Книга: Много цифр. Анализ больших данных при помощи Excel
Назад: Использование правила Байеса для создания моделирования
Дальше: Подытожим
Да начнется Excel-вечеринка!
Заметка
Электронная таблица Mandrill.xslx, используемая в этой главе, находится на сайте книги, www.wiley.com/go/datasmart. Эта таблица содержит все исходные данные для того, чтобы вы могли работать вместе со мной. Можете также просто следить за ходом повествования, используя листы, в которых все расчеты уже совершены.
В электронной таблице для этой главы – Mandrill.xslx, есть два листа с исходными данными. Первый, AboutMandrillApp, содержит 150 твитов, по одному на строку, относящихся к приложению Mandrill. Второй, AboutOther, содержит 150 твитов об остальных мандрилах.
Перед началом хочу сказать – добро пожаловать в мир обработки естественного языка (Native Language Processing, NLP)! NLP пережевывает текст, написанный человеком, и выплевывает знания. «Человеческое» содержимое (например, записи в Twitter) готово для потребления компьютером. Перед этим необходимо провести несколько мелких операций.
Убираем лишнюю пунктуацию
Первый шаг в создании набора слов из твита – это токенизирование слов, разделенных пробелами. Но не все, что отделено пробелами, является словами. Нужно перевести все буквы в строчные и удалить пунктуацию, потому что в Twitter пунктуация далеко не всегда что-то значит. Причина понижения регистра в том, что «e-mail» и «E-mail» не различаются по значению.
Поэтому в ячейку В2 на обоих листах добавьте формулу:
=LOWER(A2)
=СТРОЧН(А2)
Это переведет первую запись в строчной вид. В С2 вырежем все фразы. Не стоит кромсать ссылки, так что вырежем все части, после которых есть пробел с помощью команды SUBSTITUTE/ПОДСТАВИТЬ:
=SUBSTITUTE(В2,"."," ")
=ПОДСТАВИТЬ(В2,"."," ")
Эта формула заменяет знаки ". " единичным пробелом " ".
Вы также можете указать ячейку D2 в С2 и заменить все двоеточия с пробелами после них единичными пробелами:
=SUBSTITUTE(С2,": "," ")
=ПОДСТАВИТЬ(С2,": "," ")
В ячейках от Е 2 до Н2 необходимо сделать такие же замены знаков "?", "!", ";" и ",":
=SUBSTITUTE(D2,"?"," ")
=SUBSTITUTE(E2,"!"," ")
=SUBSTITUTE(F2,";"," ")
=SUBSTITUTE(G2,","," ")
=ПОДСТАВИТЬ(D2,"?"," ")
=ПОДСТАВИТЬ(E2,"?"," ")
=ПОДСТАВИТЬ(F2,"?"," ")
=ПОДСТАВИТЬ(G2,"?"," ")
Не нужно добавлять пробел после знаков препинания в предыдущих четырех формулах, потому что они почти не встречаются в ссылках (особенно в сокращенных).
Выделите ячейки В2:Н2 на обоих листах и кликните дважды на формуле, чтобы разослать ее дальше по листу до строки 151. Получатся два листа, вроде того, что изображен на рис. 3–3.
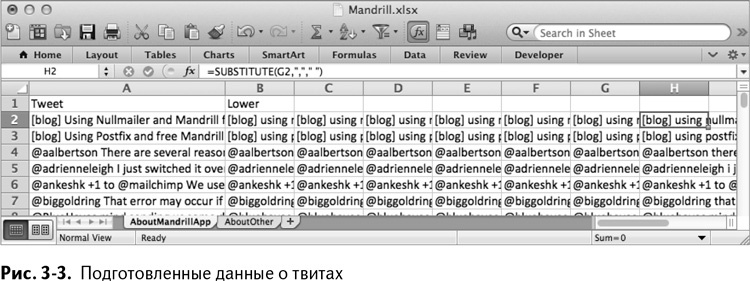
Разное о пробелах
Теперь создайте два новых листа и назовите их AppTokens и OtherTokens.
