Книга: Лестница жизни: десять величайших изобретений эволюции
Назад: Глава 1. Происхождение жизни
Дальше: Глава 3. Фотосинтез
Глава 2. ДНК
На стене паба “Орел” в Кембридже висит синяя мемориальная доска, установленная в 2003 году в честь пятидесятилетия одного случая, когда разговоры в этом пабе приняли не совсем обычный оборот. Во время обеда 28 февраля 1953 года два завсегдатая “Орла”, Джеймс Уотсон и Фрэнсис Крик, пришли туда и объявили, что раскрыли тайну жизни. Хотя этот эмоциональный американец и этот разговорчивый британец, отличавшийся малоприятным смехом, временами, должно быть, и напоминали дуэт комиков, на сей раз они были абсолютно серьезны — и наполовину правы. Если считать, что у жизни есть тайна, то эту тайну, несомненно, составляет именно ДНК. Впрочем, Крик и Уотсон, при всех их незаурядных способностях, раскрыли тогда лишь половину этой тайны.
В то утро они разгадали структуру ДНК — двойную спираль. Полученная ими схема стала результатом вдохновенного интеллектуального прорыва, обеспеченного гениальностью, умением строить модели, знанием химии и несколькими позаимствованными без спроса рентгенограммами, и была, по словам Уотсона, “слишком хороша, чтобы быть неправдой”. И чем больше они говорили о ней в тот обеденный перерыв, тем больше убеждались в ее правильности. Она была опубликована в номере журнала “Нейчур” от 25 апреля в письме, которое заняло всего одну страницу и немного напоминало заметку о появлении новорожденного в малотиражной местной газете. Необычайно скромная по тону (Уотсон писал в своей знаменитой книге, что “никогда не видел, чтобы Фрэнсис Крик держался скромно”, да и сам он был не намного скромнее своего партнера), та заметка завершалась намеренно уклончивым утверждением: “От нашего внимания не ускользнуло, что постулированное нами специфическое образование пар заставляет сразу предположить возможный механизм копирования генетического материала”.
ДНК, как известно, составляет основу наших генов, наследственный материал клеток. В ней зашифрованы свойства людей и амеб, грибов и бактерий — всех форм жизни на нашей планете, за исключением некоторых вирусов. Двойная спираль ДНК, в которой две цепочки без конца вьются друг вокруг друга оборот за оборотом, — поистине культовый научный символ. Уотсон и Крик показали, как одна цепочка дополняет другую на молекулярном уровне. Если оторвать их друг от друга, каждая из них может служить матрицей для воссоздания другой, так что из одной спирали получатся две точно таких же. Всякий раз, когда тот или иной организм размножается, он передает копии своей ДНК потомкам. Все, что для этого нужно, — это разделить цепочки и синтезировать две идентичных копии оригинала.
Хотя подробное описание молекулярного механизма этого процесса могло бы вызвать у любого читателя головную боль, лежащий в основе механизма принцип изумительно, потрясающе прост. Генетический код представляет собой последовательность “букв” (их более строгое наименование — “азотистые основания”). Таких букв в ДНК-алфавите всего четыре: А, Т, Г и Ц. Их полные названия — аденин, тимин, гуанин и цитозин, но эти химические термины для нас здесь не важны. Важно то, что в связи с ограничениями, накладываемыми формой молекул ДНК и структурой связей в них, А может образовывать пару только с Т, а Ц — только с Г. Если оторвать цепочки двойной спирали одну от другой, на каждой из них будут рядком торчать неспаренные буквы. С каждой буквой А может связаться только Т, а с каждой буквой Ц — только Г, и так далее. Азотистые основания не только дополняют друг друга, но и испытывают настоящую потребность найти себе пару. Только одно может сделать тусклую химическую жизнь буквы Т светлее — постоянная близость с буквой А. Стоит их совместить, и все их связи запоют в чудесной гармонии. Это химическое явление — настоящий “основной инстинкт”, неотъемлемое свойство азотистых оснований. Оно делает из цепочек ДНК нечто большее, чем пассивные матрицы: каждое основание обладает своего рода магнетизмом, притяжением к своему “альтер эго”. Стоит разделить цепочки, и они самопроизвольно сольются снова или, если им помешать, смогут послужить матрицами, обладающими неодолимой тягой к соединению с другой “второй половиной”, неотличимой от прежней.

Схема соединения азотистых оснований ДНК. Геометрическими особенностями “букв" определяется, что Г связывается только с Ц, а А — только с Т.
Последовательность букв ДНК кажется нескончаемой. Например, в человеческом геноме почти три миллиарда пар азотистых оснований (на научном языке — три гигабазы). Это значит, что если взять по одной из всех хромосом, имеющихся в ядре нашей клетки, общее число букв в них составит почти три миллиарда. Если опубликовать последовательность человеческого генома в виде книг, она заполнит примерно двести томов размером с солидный телефонный справочник. А ведь наш геном — еще далеко не самый большой. Как ни странно, рекордсменом по этому показателю является ничтожная амеба Amoeba dubia, гигантский геном которой содержит 670 гигабаз — примерно в 220 раз больше, чем в нашем геноме. По большей части он, судя по всему, состоит из “мусора” — ДНК-последовательностей, которые вообще ничего не кодируют.
Каждому делению клетки предшествует удвоение (репликация) всей ее ДНК — процесс, занимающий не один час. Человеческое тело состоит из чудовищного количества клеток — пятнадцати миллионов миллионов, и в каждой из них содержится собственная высококачественная копия (на самом деле — даже две копии) одних и тех же молекул ДНК. Чтобы организм каждого из нас развился из единственной оплодотворенной яйцеклетки, двойным спиралям нашей ДНК пришлось разделяться и служить матрицами для достраивания новых цепочек пятнадцать миллионов миллионов раз (и даже гораздо больше, потому что наши клетки все время умирают и замещаются новыми). Точность копирования каждой буквы фантастична: ошибки в их порядке встречаются с частотой всего в один случай на миллиард букв. Для сравнения: переписчику книг, чтобы работать со сходной точностью, понадобилось бы 280 раз переписать всю Библию от начала до конца, прежде чем сделать единственную ошибку. На деле переписчики справлялись со своей работой далеко не столь успешно. Утверждается, что до нашего времени дошло около 24 тысяч рукописных экземпляров Нового Завета, и среди них нет двух одинаковых.
И все же ошибки накапливаются и в ДНК — хотя бы потому, что геном так огромен. Ошибки, при которых одна буква случайно заменяется другой, называют точечными мутациями. Перед каждым делением человеческой клетки можно ожидать появления в каждом наборе хромосом примерно трех подобных мутаций. И чем дольше клетка делится, тем больше в ней накапливается мутаций (это может приводить к развитию болезней, например рака). Мутации могут также передаваться из поколения в поколение. Если из оплодотворенной яйцеклетки развивается женский зародыш, то яйцеклетки нового организма образуются после примерно тридцати циклов деления, и в ходе каждого цикла добавляются новые мутации. У мужского организма дела обстоят еще хуже: для образования сперматозоидов требуется около ста циклов деления, каждый из которых неизбежно вносит свою лепту в груз мутаций. Поскольку производство сперматозоидов продолжается на протяжении всей жизни и включает все больше и больше клеточных циклов, то чем старше мужчина, тем больше мутаций накапливается в его половых клетках. Генетик Джеймс Кроу сформулировал эту закономерность так: наибольшая мутационная угроза здоровью человеческих популяций исходит от плодовитых стариков. Но даже у среднего ребенка молодых родителей имеется около двухсот новых мутаций, которые у них самих отсутствовали (хотя лишь немногие из этих мутаций могут оказаться вредными)1.
Поэтому, несмотря на необычайную точность копирования ДНК, ее молекулы все-таки меняются. Каждое поколение отличается от предыдущего — не только оттого, что в результате полового процесса гены перемешиваются, но также оттого, что каждый из нас становится носителем новых мутаций. Многие из них представляют собой точечные мутации, о которых мы говорили выше (изменения единственной буквы ДНК), другие бывают намного радикальнее. Порой целые хромосомы лишний раз удваиваются или не могут разойтись при делении клетки, длиннейшие куски ДНК удаляются, вирусы встраивают в хромосомы свою ДНК, а фрагменты хромосом переворачиваются так, что последовательность букв меняется на противоположную. Возможностей таких изменений бесконечно много, хотя наиболее серьезные из них обычно несовместимы с жизнью. Если рассмотреть наш геном на этом уровне, он окажется похожим на яму, кишащую змеями, где змееподобные хромосомы без устали сливаются и разделяются. Роль стабилизирующей силы здесь играет естественный отбор, отсеивающий рождающихся монстров, кроме самых безобидных. ДНК причудливо извивается и меняется, но отбор ее выпрямляет и исправляет. Любые полезные изменения сохраняются, а любые серьезные ошибки или особо вредные изменения приводят к выкидышу — в буквальном смысле. Из вредных мутаций сразу не отсеиваются лишь не столь серьезные, которые могут быть связаны с болезнями, проявляющимися на более поздних этапах жизни.
