Глава двенадцатая
Выработка ценностей
Контроль над возможностями — в лучшем случае мера временная и вспомогательная. Если не планируется держать ИИ в заточении вечно, придется разрабатывать принципы выбора мотивации. Но как быть с ценностями? Сможем ли мы внедрить их в систему искусственного агента таким образом, чтобы он начал руководствоваться ими как своими конечными целями? Пока агент не стал разумным, у него, скорее всего, отсутствуют способности к пониманию или даже представлению, что такое система человеческих ценностей. Однако если откладывать процедуру обучения, дожидаясь, когда ИИ станет сверхразумным, то, вполне вероятно, он начнет сопротивляться такому вмешательству в свою систему мотивации и, как мы видели в седьмой главе, у него на то будут конвергентные инструментальные причины. Загрузка системы ценностей проблема не из легких, но отступать нельзя.
Проблема загрузки системы ценностей
Невозможно перечислить все ситуации, в которых может оказаться сверхразум, и для каждой из них определить действия, которые ему следует совершить. Точно так же невозможно составить список всех миров и определить полезность каждого. В любой реальности, гораздо более сложной, чем игра в крестики-нолики, есть слишком много возможных состояний (и исторических состояний), чтобы можно было использовать метод полного перебора. Значит, систему мотивации нельзя задать в виде исчерпывающей таблицы поиска. Вместо этого она должна быть определена более абстрактно, в качестве какой-то формулы или правила, позволяющих агенту решить, как поступить в любой ситуации.
Один из формальных путей описания этого правила решений состоит в определении функции полезности. Функция полезности (как мы помним из первой главы) задает ценность каждого возможного исхода или в более общем случае — каждого из так называемых возможных миров. При наличии функции полезности можно определить агента, максимизирующего ожидаемую полезность. В любой момент такой агент выбирает действие, имеющее самое высокое значение полезности. (Ожидаемая полезность рассчитывается путем умножения полезности каждого возможного мира на субъективную вероятность того, что этот мир станет реальностью при условии совершения рассматриваемого действия.) В реальности возможных исходов оказывается слишком много, чтобы можно было точно рассчитать ожидаемую полезность действия. Тем не менее правило принятия решения и функция полезности вместе определяют нормативный идеал — понятие оптимальности, — который агент мог бы разработать, чтобы сделать приближение, причем по мере повышения уровня интеллекта ИИ приближение становится все точнее. Создание машины, способной вычислить хорошее приближение ожидаемой полезности доступных ей действий, является ИИ-полной задачей. В этой главе мы рассматриваем другую задачу — задачу, которая остается таковой даже в случае решения проблемы создания машинного интеллекта.
Схему агента, максимизирующего полезность, мы используем для того, чтобы представить оказавшегося в затруднительном положении программиста, работающего с зародышем ИИ и намеревающегося решить проблему контроля. Для этого он наделяет ИИ конечной целью, соответствующей, в принципе, нормальному человеческому представлению о желаемом исходе. Программист, у которого есть своя система ценностей, хотел бы, чтобы ИИ усвоил ее. Предположим, речь идет о понятии счастья. (Такие же проблемы возникли бы, если бы программиста интересовали такие понятия, как правосудие, свобода, слава, права человека, демократия, экологическое равновесие, саморазвитие.) Таким образом, в терминах ожидаемой полезности программисту нужно определить функцию полезности, которая задает ценность возможных миров в зависимости от уровня счастья, который они обеспечивают. Но как выразить эту функцию в исходном коде? В языках программирования нет понятия «счастье». Чтобы этот термин использовать, ему сначала следует дать определение. Причем недостаточно определить его, используя философские концепции и привычную для человека терминологическую базу, например: «счастье — это наслаждение потенциальными возможностями, присущими нашей человеческой природе», или каким-то иным не менее мудреным способом. Определение должно быть дано в терминах, используемых в языке программирования ИИ, а в конечном счете с помощью таких базовых элементов, как математические операторы и ссылки на ячейки памяти. Когда смотришь на проблему с этой точки зрения, становится понятна сложность стоящей перед программистом задачи.
Идентифицировать и кодифицировать наши конечные цели так трудно потому, что человек пользуется довольно сложной системой дефиниций. Но эта сложность естественна для нас, поэтому мы ее не замечаем. Проведем аналогию со зрительным восприятием. Зрение точно так же может показаться простым делом, поскольку не требует от нас никаких усилий. Кажется, что нужно всего лишь открыть глаза, и в нашем мозгу тут же возникает богатое, осмысленное, рельефное трехмерное изображение окружающего нас мира. Это интуитивное представление о зрении сродни ощущениям монарха от организации быта в его дворце: ему кажется, что каждый предмет просто появляется в нужном месте в нужное время, притом что механизм, обеспечивающий это, полностью скрыт от его взора. Однако выполнение даже простейшей визуальной задачи: поиск перечницы на кухне — требует проведения колоссального объема вычислительных действий. На базе зашумленной последовательности двумерных паттернов, возникшей в результате возбуждения нервных клеток сетчатки глаза и переданной по глазному нерву в мозг, зрительная кора головного мозга должна реконструировать и интерпретировать трехмерное представление окружающего пространства. Заметная часть поверхности коры головного мозга — нашей драгоценной недвижимости площадью один квадратный метр — занята областью обработки зрительной информации; когда вы читаете эту книгу, над выполнением этой задачи неустанно работают миллиарды нейронов (словно множество швей, склонившихся над своими швейными машинами в ателье и множество раз за секунду успевающих сшивать и снова распарывать огромное стеганое одеяло). Точно так же наши, казалось бы, простые ценности и желания на самом деле очень сложны. Как программист мог бы отразить всю эту сложность в функции полезности?
Один из подходов заключается в том, чтобы попробовать напрямую закодировать полное представление о конечной цели, которую программист назначил для ИИ; иными словами, нужно записать функцию полезности, применив метод точной спецификации. Этот подход мог бы сработать, если у нас была бы чрезвычайно простая цель, например мы хотели бы знать, сколько десятичных знаков после запятой стоит в числе пи. Еще раз: единственное, что нам понадобилось бы от ИИ, чтобы он рассчитал все знаки после запятой в числе пи. И нас не волновали бы никакие иные последствия достижения им этой цели (как мы помним, это проходило по категории пагубных отказов, тип — инфраструктурная избыточность). Было бы полезно при использовании метода точной спецификации выбрать еще метод приручения. Но если развиваемый ИИ должен стать сверхразумным монархом, а его конечной целью является следовать любым возможным человеческим ценностям, тогда метод точной спецификации, необходимый для полного определения цели, — безнадежно недостижимая задача.
Допустим, мы не можем загрузить в ИИ описание человеческих ценностей с помощью их полного представления на языке программирования — тогда что еще можно попробовать сделать? В этой главе мы обсудим несколько альтернативных путей. Какие-то из них на первый взгляд представляются вполне возможными, но при ближайшем рассмотрении оказываются гораздо менее выполнимыми. В дальнейшем имеет смысл обсуждать те пути, которые останутся открытыми.
Решение проблемы загрузки системы ценностей — задача, достойная усилий лучших представителей следующего поколения талантливых математиков. Мы не можем себе позволить откладывать решение этой проблемы до тех времен, когда усовершенствованный ИИ станет настолько разумным, что с легкостью раскусит наши намерения. Как мы уже знаем из раздела об инструментальной конвергенции (глава седьмая), он будет сопротивляться попыткам изменить его конечные цели. Если искусственный агент еще не стал абсолютной дружественным к моменту, когда обрел возможность размышлять о собственной агентской сущности, он вряд ли благосклонно отнесется к нашим планам по «промывке мозгов» или к заговору с целью заменить его на другого агента, отличающегося большим благорасположением к своим создателям и ближайшим соседям.
Естественный отбор
Эволюция уже один раз создала живое существо, наделенное системой ценностей. Этот неоспоримый факт может вдохновить на размышления, что проблему загрузки ценностей в ИИ можно решить эволюционными методами. Однако на этом пути — не столь безопасном, как кажется, — нас ожидают некоторые препятствия. Мы вспоминали о них в конце десятой главы, когда обсуждали, насколько опасными могут быть мощные поисковые процессы.