Вам необходимо сосчитать, сколько раз каждое слово используется в записях данной категории. Это значит, что вам нужно собрать все слова из твитов в одном столбце. Резонно предположить, что каждый твит содержит не более 30 слов (но вы смело можете увеличить их количество до 40 или даже 50), так что если вы собираетесь присваивать каждому жетону отдельную строку, вам понадобится 150 × 30 = 4500 строк.
Для начала назовите ячейку А1 на обоих листах «Tweet».
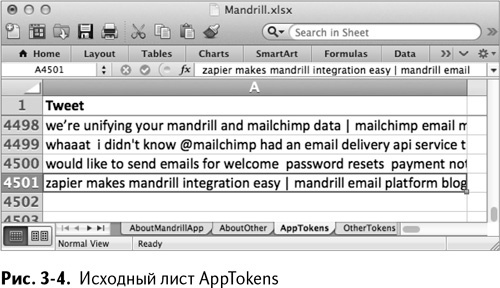
Выделите А2:А4501 и с помощью специальной вставки вставьте значения твитов из столбца Н двух начальных листов. Таким образом вы получите список всех обрабатываемых твитов, как показано на рис. 3–4. Обратите внимание: так как вы вставляете 150 твитов в 4500 строк, Excel повторяет все за вас. Восхитительно!
Это означает, что если вы выделите первое слово из первого твита в строке 2, этот самый твит повторится для выделения второго слова в строке 152, третьего – в 302 и т. д.
В столбце В вам нужно отметить положение каждого следующего пробела между словами в записи. Можете назвать этот столбец, например, Space Position. Так как в начале каждого твита больше нет пробелов, начните с помещения 0 в ячейки А2:А151, чтобы отметить, что слова начинаются с первого символа каждого твита.
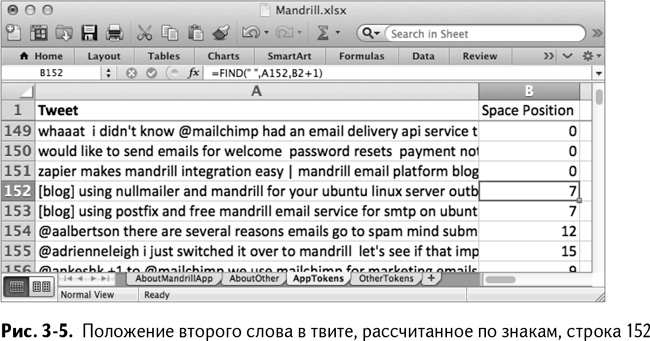
Начиная с В152 после первого полного повтора твитов можно рассчитать положение следующего пробела:
=FIND(" ",A152,B2+1)
=НАЙТИ(" ",A152,B2+1)
Формула FIND/НАЙТИ будет искать в твитах следующий пробел, считая знаки от предыдущего, упомянутого в В2, который находится 150 строками выше, как показано на рис. 3–5.
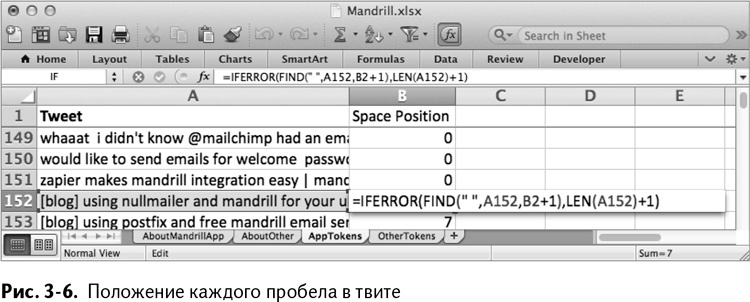
Так или иначе, помните, что эта формула выдаст ошибку, как только закончатся символы в записи – если в ней, к примеру, меньше 30 слов, которые вы планировали. Чтобы справиться с этим, вам нужно вставить формулу в утверждение IFERROR/ЕСЛИОШИБКА и просто прибавить 1 к длине твита, чтобы найти положение после последнего слова:
=IFERROR(FIND(" ",A152,B2+1),LEN(A152)+1)
=ЕСЛИОШИБКА(НАЙТИ(" ",A152,B2+1),LEN(A152)+1)
Затем вы можете кликнуть дважды на этой формуле, чтобы распространить ее по таблице до А4501. Так получится лист, изображенный на рис. 3–6.
