Книга: Много цифр. Анализ больших данных при помощи Excel
Назад: 3. Наивный байесовский классификатор и неописуемая легкость бытия идиотом
Дальше: Самое быстрое в мире введение в теорию вероятности
Называя продукт Mandrill, ждите помех вместе с сигналами
Недавно компания, в которой я работаю, начала новый проект под названием Mandrill.com. Логотип у этого проекта – самый страшный из всех мною виденных (рис. 3–1).
Mandrill – это транзакционный сервис для отправки электронных писем, предназначенный разработчикам приложений, которые хотят, чтобы их детища отправляли одноразовую информацию: письма, счета, восстановленные пароли и все остальное, что передается лично, из рук в руки. Так как он позволяет отслеживать открытие отдельного транзакционного письма и переходы по ссылкам, вы можете подключить этот сервис к своей личной почте и следить, действительно ли ваши родственники открывают и рассматривают все фото вашего котика, которые вы им непрерывно присылаете.

Но с момента запуска Mandrill меня постоянно раздражала одна вещь. При том, что MailChimp придумали мы же, Mandrill – тоже примат – стал занимать его экологическую нишу! И они оба довольно популярны. А ведь еще Дарвин называл разноцветный зад мандрила «экстраординарным».
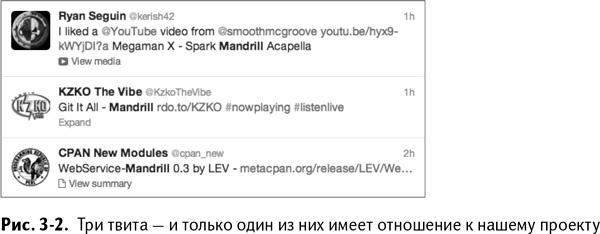
К чему я клоню? Зайдя в Twitter и посмотрев записи с упоминанием продукта Mandrill, вы увидите то, что изображено на рис. 3–2. Нижний твит – о новом модуле, подключающем язык программирования Pearl к Mandrill. И это единственный релевантный твит. Те два, что выше, – про Spark Mandrill из игры Megaman X для Super Nintendo и группу под названием Mandrill.
Ужас!
Даже если вам в школьные годы нравился Megaman X, многие записи нерелевантны вашему поиску. Разумеется, туда попадает еще куча твитов о группе, об игре, о животных, а также других пользователях Twitter, в имени которых есть «mandrill», и всего три – о Mandrill.com. Это называется помехами. Много помех.
Так возможно ли создание модели, которая способна отличить сигнал от помех? Может ли модель ИИ извещать вас только о твитах о почтовом продукте Mandrill?
Итак, мы столкнулись с типичной проблемой классификации документов. Если документ, такой, как твит о Mandrill, может принадлежать к нескольким классам (он может быть о Mandrill.com, а может – о других мандрилах), то к какому классу его следует отнести?
Самый распространенный подход к решению этой проблемы – это использование модели «набор слов» (bag of words) в сочетании с наивным байесовским классификатором. Модель «набор слов» воспринимает документ как беспорядочное множество слов. «Джонни съел сыр» для него то же самое, что «сыр съел Джонни» – и то и другое состоит из одного и того же множества слов:{«Джонни», «съел», «сыр»}.
Наивный байесовский классификатор снабжается обучающим набором уже классифицированных «наборов слов». К примеру, можно загрузить в него несколько наборов о-приложении-Mandrill и несколько – о-других-мандрилах и обучать его отличать одно от другого. В будущем вы сможете скормить ему неизвестный набор слов, и он классифицирует его для вас.
Именно этим мы и займемся в данной главе – созданием наивного байесовского классификатора документов, который воспринимает твиты о мандрилах как наборы слов и выдает вам классификацию. И это будет весьма забавно. Почему?
Потому что наивный байесовский классификатор часто называют «идиотским Байесом». Как вы увидите ниже, придется делать множество неуклюжих, идиотских предположений насчет ваших данных, и все равно они сработают! Это что-то вроде рисования брызгами в моделировании ИИ. Из-за крайней простоты исполнения (он может уложиться в 50 строк кода) компании постоянно их используют для простых классификационных задач. С его помощью можно классифицировать электронную почту организации, записи поддержки пользователей, новостную рассылку, журнал полицейских приводов, медицинские документы, обзоры кинофильмов – что угодно!
Перед тем, как начать применять эту замечательную штуку в Excel (что, на самом деле, довольно просто), вам придется освоить немного теории вероятности. Прошу прощения. Если вы запутаетесь в математике, просто втягивайтесь в процесс. Все окажется крайне просто, вот увидите!
Назад: 3. Наивный байесовский классификатор и неописуемая легкость бытия идиотом
Дальше: Самое быстрое в мире введение в теорию вероятности