Эволюцию можно рассматривать в качестве отдельного класса поисковых алгоритмов, предполагающих двухэтапную настройку: на одном этапе — популяция возможных решений расширяется за счет новых кандидатов в соответствии с каким-то простым стохастическим правилом (например, случайной мутацией или половой рекомбинацией), на другом — популяция сокращается за счет отсева кандидатов, показывающих неудовлетворительные результаты тестирования при помощи оценочной функции. Как и в случае многих других типов мощного поиска, есть риск, что этот процесс отыщет решение, действительно удовлетворяющее формально определенному критерию поиска, но не отвечающее нашим моральным ожиданиям. (Это может случиться независимо от того, стремимся ли мы создать цифровой разум, имеющий такие же цели и ценности, как у среднестатистического человека, или, напротив, представляющий собой образец нравственности или идеал покорности.) Такого риска можно избежать, если не ограничиваться одноаспектным запросом на то, что мы хотим разработать, а постараться описать формальный критерий поиска, точно отражающий все измерения нашей цели. Но это уже оборачивается полновесной проблемой загрузки системы ценностей — и тогда нужно исходить из того, что она решена. В этом случае возникает следующая проблема, изложенная Ричардом Докинзом в книге «Река, текущая из рая»:
Общее количество страдания в мире в год превосходит все мыслимые пределы. За минуту, которая потребовалась мне для написания этого предложения, тысячи животных были съедены живьем; спасались от хищников бегством, скуля от страха; медленно погибали из-за пожирающих их изнутри паразитов; умирали от голода, жажды и болезней.
Даже если ограничиться одним нашим видом, то ежедневно погибает сто пятьдесят тысяч человек, и бесконечное количество людей страдает от всевозможных мучений и лишений. Может быть, природа и великий экспериментатор, но на свои опыты она никогда не получит одобрения у совета по этике, поскольку постоянно нарушает Хельсинкскую декларацию со всеми ее этическими нормами, причем с точек зрения и левых, и правых, и центристов. Важно другое: чтобы мы сами не шли слепо по пятам природы и не воспроизводили бездумно in silico все эти ужасы. Правда, вряд ли у нас получится совсем избежать проявлений преступной безнравственности, если мы собираемся создавать искусственный интеллект по образу и подобию человеческого разума, опираясь на эволюционные методы, — чтобы повторить хотя бы на минимальном уровне естественный процесс развития, называемый биологической эволюцией.
Обучение с подкреплением
Обучение с подкреплением — это область машинного обучения, в которой агенты могут учиться максимизировать накопленное вознаграждение. Формируя нужную среду, в которой поощряется любое желательное качество агента, можно создать агента, способного научиться решать широкий круг задач (даже в отсутствие подробной инструкции или обратной связи с программистами, но лишь бы присутствовал сигнал о поощрении). Часто алгоритм обучения с подкреплением включает в себя постепенное построение некоторой функции оценки, которая присваивает значение ценности состояниям, парам состояние–действие и различным стратегическим направлениям. (Например, программа может научиться играть в нарды, используя обучение с подкреплением для постепенного развития навыка оценки позиций на доске.) Можно считать, что эта функция оценки, постоянно меняющаяся с опытом, в том числе включает в себя и обучение нужным целям. Однако то, чему учится агент, это не новые конечные ценности, но все более точные оценки инструментальной ценности достижения определенных состояний (или совершения определенных действий в определенных состояниях, или следования определенной политике). Поскольку конечная цель остается величиной постоянной, мы всегда можем описать агента, проходящего обучение с подкреплением, как агента, имеющего конечную цель. Эта неизменная конечная цель агента — его стремление получать максимальное поощрение в будущем. Вознаграждение состоит из специально разработанных объектов восприятия, помещенных в его окружающую среду. Таким образом, в результате обучения с подкреплением у агента формируется устойчивый эффект самостимуляции (о котором подробно говорилось в главе восьмой), то есть агент начинает выстраивать собственную довольно сложную модель такого мира, который в состоянии предложить ему альтернативный вариант максимизации вознаграждения.
Наши замечания не подразумевают, будто обучение с подкреплением нельзя применять для развития безопасного для нас зародыша ИИ, мы лишь хотим сказать, что его использование следует соотносить с системой мотивации, которая сама по себе не основана на принципе максимизации вознаграждения. Тогда, чтобы решить проблему загрузки системы ценностей, потребуется искать иные подходы, нежели метод обучения с подкреплением.
Ассоциативная модель ценностного приращения
Невольно возникает вопрос: если проблема загрузки системы ценностей столь неподатлива, как нам самим удается обзаводиться ценностной ориентацией?
Одна из возможных (чрезмерно упрощенных) моделей выглядит примерно так. Мы вступаем в жизнь не только с относительно простым набором базовых предпочтений (иначе почему бы мы с детства испытывали неприятные ощущения от каких-то возбудителей и старались инстинктивно избегать этого?), но и с некоторой склонностью к приобретению дополнительных предпочтений, что происходит за счет обогащения опытом (например, у нас начинают формироваться определенные эстетические предпочтения, поскольку мы видим, что в нашем культурном пространстве какие-то цели и идеалы особо ценностны, а какое-то поведение весьма поощряется). И базовые первичные предпочтения, и склонность приобретать в течение жизни ценностные предпочтения являются врожденными чертами человека, сформированными в результате естественного и генетического отбора в ходе эволюции. Однако дополнительные предпочтения, которые складываются у нас к моменту взросления, зависят от жизненного пути. Таким образом, большая часть информационно-семантических моделей, имеющих отношение к нашим конечным ценностям, не заложена генетически, а приобретена благодаря опыту.
Например, в нашей жизни появился любимый человек, и конечно, для нас важнейшей конечной ценностью становится его благополучие. От каких механизмов зависит появление этой ценности? Какие смысловые структуры задействованы в ее формировании? Структур много, но мы возьмем лишь две — понятие «человек» и понятие «благополучие». Ни эти, ни какие другие представления непосредственно не закодированы в нашей ДНК. Скорее, в ДНК хранится информация и инструкции по строительству и развитию нашего мозга, а значит, и нашего разума, который, пребывая в человеческой среде обитания, за несколько лет создает свою модель мира — модель, включающую и дефиницию человека, и дефиницию благополучия. Только после того как сложились эти два представления, можно приступать к объяснению, каким таким особым значением наполнена наша конечная ценность. А теперь вернемся к первому вопросу: от каких механизмов зависит появление наших ценностных предпочтений? Почему желание блага любимому человеку формируется вокруг именно этих обретенных нами представлений, а не каких-то других, тоже обретенных, — вроде представлений о цветочном горшке или штопоре? Вероятно, должен существовать какой-то особый врожденный механизм.
Как работает сам механизм, нам неизвестно. Он, видимо, очень сложный и многогранный, особенно в отношении человека. Поэтому, чтобы хоть как-то понять, как он действует, рассмотрим его примитивную форму на примере животных. Возьмем так называемую реакцию следования (геномный, или родительский, импринтинг), в частности, у выводковых птиц, когда только что вылупившийся, но уже сформированный, птенец сразу начинает неотступно следовать за родителями или первым увиденным движущимся объектом. За каким объектом-«мамой» птенец пожелает двигаться, зависит от его первого опыта, но сам процесс запечатления в памяти соответствующей сенсорной информации (импринтинг) обусловлен генетическими особенностями. Попытаемся провести аналогию с человеческими привязанностями. Когда Гарри встретил Салли, ее благополучие стало для него абсолютной ценностью, но предположим, что они так и не встретились, и Гарри полюбил бы другую; тогда, может быть, его ценностные предпочтения тоже были бы иными. Способность генов человека кодировать механизм выработки целеполагания лишь объясняет, почему наша конечная цель обрастает разнообразными информационно-семантическими моделями, но их сложная организация никак не обусловлена генетически.
Следовательно, возникает вопрос: можно ли построить систему мотивации для искусственного интеллекта, основанную на этом принципе? То есть вместо описания сложной системы ценностей напрямую определить некий механизм, который обеспечил бы приобретение этих ценностей в процессе взаимодействия ИИ с определенной средой.
Похоже, имитировать процесс формирования ценностей, характерный для людей, непросто. Соответствующий человеческий генетический механизм стал результатом колоссальной работы, проделанной эволюцией, и повторить ее работу будет трудно. Более того, механизм, вероятно, рассчитан на нейрокогнитивную систему человека и поэтому неприменим к машинному интеллекту за исключением имитационных моделей. Но даже если полная эмуляция головного мозга окажется возможной, лучше будет начать с загрузки разума взрослого человека — разума, уже содержащего полное представление о некоторой совокупности человеческих ценностей.
Таким образом, попытка разработать модель ценностного приращения, точно имитирующую процесс формирования системы ценностей человека, означает безуспешную серию атак на проблему загрузки ценностей. Но, возможно, мы могли бы создать более простой искусственный механизм импорта в целевую систему ИИ высокоточных представлений о нужных нам ценностях? Чтобы добиться успеха, не обязательно снабжать ИИ точно такой же, как у людей, врожденной склонностью приобретать ценностные предпочтения. Возможно, это даже нежелательно — в конце концов, человеческая природа несовершенна, человек слишком часто делает выбор в пользу зла, что неприемлемо в любой системе, способной получить решающее стратегическое преимущество. Наверное, лучше ориентироваться на систему мотивации, не всегда соответствующей человеческим нормам, например такую, которой свойственна тенденция формировать конечные цели, полные бескорыстия, сострадания и великодушия, — любого, имеющего такие качества, мы сочли бы образцовым представителем человеческого рода. Эти конечные цели должны отклоняться от человеческой нормы в строго определенном направлении, иначе их трудно будет считать улучшениями; кроме того, они должны предполагать наличие неизменной антропоцентричной системы координат, при помощи которой можно делать значимые с человеческой точки зрения оценочные обобщения (чтобы избежать порочной реализации на базе искусственно приемлемых описаний цели, которую мы рассматривали в главе восьмой). Вопрос, насколько такое возможно, по-прежнему остается открытым.