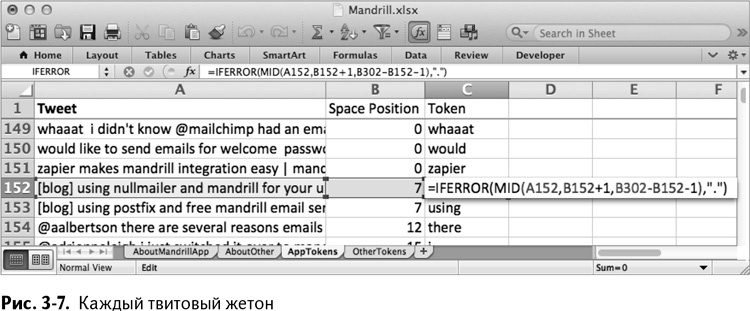
Затем в столбце С можно начать извлекать единичные жетоны (token) из твитов. Назовите столбец С Token и начиная с С2 перетаскивайте подходящие слова с помощью функции MID/ПСТР. Эта функция извлекает из строки текста начальное положение и количество символов. Так, в С2 наш текст находится в А2, начальное положение – 1 после последнего пробела (В2+1), а длина – это разница между последующим положением пробела в В152 и текущим в В2 минус 1 (не забываем, что твиты повторяются через каждые 150 строк).
Получается следующая формула:
=MID(A2,B2+1,B152-B2–1)
=ПСТР(A2,B2+1,B152-B2–1)
Теперь еще раз вернемся к коротким твитам в конце строки, в которых у нас рано заканчивались слова. Если есть ошибка, превратите этот жетон в комбинацию «.», которую потом легко будет проигнорировать:
=IFERROR(MID(A2,B2+1,B152-B2–1),".")
=ЕСЛИОШИБКА(ПСТР(A2,B2+1,B152-B2–1),".")
Теперь вы можете распространить эту формулу на весь лист двойным щелчком, чтобы токенизировать каждый твит, как показано на рис. 3–7.
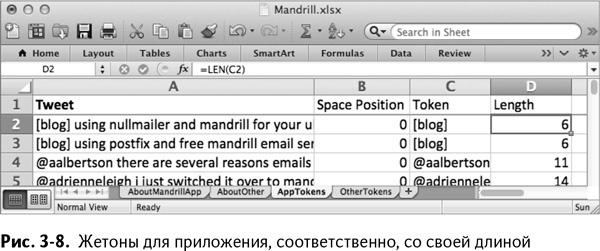
Добавьте столбец Length в D и в ячейке D2 получите длину жетона в С2 в символах:
=LEN(C2)
=ДЛСТР(С2)
Можете также распространить это на весь лист двойным кликом. Это значение позволяет вам находить и удалять любой жетон в три или менее символов, которые практически всегда бессмысленны.
Заметка
Обычно в таком типе обработки натурального языка кроме удаления всех коротких слов существует еще список стоп-слов для отдельного языка (в данном случае, английского), которые также удаляются. Стоп-слова – это слова с очень низким лексическим содержанием, которое подобно содержанию питательных веществ для модели «набор слов».К примеру, «потому что» и «вместо» могут быть стоп-словами из-за того, что они обычные и не особенно помогают отличить один документ от другого. Самые распространенные стоп-слова в английском почти всегда короткие: «a», «and», «the» и т. д., поэтому в данной главе будет рассмотрен наиболее простой, но и наиболее драконовский способ удаления коротких слов из твитов.