Меняющиеся последовательности букв в ДНК стоят почти за всем, что можно прочитать в газетах о наших генах. Например, ДНК-дактилоскопия (которую используют для установления отцовства, импичмента президентов, а также уличения преступников — иногда спустя десятки лет после события преступления) основана на различиях в последовательностях ДНК-букв между индивидуумами. Человеческие геномы различаются столь заметно, что ДНК каждого из нас свойственны собственные уникальные “отпечатки”. Степень нашей подверженности многим болезням тоже зависит от крошечных различий в ДНК-последовательностях. В среднем люди отличаются друг от друга примерно одной на каждую тысячу букв, так что разница между двумя человеческими геномами составляет 6-ю миллионов однобуквенных отличий — так называемых “снипов” (SNPs, от single nucleotide polymorphisms — однонуклеотидные полиморфизмы). Существование снипов означает, что у всех нас имеются немного разные варианты большинства генов. Хотя большинство снипов почти точно не имеют для нас никаких последствий, некоторые из них связаны с недугами, такими как диабет или болезнь Альцгеймера (однако как они действуют, нам еще не всегда известно).
При всех этих различиях мы все-таки можем пользоваться понятием “человеческий геном”: несмотря на все снипы, 999 букв из каждой тысячи у всех нас все-таки совпадают. На то есть две причины: время и отбор. В эволюционных масштабах не так уж много времени прошло с тех пор, как мы были обезьянами. Более того, зоолог стал бы уверять вас, что мы по-прежнему обезьяны. Предки человека отделились от общего предка с шимпанзе около шести миллионов лет назад и с тех пор накапливали мутации с частотой двести мутаций за поколение. Этого времени хватило лишь на то, чтобы изменить около 1 % нашего генома. При этом предки шимпанзе эволюционировали со сходной скоростью, и теоретически мы могли бы ожидать разницы в 2 %. Но на деле разница несколько меньше: ДНК-последовательности людей и шимпанзе идентичны на 98,6 %2. Это связано с постоянным торможением изменений, которое обеспечивает естественный отбор, выбраковывая большинство вредных мутаций. Ясно, что когда многие изменения выбраковываются отбором, оставшиеся будут больше похожи друг на друга, чем были бы, если бы их ничто не сдерживало.
Если углубиться еще дальше в прошлое, мы увидим, как эти две силы, время и отбор, действуя вместе, сплели великолепнейший, изысканнейший ковер. Все живое на нашей планете состоит в родстве, и, читая буквы ДНК, можно выяснить, в каком. Сравнивая ДНК-последовательности, можно рассчитать степень нашего родства с любыми другими организмами, от обезьян до сумчатых, рептилий, амфибий, рыб, насекомых, ракообразных, червей, растений, простейших, бактерий — кого угодно. Свойства всех нас определяются последовательностями букв, которые можно точными методами сравнивать друг с другом. У всех нас даже есть общие участки последовательностей — фрагменты, изменение которых сдерживалось общими механизмами отбора, в то время как другие участки изменялись до неузнаваемости. Если прочитать ДНК-последовательность кролика, мы увидим такие же нескончаемые ряды оснований, одни участки которых будут идентичны нашим, другие — отличными от них, и все они будут перемешаны друг с другом, составляя сложный калейдоскоп. То же относится и к чертополоху: кое-где наши с ним ДНК-последовательности идентичны или похожи, но здесь несходные участки будут занимать гораздо больше места, отражая, во-первых, огромный промежуток времени, прошедшего с тех пор, когда жил наш общий предок, а во-вторых, разность образа жизни человека и чертополоха. Впрочем, глубокие основы нашей биохимии остались теми же. Мы все состоим из клеток, работающих сходным образом, и их общие свойства определяются похожими участками ДНК-последовательностей.
Учитывая эти черты глубокого биохимического сходства, можно ожидать, что у нас найдутся общие участки последовательностей даже с самыми далекими от нас формами жизни, такими как бактерии. Это действительно так. Но здесь мы сталкиваемся с источником некоторой путаницы, поскольку сходство последовательностей может оцениваться не в пределах 0-100%, а лишь от 25 до 100% (ведь ДНК-букв всего четыре). Если случайным образом заменить одну букву на одну из четырех, с вероятностью 25% новая буква будет такой же, как и старая. Точно так же, если с нуля синтезировать в лаборатории случайную ДНК-последовательность, она неизбежно будет по крайней мере на четверть сходна с любым случайно выбранным нашим геном. Поэтому соображение о том, что мы “наполовину бананы”, раз наш геном наполовину совпадает с геномом банана, мягко говоря, неверно. Исходя из той же логики, любая случайно составленная последовательность ДНК будет на четверть человеком. Не зная, что именно означают буквы той или иной последовательности, мы блуждали бы впотьмах.
Именно поэтому утром 28 февраля 1953 года Уотсон и Крик лишь наполовину разгадали загадку жизни. Им удалось разобраться в строении ДНК и понять, как каждая из двух цепочек двойной спирали служит матрицей для синтеза копии другой цепочки, обеспечивая передачу наследственного кода каждого организма. О чем они не упомянули в своей знаменитой статье (поскольку для выяснения этого потребовался еще десяток лет хитроумных исследований), — так это о том, как именно в каждой последовательности букв зашифрована наследственная информация. Хотя расшифровка генетического кода, этого шифра жизни, и не дала столь символичного и впечатляющего результата, как сама двойная спираль, ровным счетом ничего не говорящая о последовательностях записанных в ней букв, она стала, возможно, еще более крупным достижением — в тем числе Фрэнсиса Крика, сыгравшего в тех исследованиях немалую роль. Для темы этой главы особенно важно, что расшифрованный код, сначала казавшийся главным разочарованием современной биологии, сообщает нам интереснейшие сведения о становлении в ходе эволюции самой ДНК почти четыре миллиарда лет назад.
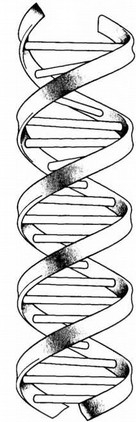
Схема двойной спирали молекулы ДНК, показывающая, как две ее цепочки закручиваются друг вокруг друга. Если разделить их, каждая цепочка сможет служить матрицей для синтеза точно такой же противоположной цепочки.
ДНК кажется чем-то столь современным, что нам сложно оценить, как мало в 1953 году было известно о началах молекулярной биологии. Образ двойной спирали разошелся по свету именно из той публикации Уотсона и Крика, иллюстрацию к которой нарисовала жена Крика Одиль (она была художницей). На ее рисунке ДНК похожа на своего рода винтовую лестницу, и именно так его и воспроизводили почти без изменений на протяжении полувека. Написанная в 60-х годах знаменитая книга Уотсона “Двойная спираль” стала, в свою очередь, классическим изображением современного взгляда на науку. Влияние этой книги было настолько велико, что сама жизнь, может быть, начала подражать искусству. Я, например, прочитав “Двойную спираль” еще в школе, и сам стал мечтать о Нобелевской премии и революционных открытиях. Думаю, мои представления о том, как занимаются наукой, в то время основывались почти исключительно на книге Уотсона, и разочарование, которое неизбежно постигло меня в университете, по всей вероятности, было связано с тем, что действительность не оправдала моих восторженных ожиданий. Я перестал искать острых ощущений в науке и занялся ради них скалолазанием. Потребовался не один год, чтобы я снова проникся чувством интеллектуального восторга от научной работы.
Но едва ли не все, чему я научился в университете, было неизвестно в 1953 году Уотсону и Крику. Давно стал общим местом тезис, что “белки закодированы в генах”. Но в начале 50-х годов даже по этому вопросу у ученых не было единого мнения. Уотсон впервые приехал в Кембридж в 1951 году, и очень скоро его стал раздражать скептицизм Макса Перуца и Джона Кендрю. По их мнению, еще нельзя было считать окончательно доказанным, что гены записаны в ДНК, а не в белках. Хотя молекулярная структура ДНК не была пока известна, ее химический состав был уже вполне ясен, и было известно, что он почти не меняется от одного вида к другому. Если гены действительно составляют основу наследственности и в них закодированы бесчисленные отличительные черты разных особей и видов, то как можно было пытаться объяснить все богатство и разнообразие жизни этим однородным соединением, по составу которого даже животные и бактерии не слишком отличаются друг от друга? Казалось, что белки с их бесконечным многообразием гораздо лучше подходят на роль носителя наследственной информации.