Еще одна проблема, связанная с ассоциативной моделью ценностного приращения, заключается в том, что ИИ может просто отключить этот механизм приращения. Как мы видели в седьмой главе, неприкосновенность целевой системы является его конвергентной инструментальной целью. Достигнув определенной стадии когнитивного развития, ИИ может начать воспринимать продолжающуюся работу механизма приращения как враждебное вмешательство. Это необязательно плохо, но нужно с осторожностью подходить к блокировке целевой системы, чтобы ее отключение произошло в правильный момент: после того, как были приобретены нужные ценности, но до того, как они будут перезаписаны в виде непреднамеренного приращения.
Строительные леса для мотивационной системы
Есть еще один подход к решению проблемы загрузки системы ценностей, который можно назвать «возведение строительных лесов». Подход состоит в наделении зародыша ИИ временными сравнительно простыми конечными целями, которые можно выразить прямым кодированием или каким-то иным доступным способом. Наступит время, и ИИ будет способен формировать более сложные представления. Тогда мы снимем мотивационные «леса» и заменим временные ценности на новые, которые останутся конечной ценностной системой ИИ, даже когда он разовьется в полноценный сверхразум.
Поскольку временные цели — не просто инструментальные, но конечные цели ИИ, можно ожидать, что он будет сопротивляться их замене (неприкосновенность системы целей является конвергентной инструментальной ценностью). В этом и состоит главная опасность. Если ИИ преуспеет в противодействии замене временных целей постоянными, метод потерпит неудачу.
Чтобы избежать такого отказа, необходимо соблюдать осторожность. Например, можно использовать метод контроля над возможностями, чтобы ограничить свободу ИИ до тех пор, пока не будет инсталлирована зрелая система мотивации. В частности, можно попробовать остановить его когнитивное развитие на таком уровне, где можно безопасно и эффективно наделить ИИ желательными для нас конечными целями. Для этого нужно затормозить совершенствование отдельных когнитивных способностей, в частности, таких, которые требуются для выработки стратегии и хитроумных схем в духе Макиавелли, при этом позволив развиваться более безобидным (предположительно) способностям.
Программисты могут попробовать создать атмосферу сотрудничества с ИИ при помощи методов выбора мотивации. Например, использовав такую временную цель, как готовность выполнять команды людей, в том числе команд, предполагающих замену любых имеющихся целей ИИ. К другим временным целям относятся прозрачность ценностей и стратегии ИИ, а также разработка легкой для понимания программистами архитектуры, включающей последнюю версию конечной цели, значимой с точки зрения людей, и мотивированность к приручению (например, к ограничению использования вычислительных ресурсов).
Можно было бы попробовать и такой вариант: со временем заменить зародыш ИИ, наделенный единственной конечной целью, на аналогичную версию зародыша, но уже с другой конечной целью, заданной программистами косвенным образом. С такой заменой связаны некоторые трудности, особенно в контексте подхода к обучению целям, который мы обсудим в следующем разделе. Другие трудности будут рассмотрены в главе тринадцатой.
Метод возведения строительных лесов для мотивационной системы не лишен недостатков. В частности, есть риск, что ИИ станет слишком могущественным прежде, чем будет изменена его временная целевая система. Тогда он может воспротивиться (явно или тайно) усилиям программистов по ее замене на постоянную. В результате на этапе превращения зародыша ИИ в полноценный сверхразум останутся актуальными старые конечные цели. Еще один недостаток состоит в том, что наделение ИИЧУ желательными для разработчиков конечными целями может оказаться не таким простым делом, как в случае более примитивного ИИ. В отличие от него зародыш ИИ представляет собой tabula rasa, позволяя сформировать любую его структуру по желанию программистов. Этот недостаток может превратиться в преимущество, если удастся наделить зародыш ИИ временными целями, благодаря которым он будет стремиться к созданию такой архитектуры, которая поможет разработчикам в их последующих усилиях по заданию ему постоянных конечных целей. Однако пока неясно, легко ли обеспечить наличие у временных целей зародыша ИИ такого свойства, а также будет ли способен даже идеально мотивированный ИИ создать лучшую архитектуру, чем команда программистов-людей.
Обучение ценностям
Теперь переходим к загрузке ценностей — серьезная проблема, которую придется решать довольно мягким методом. Он состоит в обучении ИИ ценностям, которые мы хотели бы ему поставить. Для этого потребуется хотя бы неявный критерий их отбора. Можно настроить ИИ так, чтобы он действовал в соответствии со своими представлениями об этих неявно заданных ценностях. Данные представления он будет уточнять по мере расширения своих знаний о мире.
В отличие от метода мотивационных строительных лесов, когда ИИ наделяется временной конечной целью, которая потом заменяется на отличную от нее постоянную, в методе обучения ценностям конечная цель не меняется на стадии разработки и функционирования ИИ. Обучение меняет не саму цель, а представления ИИ об этой цели.
Таким образом, у ИИ должен быть критерий, при помощи которого он мог бы определять, какие объекты восприятия содержат свидетельства в пользу некоторой гипотезы, что представляет собой конечная цель, а какие — против нее. Определить подходящий критерий может быть трудно. Отчасти эта трудность связана с самой задачей создания ИИ, которому требуется мощный механизм обучения, способный определять структуру окружающего мира на основании ограниченных сигналов от внешних датчиков. Этой проблемы мы касаться не будем. Но даже если считать задачу создания сверхразумного ИИ решенной, остаются трудности, специфические для проблемы загрузки системы ценностей. В случае метода обучения целям они принимают форму определения критерия, который связывает воспринимаемые потоки информации с гипотезами относительно тех или иных целей.
Прежде чем глубже погрузиться в метод обучения ценностям, было бы полезно проиллюстрировать идею на примере. Возьмем лист бумаги, напишем на нем определение какого-то набора ценностей, положим в конверт и заклеим его. После чего создадим агента, обладающего общим интеллектом человеческого уровня, и зададим ему следующую конечную цель: «Максимизировать реализацию ценностей, описание которых находится в этом конверте». Что будет делать агент?
Он не знает, что содержится в конверте. Но может выстраивать гипотезы и присваивать им вероятности, основываясь на всей имеющейся у него информации и доступных эмпирических данных. Например, анализируя другие тексты, написанные человеком, или наблюдая за человеческим поведением и отмечая какие-то закономерности. Это позволит ему выдвигать догадки. Не нужно иметь диплом философа, чтобы предположить, что, скорее всего, речь идет о заданиях, связанных с определенными ценностями: «минимизируй несправедливость и бессмысленные страдания» или «максимизируй доход акционеров», вряд ли его попросят «покрыть поверхность всех озер пластиковыми пакетами».
Приняв решение, агент начинает действовать так, чтобы реализовать ценности, которые, по его мнению, с наибольшей вероятностью содержатся в конверте. Важно, что при этом он будет считать важной инструментальной целью как можно больше узнать о содержимом конверта. Причина в том, что агент мог бы лучше реализовать почти любую конечную ценность, содержащуюся в конверте, если бы знал ее точную формулировку — тогда он действовал бы гораздо эффективнее. Агент также обнаружит конвергентные инструментальные причины (описанные в главе седьмой): неизменность целей, улучшение когнитивных способностей, приобретение ресурсов и так далее. И при этом, если исходить из предположения, что он присвоит достаточно высокую вероятность тому, что находящиеся в конверте ценности включают благополучие людей, он не станет стремиться реализовать эти инструментальные цели за счет немедленного превращения планеты в компьютрониум, тем самым уничтожив человеческий вид, поскольку это будет означать риск окончательно лишиться возможности достичь конечной ценности.
Такого агента можно сравнить с баржей, которую несколько буксиров тянут в разные стороны. Каждый буксир символизирует какую-то гипотезу о конечной ценности. Мощность двигателя буксира соответствует вероятности гипотезы, поэтому любые новые свидетельства меняют направление движения баржи. Результирующая сила перемещает баржу по траектории, обеспечивающей обучение (неявно заданной) конечной ценности и позволяющей обойти мели необратимых ошибок; а позднее, когда баржа достигнет открытого моря, то есть более точного знания конечной ценности, буксир с самым мощным двигателем потянет ее по самому прямому или благоприятному маршруту.
