн. Будет применяться одна и та же логика, только увеличится масштаб. Поскольку текст представляет собой иной тип данных, придется проделать много подготовительной работы, чтобы запустить анализ даже очень малого объема текстовых данных.
Разумеется, при выполнении аналитического процесса 10 000 имейлов будут обработаны быстрее, чем 100 млн. Несмотря на то что увеличение объема требует масштабирования процесса, лежащая в его основе логическая схема анализа остается прежней. Поэтому первым делом нужно решить, как управлять разнообразием источника больших данных. А затем решить, как управлять разнообразием при масштабировании.
Большие данные требуют масштабирования по нескольким параметрам
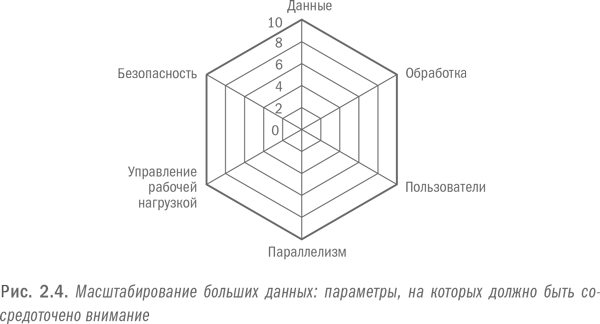
Главное внимание при работе с большими данными обычно уделяется проблеме масштабирования. Если конкретнее, то количеству данных и объему требуемой обработки. Между тем нужно учитывать и другие параметры масштабирования в том случае, если организация решает внедрить аналитику на уровне всего предприятия и особенно если решает превратить ее в операционную. Эти аспекты проиллюстрированы на рис. 2.3 и 2.4.
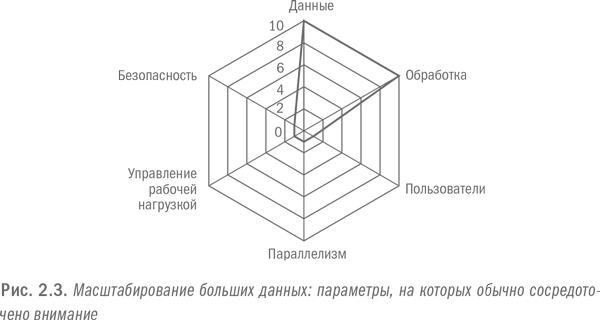
Во-первых, необходимо произвести масштабирование касательно количества и разнообразия пользователей, имеющих доступ как к исходным данным, так и к результатам основанных на них аналитических процессов. Десяткам и сотням тысяч сотрудников может потребоваться в любое время ознакомиться в разных аспектах с первичными данными и результатами их анализа. Корпоративные платформы должны быть дружественными к пользователям и совместимыми с широким спектром инструментов и приложений.
Масштабирование касается не только хранения и обработки
Основное внимание при внедрении больших данных, как правило, уделяется возможностям масштабирования хранения и обработки данных. При этом часто упускаются из виду другие важные параметры, которые также требуют масштабирования, такие как количество пользователей, уровень параллелизма, управление рабочей нагрузкой и протоколы безопасности. Если системы не будут масштабированы по всем перечисленным параметрам, организации не удастся добиться успеха в операционной аналитике.
Во-вторых, крайне важно произвести масштабирование такого параметра, как параллелизм. Под ним понимается количество пользователей или приложений, которые одновременно могут получить доступ к определенному набору информации. Также параллелизм на уровне предприятия означает, что по мере изменения данных все пользователи получают согласованные ответы на свои запросы. По мере роста параллелизма значительно возрастает и риск того, что система перестанет справляться с обработкой запросов. Следовательно, если крупная организация решает внедрить у себя операционно-аналитические процессы, она должна создать такую среду, где множество разных пользователей и приложений могут одновременно взаимодействовать с одной и той же информацией.