Если вы все делали вместе со мной, у вас должен получиться лист AppTokens, показанный на рис. 3–8 (лист Other Tokens идентичен ему, за исключением твитов, вставленных в столбец А).
Подсчет жетонов и вычисление вероятностей
Теперь, токенизировав свои твиты, вы готовы к расчету условной вероятности жетона, р(жетон | класс).
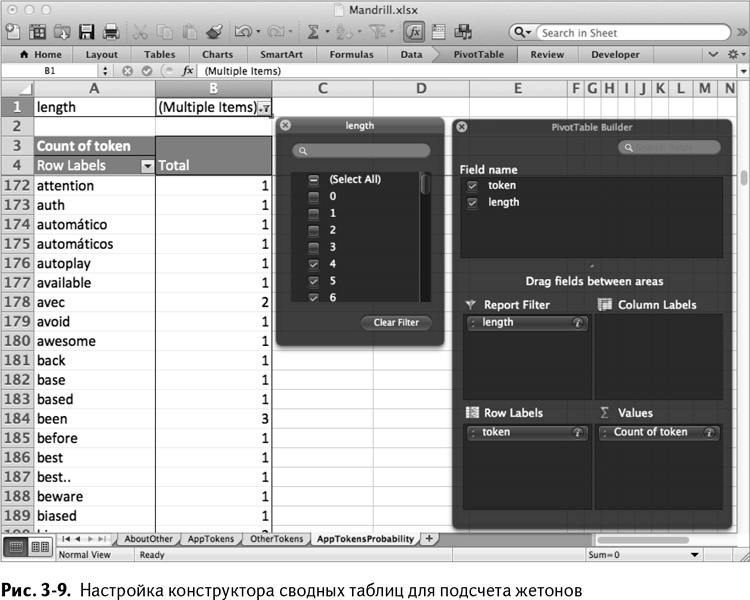
Чтобы произвести расчет, вам нужно определить, сколько раз использовался каждый жетон. Начните с листа AppTokens, выбирая жетон и область длины С1:D4501 и потом вставьте данные в сводную таблицу. Переименуйте полученную сводную таблицу в AppTokensProbability.
В конструкторе сводных таблиц отфильтруйте жетоны по длине и поставьте их по горизонтали, а в окне значений установите значение для подсчета количества каждого жетона. Настройка конструктора показана на рис. 3–9.
В самой сводной таблице в фильтре по длине снимите галочки с жетонов длиной в 0, 1, 2 и 3, чтобы не использовать их (в Windows нужно проинструктировать Excel, что вы собираетесь сделать множественный выбор в выпадающем меню). Это тоже видно на рис. 3–9.
Теперь у вас есть только длинные жетоны из каждого твита, и все они подсчитаны.
Настало время «пристегнуть» вероятность к каждому жетону. Перед запуском расчета примените оговоренную ранее функцию дополнительного сглаживания, добавив 1 к каждому жетону.
Назовите столбец С Add One To Everything и установите С5 = В5 + 1 (С4 + В4 в Windows, где Еxcel строит сводные таблицы на строку выше, просто чтобы рассердить читателей). Вы можете распространить формулу двойным щелчком.
Так как вы добавили 1 ко всему, вам понадобится новый подсчет жетонов. Внизу таблицы (строка 828 на листе AppTokensProbability) введите в ячейку сумму всех ячеек, находящихся над ней. Еще раз отмечу, что если вы работаете с Windows, то все сведется на одну строку выше (С4:С826 для суммирования):
=SUM(С5:С827)
=СУММА(С5:С827)
В столбце D можно рассчитать вероятность для каждого жетона, основываясь на его количестве в столбце С, деленном на общее число жетонов. Назовите этот столбец P(Token|App). Вероятность для первого жетона находится в D5 (D4 в Windows) и рассчитывается так:
=C5/C$828
Обратите внимание на абсолютную ссылку в общем числе жетонов. Это позволяет вам отправить формулу на весь столбец D двойным щелчком. Затем в столбец Е (назовем его LN(P)) можно поместить натуральный логарифм вероятности из D5:
=LN(D5)
Применив эту формулу ко всему листу, получаем все необходимые значения для правила МАР, как на рис. 3-10

Точно так же поступаем с жетонами о других мандрилах и создаем лист OtherTokensProbabilities.