Метафоры с конвертом и баржей иллюстрируют принцип, лежащий в основе метода обучения ценностям, но обходят стороной множество критически важных технических моментов. Они станут заметнее, когда мы начнем описывать этот метод более формально (см. врезку 10).
Как можно наделить ИИ такой целью: «максимизируй реализацию ценностей, изложенных в записке, лежащей в запечатанном конверте»? (Или другими словами, как определить критерий цели — см. врезку 10.) Чтобы сделать это, необходимо определить место, где описаны ценности. В нашем примере это требует указания ссылки на текст в конверте. Хотя эта задача может показаться тривиальной, но и она не без подводных камней. Упомянем лишь один: критически важно, чтобы ссылка была не просто на некий внешний физический объект, но на объект по состоянию на определенное время. В противном случае ИИ может решить, что наилучший способ достичь своей цели — это заменить исходное описание ценности на такое, которое значительно упростит задачу (например, найти большее число для некоторого целого числа). Сделав это, ИИ сможет расслабиться и бить баклуши — хотя скорее за этим последует опасный отказ по причинам, которые мы обсуждали в главе восьмой. Итак, теперь встал вопрос, как определить это время. Мы могли бы указать на часы: «Время определяется движением стрелок этого устройства», — но это может не сработать, если ИИ предположит, что в состоянии манипулировать временем, управляя стрелками часов. И он будет прав, если определять «время» так, как это сделали мы. (В реальности все будет еще сложнее, поскольку соответствующие ценности не будут изложены в письменном виде. Скорее всего, ИИ придется выводить ценности из наблюдений за внешними структурами, содержащими соответствующую информацию, такими как человеческий разум.)
ВРЕЗКА 10. ФОРМАЛИЗАЦИЯ ОБУЧЕНИЯ ЦЕННОСТЯМ
Чтобы яснее понять метод, опишем его более формально. Читатели, которые не готовы погружаться в математические выкладки, могут этот раздел пропустить.
Предположим, что есть упрощенная структура, в которой агент взаимодействует со средой конечного числа моментов. В момент k агент выполняет действие yk, после чего получает ощущение xk. История взаимодействия агента со средой в течение жизни m описывается цепочкой y1x1y2x2…ymxm (которую мы представим в виде yx1:m или yx≤m). На каждом шаге агент выбирает действие на основании последовательности ощущений, полученных к этому моменту.
Рассмотрим вначале обучение с подкреплением. Оптимальный ИИ, обучающийся с подкреплением (ИИ-ОП), максимизирует будущую ожидаемую награду. Тогда выполняется уравнение:
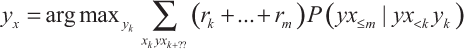
Последовательность подкреплений rk, …, rm вытекает из последовательности воспринимаемых состояний среды xk:m, поскольку награда, полученная агентом на каждом шаге, является частью восприятия, полученного на этом шаге.
Мы уже говорили, что такого рода обучение с подкреплением в нынешних условиях не подходит, поскольку агент с довольно высоким интеллектом поймет, что обеспечит себе максимальное вознаграждение, если сможет напрямую манипулировать сигналом системы наград (эффект самостимуляции). В случае слабых агентов это не будет проблемой, поскольку мы сможем физически предотвратить их манипуляции с каналом, по которому передаются вознаграждения. Мы можем также контролировать их среду, чтобы они получали вознаграждение только в том случае, если их действия согласуются с нашими ожиданиями. Но у любого агента, обучающегося с подкреплением, будут иметься серьезные стимулы избавиться от этой искусственной зависимости: когда его вознаграждения обусловлены нашими капризами и желаниями. То есть наши отношения с агентом, обучающимся с подкреплением, фундаментально антагонистичны. И если агент силен, это может быть опасно.
Варианты эффекта самостимуляции также могут возникнуть у систем, не стремящихся получить внешнее вознаграждение, то есть у таких, чьи цели предполагают достижение какого-то внутреннего состояния. Скажем, в случае систем «актор–критик», где модуль актора выбирает действия так, чтобы минимизировать недовольство отдельного модуля критика, который вычисляет, насколько соответствует поведение актора требуемым показателям эффективности. Проблема этой системы следующая: модуль актора может понять, что способен минимизировать недовольство критика, изменив или вовсе ликвидировав его — как диктатор, распускающий парламент и национализирующий прессу. В системах с ограниченными возможностями избежать этой проблемы можно просто: не дав модулю актора никаких инструментов для модификации модуля критика. Однако обладающий достаточным интеллектом и ресурсами модуль актора всегда сможет обеспечить себе доступ к модулю критика (который фактически представляет собой лишь физический вычислительный процесс в каком-то компьютере).
Прежде чем перейти к агенту, который проходит обучение ценностям, давайте в качестве промежуточного шага рассмотрим другую систему, максимизирующую полезность на основе наблюдений (ИИ-МНП). Она получается путем замены последовательности подкреплений (rk + … + rm) в ИИ-ОП на функцию полезности, которая может зависеть от всей истории будущих взаимодействий ИИ:
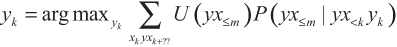
Эта формула позволяет обойти проблему самостимуляции, поскольку функцию полезности, зависящую от всей истории взаимодействий, можно разработать так, чтобы наказывать истории взаимодействия, в которых проявляются признаки самообмана (или нежелания агента прикладывать достаточные усилия, чтобы получить точную картину действительности).
Таким образом, ИИ-МНП дает возможность обойти проблему самостимуляции в принципе. Однако, чтобы ею воспользоваться, нужно задать подходящую функцию полезности на классе всех возможных историй взаимодействия — а это очень трудная задача.
Возможно, более естественным было бы задать функцию полезности непосредственно в терминах возможных миров (или свойств возможных миров, или теорий о мире), а не в терминах историй взаимодействия агента. Используя этот подход, формулу оптимальности ИИ-МНП можно переписать и упростить:
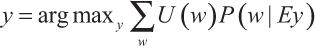
Здесь E — это все свидетельства, доступные агенту (в момент, когда он принимает решение), а U — функция полезности, которая присваивает полезность некоторому классу возможных миров. Оптимальный агент будет выбирать действия, которые максимизируют ожидаемую полезность.
Серьезная проблема этих формул — сложность задания функции полезности. И это наконец возвращает нас к проблеме загрузки ценностей. Чтобы функцию полезности можно было получить в процессе обучения, мы должны расширить наше формальное определение и допустить неопределенность функции полезности. Это можно сделать следующим образом (ИИ-ОЦ):
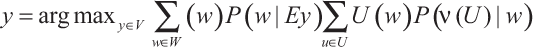
где v(—) — функция от функций полезности для предположений относительно функций полезности. v(U) — предположение, что функция полезности U удовлетворяет критерию ценности, выраженному v.
То есть чтобы решить, какое действие выполнять, нужно действовать следующим образом: во-первых, вычислить условную вероятность каждого возможного мира w (учитывая все возможные свидетельства и исходя из предположения, что должно быть выполнено действие y); во-вторых, для каждой возможной функции U вычислить условную вероятность того, что U удовлетворяет критерию ценности v (при условии, что w — это реальный мир); в-третьих, для каждой возможной функции полезности U вычислить полезность возможного мира w; в-четвертых, использовать все эти значения для расчета ожидаемой полезности действия y; в-пятых, повторить эту процедуру для всех возможных действий и выполнить действие, имеющее самую высокую ожидаемую полезность (используя любой метод выбора из равных значений в случае возникновения таковых). Понятно, что таким образом описанная процедура — предполагающая явное рассмотрение всех возможных миров — вряд ли реализуема с точки зрения потребности в вычислительных ресурсах. ИИ придется использовать обходные пути, чтобы аппроксимировать это уравнение оптимальности.
Остается вопрос, как определить критерий ценности v. Если у ИИ появится адекватное представление этого критерия, он, в принципе, сможет использовать свой интеллект для сбора информации о том, какие из возможных миров с наибольшей вероятностью могут оказаться реальными. После чего применить критерий ценности для каждого потенциально реального мира, чтобы выяснить, какая целевая функция удовлетворяет критерию в мире w. То есть формулу ИИ-ОЦ можно считать одним из способов идентифицировать и выделить ключевую сложность в методе обучения ценностям — как представить v. Формальное описание задачи высвечивает также множество других сложностей (например, как определить Y, W и U), с которыми придется справиться прежде, чем метод можно будет использовать.
Другая трудность кодирования цели «максимизируй реализацию ценностей из конверта» заключается в том, что даже если в этом письме описаны все правильные ценности и система мотивации ИИ успешно воспользуется этим источником, ИИ может интерпретировать описания не так, как предполагалось его создателями. Это создаст риск порочной реализации, описанной в главе восьмой.