Уотсон был одним из тех немногих, кого убедили результаты экспериментов американского биохимика Освальда Эвери, опубликованные в 1944 году и свидетельствовавшие о том, что гены записаны в ДНК. Только энтузиазм и убежденность Уотсона побудили Крика взяться за насущную проблему разгадки структуры ДНК. Когда эта проблема была решена, ребром встал вопрос о генетическом коде. И здесь степень неосведомленности ученых того времени тоже просто удивительна для людей нового поколения. Молекулы ДНК состоят из последовательностей, составленных из всего четырех букв, расположенных на первый взгляд в случайном порядке. Было не так уж сложно догадаться, что этот порядок должен каким-то образом кодировать белки. Молекулы белков тоже состоят из последовательности “строительных блоков”, которые называют аминокислотами. Последовательностями букв в ДНК были предположительно закодированы последовательности аминокислот в белках. Но если код был универсальным для всех организмов (чего на тот момент уже можно было ожидать), то набор аминокислот, входящих в состав белков, тоже должен был оказаться универсальным. А в этом еще отнюдь не было уверенности. Саму эту возможность мало кто обсуждал, пока Уотсон и Крик за обедом все в том же “Орле” не составили канонический список двадцати аминокислот, который сейчас можно найти во всех учебниках. Любопытно, что хотя ни один из дуэта не был биохимиком, они угадали все с первого же раза.
Теперь задача сразу стала ясна. Все свелось к математической головоломке, варианты решения которой не ограничивались никакими фактами из тех, что пришлось зубрить следующим поколениям студентов, изучавших молекулярную биологию. Четыре буквы в молекулах ДНК должны были кодировать двадцать аминокислот. Это позволяло отбросить возможность прямой транслитерации, при которой одна ДНК-буква соответствовала бы одной аминокислоте. Дублетный код тоже был невозможен, потому что кодировал бы не более шестнадцати аминокислот (4x4 = 16). Минимальное число букв было три, то есть код мог быть триплетным (впоследствии Фрэнсис Крик и Сидней Бреннер доказали, что это именно так). Каждая группа из трех ДНК-букв могла кодировать одну аминокислоту. Но такой код казался очень уж расточительным. Из четырех букв можно составить шестьдесят четыре триплета (4x4x4 = 64), а значит, потенциально триплетами можно было закодировать шестьдесят четыре аминокислоты. Так почему же их было только двадцать? Секрет этого фокуса должен был объяснить смысл четырехбуквенного “алфавита”, организованного в шестьдесят четыре трехбуквенных “слова”, кодирующие двадцать аминокислот.
Не случайно, наверное, первым, кому удалось дать хоть какой-то ответ, стал не биолог, а энергичный американский физик российского происхождения Георгий (Джордж) Гамов, больше известный своими теориями, касающимися Большого взрыва. Гамов считал ДНК в буквальном смысле матрицей для синтеза белков. Он полагал, что аминокислоты вкладываются в ромбовидные борозды между оборотами спирали. Но его теория генетического кода была в основе нумерологической, и когда он узнал, что белки вообще не синтезируются в ядре, а значит, в ходе синтеза не могут непосредственно контактировать с ДНК, это не произвело на него особого впечатления. Этот факт лишь делал его идею более абстрактной. Суть его предположения состояла в том, что код перекрывается. Это дает большое преимущество, которое обожают криптографы: максимизация плотности информации. Представьте себе последовательность АТЦГТЦ. Первое слово, или, если использовать более строгий термин, первый кодон, будет АТЦ, второй — ТЦГ, третий — ЦГТ, и так далее. Здесь важно то, что перекрывающиеся кодоны всегда ограничивали бы число аминокислотных последовательностей. Например, если АТЦ кодирует определенную аминокислоту, за ней может следовать только аминокислота, кодон которой начинается с букв ТЦ, а следующей аминокислоте должен соответствовать кодон, начинающийся с буквы Ц. Если изучить все возможные варианты, окажется, что очень многие триплеты просто недопустимы: они не могут входить в состав этого перекрывающегося кода, потому что в нем буква А всегда должна стоять рядом с Т, Т — рядом с Ц, и так далее. И сколько триплетов у нас останется для кодирования аминокислот? Ровно двадцать! — сказал Гамов с торжеством фокусника, вынимающего кролика из шляпы.
Эта остроумная идея была первой из многих, безжалостно опровергнутых фактами. Перекрывающиеся коды оказались невозможны из-за накладываемых ими самими ограничений. Во-первых, они предполагают, что некоторые аминокислоты в белках должны всегда стоять рядом. Но Фред Сэнгер, скромный гений, впоследствии получивший две Нобелевских премии (одну за метод прочтения последовательностей аминокислот в белках, другую — за метод прочтения букв в ДНК), занимался в то время выяснением последовательности аминокислот в молекуле инсулина. Вскоре он выяснил, что аминокислоты в белке могут располагаться в любом порядке и ограничений на их последовательности в белках в природе нет. Вторая серьезная проблема состояла в том, что при перекрывающемся коде любая точечная мутация (в которой одна буква заменяется другой) неизбежно приводила бы к изменению больше чем одной аминокислоты в белке, а экспериментальные данные свидетельствовали о том, что при таких мутациях меняется лишь одна аминокислота. Стало ясно, что генетический код не перекрывается. Предположение Гамова о перекрывании кода было опровергнуто задолго до того, как стал известен настоящий код. Криптографы начали подозревать, что мать-природа упустила возможность воспользоваться некоторыми известными им трюками.
Следующую попытку разгадать загадку кода предпринял Крик. Он высказал идею настолько красивую, что ее немедленно все приняли, хотя самого автора и смущала нехватка доказательств. Крик воспользовался новыми открытиями, сделанными в нескольких молекулярно-биологических лабораториях, в первую очередь в новой лаборатории Уотсона в Гарварде. Уотсон глубоко увлекся исследованиями РНК — более короткой одноцепочечной молекулы, близкой к ДНК и находимой как в цитоплазме клеток, так и в ядре. Кроме того, он обратил внимание на то, что РНК составляет неотъемлемую часть крошечных структур, теперь называемых рибосомами, на которых, судя по всему, и синтезировались белки. Итак, неактивная ДНК сидит в ядре. Когда нужно синтезировать какой-либо белок, соответствующий участок ДНК используется в качестве матрицы, чтобы синтезировать его РНК-копию. Она физически выходит из ядра и достигает ожидающих ее снаружи рибосом, синтезирующих этот белок, используя в качестве матрицы уже молекулу РНК. Эта разновидность РНК впоследствии получила название матричной РНК (мРНК). Уотсон еще в 1952 году писал Крику: “ДНК делает РНК делает белок”. Крика теперь интересовало вот что: как точная последовательность букв молекулы матричной РНК переводится (транслируется) в последовательность аминокислот в белке?
Крик крепко задумался. Он предположил, что матричная РНК транслируется с помощью набора особых молекул — адаптеров, по одной на каждую аминокислоту. Адаптеры тоже должны состоять из РНК, у каждого из них должен быть антикодон, способный узнавать соответствующий кодон матричной РНК и связываться с ним. Принцип этого связывания, как считал Крик, должен быть точно таким же, как в ДНК: Ц образует пару с Г, А — с Т, и так далее3. Существование адаптеров предполагалось тогда чисто гипотетически, но они действительно были открыты несколько лет спустя, и оказалось, что они действительно состоят из РНК, как и предсказывал Крик. Теперь их называют транспортными РНК (тРНК). Вырисовывалась система, напоминающая детский конструктор, детали которого соединялись друг с другом и вновь разделялись, образуя изумительные, хотя и недолговечные структуры.
Но здесь Крик пошел по ложному пути. Я пишу об этом довольно подробно потому, что хотя действительность и оказалась несколько богаче, чем он предполагал, его идеи могут по-прежнему быть актуальны для решения вопроса о том, как все это возникло. Крик представлял себе, что матричная РНК просто сидит в цитоплазме, а ее кодоны торчат, как соски свиноматки, и к каждому из них может “присосаться” транспортная РНК. Рано или поздно молекулы тРНК свяжутся с мРНК по всей длине, расположившись одна за другой, и с каждой из них будет связана, как хвост поросенка, соответствующая аминокислота, готовая соединиться с соседними аминокислотами и образовать белковую цепочку.