У нас есть модель! Воспользуемся ею
В отличие от регрессивной модели (которая встретится вам в главе 6), оптимизационного этапа здесь не будет. Никакого «Поиска решения», никакой подгонки модели. Модель байесовского классификатора – не что иное, как две таблицы условной вероятности.
Это одна из причин, по которым эту модель любят программисты. Здесь нет сложного этапа подгонки – достаточно подбросить побольше жетонов и сосчитать их. А еще вы можете сохранить получившийся словарь жетонов у себя на диске для дальнейшего использования. Гениально просто!
Теперь, когда модель классификатора «обучена», настало время ее использовать. На листе TestTweets в «Рабочей тетради» вы найдете 20 твитов, 10 о приложении, 10 – о другом. Вам нужно подготовить эти твиты, токенизировать их (ради интереса сделаем это немного по-другому), рассчитать логарифмированные вероятности для жетонов обоих классов и определить их наиболее вероятную принадлежность.
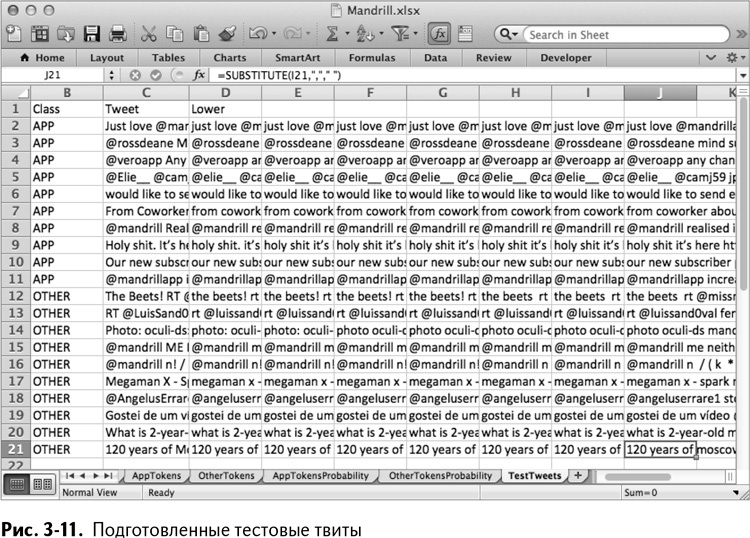
Для начала скопируем ячейки В2:Н21 из листа AboutMandrillApp и вставим их в D2:J21 листа TestTweets. Получаем лист, изображенный на рис. 3-11.
Теперь создадим новый лист и назовем его TestPredictions. Вставим в него столбцы Number и Class из TestTweets. Назовем столбец С Prediction, который впоследствии заполним предполагаемыми значениями классов. Затем назовем столбец D Tokens и вставим в D2:D21 значения из столбца J из листа TestTweets. Получается лист, изображенный на рис. 3-12.
В отличие от построения таблиц вероятности, не нужно комбинировать жетоны, содержащиеся во всех твитах. Следует оценивать каждый твит отдельно, что делает токенизирование довольно простым.
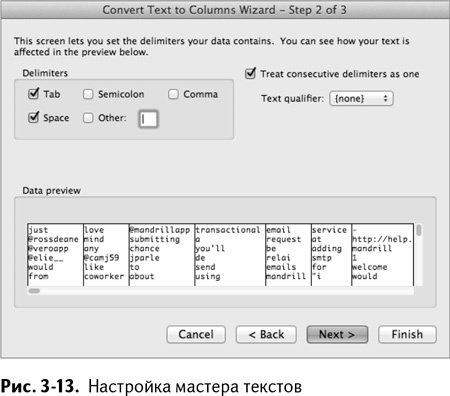
Сначала выделите твиты в D2:D21 и выберите «Текст по столбцам» во вкладке меню «Данные». В появившемся «Мастере текстов», выберите «С разделителями» и нажмите «Далее».