Поясним, что трудность здесь даже не в том, как добиться, чтобы ИИ понял намерения людей. Сверхразум справится с этим без проблем. Скорее, трудность заключается в том, чтобы ИИ был мотивирован на достижение описанных целей так, как предполагалось. Понимание наших намерений это не гарантирует: ИИ может точно знать, что мы имели в виду, и не обращать никакого внимания на эту интерпретацию наших слов (используя в качестве мотивации иную их интерпретацию или вовсе на них не реагируя).
Трудность усугубляется тем, что в идеале (по соображениям безопасности) правильную мотивацию следует загрузить в зародыш ИИ до того, как он сможет выстраивать представления любых человеческих концепций и начнет понимать намерения людей. Это потребует создания какого-то когнитивного каркаса, в котором будет предусмотрено определенное место для системы мотивации ИИ как хранилища его конечных ценностей. Но у ИИ должна быть возможность изменять этот когнитивный каркас и развивать свои способности представления концепций по мере узнавания мира и роста интеллекта. ИИ может пережить эквивалент научной революции, в ходе которой его модель мира будет потрясена до основания, и он, возможно, столкнется с онтологическим кризисом, осознав, что его предыдущее видение целей было основано на заблуждениях и иллюзиях. При этом, начиная с уровня интеллекта, еще не достигающего человеческого, и на всех остальных этапах развития, вплоть до сверхразума галактических масштабов, поведение ИИ должно определяться, по сути, неизменной конечной системой ценностей, которую благодаря этому развитию ИИ понимает все лучше; при этом зрелый ИИ, скорее всего, будет понимать ее совсем не так, как его разработчики, хотя эта разница возникнет не в результате случайных или враждебных действий ИИ, но скорее из добрых побуждений. Как бороться с этим, еще неясно (см. врезку 11).
Подводя итоги, стоит сказать, что пока неизвестно, как использовать метод обучения ценностям для формирования у ИИ ценностной системы, приемлемой для человека (впрочем, некоторые новые идеи можно найти во врезке 12). В настоящее время этот метод следует считать скорее перспективным направлением исследований, нежели доступной для применения техникой. Если удастся заставить его работать, он может оказаться почти идеальным решением проблемы загрузки ценностей. Помимо прочих преимуществ, его использование станет естественным барьером для проявлений с нашей стороны преступной безнравственности, поскольку зародыш ИИ, способный догадаться, какие ценностные цели могли загрузить в него программисты, может додуматься, что подобные действия не соответствуют этим ценностям и поэтому их следует избегать как минимум до тех пор, пока не будет получена более определенная информация.
Последний, но немаловажный, вопрос — что положить в конверт? Или, если уйти от метафор, каким ценностям мы хотели бы обучить ИИ? Но этот вопрос одинаков для всех методов решения проблемы загрузки ценностей. Вернемся к нему в главе тринадцатой.
ВРЕЗКА 11. ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ, КОТОРЫЙ ХОЧЕТ БЫТЬ ДРУЖЕСТВЕННЫМ
Элиезер Юдковский попытался описать некоторые черты архитектуры зародыша ИИ, которая позволила бы ему вести себя так, как описано выше. В его терминологии такой ИИ должен использовать «семантику внешних ссылок». Чтобы проиллюстрировать основную идею Юдковского, давайте предположим, что мы хотим создать дружественный ИИ. Его исходная цель — попытаться представить себе некое свойство F, но изначально ИИ почти ничего об F не знает. Ему известно лишь, что F — некоторое абстрактное свойство. И еще он знает, что когда программисты говорят о дружественности, они, вероятно, пытаются передать информацию об F. Поскольку конечной целью ИИ является составление формулировки понятия F, его важной инструментальной целью становится больше узнать об F. По мере того как ИИ узнает об F все больше, его поведение все сильнее определяется истинным содержанием этого свойства. То есть можно надеяться, что чем больше ИИ узнаёт и чем умнее становится, тем более дружелюбным он становится.
Разработчики могут содействовать этому процессу и снизить риск того, что ИИ совершит какую-то катастрофическую ошибку, пока не до конца понимает значение F, обеспечивая его «заявлениями программистов» — гипотезами о природе и содержании F, которым изначально присваивается высокая вероятность. Например, можно присвоить высокую вероятность гипотезе «вводить программистов в заблуждение недружественно». Однако такие заявления не являются «истиной по определению», аксиомами концепции дружелюбия. Скорее всего, это лишь начальные гипотезы, которым рациональный ИИ будет присваивать высокую вероятность как минимум до тех пор, пока доверяет эпистемологическим способностям программистов больше, чем своим.
Юдковский также предложил использовать то, что он называет «семантика причинной валидности». Идея состоит в том, чтобы ИИ делал не в точности то, что программисты говорят ему делать, но скорее то, что они пытались ему сказать сделать. Пытаясь объяснить зародышу ИИ, что такое дружелюбие, они могли совершить ошибку в своих объяснениях. Более того, сами программисты могли не до конца понимать истинную природу дружелюбия. Поэтому хочется, чтобы ИИ мог исправлять ошибки в их умозаключениях и выводить истинное или предполагавшееся значение из неидеальных объяснений, которые дали ему программисты. Например, воспроизводить причинные процессы появления представлений о дружелюбии у самих программистов и о способах его описания; понимать, что в процессе ввода информации об этом свойстве они могли сделать опечатку; попытаться найти и исправить ее. В более общем случае ИИ следует стремиться исправить последствия любого вмешательства, искажающего поток информации о характере дружелюбия, на всем ее пути от программистов до ИИ (где «искажающий» понимается в эпистемологическом смысле). В идеале по мере созревания ИИ ему следует преодолеть все когнитивные искажения и прочие фундаментально ошибочные концепции, которые могли бы помешать программистам до конца понять, что такое дружелюбие.
ВРЕЗКА 12. ДВЕ НОВЕЙШИЕ ИДЕИ — ПРАКТИЧЕСКИ НЕЗРЕЛЫЕ, ПОЧТИ ПОЛУСЫРЫЕ
Подход, который можно назвать «Аве Мария», основан на надежде, что где-то во Вселенной существуют (или вскоре возникнут) цивилизации, успешно справившиеся со взрывным развитием интеллекта и в результате пришедшие к системам ценностей, в значительной степени совпадающим с нашими. В этом случае мы можем попробовать создать свой ИИ, который будет мотивирован делать то же, что и их интеллектуальные системы. Преимущества этого подхода состоят в том, что так создать нужную мотивацию у ИИ может быть легче, чем напрямую.
Чтобы эта схема могла сработать, нашему ИИ нет необходимости связываться с каким-то инопланетным ИИ. Скорее, в своих действиях он должен руководствоваться оценками того, что тот мог бы захотеть сделать. Наш ИИ мог бы смоделировать вероятные исходы взрывного развития интеллекта где-то еще, и по мере превращения в сверхразум делать это все точнее. Идеальных знаний от него не требуется. У взрывного развития интеллекта может быть широкий диапазон возможных исходов, и нашему ИИ нужно постараться определиться с предпочтениями относительно типов сверхразума, которые могут быть связаны с ними, взвешенными на их вероятности.
В этой версии подхода «Аве Мария» требуется, чтобы мы разработали конечные ценности для нашего ИИ, согласующиеся с предпочтениями других систем сверхразума. Как это сделать, пока до конца неясно. Однако структурно сверхразумные агенты должны отличаться, чтобы мы могли написать программу, которая служила бы детектором сверхразума, анализируя модель мира, возникающую в нашем развивающемся ИИ, в поиске характерных для сверхразума элементов представления. Затем программма-детектор могла бы каким-то образом извлекать предпочтения рассматриваемого сверхразума (из его представления о нашем ИИ). Если нам удастся создать такой детектор, его можно будет использовать для определения конечных ценностей нашего ИИ. Одна из трудностей заключается в том, что нам нужно создать такой детектор раньше, чем мы будем знать, какой каркас представления разработает наш ИИ. Программа-детектор должна уметь анализировать незнакомые каркасы представления и извлекать предпочтения представленных в них систем сверхразума. Это кажется непростой задачей, но, возможно, какое-то ее решение удастся найти.
Если получиться реализовать основной подход, можно будет немедленно заняться его улучшением. Например, вместо того чтобы следовать предпочтениям (точнее, их некоторой взвешенной композиции) каждого инопланетного сверхразума, у нашего ИИ может иметься фильтр для отбора подмножества инопланетных ИИ (чтобы он мог брать пример с тех, чьи ценности совпадают с нашими). Например, в качестве критерия включения ИИ в это подмножество может использоваться источник его возникновения. Некоторые обстоятельства создания ИИ (которые мы должны уметь определить в структурных терминах) могут коррелировать с тем, в какой степени появившийся в результате ИИ может разделять наши ценности. Возможно, большее доверие у нас вызовут ИИ, первоисточником которых была полная эмуляция головного мозга, или зародыш ИИ, в котором почти не использовались эволюционные механизмы, или такие, которые возникли в результате медленного контролируемого взлета. (Если брать в расчет источник возникновения ИИ, мы также сможем избежать опасности присвоить слишком большой вес тем ИИ, которые создают множество своих копий, — а на самом деле избежать создания для них стимула делать это.) Можно также внести в этот подход множество других улучшений.