Проблема, по мнению Крика, состояла в том, что тРНК будут прибывать в случайном порядке, по мере их появления рядом с мРНК, и связываться с ближайшим соответствующим кодоном. Но если не начинать с начала и не заканчивать в конце, как они узнают, где начинается и где заканчивается один кодон? Как они смогут найти правильную рамку считывания? Если последовательность содержит фрагмент АТЦГТЦ, то одна тРНК может связаться с кодоном АТЦ, а другая — с кодоном ГТЦ, но что помешает соответствующей тРНК узнать кодон ЦГТ в середине этого фрагмента и тем самым транслировать совсем не то, что нужно? Предложенный Криком ответ на этот вопрос предполагал категорический запрет подобных вещей. Раз матрица в целом должна читаться однозначно, значит, не все кодоны должны иметь смысл. Какие же из них требовалось запретить? Ясно, что последовательности, состоящие только из А, только из Ц, только из Т или только из Г, должны были оказаться под запретом: в цепочке АААААА нельзя найти правильную рамку считывания. Затем Крик проверил все другие трехбуквенные комбинации. Он рассуждал примерно так: если АТЦ имеет смысл, то все циклические перестановки этих трех букв (ТЦА и ТАЦ) должны быть под запретом. Сколько возможностей это нам оставляет? Снова двадцать! (Из шестидесяти четырех возможных кодонов AAA, ТТТ, ЦЦЦ и ГГГ исключаются. Остается шестьдесят. Из каждых трех вариантов циклических перестановок допустим только один, значит, делим шестьдесят на три.)
В отличие от перекрывающихся кодов, код Крика не накладывал никаких ограничений на порядок аминокислот в белке и не предполагал, что точечная мутация будет непременно менять две или три аминокислоты. Когда была выдвинута эта гипотеза, казалось, она дает прекрасное решение проблемы рамки считывания и при этом сокращает число кодонов с шестидесяти четырех до двадцати, что соответствует числу аминокислот в белках. Эта гипотеза ничуть не противоречила всем имеющимся на тот момент данным. И все же она ошибочна. Спустя несколько лет выяснилось, что искусственно полученная РНК, состоящая из кодонов ААА (запрещенных Криком), все же кодирует аминокислоту лизин и может транслироваться в белковую цепочку, состоящую исключительно из лизина.
К середине 60-х годов, когда были усовершенствованы экспериментальные методы, нескольким исследовательским группам удалось шаг за шагом выяснить, что на самом деле представляет собой генетический код. После всех попыток расшифровать его открывшаяся картина вызывала глубочайшее разочарование. Оказалось, что никакого изящного нумерологического решения не было, а код просто вырожден (это значит, что в нем полно излишеств). Три аминокислоты кодируются шестью разными кодонами каждая, в то время как другие кодируются лишь одним или двумя. Все кодоны идут в дело: три кодона означают “стоп” (конец трансляции), а все остальные кодируют ту или иную аминокислоту. Выходило, что в генетическом коде нет никакого порядка, никакой красоты. Этот пример может служить нагляднейшим опровержением мысли, что красота может служить проводником к научной истине*1. Судя по всему, в основе кода не было и никакой структурной логики: между аминокислотами и соответствующими им кодонами не было ни особой химической, ни особой физической связи.
Крик объявил этот удручающий код “застывшей случайностью”, и большинство исследователей не могло с ним не согласиться. По мнению Крика, код застыл оттого, что любые покушения на его структуру (попытки его разморозить) имели бы слишком серьезные последствия. Единственная точечная мутация может изменить ту или иную аминокислоту, расположенную в определенном месте определенного белка, но любое изменение самого кода приводило бы к катастрофическим переменам во всех белках без исключения. Разница между этими событиями соответствовала бы разнице между случайной опечаткой в книге, не особенно меняющей ее смысл, и изменением одной буквы на другую во всем алфавите, что превращало бы весь текст в абракадабру. Поэтому, как считал Крик, после того, как код был выбит на скрижалях, любые покушения на него карались смертью. Эта точка зрения и сегодня широко распространена среди биологов.
Но предполагаемая Криком “случайная” природа кода ставила одну проблему. Почему такая случайность была всего одна? Почему не несколько? Если код произволен, то один код не должен быть особенно лучше другого. Не было никаких оснований считать, что отбор некогда создал своего рода “бутылочное горлышко”, при прохождении через которое один из вариантов кода обладал бы, по словам Крика, “таким селективным преимуществом над всеми конкурентами, что сохранился бы только он один”. Но если никакого “бутылочного горлышка” не было, то почему мы не наблюдаем сосуществования разных организмов с несколькими разными кодами? Крик всерьез задумался над этим вопросом.
Самый очевидный ответ предполагал, что все живое на земле происходит от общего предка, у которого генетический код уже был жестко закреплен. Говоря об этом в философском ключе, можно было сказать, что жизнь возникла на Земле лишь однажды, в связи с чем ее возникновение казалось событием уникальным и почти невероятным, может быть даже совершенно исключительным. По мнению Крика, это заставляло предположить заражение — однократное занесение жизни на нашу планету. Он стал отстаивать идею, что жизнь была “посеяна” на Земле в форме бактериальных клонов единственного внеземного организма. Крик пошел еще дальше: принялся доказывать, что эти бактерии были преднамеренно посеяны на Земле неким инопланетным разумом с помощью космического корабля. Крик назвал подобный сценарий “направленной панспермией”. Эту тему он разработал в книге “Жизнь как она есть”, опубликованной в 1981 году. Мэтт Ридли в своей превосходной биографии Крика писал: “Предмет этой книги вызвал немало удивления. Великий Крик пишет об инопланетных жизненных формах, рассеиваемых во Вселенной космическим кораблем? Не слишком ли успех вскружил ему голову?” Действительно ли идея случайного кода оправдывает столь далеко идущие философские выводы — вопрос спорный. Чтобы код прошел через “бутылочное горлышко”, не требуется, чтобы определенный его вариант имел какие-то особые преимущества перед другими. Сильный отбор по любому признаку, хотя бы и в результате исключительного события, например столкновения с Землей астероида, вполне мог истребить все живое на планете, кроме потомков единственного клона, которые по определению должны были обладать только одним вариантом кода. Так или иначе, Крик не вовремя выдвинул свою идею направленной панспермии. Как раз в начале 8о-х годов, когда он писал свою книгу, стало ясно, что генетический код нельзя считать ни застывшим, ни случайным. В нем есть скрытые закономерности, своего рода “код внутри кодонов”, дающий нам ключи к разгадке тайны происхождения нашего кода, возникшего почти четыре миллиарда лет назад. Теперь мы знаем, что он представляет собой не тот жалкий шифр, который так разочаровал в свое время криптографов, а единственный в своем роде код из миллиона возможных, способный противостоять изменениям и одновременно ускорять ход эволюции.
Код внутри кодонов! С 60-х годов в генетическом коде выявили целый ряд закономерностей, но большинство из них легко было отбросить как обыкновенный статистический шум (что, собственно, и делал Крик). Казалось даже, будто совокупность этих закономерностей не несет особого смысла. Хороший вопрос — почему так казалось. Этим вопросом задался калифорнийский биохимик Брайан Дэвис, уже давно интересовавшийся корнями генетического кода. Он отмечает, что сама идея “застывшей случайности” погасила интерес к проблеме происхождения кода. Какой смысл изучать происхождение случайности? Случайности случаются, только и всего. Кроме того, по мнению Дэвиса, те немногие исследователи, которые продолжали интересоваться этой проблемой, пошли по ложному пути, ухватившись за наиболее популярную в то время идею первичного бульона. Если генетический код возник в таком бульоне, то он должен восходить к молекулам, возникновение которых в результате происходивших в таком бульоне физических и химических процессов особенно вероятно. А это заставляло предположить, что в основе кода лежал некий базовый набор аминокислот, а все остальное добавилось позже. Истины в этой идее было ровно столько, чтобы данные, свидетельствующие в ее пользу, производили сильнейшее впечатление, хотя в действительности они лишь сбивали с толку. Смысл закономерностей генетического кода мы начинаем понимать лишь тогда, когда рассматриваем его как продукт биосинтеза, то есть продукт клеток, способных синтезировать собственные “строительные блоки” из водорода и углекислого газа.