В-третьих, существует потребность в масштабировании инструментов управления рабочей нагрузкой. Когда различные типы пользователей подают широкий спектр запросов на анализ да еще и на защищенном уровне, необходимо наладить управление рабочей нагрузкой. Сбалансировать разом множество запросов – не такая простая задача, как кажется, однако этот аспект масштабирования легко упустить из виду. Очень нелегко создать систему, которая способна эффективно управлять как незначительными тактическими, так и крупными стратегическими запросами.
Наконец, нужно масштабировать и протоколы безопасности. Организация при необходимости должна быть способна контролировать и блокировать доступ к данным. Пользователям предоставляются только те части данных, которые им позволяется видеть. Крупная организация должна встроить надежные протоколы безопасности во все свои платформы.
Все перечисленные параметры масштабирования – данные, обработка, пользователи, параллелизм, управление рабочей нагрузкой и безопасность – должны присутствовать с самого начала, если организация хочет добиться успеха в операционной аналитике. И потерпят неудачу те, кто заботится только о масштабировании хранения и обработки данных.
Как получить максимальную отдачу от больших данных
Одна из самых распространенных ошибок, которую я видел в организациях, пытающихся внедрить большие данные в свои аналитические процессы, состоит в подходе к большим данным как совершенно отдельной и самостоятельной проблеме. Многие компании даже создают специальные подразделения, занимающиеся только большими данными. А некоторые доходят вплоть до того, что открывают в Кремниевой долине офисы, призванные заниматься реализацией проектов в области больших данных. Однако такой подход может встретиться с трудностями, поскольку большие данные всего лишь один из аспектов общей корпоративной стратегии управления данными и аналитикой. Необходима единая согласованная стратегия, охватывающая все данные, большие и малые, как это проиллюстрировано на рис. 2.5 и 2.6.
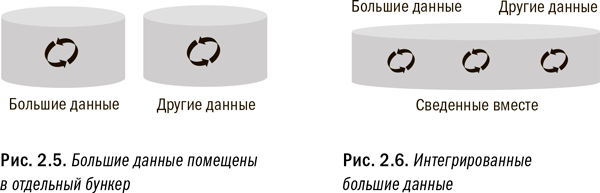
Давайте рассмотрим историческую параллель, которая наглядно показывает, почему отсутствие единой стратегии управления данными и аналитикой может привести к проблемам. Когда электронная коммерция уже достигла зрелости, многие ретейлеры все еще рассматривали ее не в качестве аспекта своих стратегий розничного бизнеса, а как совершенно новое направление деятельности. В результате многие из них создавали специальные подразделения электронной коммерции, иногда даже придавая им статус отдельных юридических лиц. Эти отдельные организации создавали собственные цепочки поставок, иерархии продуктов, политику ценообразования и т. д.
Теперь перенесемся в сегодняшний день. Те же самые ретейлеры сейчас желают, чтобы их бизнес воспринимали как единое целое, включая традиционные стационарные магазины и электронную коммерцию. Более того, они хотят обеспечить потребителям плавное переключение между различными каналами торговли. Однако, для того чтобы объединить в некоторых случаях совершенно несовместимые системы, ретейлерам требуются миллионы долларов инвестиций и годы работы.
Разработайте общую стратегию в области данных и аналитики
Вы должны рассматривать большие данные как один из аспектов общей стратегии управления данными и аналитикой. В противном случае вы столкнетесь с теми же проблемами, с которыми сегодня сталкиваются ретейлеры, изначально не включившие электронную коммерцию в свои стратегии розничной торговли.
10–15 лет тому назад ретейлеры справедливо признали, что электронная коммерция имеет свою специфику. Но им также нужно было бы признать, что ее следовало вписать в их общую стратегию розничной торговли. Если бы они развивали электронную коммерцию в интеграции с основным бизнесом, то это немного растянуло бы процесс поначалу, зато в долгосрочной перспективе сэкономило бы много денег и времени.
Убедитесь, что ваша организация не совершает ту же ошибку в отношении больших данных. Потратьте время на то, чтобы продумать, как большие данные могут быть интегрированы в вашу общую стратегию управления данными и аналитикой. Это важный момент, поскольку ни один источник данных сам по себе не способен обеспечить оптимальные результаты. Сочетание различных источников данных – единственный способ извлечь из них максимальную ценность. Например, для того чтобы составить представление о потребителе, нужно совместить данные о продажах и поисковых запросах в веб-браузере, демографические данные и другие.