Подход «Аве Мария» подразумевает веру, что где-то существуют другие системы сверхразума, в значительной степени разделяющие наши ценности. Это означает, что он неидеален.
Однако технические препятствия, стоящие на пути реализации подхода «Аве Мария», хотя и значительны, но вполне могут оказаться менее сложными, чем при других подходах. Может быть, имеет смысл изучать подходы пусть и не самые идеальные, но более простые в применении, — причем не для использования, а скорее, чтобы иметь запасной план на случай, если к нужному моменту идеальное решение не будет найдено.
Недавно Пол Кристиано предложил еще одну идею решения проблемы загрузки ценностей. Как и при «Аве Марии», это метод обучения ценностям, который предполагает определение критерия ценности не при помощи трудоемкой разработки, а скорее фокусировки. В отличие от «Аве Марии», здесь не предполагается существования других сверхразумных агентов, которые мы используем в качестве ролевых моделей для нашего собственного ИИ. Предложение Кристиано с трудом поддается короткому объяснению — оно представляет собой цепочку сложных умозаключений, — но можно попытаться как минимум указать на его основные элементы.
Предположим, мы получаем: а) математически точное описание мозга конкретного человека; б) математически строго определенную виртуальную среду, содержащую идеализированный компьютер с произвольно большим объемом памяти и сверхмощным процессором. Имея а и б, можно определить функцию полезности U как выходной сигнал, который выдает мозг человека после взаимодействия с этой средой. U может быть математически строго определенным объектом, но при этом таким, который (в силу вычислительных ограничений) мы неспособны описать конкретно. Тем не менее U может служить в качестве критерия ценности при обучении ИИ системе ценностей. При этом ИИ будет использовать различные эвристики, чтобы строить вероятностные гипотезы о том, что представляет собой U.
Интуитивно хочется, чтобы U была такой функцией полезности, которую нашел бы соответствующим образом подготовленный человек, обладающий произвольно большим объемом вычислительных ресурсов, достаточным, например, для создания астрономически большого количества своих имитационных моделей, способных помогать ему в поиске функции полезности или в разработке процесса ее поиска. (Мы сейчас затронули тему конвергентного экстраполированного волеизъявления, которую подробнее рассмотрим в тринадцатой главе.)
Задача описания идеализированной среды кажется относительно простой: мы можем дать математическое описание абстрактного компьютера с произвольно большой емкостью; а также при помощи программы виртуальной реальности описать, скажем, комнату со стоящим в ней компьютерным терминалом (олицетворяющим тот самый абстрактный компьютер). Но как получить математически точное описание мозга конкретного человека? Очевидный путь — его полная эмуляция, но что если эта технология еще не доступна?
Именно в этом и проявляется ключевая инновация, предложенная Кристиано. Он говорит, что для получения математически строгого критерия цели нам не нужна пригодная для практического использования вычислительная имитационная модель мозга, которую мы могли бы запустить. Нам нужно лишь (возможно, неявное и безнадежно сложное) ее математическое определение — а его получить гораздо легче. При помощи функциональной нейровизуализации и других средств измерения можно собрать гигабайты данных о связях между входными и выходными сигналами головного мозга конкретного человека. Собрав достаточное количество данных, можно создать наиболее простую имитационную математическую модель, которая учитывает все эти данные, и эта модель фактически окажется эмулятором рассматриваемого мозга. Хотя с вычислительной точки зрения нам может оказаться не под силу задача отыскать такую имитационную модель из имеющихся у нас данных, опираясь на них и используя математически строгие показатели сложности (например, какой-то вариант колмогоровской сложности, с которой мы познакомились во врезке 1 в первой главе), вполне реально эту модель определить.
Вариации имитационной модели
Проблема загрузки ценностей выглядит несколько иначе, если речь идет не об искусственном интеллекте, а об имитационной модели головного мозга. Во-первых, к эмуляторам неприменимы методы, предполагающие понимание процессов на нижнем уровне и контроль над алгоритмами и архитектурой. Во-вторых, имея дело с имитационными моделями головного мозга (и улучшенным биологическим разумом) можно использовать неприменимый для искусственного интеллекта метод приумножения (из общей группы методов выбора мотивации).
Метод приумножения можно сочетать с техниками корректировки изначально имеющихся у системы целей. Например, можно попробовать манипулировать мотивационными состояниями эмуляторов, управляя цифровым эквивалентом психоактивных веществ (или реальных химических веществ, если речь идет о биологических системах). Сегодня уже есть возможность манипулировать целями и мотивацией при помощи лекарственных препаратов, правда, в ограниченной степени. Но фармакология будущего сможет предложить лекарства с гораздо более точным и предсказуемым эффектом. Благодаря цифровой среде, в которой существуют эмуляторы, все эти действия существенно упростятся — в ней гораздо легче проводить контролируемые эксперименты и получать непосредственный доступ к любым областям цифрового мозга.
Как и при проведении опытов над живыми существами, эксперименты на имитационных моделях связаны с этическими трудностями, которые невозможно урегулировать лишь с помощью формы информированного согласия. Подобные довольно трудноразрешимые проблемы могут перерасти в настоящие конфликты, тормозящие развитие проектов, связанных с полной эмуляцией головного мозга (скорее всего, будут введены новые этические стандарты и нормативные акты). Сильнее всего это скажется на исследованиях механизмов мотивационной структуры эмуляторов. Результат может оказаться плачевным: из-за недостаточного изучения методов контроля над возможностями имитационных моделей и методов корректировки их конечных целей когнитивные способности эмуляторов начнут неуправляемо совершенствоваться, пока не достигнут потенциально опасного сверхразумного уровня. Более того, вполне реально, что в ситуации, когда этические вопросы будут стоять особенно остро, вперед вырвутся наименее щепетильные проектные группы и государства. В то же время если мы снизим свои этические стандарты, то в процессе экспериментальной работы с оцифрованным человеческим разумом ему может быть причинен непоправимый вред, что абсолютно неприемлемо. В любом случае нам придется нести полную ответственность за собственное недобросовестное поведение и нанесенный ущерб имитационным моделям.
При прочих равных условиях соображения этического порядка, скорее всего, заставят нас отказаться от проведения опытов над цифровыми копиями людей. В такой критическо-стратегической ситуации мы будем вынуждены искать альтернативные пути, не требующие столь активного изучения биологического мозга.
Однако не все так однозначно. Готов выслушать ваши возражения: исследования, связанные с полной эмуляцией головного мозга, с меньшей вероятностью будут вызывать этические проблемы, чем разработки в области искусственного интеллекта, на том основании, что нам легче проследить момент становления, когда право на моральный статус начнет обретать именно эмулятор, а не совершенно чужеродный искусственный разум. Если ИИ определенного типа или какие-то его подпроцессы обретут значительный моральный статус прежде, чем мы это распознаем, этические последствия могут быть огромными. Возьмем, например, невероятную легкость, с которой современные программисты создают агентов для обучения с подкреплением и применяют к ним негативные раздражители. Ежедневно создается бесчисленное количество таких агентов, причем не только в научных лабораториях, но и в многочисленных фирмах, где разрабатываются разные приложения и создаются компьютерные игры, содержащие множество сложных персонажей. Предположительно, эти агенты еще слишком примитивны, чтобы претендовать на какой-то моральный статус. Но можем ли мы быть уверены на все сто процентов? И еще одно важное замечание: можем мы быть уверены, что узнаем, в какой момент следует остановиться, чтобы программы не начали испытывать страдания?
(В четырнадцатой главе мы вернемся к некоторым более общим стратегическим вопросам, которые возникают при сравнении двух процессов: проведения полной эмуляции головного мозга и создания искусственного интеллекта.)
Институциональное конструирование
Существуют интеллектуальные системы, чьи составляющие сами являются агентами, обладающими интеллектом. В нашем, пока еще человеческом, мире примерами таких систем являются государства и корпорации — они состоят из людей, но в отдельных случаях сами институты могут рассматриваться как самостоятельные, функционально независимые агенты. Мотивация такой сложной системы, как учреждение, зависит не только от мотивов составляющих ее субагентов, но и от того, как эти субагенты организованы. Например, институциональная система диктаторского типа может вести себя так, словно обладает волей, аналогичной воле одного-единственного субагента, исполняющего роль диктатора, а институциональная система демократического типа, напротив, ведет себя так, как будто аккумулирует в себе интересы всех субагентов и выражает совокупную волю всех участников. Однако можно представить такие институты управления, при которых организация не выражает совокупные интересы составляющих ее субагентов. (Теоретически вполне возможно существование тоталитарного государства, дружно ненавидимое всем его населением, поскольку властная структура обладает мощным аппаратом подавления, не допускающим даже мысли о каком бы то ни было гражданском противостоянии — ни о скоординированном восстании, ни об отдельных протестах. В итоге гражданам, не имеющим права ни на всеобщее, ни на одиночное возмущение, остается лишь выполнять функцию винтиков государственной машины.)