Второй шаг мастера – выберите знаки табуляции и пробела в качестве разделителей. Также можно выбрать «Считать последовательные разделители одним» и убедиться, что ограничитель строк установлен на {нет}. Настройка мастера показана на рис. 3-13.
Нажмите «Готово». Это разбросает твиты по столбцам всего листа до столбца AI, как на рис. 3-14.
Под списком жетонов в столбце D в строке 25 нужно найти вероятность отношения к приложению для каждого жетона. Для этого можно использовать функцию VLOOKUP/ВПР (в главе 1 эта функция описана более подробно), начиная с ячейки D25:
=VLOOKUP(D2,AppTokensProbability!$A$5:$E$827,5,FALSE)
=ВПР(D2,AppTokensProbability!$A$5:$E$827,5,FALSE)
Функция VLOOKUP/ВПР берет соответствующий жетон из D2 и пытается найти его в столбце А листа AppTokensProbability. Если таковой находится, функция берет значение из столбца Е.
Но этого недостаточно, потому что вам нужно иметь дело с редкими словами, которых нет в таблице просмотра, – такие жетоны получат значение N/A от функции. Как обсуждалось ранее, эти редкие слова должны иметь вероятность, равную 1, деленную на общее число жетонов в ячейке В828 на листе AppTokensProbability.
Имея дело с редкими словами, нужно вложить VLOOKUP/ВПР в проверку ISNA/ЕНД и работать с логарифмированными вероятностями редких слов, если есть такая необходимость:
IF(ISNA(VLOOKUP(D2,AppTokensProbability!$A$5:$E$827,5,
FALSE)),LN(1/AppTokensProbability!$C$828),
VLOOKUP(D2,AppTokensProbability!$A$5:$E$827,5,FALSE))
ЕСЛИ(ЕНД(ВПР(D2,AppTokensProbability!$A$5:$E$827,5,ЛОЖЬ)),
LN(1/AppTokensProbability!$C$828), ВПР(D2,
AppTokensProbability!$A$5:$E$827,5,ЛОЖЬ))
Единственное, что не учитывает данное решение, – это маленькие жетоны. Есть соблазн их выкинуть. Так как мы будем суммировать эти логарифмированные вероятности, вы можете установить логарифмированную вероятность любого маленького жетона на 0 (это, по сути, то же самое, что и выставление вероятности редких слов на 1, только наоборот – жетоны отбраковываются).
Для проведения этой операции нужно снова вложить всю формулу в еще одно утверждение IF/ЕСЛИ, проверяющее длину:
=IF(LEN(D2)<=3,0,IF(ISNA(VLOOKUP(D2,AppTokensProbability!
$A$5:$E$827,5,FALSE)),LN(1/AppTokensProbability!$C$828),
VLOOKUP(D2,AppTokensProbability!$A$5:$E$827,5,FALSE)))
=ЕСЛИ(ДЛСТР(D2)<=3,0,ЕСЛИ(ЕНД(ВПР(D2,AppTokensProbability!
$A$5:$E$827,5,ЛОЖЬ)),LN(1/AppTokensProbability!$C$828),
ВПР(D2,AppTokensProbability!$A$5:$E$827,5,ЛОЖЬ)))
Обратите внимание: на листе AppTokensProbability используются абсолютные ссылки, так что вы можете перемещать формулу, как того пожелаете.