Если же организация внедрит отдельные системы и процессы для больших данных, не подумав о необходимости интеграции, ей будет гораздо труднее добиться в итоге искомой оптимизации. Компании должны стремиться создать единое аналитическое окружение, которое позволяет его пользователям осуществлять любой тип анализа с использованием любого типа и объема данных в любой момент времени. Далее в книге мы подробнее рассмотрим, как создать такое окружение. Читателям, желающим больше узнать о том, как получить максимальную отдачу от использования больших данных в маркетинге, я рекомендую прочитать книгу моей коллеги Лайзы Артур «Маркетинг на основе больших данных: как эффективнее привлечь потребителей и извлечь ценности» (Big Data Marketing: Engage Your Customers More Effectively and Drive Value).
Назад в будущее
Одна из шумно разрекламированных концепций касательно больших данных связана с якобы новым миром, создаваемым набором нереляционных инструментов, которые не опираются на реляционные базы данных и не используют SQL в качестве первичного интерфейса. Аббревиатура SQL расшифровывается как «язык структурированных запросов», и на протяжении многих лет его называли «языком бизнеса». Нереляционнные наборы инструментов не используют SQL эксклюзивно либо вообще его не используют. Приверженцы нереляционного подхода считают, что возникла потребность в дополнительных языках, поскольку SQL во многих компаниях был практически единственным языком бизнеса. В конце концов почему бизнес не может быть многоязычным? Он и должен быть таковым. Более того, он должен был быть таковым с самого начала.
Давайте сразу же разоблачим роковое заблуждение. Дело в том, что нереляционная аналитика – далеко не новая концепция. Когда я начинал свою карьеру аналитика, реляционных баз данных в мире бизнеса еще не существовало. Как и не существовало SQL. Поэтому всю аналитику мы выполняли с помощью нереляционных методов. Например, я обычно использовал инструменты из SAS (системы статистического анализа). Для специалистов вроде меня язык SQL действительно был новинкой. Со временем мы поняли, что SQL лучше подходит для определенных видов задач и обработки. Но всегда встречались и такие виды обработки, которые профессиональные аналитики по-прежнему осуществляли вне окружения SQL.
Сегодня же, с появлением больших данных, организации вновь открыли для себя ценность обработки вне контекста SQL в тех случаях, когда это имеет смысл. Оказалось, что источники больших данных гораздо чаще, чем источники традиционных данных, оправдывают использование нереляционных технологий. Однако многие компании зашли слишком далеко и постарались втиснуть всю обработку в парадигму SQL. Это было ошибкой; организациям действительно необходимо включать в свой набор различные подходы. Просто вы должны знать, что нереляционные технологии были доступны всегда. И дело не в том, что в течение 2010-х гг. не существовало никакой необходимости в нереляционной обработке. Скорее компании слишком сильно сконцентрировались на SQL. Можно ожидать, что в будущем SQL останется доминирующим подходом для анализа данных, а нереляционная аналитика станет применяться в специфических целях.
Огромный сдвиг во взглядах на большие данные
После того как на протяжении нескольких лет предсказывалась скорая смерть SQL, сегодня нереляционные платформы стремятся дополниться интерфейсами SQL. В этом нашли отражение не только огромный сдвиг во взглядах, но и реальные потребности бизнеса.
Организациям следует внедрять набор нереляционных инструментов когда это уместно, но ни в коем случае нельзя предполагать, что при этом отпадет необходимость в использовании наряду с ними и SQL. Ведь так легко впасть в противоположную крайность, и многие организации сегодня подвергаются риску поступить именно так. Но, хотя в течение нескольких лет многие эксперты провозглашали смерть SQL, вследствие массовой перемены мнений сейчас возникло сильное движение за внедрение функциональности в стиле SQL в широкий спектр нереляционных платформ, таких как Hadoop. В очередной раз мы возвращается назад в будущее. Подробнее об этом тренде и о том, как правильно выбрать тип обработки, мы поговорим в пятой и шестой главах.