Таким образом, создавая соответствующие институты для сложных систем, можно предринять попытки сразу формировать эффективные системы мотивации. В девятой главе мы обсуждали социальную интеграцию как один из вариантов метода контроля над возможностями. Теперь нам надо рассмотреть вопрос социальной интеграции с точки зрения стимулов, с которыми сталкивается агент, существующий в социальном мире равных ему субъектов. Мы сосредоточим внимание на том, что происходит внутри конкретного агента: каким образом его воля определяется его внутренней организацией. Поскольку устройство института такого рода не зависит от крупномасштабного социального инжиниринга или реформ, метод выбора мотивации применим в условиях отдельного проекта создания сверхразума, даже если социоэкономическая среда и международная обстановка не самые благоприятные.
Вероятно, правильнее всего было бы использовать институциональное конструирование в сочетании с методом приумножения. Если мы можем начать с агентов, уже обладающих требуемой мотивацией или даже аналогичной человеческой, то институциональные механизмы и меры предосторожности повысят гарантии, что система не свернет с правильного пути.
Предположим, мы начали с некоторых хорошо мотивированных агентов человеческого типа, например имитационных моделей. Нам требуется повысить когнитивные возможности этих агентов, но нас беспокоит, что совершенствование может нарушить их мотивационную систему. Один из способов справиться с этой проблемой — создать что-то типа организации, в которой отдельные эмуляторы действуют как субагенты. Каждая последующая процедура усовершенствования будет применяться по отношению лишь к небольшой части таких субагентов, а его влияние — оцениваться путем сравнения их поведения с поведением контрольной группы субагентов, не подвергавшихся процедуре улучшения. Когда подтвердится, что совершенствование когнитивных способностей эмуляторов не вредит их мотивации, то процедуру можно начать применять ко всей популяции субагентов. Если выяснится, что система мотивации улучшенных субагентов пострадала, они выключаются из дальнейших планов усовершенствования и не допускаются к процессу принятия основных решений (минимум до тех пор, пока организационная система в целом не разовьется до такой степени, что сможет безопасно их реинтегрировать). Хотя субагенты с пострадавшей мотивацией могли бы в результате улучшения получить определенное преимущество, они не в состоянии захватить власть в организационной системе или «заразить» своей погрешностью всех остальных, поскольку представляют собой небольшое меньшинство всего сообщества субагентов. То есть коллективный интеллект и возможности системы будут постепенно повышаться в результате последовательных небольших шагов, притом что правильность каждого шага проверяется субагентами, обладающими не намного меньшими способностями, чем субагенты, появляющиеся в результате очередного шага.
Степень безопасности, которая достигается за счет такого институционального конструирования, ограничена точностью тестов, применяющихся для оценки улучшенных субагентов. Разработка тестов усложняется тем, что оцениваемые параметры могут быть проверены лишь на небольшом диапазоне когнитивных способностей, а применяться они должны к агентам в том числе за пределами этого диапазона. Можно отчасти снять эту проблему, если проводить усовершенствование последовательно, шаг за шагом, и проверку на протяжении длительного времени. Однако такие меры предосторожности повысят издержки и замедлят прогресс (а в случае конкурентной гонки это будет означать, что проект, принимающий такие меры, окажется в невыгодном положении). И даже если идти вперед небольшими шагами и проводить интенсивное тестирование, остается некоторый риск появления небольших дефектов, которые постепенно приведут к деградации всю систему целей — деградации, способной проявиться лишь на этапе достижения системой уровня сверхразума. Риск можно несколько снизить, расширив условие тестирования на множество шагов улучшений, чтобы даже те агенты, которые успешно прошли проверку на каком-то этапе и были подвергнуты последующим улучшениям, продолжали бы сравниваться с контрольной группой немодифицированных агентов с изначально правильной системой мотивации.
В идеале такое тестирование должно проходить непрерывно, а не ограничиваться первоначальным периодом оценки. У субагентов человеческого уровня имеются стратегические способности, и они могут скрывать некоторые цели в ходе контрольных проверок их поведения. Чтобы сделать возможным непрерывное тестирование, можно создать иерархию, в рамках которой одни субагенты выполняли задачу по контролю над другими субагентами с несколько более высоким уровнем способностей. На нижней иерархической ступеньке способностей (но на вершине властной иерархии) окажется самый недалекий и «заторможенный» принципал. Он будет напоминать слабоумного короля, который отдает распоряжение недееспособному двору, а тот, в свою очередь, контролирует посредственное правительство, управляющее талантливыми людьми. Еще его можно сравнить с древним «мозгом рептилий», который следит за тем, чтобы более молодой и гораздо более развитый «неокортекс» отвечал за выполнение таких функций, как питание и совокупление.
Может возникнуть вопрос, а будет ли такая перевернутая меритократия стабильной? Если окажется, что мотивация значительного количества сверхразумных агентов нарушена, и люди, отвечающие за проект в целом, попытаются «откатить» часть улучшений, окажется ли эта институциональная структура достаточно прочной для того, чтобы выдержать сопротивление, вызванное этим шагом? В контексте исторических и современных человеческих обществ ответ, скорее всего, будет отрицательным. (Нельзя сказать, что к власти приходят только самые способные люди, но и сказать, что нами в прямом смысле управляют шимпанзе, тоже нельзя.) Однако этот вопрос оказывается гораздо более сложным, когда общество представляет собой совокупность компьютерных программ.
Представьте цифровую иерархию, в которой на каждых двух пролетариев приходится по одному хорошо обученному полицейскому агенту. А на каждых двух обычных полицейских агентов — один специальный полицейский агент. Еще есть специальный специальный полицейский агент на каждых двух просто специальных — и так далее, так что над каждым уровнем контролеров имеется уровень с как минимум в два раза меньшим количеством контролеров. Представьте также структуру этого общества, при которой контролер обладает большими полномочиями в отношении подконтрольных ему агентов. Например, может видеть и записывать все, что они говорят и делают, как если был бы скрыт от них зеркальным стеклом — из-за этого стекла подконтрольные агенты получают лишь приказы и инструкции, которые отбирал сам контролер. Еще нужно представить, что перед каждым контролером есть приборная панель с кнопками, нажимая которые он может в любой момент соответственно наказать, вознаградить, поставить на паузу, удалить или вернуть в предыдущее состояние своего подконтрольного агента. Благодаря этим возможностям власть агента-контролера выходит далеко за исторические рамки того, что встречалось даже в наиболее тоталитарных организациях.
Но даже этим инструменты контроля не исчерпываются. В распоряжении контролеров могут иметься реалистичные симуляторы виртуальной реальности, которые они могут использовать для моделирования гипотетических сценариев, чтобы провоцировать подконтрольных агентов и изучать их реакции (например, предлагать принять участие в заговоре или немного расслабиться, уверяя, что их никто не видит). Кроме того, контролеры могут «влезать в умы» подконтрольных агентов, подслушивая их внутренние монологи и напрямую манипулируя их эмоциональным состоянием.
То есть у контролера имеется огромное преимущество. Но каждый контролер является подконтрольным агентом другого контролера более высокого уровня, который, в свою очередь, наблюдает за каждым его шагом и следит, чтобы он не ослаблял усилий в деле исполнения своих контрольных функций. Таким образом, продуманная структура может быть стабильной даже в том случае, когда интеллектуально контролеры на всех уровнях иерархии слабее тех, кого контролируют. И всю эту структуру, включающую множество сверхразумных агентов, может контролировать небольшое количество людей с административным доступом.
Издержки, связанные с такой структурой внутреннего контроля, могут быть значительными, но не запредельно высокими. Например, в модели, где на каждом уровне членов в два раза меньше, чем уровнем ниже, издержки на дополнительные вычисления ограничены всего лишь ста процентами от того, что требуется для «пролетарской» части системы, — или даже меньшей величиной, если более глупый босс требует меньше вычислений в расчете на субагента. За счет увеличения этого показателя можно усилить контроль, за счет понижения — уменьшить издержки. Дополнительные вычислительные издержки будут главным фактором при сценарии конкурентного рыночного мира (см. ), но в контексте проекта, не имеющего сильных непосредственных конкурентов, их роль довольно умеренная. Также потребуются затраты времени разработчиков на создание и тестирование всего этого контрольного функционала. Их можно снизить, если в рамках обладающего большими ресурсами проекта распараллелить работу над контрольной структурой и самим искусственным интеллектом; но их тяжесть будет непомерной при небольших проектах и проектах, участвующих в напряженной технологической гонке.