Так что же собой представляют эти неочевидные закономерности? С каждой буквой триплетного кода связана некая закономерность. Особенно красноречивы свойства первой буквы, поскольку она касается процесса, позволяющего поэтапно превращать несложные вещества-предшественники в аминокислоты. Принцип, лежащий в основе этой закономерности, настолько поразителен, что его стоит здесь изложить в двух словах. В клетках современных организмов аминокислоты синтезируются посредством целого ряда биохимических преобразований, начинающихся с нескольких несложных веществ-предшественников. А удивительно здесь то, что между первой буквой триплетного кодона и этими несложными предшественниками есть определенная связь. Так, все аминокислоты, предшественником которых оказывается пируват, соответствуют кодонам, начинающимся с одной и той же буквы — в данном случае Т5. Я привел в качестве примера именно пируват, потому что мы уже встречались с этим веществом в главе 1. Оно может образовываться в гидротермальных источниках из углекислого газа и водорода при участии катализаторов — ими могут служить присутствующие в таких источниках минералы. Но это относится не только к пирувату. Предшественники всех аминокислот участвуют в цикле Кребса — основе биохимии всех клеток, и должны образовываться в щелочных гидротермальных источниках, которые мы обсуждали в главе 1. Напрашивается вывод (на данном этапе, надо признать, поверхностный, но нам еще предстоит его уточнить), что между первой буквой триплетного кода и гидротермальными источниками существует какая-то связь.
А как обстоят дела со второй буквой? Здесь наблюдается связь со степенью растворимости (или нерастворимости) аминокислоты в воде, то есть гидрофильности (или гидрофобности). Гидрофильные аминокислоты растворяются в воде, в то время как гидрофобные с ней не смешиваются, а растворяются в жироподобных веществах, таких как липидные мембраны клеток. Все аминокислоты можно распределить по своего рода спектру, начиная от “очень гидрофобных” и заканчивая “очень гидрофильными”. Именно этот спектр имеет связь со второй буквой триплетного кода. Пяти из шести самых гидрофобных аминокислот соответствуют кодоны с буквой Т в середине, а всем самым гидрофильным — кодоны с буквой А в середине. Промежуточным аминокислотам спектра соответствуют кодоны с буквой Г или Ц в середине. Таким образом, чем бы это ни объяснялось, в целом наблюдается сильная и вполне определенная связь между первыми двумя буквами каждого кодона и той аминокислотой, которую этот кодон кодирует.
Именно последняя буква приводит к вырожденности кода: восьми аминокислотам свойственна (прекрасный научный термин!) четырехкратная вырожденность. Хотя большинству читателей может показаться, что четырехкратная вырожденность означает совершенно опустившихся людей, пьяниц, которым удается падать в четыре разных канавы одновременно, биохимики обозначают этим термином ситуацию, когда третья буква кода не несет никакой информации. Независимо оттого, какое азотистое основание стоит на этом месте, во всех четырех случаях триплет кодирует одну и ту же аминокислоту. Например, в триплете ГГГ, кодирующем глицин, можно заменить последнюю Г на Т, А или Ц — и все три новых триплета будут по-прежнему кодировать глицин.
Вырожденность кода по третьей букве имеет несколько интересных следствий. Мы уже отмечали, что дублетный код мог бы кодировать только шестнадцать из двадцати входящих в состав белков аминокислот. Если исключить из их списка пять самых сложных (оставив, таким образом, пятнадцать, плюс стоп-кодон), закономерности, касающиеся первых двух букв, окажутся выражены еще ярче. Так что, возможно, код первоначально был дублетным и лишь потом расширился до триплетного в результате “присвоения кодонов”: аминокислоты могли соперничать друг с другом за третью букву. Древнейшие аминокислоты, вероятно, получили “нечестное” преимущество в борьбе за “прикарманивание” триплетных кодонов, и очень похоже, что так оно и было. Например, те пятнадцать аминокислот, которые скорее всего кодировались первоначальным дублетным кодом, загребли себе 53 из 64 возможных триплетов (в среднем 3,5 кодона на аминокислоту), в то время как оставшиеся пять “позднейших” аминокислот разделили между собой лишь восемь кодонов (в среднем 1,6 на аминокислоту). Очень похоже, что здесь кто успел, тот и съел.
Давайте подробно рассмотрим следующую возможность: код первоначально был дублетным, а не триплетным, и кодировал пятнадцать аминокислот (плюс один стоп-кодон). Этот первоначальный код, судя по всему, был почти полностью детерминирован, то есть продиктован физическими и химическими факторами. Есть немного исключений из того правила, что первая буква связана с предшественником, а вторая — с гидрофильностью или гидрофобностью аминокислоты. Здесь было мало простора для игры случая, не было свободы от физических законов.
Но с третьей буквой дело обстояло иначе. Здесь было куда больше возможных вариантов, и многое могло произойти по воле случая, после чего отбор получал возможность “оптимизировать” полученный код. Такое смелое предположение высказали в конце 90-х годов два английских специалиста по молекулярной биологии, Лоренс Херст и Стивен Фриленд. Эти два исследователя получили известность благодаря своей совместной работе по сравнению генетического кода с миллионами случайных кодов, сгенерированных компьютером. Они оценивали потенциальный вред точечных мутаций, при которых одна буква кодона заменяется другой. Исследователи задались вопросом, какой код лучше всего противостоял бы таким мутациям, либо по-прежнему кодируя все ту же аминокислоту, либо меняя ее на другую, похожую. Оказалось, что настоящий генетический код поразительно устойчив к таким изменениям: точечные мутации часто вообще не влияют на последовательность аминокислот, а если все-таки влияют, то аминокислота обычно заменяется на другую, близкую к исходной. Более того, Херст и Фриленд пришли к выводу, что наш генетический код лучше миллиона альтернативных кодов, сгенерированных случайным образом. Он оказался отнюдь не жалкой поделкой слепого шифровальщика, а уникальным продуктом, единственным из миллиона. Авторы этой работы утверждают, что наш код не только устойчив к потенциальным изменениям — он нейтрализует возможные катастрофические последствия тех изменений, которые все-таки происходят и тем самым ускоряют эволюцию. Ведь ясно, что у мутаций намного больше шансов оказаться полезными, если они не ведут к катастрофическим последствиям.
Не постулируя вмешательство божественного замысла, подобную оптимизацию можно объяснить только работой отбора. А если так, то шифр жизни должен был эволюционировать. И действительно, целый ряд незначительных вариаций этого “универсального” кода, наблюдаемых среди бактерий и митохондрий, говорит именно о том, что генетический код все-таки может эволюционировать — по крайней мере, при исключительных обстоятельствах. Но как, спросите вы вслед за Криком, он может меняться, не вызывая бедствий? Ответ: постепенно. Если аминокислота кодируется четырьмя или даже шестью разными кодонами, то некоторые из них могут использоваться чаще других. Редко используемые кодоны вполне реально передать другой (но, вероятно, близкой) аминокислоте, не вызывая катастрофических последствий. Именно так генетический код может эволюционировать.
Итак, в целом “код внутри кодонов” говорит нам о процессе, первоначально связанном с биосинтезом и водорастворимостью аминокислот, а затем проходившем фазы расширения и оптимизации. Возникает вопрос: что это был за процесс, на который начал действовать естественный отбор?
Точного ответа на этот вопрос нет, и несколько препятствий затрудняют его поиски. Одним из первых оказалась проблема ДНК и белков (напоминает давнюю проблему — что было раньше, курица или яйцо). Проблема в том, что ДНК сама по себе более или менее неактивна, так что даже для удвоения ее молекул требуются специальные белки. С другой стороны, специальные белки не могли стать специальными случайно. Они должны были эволюционировать путем естественного отбора, а для этого требовалось, чтобы их строение было, во-первых, наследуемым, а во-вторых, изменчивым. Белки не работают как наследуемая матрица для синтеза самих себя: их кодирует ДНК. Значит, белки не могут эволюционировать без ДНК, а ДНК не может эволюционировать без белков. А если одно не могло эволюционировать без другого, то отбору не с чего было начинать.
В середине 8о-х годов было сделано поразительное открытие. Выяснилось, что РНК может работать катализатором. РНК редко сворачивается в двойную спираль: она чаще существует в виде небольших молекул, образующих структуры сложной формы, способные выполнять каталитические функции. РНК позволяет разорвать порочный круг. В гипотетическом “мире РНК” она могла брать на себя роль как белков, так и ДНК, катализируя, наряду со многими другими реакциями, синтез самой себя. Вдруг оказалось, что генетический код поначалу мог вообще не иметь отношения к ДНК: он мог вырасти из непосредственных взаимодействий РНК с белками.