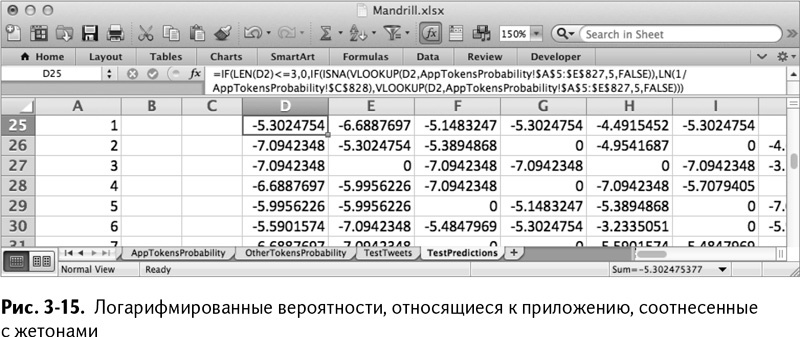
Когда жетоны твитов достигнут столбца AI, протащите эту формулу из D25 до AI44, чтобы учесть каждый жетон. Так получается рабочий лист, изображенный на рис. 3-15.
Начиная с ячейки D48 можно использовать ту же формулу, что и в D25. Имейте в виду, что она должна ссылаться на лист OtherTokensProbability, диапазон использования функции VLOOKUP//ВПР изменится на $A$5:$E$810 и общее число жетонов окажется в $C$811.
Все это приводит нас к листу, показанному на рис. 3-16.
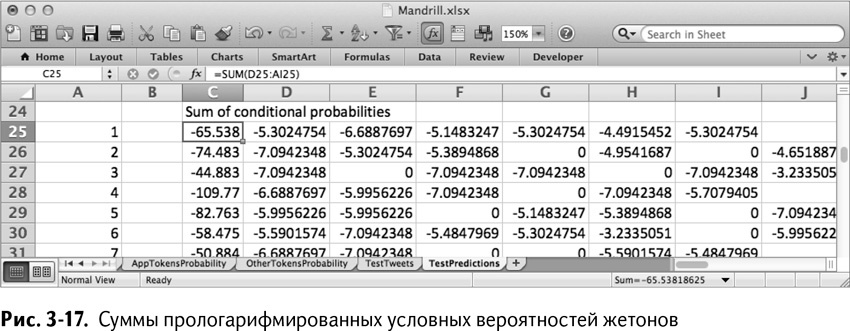
В столбце С можно просуммировать каждую строку вероятностей, что показано на рис. 3-17. К примеру, С25 – это просто
=SUM(D25:AI25)
=СУММА(D25:AI25)
В ячейке С2 можно классифицировать первый твит, просто сравнив его показатели в ячейках С25 и С48, используя следующее утверждение:
=IF(C25>C48,"APP","OTHER")
=ЕСЛИ(C25>C48,"APP","OTHER")
Копируя эту формулу дальше до С21, вы получаете классификации для каждого твита, как показано на рис. 3-18.
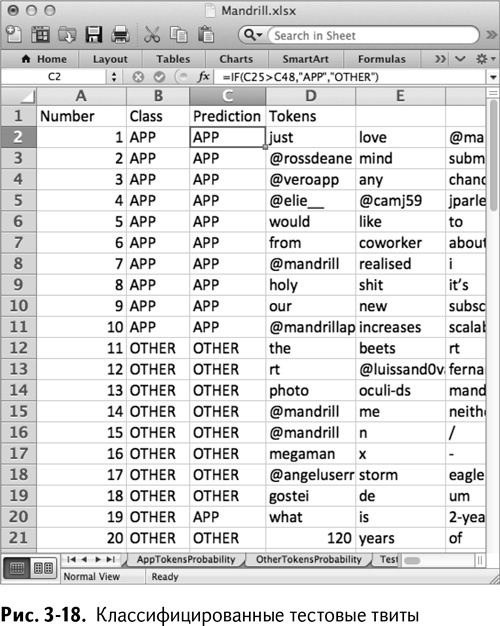
Попадание – 19 из 20! Неплохо. Если взглянуть на неправильно классифицированный твит, можно увидеть, что написан он весьма расплывчато – показатели близки к неопределенным.
Вот и все. Модель построена, предположения сделаны.
Назад: Использование правила Байеса для создания моделирования
Дальше: Подытожим