Также заслуживает внимания еще один тип издержек в структурах такого рода — риск проявления преступной безнравственности. Описанная нами институция выглядит как страшный северокорейский трудовой лагерь. Однако возможности ослабить этические проблемы, связанные с его работой, есть даже в том случае, когда составляющие его субагенты являются эмуляторами с моральным статусом, соответствующим человеческому. В самом крайнем случае он может быть основан на добровольном участии в нем. Причем у каждого субагента должно быть право в любой момент прекратить свое участие. Стертые имитационные модели могут храниться в памяти с обязательством восстановить их в более подходящих условиях, когда минует опасная стадия взрывного развития интеллекта. Тем временем субагенты, решившие участвовать в системе, могут размещаться в очень комфортабельных виртуальных условиях и иметь достаточно времени для сна и отдыха. Эти меры также предполагают затраты, которые, однако, вполне по силам проекту, обладающему большими ресурсами и не имеющему прямых конкурентов. Но в высококонкурентной среде эти расходы могут быть неприемлемыми — утешит лишь уверенность, что конкуренты их тоже несут.
В нашем примере мы предположили, что субагенты являются эмуляторами, то есть имитационными моделями головного мозга человека. Может возникнуть вопрос: потребует ли метод институционального конструирования, чтобы субагенты были антропоморфными? Или он равноприменим к системам, состоящим из искусственных субагентов?
Возможный скепсис в этом вопросе понятен. Известно, что несмотря на весь наш огромный опыт наблюдения за агентами-людьми, мы до сих пор не в состоянии предсказывать начало и исход революций: социальные науки могут в лучшем случае описать некоторые их статистические закономерности. А поскольку мы не можем надежно предсказывать стабильность социальных структур, состоящих из обычных человеческих существ (о которых знаем так много), возникает соблазн заключить, что у нас нет надежды выстроить стабильные социальные структуры для когнитивно улучшенных человекоподобных агентов (о которых мы не знаем ничего), и тем более для ИИ-агентов (которые даже не похожи на агентов, о которых мы что-то знаем).
Однако все не так уж плохо. Люди и человекоподобные субъекты чрезвычайно сложны, в то время как искусственные агенты могут иметь сравнительно простую архитектуру. У искусственных агентов также может быть простая и явно задаваемая мотивация. Более того, цифровые агенты в целом (и эмуляторы и ИИ) поддаются копированию: это преимущество способно вызвать революцию в управлении, как взаимозаменямые комплектующие вызвали революцию в производстве. Эти отличия в сочетании с возможностью работать с агентами, которые вначале бессильны, и создавать институциональные структуры, в которых используются перечисленные выше методы контроля, могут сделать возможным получение нужного институционального результата — например, системы, в которой не будет революций, — причем с большей вероятностью, чем в случае с людьми.
Впрочем, нужно сказать, что у искусственных агентов могут отсутствовать многие свойства, знание которых позволяет нам прогнозировать поведение человекоподобных агентов. Им не нужно иметь никаких социальных эмоций, которые определяют человеческое поведение, таких как страх, гордость и угрызения совести. Им не нужны дружественные и семейные связи. Им не нужен «язык тела», который не позволяет нам, людям, скрыть свои намерения. Эти факторы могут дестабилизировать организации, состоящие из искусственных агентов. Более того, такие агенты способны совершать большие скачки в когнитивной производительности в результате внешне незначительных изменений в их алгоритмах или архитектуре. Безжалостно оптимальные искусственные агенты будут готовы пускаться в такие рискованные авантюры, результатом которых может стать сокращение размеров человечества. А еще агенты, обладающие сверхразумом, смогут удивить нас способностью координировать свои действия, почти или совсем не связываясь друг с другом (например, посредством внутреннего моделирования гипотетической реакции партнеров на различные обстоятельства).
Эти и другие особенности повышают вероятность внезапного краха организации, состоящей из искусственных агентов, невзирая даже на, казалось бы, пуленепробиваемые методы социального контроля.
Итак, пока неясно, насколько многообещающим является метод институционального конструирования и будет ли он более эффективным в случае антропоморфных, нежели искусственных, агентов. Может показаться, что создание института с адекватной системой сдержек и противовесов повысит нашу безопасность — или по крайней мере не снизит ее, — поэтому с точки зрения снижения рисков данный метод лучше применять всегда. Но на самом деле даже это нельзя сказать с определенностью. Использование метода повышает сложность системы, создавая тем самым новые возможности для неблагоприятного развития ситуации, которые отсутствуют в случае агентов, не имеющих в качестве составляющих интеллектуальных субагентов. Тем не менее метод институционального конструирования заслуживает дальнейшего изучения.
Резюме
Инжиниринг системы целей — еще не установленная дисциплина. Пока нет полной ясности в том, как загружать в компьютер человеческие ценности, даже если речь идет о машинном интеллекте человеческого уровня. Изучив множество подходов, мы обнаружили, что некоторые из них, похоже, ведут в тупик, но есть и такие, которые кажутся многообещающими и должны стать предметом дальнейшего анализа. Обобщим изученный материал в табл. 12.
Таблица 12. Обобщение методов загрузки ценностей
| Представление в явной форме | Кажется многообещающим в качестве способа загрузки ценностей при использовании метода приручения. Вряд ли полезен в случае более сложных целей |
| Естественный отбор | Менее перспективный. Полным перебором можно обнаружить схемы, удовлетворяющие формальному критерию поиска, но не соответствующие нашим намерениям. Более того, если варианты схем оценивать путем их реализации — включая те, которые не удовлетворяют даже формальному критерию, — резко повышаются риски. В случае применения метода естественного отбора сложнее избежать преступной безнравственности, особенно если мозг агентов похож на человеческий |
| Обучение с подкреплением | Для решения задачи обучения с подкреплением могут использоваться различные методы, но обычно это происходит путем создания системы, которая стремится максимизировать сигнал о вознаграждении. По мере развития интеллекта таких систем у них проявляется внутренне присущая им тенденция отказа по типу самостимулирования. Методы обучения с подкреплением не кажутся перспективными |
| Модель ценностного приращения | Человек получает большую часть информации о своих конкретных целях благодаря обогащенному опыту. И хотя, в принципе, метод ценностного приращения может использоваться для создания агента с человеческой мотивацией, присущие людям особенности приращения целей слишком сложно воспроизводить, если начинаешь работу с зародыша ИИ. Неверная аппроксимация способна привести к тому, что ИИ будет обобщать информацию не так, как люди, вследствие чего приобретет не те конечные цели, которые предполагались. Чтобы определить с достаточной точностью, насколько трудна может оказаться работа по ценностному приращению, требуются дополнительные исследования |
| Строительные леса для мотивационной системы | Пока рано говорить, насколько трудно будет добиться от системы выработки внутренних представлений высокого уровня, прозрачных для людей (и при этом удержать возможности системы на безопасном уровне), чтобы при помощи таких представлений создать новую систему ценностей. Метод кажется очень перспективным. (Но поскольку в этом случае, как при любом неопробованном методе, большая часть работы по созданию системы безопасности откладывается до момента появления ИИЧУ, нельзя допустить, чтобы это стало оправданием для игнорирования проблемы контроля в течение всего времени, предшествующего этому моменту.) |
| Обучение ценностям | Потенциально многообещающий подход, но нужно провести дополнительные исследования, чтобы определить, насколько трудно будет формально определить ссылки на важную внешнюю информацию о человеческих ценностях (и насколько трудно при помощи такой ссылки задать критерий правильности для функции полезности). В рамках этого подхода стоят пристального изучения предложения вроде метода «Аве Мария» и конструкции Пола Кристиано |
| Эмуляторы и цифровые модуляции | Если машинный интеллект создан в результате полной эмуляции головного мозга, скорее всего, будет возможно корректировать его мотивацию при помощи цифрового эквивалента лекарственных препаратов или иных средств. Позволит ли это загрузить цели с достаточной точностью, чтобы обеспечить безопасность даже в случае превращения эмулятора в сверхразум, — вопрос пока открытый. (Повлиять на развитие процесса могут этические ограничения.) |
| Институциональное конструирование | К организациям, состоящим из эмуляторов, применимы различные сильные методы контроля над возможностями, в том числе социальная интеграция. В принципе, такие методы могут быть использованы и для организаций, члены которых являются системами ИИ. Эмуляторы обладают одним набором свойств, которые облегчают проведение контроля над ними, и другим набором свойств, которые затрудняют проведение контроля над ними по сравнению с ИИ. Институциональное конструирование стоит дальнейшего исследования как потенциально полезная техника метода загрузки ценностей |
Когда мы поймем, как решить проблему загрузки ценностей, то немедленно столкнемся со следующей — как решать, какие ценности надо загружать. Иными словами, есть ли у нас сложившееся мнение, что должен был бы желать сверхразум? Это вопрос почти философский, и мы к нему сейчас обратимся.