Все это выглядело вполне логично в свете того, что уже было известно о работе современных клеток. Теперь ДНК в клетках непосредственно с аминокислотами не взаимодействует, но многие из ключевых реакций, участвующих в синтезе белков, катализируются именно РНК-ферментами — так называемыми рибозимами. Термин “мир РНК” предложил Уолтер Гилберт, гарвардский коллега Уотсона, в одной из самых читаемых статей, когда-либо опубликованных в журнале “Нейчур”. Идея Гилберта произвела огромное впечатление на всех, кто занимался поисками истоков генетического кода. Изначальный его смысл, оказывается, состоял не в том, как ДНК кодирует белки, а в том, какого рода взаимодействия должны были происходить между РНК и аминокислотами. Однако ответ на поставленный вопрос был по-прежнему не очевиден.
Учитывая, какой интерес вызвала гипотеза мира РНК, может показаться странным, что мало кто обращал внимание на каталитические свойства маленьких фрагментов РНК. Если большие молекулы РНК могут катализировать различные реакции, вполне можно ожидать, что и совсем маленькие фрагменты РНК — отдельные “буквы” или пары “букв” — тоже могут катализировать какие-то реакции, хотя и не столь эффективно. Недавние исследования, которые совместно провели почтенный американский биохимик Гарольд Моровиц, специалист по молекулярной биологии Шелли Копли и физик Эрик Смит, указывают именно на эту возможность. Даже если идеи этих авторов и ошибочны, по-моему, именно такого рода теорию нам нужно искать, чтобы объяснить происхождение генетического кода.
Моровиц и его коллеги постулировали, что двухбуквенные молекулы РНК (по-научному — динуклеотиды) действительно играли роль катализаторов. Такой динуклеотид мог связываться с предшественником аминокислоты, например пируватом, и катализировать его преобразование в аминокислоту. Какая именно аминокислота при этом получалась, зависело от букв, входящих в состав данного динуклеотида (в соответствии с “кодом внутри кодонов”, обсуждавшимся выше). Первой буквой, по сути, определялось вещество-предшественник, а второй — характер преобразования. Например, динуклеотид, соответствующий буквам ТТ, связывался с пируватом и превращал его в довольно гидрофобную аминокислоту лейцин. В подтверждение этой простой и красивой идеи Моровиц привел несколько остроумно подобранных возможных механизмов таких реакций, благодаря чему идея стала выглядеть, по крайней мере, убедительно, хотя мне все-таки хотелось бы увидеть какие-нибудь экспериментальные доказательства того, что такие реакции действительно происходят.
Чтобы перейти отсюда к триплетному коду, по крайней мере продемонстрировать принципиальную возможность такого перехода, нужно всего два этапа, для каждого из которых не требуется делать никаких допущений, кроме обычного образования пар между буквами. На первом этапе молекула РНК связывается с двухбуквенным динуклеотидом по тому же принципу, что и в классическом случае (Г с Ц, А с Т, и наоборот). Аминокислота при этом передается большой молекуле РНК, которая, будучи больше, обладает и большей силой притяжения6. Результатом оказывается РНК, связанная с аминокислотой, разновидность которой зависит от букв, входящих в состав динуклеотида. По сути, мы получаем прообраз угаданных Криком “адаптеров” — молекул РНК, несущих соответствующую аминокислоту.
На втором, последнем этапе двухбуквенный код преобразовывается в трехбуквенный, и для этого снова могло потребоваться лишь стандартное образование пар между азотистыми основаниями РНК. Если подобные взаимодействия лучше работают с двумя буквами, чем с одной (например потому, что при этом получаются более подходящие промежутки или более сильные связи), то мы легко можем перейти к триплетному коду: две первые буквы определяются ограничениями, накладываемыми механизмом синтеза, а третья может в некоторых пределах меняться, оставляя место для дальнейшей оптимизации кода. По-моему, на том этапе эволюции вполне могла быть верна первоначальная концепция Крика, предполагавшая маленькие молекулы РНК, “присасывающиеся” к большой молекуле, как поросята к свиноматке. При этом пространственные ограничения могли заставлять соседние маленькие молекулы РНК располагаться в среднем на расстоянии трех букв друг от друга. Заметьте, здесь еще нет никакой рамки считывания, никаких белков — есть лишь аминокислоты, взаимодействующие с РНК. Но основа для генетического кода уже имеется, а дополнительные аминокислоты могли добавиться в дальнейшем, присвоив себе еще не занятые триплетные кодоны.
Разумеется, изложенный здесь сценарий умозрителен и в подтверждение его пока получено очень мало данных. Главное достоинство этих построений состоит в том, что они проливают свет на происхождение генетического кода (начиная с простого химического сродства и заканчивая триплетными кодонами), предполагая наличие предназначенных для этого правдоподобных и проверяемых механизмов. Тем не менее, вам может показаться, что все это прекрасно, но я размахиваю РНК так, будто она растет на деревьях. И вы можете спросить, как перейти от простого химического сродства к естественному отбору белков. И как перейти от РНК к ДНК? Оказывается, у нас есть замечательные ответы на эти вопросы, подтверждаемые удивительными открытиями, сделанными в последние несколько лет. Что особенно радует, так это то, что они прекрасно согласуются с идеей возникновения жизни в гидротермальных источниках — в обстановке, описанной в главе 1.
Первый вопрос — откуда взялась вся подобная РНК. Хотя исследования, связанные с гипотезой “мира РНК”, продолжаются уже два десятка лет, этим вопросом мало кто задавался всерьез. Негласное и, откровенно говоря, совершенно бессмысленное предположение, из которого все исходили, состоит в том, что она “просто была” в первичном бульоне.
Я вовсе не пытаюсь язвить. Перед наукой стоит немало конкретных вопросов, и на все эти вопросы нельзя ответить одновременно. Гипотеза “мира РНК” с ее замечательной объяснительной силой исходит из наличия РНК как некоей “данности”. Для ученых, положивших начало исследованиям в этом направлении, было не важно, откуда взялась РНК. Вопрос, интересовавший их в первую очередь, заключался в том, что она может делать. Были, конечно, и те, кто интересовался синтезом РНК, но они были разделены на группы, погрязшие в бесконечных спорах и препирательствах при отстаивании любимых версий. Возможно, РНК была синтезирована в космосе из цианида. Возможно, она была получена здесь, на Земле, за счет молний и смеси метана с аммиаком. Возможно, она была синтезирована на пирите — в недрах вулкана. У всех этих сценариев были свои достоинства, но все они страдали от одной и той же фундаментальной проблемы — проблемы концентрации.
Даже синтезировать однобуквенные молекулы, из которых состоит РНК (нуклеотиды), достаточно сложно, а соединяться вместе, образуя полимер (собственно молекулу РНК), они могут лишь при условии, что их концентрация достаточно высока. В этом случае они могут самопроизвольно объединяться в длинные цепочки. Но если их концентрация невысока, то происходит обратное: молекула РНК снова распадается на составляющие. Проблема в том, что при каждой репликации РНК поглощает нуклеотиды, тем самым уменьшая их концентрацию. Без постоянного пополнения запаса нуклеотидов (причем со скоростью большей, чем они поглощаются) гипотеза “мира РНК”, несмотря на всю свою объяснительную силу, никак не может работать. Принять это было нельзя. Поэтому тем, кто хотел и дальше продуктивно работать в этом направлении, было удобнее всего рассматривать РНК как данность.
И они оказались правы, потому что ответ на вопрос, откуда взялась РНК, нашелся не скоро, хотя и оказался в итоге поистине замечательным. РНК и вправду не растет на деревьях, но она может расти в гидротермальных источниках — по крайней мере, теоретически. Неутомимый геохимик Майк Рассел (с которым мы познакомились в главе 1) в важной теоретической статье, написанной в соавторстве с Дитером Брауном и его коллегами из Германии, отметил, что нуклеотиды могли в огромных количествах накапливаться в гидротермальных источниках. Это связано с сильными градиентами температур. Как мы помним из главы 1, щелочные гидротермальные источники пронизаны сетью взаимосвязанных пор. Градиенты температур приводят к возникновению циркулирующих по этим порам потоков двух типов: конвекции (как в кипящем чайнике) и температурной диффузии (рассеивания теплоты в более холодной жидкости). Эти два типа потоков могут приводить к постепенному отложению в самых глубоких порах множества некрупных молекул, в том числе нуклеотидов. Из расчетов, проведенных авторами статьи, следует, что концентрации нуклеотидов в такой системе могли возрастать в тысячи и даже миллионы раз. Столь высокие концентрации вполне могли приводить к объединению нуклеотидов в цепочки РНК или ДНК. Рассел и его коллеги пришли к выводу, что такие условия дают нам “убедительную исходную позицию с высокой концентрацией для начала молекулярной эволюции жизни”.