Большие данные следуют кривой зрелости
Многие люди жалуются мне на то, что большие данные их подавляют. Существует так много новых источников данных и так много новых возможностей применения этих данных, что организации попросту не знают, как с ними справиться и с чего начать. Прежде чем отчаиваться, подумайте о том, что большие данные следуют той же кривой зрелости, что и любой новый источник данных. Такова жизнь, что, когда появляется новый источник данных, он всегда представляет собой вызов. Люди не знают в точности, как наилучшим образом использовать эти новые данные, какие метрики создать на их основе, какие проблемы с качеством данных могут возникнуть, и т. д. Однако с течением времени работа с этим источником нормализуется.
Много лет назад, когда я со своей командой впервые занялся анализом данных с точек продаж (point‐of‐sale, POS), мы тоже не знали, как лучше их использовать в целях анализа покупательского поведения и улучшения результатов в бизнесе. О том, чтобы применить к POS-данным операционную аналитику, мы тогда и помыслить не могли. У нас было множество теорий и идей, но ни одна из них на тот момент не была проверена на практике. Разумеется, мы не располагали никакими стандартизированными подходами к вводу, подготовке и анализу этих данных. Со временем в процессе регулярного анализа POS-данных все эти аспекты были стандартизированы. Сегодня использование POS-данных считается простым делом и применяется для решения широкого круга задач.
Не отчаивайтесь
Новые источники данных всегда пугают, когда мы впервые начинаем их анализировать. Но со временем наше понимание их крепнет, и нам становится удобно с ними работать. Такой же процесс вызревания произойдет и с большими данными. Ситуация с ними кажется более пугающей, чем обычно, только лишь потому, что нам приходится одновременно иметь дело со множеством новых источников.
Организациям предстоит пройти одним и тем же путем познания каждого нового источника данных (см. рис. 2.7). Принципиальное отличие сегодняшней ситуации состоит в том, что в прошлом организация получала доступ к действительно новому и уникальному источнику данных раз в несколько лет, тогда как в эпоху больших данных она может получить доступ сразу ко множеству таких источников.

Сегодня перед профессиональными аналитиками может стоять задача одновременно наладить анализ в таких областях, как взаимодействие в социальных сетях, взаимодействие по обслуживанию клиентов, веб-поведение клиентов, сенсорные данные и т. д. Иногда требуется использовать все эти данные в одном аналитическом процессе. В таком случае множественные новые источники, следующие кривой зрелости, применяются все вместе. Сделать это гораздо сложнее, чем в случае с одним лишь новым источником. Ситуация усугубляется тем, что необходимо представлять себе не только как обращаться с каждым источником данных, но и как соединить их вместе (мы обсуждали это выше),
Помните, что работа с новыми данными всегда сложна и всегда поначалу пугает. На этом пути вам всегда придется преодолевать ухабы, но неизбежно со временем процесс ввода и анализа данных будет в основном стандартизирован – и станет для вас простым делом. Затем вы сможете перейти к следующему новому источнику данных. Именно так произойдет и уже происходит с большими данными сегодня.
Большие данные как глобальный феномен
Наконец в этой главе мы рассмотрим, насколько велика зрелость больших данных и устойчивы взгляды на них в различных точках земного шара. Ведь одни организации находятся впереди, а другие отстают в циклах внедрения и развития больших данных. Тем не менее, объехав несколько континентов и пообщавшись со множеством банков, страховых компаний, ретейлеров, государственных учреждений и т. д., я обнаружил, что все они сталкиваются фактически с одними и теми же проблемами. Несмотря на особенности местных рынков, определяемые законами и обычаями, фундаментальные проблемы бизнеса отличаются постоянством. Кроме того, люди в большинстве своем считают, что в других отраслях и в других частях света ситуация куда лучше, чем в их организации, хотя зачастую это совсем не так.