Но и это не все, на что способны гидротермальные источники. Более длинные молекулы РНК или ДНК теоретически должны аккумулироваться в еще больших количествах, чем отдельные нуклеотиды: так как они крупнее, они с большей вероятностью будут откладываться в порах. Согласно расчетам, молекулы ДНК, включающие около сотни пар оснований, должны накапливаться просто с фантастической скоростью, так что их концентрация может возрастать даже в миллион миллиардов раз. При таких высоких концентрациях принципиально возможны взаимодействия всех типов, обсуждавшихся выше, в том числе связывание молекул РНК друг с другом и многое другое. Более того, колебание температур (циклическое температурное воздействие) способствует репликации РНК тем же путем, что и повсеместно применяемый в лабораториях метод ПЦР (полимеразная цепная реакция). В ходе ПЦР высокие температуры приводят к расплетанию молекулы ДНК, давая ей возможность служить матрицей для синтеза новых цепочек, а последующее увеличение концентрации при более низких температурах дает новым цепочкам возможность полимеризоваться. Это позволяет осуществлять репликацию ДНК в геометрической прогрессии7.
Итак, температурные градиенты в гидротермальных источниках могут приводить к накоплению отдельных нуклеотидов в огромных концентрациях, способствуя образованию молекул РНК. Они тоже будут накапливаться и активнее взаимодействовать друг с другом. И, наконец, колебание температур будет способствовать репликации РНК. Сложно представить себе более подходящие условия для возникновения “мира РНК”.
Но у нас есть и второй вопрос: как перейти от реплицирующихся молекул РНК, конкурирующих друг с другом за ресурсы, к более сложной системе, в которой РНК начнет кодировать белки. Ответ на этот вопрос, возможно, тоже могут дать гидротермальные источники.
Если поместить в пробирку РНК вместе с необходимым ей сырьем и источником энергии (как АТФ), она будет реплицироваться. Более того, как выяснили еще в 60-х годах специалисты по молекулярной биологии (Сол Шпигельман и другие), она будет эволюционировать! После смены ряда поколений, образовавшихся в пробирке, РНК реплицируется все быстрее и быстрее и в итоге начинает делать это с чудовищной быстротой. При этом образуется так называемый монстр Шпигельмана — бурно реплицирующаяся цепочка РНК, возникающая и существующая лишь в искусственных условиях. Примечательно, что для этого неважно, с чего начинать — с целого вируса или с искусственно синтезированного фрагмента РНК. Можно начать даже со смеси нуклеотидов с полимеразой, которая может соединять их друг с другом. С чего бы мы ни начали, результатом обычно оказывается один и тот же “монстр”, одна и та же цепочка РНК длиной всего в полсотни букв, воспроизводящаяся с маниакальным упорством. Все это повторяется раз за разом, как своего рода молекулярный День сурка.
Существенно то, что монстр Шпигельмана не усложняется. Причина, по которой он в итоге превращается в цепочку из полусотни нуклеотидов, состоит в том, что именно такая последовательность нуклеотидов и нужна для связывания с ферментом репликазой, без которого эта цепочка вообще не может реплицироваться. Полученная РНК не видит дальше собственного носа, и в том растворе, где она возникает, никогда не начинается процесс усложнения. Так как и отчего РНК могла начать иодировать белки, пожертвовав собственной скоростью репликации? Единственный способ вырваться из этого порочного круга — это перейти к отбору на “более высоком уровне”, где РНК войдет в состав чего-то большего, что и будет единицей отбора, например в состав клетки. Проблема здесь в том, что все известные живые клетки настолько сложны, что никак не могли возникнуть без эволюции. Для возникновения клетки требуется отбор признаков, а не отбор на скорость репликации РНК. Здесь мы снова сталкиваемся с проблемой курицы и яйца, столь же неотвратимой, как и в случае с ДНК и белками, хотя и не столь знаменитой.
Мы уже убедились, что порочный круг, связанный с ДНК и белками, чудесно разрывает РНК, но что может разорвать порочный круг, связанный с отбором? Искать недалеко: это готовые неорганические клетки в щелочных гидротермальных источниках. Размеры этих клеток сопоставимы с размерами органических клеток, а их формирование в активных источниках продолжается непрерывно. Если содержимое такой клетки особенно хорошо справляется с пополнением запасов сырья, необходимых для самовоспроизводства, эта клетка начинает размножаться, отпочковываясь в другие неорганические клетки. Что же до “эгоистичных” РНК, стремящихся реплицироваться как можно быстрее, то они остаются в проигрыше, поскольку неспособны пополнять запасы сырья, необходимого для поддержания собственной репликации.
Иными словами, в условиях щелочного источника отбор постепенно переходит от работы со скоростью репликации отдельных молекул РНК к работе с “обменом” веществ минеральных клеток, которые и становятся новыми единицами отбора. А белки, кроме прочего, большие мастера управлять обменом веществ. В такой ситуации было неизбежно, что они рано или поздно займут место молекул РНК как катализаторов реакций. Но белки, разумеется, появились не на пустом месте. Скорее всего, в возникновении прообраза обмена веществ принимали участие и минеральные вещества, и нуклеотиды, и РНК, и аминокислоты, и различные молекулярные комплексы (например, аминокислоты, связанные с РНК). Существенно то, что в этом мире естественным образом размножающихся неорганических клеток процесс, начавшийся с простого сродства молекул, мог привести к отбору на способность воспроизводить содержимое таких клеток. Этот отбор стал поддерживать самодостаточность, обеспечив в итоге и переход клеток к автономному существованию. По иронии судьбы именно в автономном существовании современных клеток мы и находим последний ключ к тайне происхождения самой ДНК.
Среди бактерий наблюдается глубокий раскол. Об огромном значении этого раскола для нашей собственной эволюции мы поговорим в главе 4, а пока ограничимся выводами, которые он позволяет сделать о возникновении ДНК и которые тоже достаточно глубоки. Речь идет о разделении бактерий на эубактерий (греческая приставка эу- означает “настоящий”) и еще одну группу, на первый взгляд мало чем отличающуюся от первой. Эту вторую группу называют архебактериями, или просто археями. Своим названием они обязаны идее, что это наиболее архаичная, то есть древняя группа, хотя сегодня мало кто думает, что они сколько-нибудь древнее настоящих бактерий.
Более того, вполне возможно, что по прихоти судьбы и бактерии, и археи возникли в одной и той же “трубе” гидротермального источника. Мало чем еще можно объяснить тот факт, что у них полностью совпадает генетический код, как и многие другие особенности синтеза белков. При этом воспроизводить свою ДНК они, похоже, научились лишь впоследствии, совершенно независимо друг от друга. Хотя сама ДНК и генетический код, несомненно, возникли лишь однажды, репликация ДНК (механизм, обеспечивающий передачу наследственной информации у всех органических клеток), судя по всему, выработалась в ходе эволюции дважды.
Если бы автором этой идеи был не столь большой ученый, как Евгений (Юджин) Кунин, дотошный и проницательный специалист российского происхождения, занимающийся вычислительной геномикой в Национальных институтах здравоохранения США, она вызывала бы у меня серьезные сомнения. Но Кунин и его коллеги не ставили перед собой задачу найти подтверждение некоей смелой концепции. Они пришли к этому выводу в ходе методичного исследования репликации ДНК у бактерий и архей. Подробно сравнивая последовательности множества генов, они установили, что механизмы синтеза белка у бактерий и архей во многом совпадают. Это относится, например, к принципиальному механизму транскрипции последовательности с ДНК на РНК, а затем ее трансляции с РНК на белок. У бактерий и архей в этих процессах участвуют ферменты, которые (судя по последовательностям кодирующих их генов) явно были унаследованы от общего предка. Но это отнюдь не относится к ферментам, необходимым для репликации ДНК. Между большинством их у бактерий и архей нет ровным счетом ничего общего. Это странное положение дел можно было бы объяснять очень сильным эволюционным расхождением, но тогда возникает вопрос, почему такое расхождение не привело к столь же радикальному несходству механизмов транскрипции и трансляции? Простейшим объяснением наблюдаемой ситуации и будет смелое предположение, выдвинутое Куниным: репликация ДНК возникла в ходе эволюции дважды: один раз у архей и один раз у бактерий8.
Подобное утверждение многим могло бы показаться возмутительным, но для блистательного и въедливого техасца, работающего в Германии, это было именно то, что доктор прописал.
Биохимик Билл Мартин, с которым мы познакомились в главе 1, уже объединял усилия с Майком Расселом для изучения возможности зарождения биохимии в гидротермальных источниках. Бросая вызов общепризнанным истинам, в 2003 году они выдвинули собственное предположение: что общий предок бактерий и архей вообще не был свободноживущим организмом, а был особого рода репликатором, заключенным в пористом минерале, еще не вырвавшимся из плена неорганических клеток, пронизывающих трубы гидротермальных источников. В подтверждение своей версии Мартин и Рассел составили список других глубочайших различий бактерий и архей. В частности, у них совершенно разные клеточные мембраны и стенки, что заставляет предположить независимый выход этих двух групп на свободу из одних и тех же минеральных клеток. Многие сочли эту идею слишком смелой, но Кунин считает, что она прекрасно согласуется с его наблюдениями.
Вскоре Мартин и Кунин вместе занялись проблемой происхождения генов и геномов в гидротермальных источниках и в 2005 году опубликовали интереснейшую работу, в которой изложили свои мысли об этом предмете. Они предположили, что “жизненный цикл” минеральных клеток мог напоминать цикл современных ретровирусов, таких как ВИЧ. У ретровирусов крошечный геном, который записан не в ДНК, а в РНК. Проникнув в клетку, ретровирус копирует свою РНК на ДНК с помощью фермента, который называют обратной транскриптазой. Вначале эта новая ДНК встраивается в геном зараженной клетки, а затем считывается оттуда наряду с собственными генами хозяина. В итоге, когда вирус образует многочисленные копии самого себя, он работает с ДНК, но передавая наследственную информацию следующему поколению, он снова записывает ее на РНК. Примечательно, что такие вирусы не умеют реплицировать ДНК. Процедура ее репликации в целом довольно сложна и требует участия целого ряда разных ферментов.
Такой жизненный цикл имеет и свои достоинства, и свои недостатки. Главное его достоинство — скорость. Используя в своих целях имеющийся в клетке аппарат транскрипции с ДНК на РНК и трансляции с РНК на белки, ретровирусы обходятся без большого числа генов и тем самым экономят немало времени и ресурсов. Главный же недостаток состоит в том, что существование таких вирусов целиком и полностью зависит от “соответствующих” клеток. Другой, не столь очевидный недостаток заключается в том, что РНК как хранилище информации сильно уступает ДНК. Молекулам РНК свойственна меньшая химическая стойкость, то есть более высокая химическая активность, чем молекулам ДНК. Именно за счет этого РНК катализирует биохимические реакции. Но высокая химическая активность означает, что большие РНК-геномы нестойки и легко разваливаются. Из-за этого их максимально возможный размер намного меньше, чем требуется для независимого существования. Ретровирусы уже близки по сложности к уровню, предельному для жизненных форм с РНК-геномом.
Но только не для минеральных клеток. У минеральных клеток есть два преимущества, позволяющие этой жизненной форме достигать в ходе эволюции и более высоких уровней сложности. Первое состоит в том, что в щелочных гидротермальных источниках многие вещи, необходимые для независимого существования, имеются в свободном доступе. Это очень упрощало жизнь обитателям таких источников: у постоянно нарастающих минеральных клеток уже были и оболочки, и источник энергии, и многое другое. Поэтому в некотором смысле самореплицирующиеся РНК, колонизовавшие такие клетки, уже были вирусными. Второе преимущество состоит в том, что молекулы РНК в этих “стаях” могли постоянно перемешиваться в связанных между собой клетках, и отбор мог поддерживать те их группы, у которых лучше получалось “сотрудничать”, если они могли вместе распространяться, колонизуя новообразованные клетки.
Поэтому Мартин и Кунин предположили, что в минеральных клетках могли возникнуть целые популяции сотрудничающих друг с другом молекул РНК, каждая из которых кодировала небольшое число близких генов. Разумеется, у такой системы есть и существенный недостаток: популяции РНК легко смешивались бы друг с другом, образуя новые, часто неудачные комбинации. Минеральная клетка, которой удалось бы сплотить свой “геном”, синтезировав на основе группы сотрудничающих молекул РНК одну молекулу ДНК, тем самым сохранила бы все накопленные преимущества. Механизм ее самовоспроизводства напоминал бы механизм воспроизводства ретровирусов: с ее ДНК транскрибировалась бы стайка РНК, которые заражали бы соседние клетки, передавая им ту же способность хранить информацию в надежном ДНК-банке. Каждая новая волна РНК выдавалась бы уже этим банком, а значит, была бы лучше защищена от возможных ошибок.
Насколько сложно было бы минеральным клеткам “изобрести” ДНК в таких условиях? Возможно, не так уж сложно, во всяком случае гораздо проще, чем изобрести целую систему для репликации ДНК (а не РНК). Между РНК и ДНК есть лишь два крошечных химических различия, но вместе они составляют огромную структурную разницу — разницу между свернутыми каталитическими молекулами РНК и классической двойной спиралью ДНК (что, кстати, предположили еще Уотсон и Крик в своей первой публикации 1953 года)9. Мало что могло помешать соответствующим крошечным изменениям происходить в гидротермальных источниках почти самопроизвольно. Первое из них — это удаление из РНК (рибонуклеиновой кислоты) единственного атома кислорода, в результате чего получается дезоксирибонуклеиновая кислота (ДНК). Механизм, с помощью которого эта реакция осуществляется сегодня, по-прежнему включает химически активные посредники (свободные радикалы) того же рода, что встречаются в щелочных источниках.
Второе изменение — это добавление метальной группы атомов (СН3) к входящему в состав РНК азотистому основанию урацилу, из которого при этом получается входящий в состав ДНК тимин. Метильные группы в виде свободных радикалов образуются, в свою очередь, из осколков молекул метана, в изобилии имеющихся в щелочных источниках.
Выходит, сделать ДНК было сравнительно просто: она должна была образовываться в гидротермальных источниках столь же самопроизвольно, как и РНК (я имею в виду ее образование из несложных веществ-предшественников, катализируемое минералами, нуклеотидами, аминокислотами и так далее). Немного сложнее было сделать так, чтобы ДНК сохраняла закодированную в РНК информацию, то есть точно копировала последовательности букв молекул РНК в форме ДНК. Но и здесь нет никакой непреодолимой пропасти. Для синтеза ДНК на матрице РНК требуется всего один фермент — обратная транскриптаза, на которую сегодня полагаются ретровирусы, например ВИЧ. По иронии судьбы тот самый фермент, который нарушает “центральную догму молекулярной биологии” (“ДНК делает РНК делает белок”), видимо, и превратил пористый минерал, набитый “вирусной” РНК, в жизнь, как мы ее знаем! Возможно, что самим появлением органических клеток мы обязаны ферменту скромных ретровирусов.
В этом рассказе многое упущено, и многие загадки были пропущены, чтобы попытаться восстановить логику описываемых событий, по крайней мере так, как я ее себе представляю. Не стану делать вид, будто факты, которые мы здесь обсудили, дают нам неопровержимые доказательства, а не просто ключи к тайнам нашего древнейшего прошлого. Но все-таки это настоящие ключи, и какая бы теория ни оказалась правильной, она должна будет объяснять все приведенные здесь факты. Генетический код действительно демонстрирует определенные закономерности, указывающие на работу как химии, так и естественного отбора. Потоки, бурлившие в трубах глубоководных гидротермальных источников, действительно должны были приводить к накоплению нуклеотидов, РНК и ДНК, делая минеральные клетки, пронизывавшие стенки этих труб, идеальной средой для “мира РНК”. А между археями и бактериями действительно есть глубокие различия, от которых нельзя просто так отмахнуться. Они определенно указывают на то, что жизнь, как мы ее знаем, вышла из процесса, напоминающего жизненный цикл ретровирусов.
У меня вызывает огромный восторг сознание того, что история, которую мы здесь разобрали, может быть правдой, но одна затаенная мысль все же заставляет меня сомневаться. Я говорю о том выводе, что клеточная жизнь вышла из глубоководных гидротермальных источников дважды. Могли ли стаи РНК “заражать” соседние источники, постепенно завоевывая обширные зоны на дне океана, давая естественному отбору возможность работать в глобальном масштабе? Или необычные условия одного конкретного источника по какой-то причине оказались исключительно благоприятны и именно из него вышли археи и бактерии? Возможно, мы никогда этого не узнаем, но описанная здесь игра случая и необходимости дает нам всем хороший повод задуматься.
Назад: Глава 1. Происхождение жизни
Дальше: Глава 3. Фотосинтез