Математика, статистика, аналитика и данные не пользуются особым языком и не принадлежат особой культуре. Они универсальны по своей природе. График тренда в Китае выглядит точно так же, как график тренда в Испании, и основан на одинаковой информации. Средние значения вычисляются в Индии точно так же, как и в Германии. Запись транзакции в Японии содержит точно такую же информацию, как и запись транзакции в Бразилии. Утверждение о том, что большие данные представляют собой уникальную проблему для какой-либо отрасли или страны, является ошибочным за очень редкими исключениями.
Ваша организация может отставать не на столько, на сколько вы считаете
Организации по всему миру сталкиваются с очень похожими проблемами в области больших данных. Однако организации часто считают, что в своей отрасли они попали в число отстающих, и точно так же считают организации в той же отрасли, но в другом регионе мира. Несмотря на то что каждый считает себя отстающим, во многих случаях реальное отставание гораздо меньше, чем предполагается.
Подумайте над тем, чтобы наладить сотрудничество с другими похожими организациями где угодно в мире. Благодаря социальным сетям сегодня это сделать легко. Вполне может оказаться, что другая организация сталкиваются со сходными проблемами. Разумеется, нет смысла пытаться наладить конструктивный диалог со своим прямым конкурентом. Но вы можете найти организацию на другом конце земного шара, которая не представляет для вас конкурентной угрозы. Обмен информацией и усвоенными уроками будет выгодным для обеих сторон.
С какими бы трудностями ни сталкивалась ваша организация при внедрении больших данных, вы можете быть уверены в том, что многие другие организации проходят через то же самое. Со временем для всех этих проблем будут найдены решения, которые станут общеизвестными и общедоступными. Включение больших данных в операционную аналитику превратится в намного более легкую и стандартную процедуру. Организации необязательно стремиться во что бы то ни стало стать первопроходцем, но ей не следует и дожидаться полного решения проблем. Догоняющее развитие не приведет к выигрышу.
Подведем итоги
Наиболее важные положения этой главы:
• Не беспокойтесь насчет определения больших данных. Гораздо важнее определить, какие именно данные, будь то большие или малые, необходимы вам для аналитики. Важно не определение, а результаты!
• Всегда начинайте с конкретных бизнес-проблем. Не внедряйте технологии больших данных только лишь для того, чтобы заявить об этом.
• Несмотря на чрезмерную шумиху и нереалистичные краткосрочные ожидания, большие данные останутся с нами. Точно так же как пузырь доткомов не означал, что у Интернета не было огромного потенциала, так и пузырь больших данных не означает отсутствия огромного потенциала у больших данных.
• Что делает большие данные настолько захватывающими, так это новая информация, которая в них содержится. Новая информация почти всегда побеждает новые алгоритмы.
• Не используйте большие данные только для улучшения существующих аналитических процессов. Ищите способы, при помощи которых большие данные позволят решить старые проблемы с новой точки зрения или решить совершенно новые проблемы.
• В ближайшие годы будьте готовы к стремительному росту ажиотажа вокруг Интернета вещей, а также к пересмотру своей политики по отношению к сохранению данных, чтобы справляться с грядущими потоками малоценных данных.
• Разнообразие больших данных, по сравнению с традиционными, гораздо проблематичнее, чем их «огромность».
• Большие данные требуют масштабирования не только при обработке и хранении, но и в параметрах касательно пользователей, параллелизма, управления рабочей нагрузкой и безопасности.
• Большие данные должны стать компонентом общей стратегии управления данными и аналитикой. Большие данные не могут эффективно работать сами по себе.
• После нескольких лет предсказаний о скорой смерти SQL сегодня нереляционные платформы стремятся дополниться интерфейсами SQL. В этом находят отражение не только огромный сдвиг во взглядах, но и реальные потребности бизнеса.
• Хотя сегодня большие данные могут казаться подавляющими, они следуют той же кривой зрелости, что и другие источники данных. Большие данные довлеют над нами сильнее ввиду количества новых источников данных, которые все разом стали нам доступны.
• Большинство организаций во всех отраслях и странах мира считает, что они далеко отстали в области больших данных. На самом же деле немногие организации вырвались далеко вперед, соответственно и немногие далеко отстали.

